Майкл ДМерс ГИС. Инициаторы проведения этого новаторского события надеются привлечь к нему внимание мировой общественности и широких масс пользователей географических информационных систем из всех стран.
 Скачать 4.47 Mb. Скачать 4.47 Mb.
|

|
Глава 9 До сих пор мы рассматривали переклассификацию данных лишь номинальной шкалы измерений. Нетрудно представить, как можно было бы переклассифицировать данные других шкал. В картографических методах это делается созданием диапазонов категорий данных, что часто называется ранжированными (range graded) классификациями. Такой сценарий требует от нас всего лишь перекодировать эти данные на основе классовых интервалов, в которые они попадают. И, как и в случае данных номинальной шкалы, мы просто перекодируем ячейки растра или выполняем замену атрибутов и растворение границ. Одновременно мы можем также выполнить такие операции, как упорядочивание ячеек растра или значений полигонов, их инверсию или использовать иные преобразования, включающие математические операции (умножение, деление и т.д.) над значениями полигонов с участием других переменных. При этом процесс по сути таков же, как и в случае с данными номинальной шкалы. Все перечисленные до сих пор методы имеют одну общую черту. Процесс переклассификации направлен на переименовывание полигонов на основе значений атрибутов на их собственном месте. Это своего рода приземленный взгляд, в котором каждый набор ячеек растра или каждый полигон рассматривается как отчетливо индивидуальная сущность, а классификация ограничена целевой областью, — как в использовании начальных значений, так и в самой переклассификации. Переклассификация на основе атрибутивной информации — только один из четырех основных методов; остальные основаны на информации о положении, размере и форме. Впрочем, эти представления не выделяются как отдельные методы: все они часто комбинируются друг с другом для создания широкого разнообразия методов переклассификации. Мы рассмотрим их, начиная с функций соседства, затем рассмотрим различные типы, включая фильтры, двух - и трехмерные соседства и буферы. Читая, отметьте частые сходства между этими методами, когда они применяются в различных обстоятельствах. ОКРЕСТНОСТИ Переклассификация на основе "негеометрических" атрибутов очень полезна, но она ограничивает нас атрибутами в пределах каждого объекта. Было бы замечательно, если бы мы могли классифицировать объекты с высоты птичьего полета. Другими словами, если бы мы могли пролететь над территорией, то могли бы узнать не только о существовании определенного объекта, но и о том, как он расположен по отношению к другим. Такие процедуры переклассификации основаны на идее характеризования каждого объекта как части большей окрестности (neighborhood) объектов. Нам свойственно более часто взаимодействовать с теми, кто находится ближе, чем с теми, кто дальше. В некоторых случаях окрестности определяются политическими или экономическими критериями. Окрестности могут определяться в терминах объединяющего атрибута всей области (такая классификация называется общим анализом соседства (total analysis of neighborhood)), или фокус может быть направлен на меньшие части всей территории (целевой анализ (targeted analysis)) [Star and Estes, 1990; Tomlin, 1990]. Целевой анализ, также называемый непосредственной окрестностью (immediate neighborhoods), включает только места, непосредственно прилегающие к целевой области или месту. Анализ общего соседства, называемый также расширенной окрестностью (extended neighborhoods), включает местоположения, которые находятся в непосредственной близости, а также и удаленные на некоторое расстояние. Хотя такое разделение функций соседства интеллектуально стимулирует и довольно полезно для продвинутого ГИС-аналитика, на начальном уровне оно может внести некоторую путаницу. Набравшись опыта и расширив свой лексикон, вы можете обратиться к книге Томлин [Tomlin, 1990], где дана классификация функций соседства. А пока мы посмотрим на функции соседства, имеющие дело с двух и трехмерными объектами. Мы сможем разделить функции обоих этих типов на статические (static neighborhood functions), в которых анализ проводится сразу по всей выбранной целевой области, и функции скользящего окна (roving window neighborhood functions), где анализ проводится только в рамках окна, которое перемещается по покрытию. Мы встречали пример "оконной" функции в Главе 8, когда характеризовали развитость границы области. ФИЛЬТРЫ Как мы видели в Главе 8, существуют функции, которые используют окно переклассификации ячеек растра для определения развитости границы области. Эти оконные функции называются также фильтрами, особенно если само окно является матрицей чисел, которые служат операндами в выражениях со значениями ячеек растра. Довольно часто этот метод используется в обработке изображений дистанционного зондирования [Lillesand and Kiefer, 1995], но имеет такую же применимость и в растровых ГИС. В частности, фильтры используются для выделения краев областей или линейных объектов (фильтры высоких частот (ФВЧ) (high pass filters)), усиления общих градиентов и устранения мелких флуктуации и шума (фильтры низких частот (ФНЧ) (low pass filters)), или даже для подчеркивания ориентации (анизотропные фильтры (directional filters)). Фильтр высоких частот предназначен для выделения деталей в растровом покрытии, которые могут быть незаметны из-за близлежащих ячеек растра, содержащих относительно близкие значения. В дистанционном зондировании эти значения показывают величину отражения электромагнитного излучения. Однако, мы можем использовать практически любые связанные с поверхностью данные. Допустим, что мы заинтересованы в обнаружении мелких гребней в растровом топографическом покрытии. Каждая ячейка растра содержит отсчет высоты, и мы хотим подчеркнуть контраст между несколько более высокими значениями для гребня и несколько более низкими значениями, окружающими этот объект. Типичный метод для выполнения такой фильтрации высоких пространственных частот состоит в том, чтобы создать матрицу фильтра 3x3 с весовым коэффициентом 9 в центральной клетке и минус 1 - во всех остальных. Этот фильтр помещается поверх каждой группы ячеек растра 3x3 в нашем покрытии, и члены каждой пары соответствующих ячеек растра и матрицы фильтра перемножаются. То есть, значение высоты в центральной ячейке растра топографического покрытия умножается на коэффициент 9, а все остальные значения умножаются на минус 1. Затем, эти девять только что созданных произведений суммируются для получения результирующего значения центральной ячейки растра (Рисунок 9.2). Другими словами, эта одиночная операция с двумя матрицами по девять чисел производит единственное значение, которое помещается в центр нового покрытия. Следующий шаг должен переместить фильтр на одну ячейка растра вправо, так, чтобы центральная ячейка в топографическом покрытии была теперь (3,2). Вычисления выполняются также, как и прежде, приводя к новому значению ячейки (3,2). Процедура повторяется для всего покрытия, так что в итоге в результирующем покрытии гребни видны гораздо лучше. Поскольку края областей и линейные объекты имеют различные ориентации (например, вы можете обнаружить какое-то число гребней, связанных с некоторым геологическим циклом образования складок и эрозии), иногда полезно согласовать фильтр с определенной ориентацией. Например, если вы хотите выделить гребни, ориентированные с востока на запад, вы должны использовать фильтр (размер матрицы оставим тот же), у которого ячейки средней строки содержат положительные числа, а остальные - минус 1. Для ориентации с северо-запада на юго-восток нужно сделать положительными числа главной диагонали матрицы фильтра. То же относится и к другим направлениям, то есть положительные числа ориентированы в том направлении, которое вы желаете подчеркнуть. Если вы хотите подавить более высокие пространственные частоты, чтобы удалить не имеющие ценности топографические флуктуации, получив таким образом покрытие, которое показывает топографию в более общем (упрощенном, сглаженном) виде, вы можете использовать фильтр с меньшим  
Перемещаемая матрица фильтра  Заметьте, что некоторые значения стали намного больше а другие -намного меньше Рисунок 9.2. Фильтр высоких частот. Работа ФВЧ с использованием матрицы 3x3, предназначенной для подчеркивания более высоких пространственных частот по сравнению с более низкими. различием коэффициентов. Наиболее распространен ФНЧ с матрицей 3x3, все коэффициенты которой равны одной девятой (чтобы сумма по всем ячейкам составляла единицу). В результате значения каждой ячейки будут усреднены с соседними. Хотя обычные методы фильтрации растра используют стандартные матрицы 3x3 с "прошитыми" коэффициентами, нет необходимости к этому привязываться. Большинство программ, выполняющих фильтрацию, позволяют менять размер матрицы и значения коэффициентов. Чем больше размер матрицы, тем большее пространственное усреднение можно получить в случае ФНЧ, поскольку большее число ячеек принимают участие в усреднении. В случае ФВЧ с ростом размера матрицы может быть получено более качественное подчеркивание мелких деталей поверхности. Решение использовать нестандартные размеры и коэффициенты часто возникает в результате экспериментирования. ОКРЕСТНОСТИ Мы знаем, что ГИС должна быть способна измерять размер полигона, или фрагментированного региона, составленного из нескольких полигонов. Представьте, однако, что нас интересует только идентичность полигонов региона в пределах некоторой окрестности или расстояния. Например, мы изучаем распространение новых фермерских методов, чтобы увидеть, не проявляется ли картина подражания, когда фермеры-традиционалисты вооружаются новыми методами, внедренными их соседями. Допустим, нас интересуют зоны использования так называемой нулевой обработки почвы перед посевом. Вначале мы выбираем покрытие, показывающее только места, где данный метод применяется. Затем мы устанавливаем примерный радиус, в котором скорее всего может наблюдаться подражание. Мы можем принять, что оно проявится только у непосредственных соседей, либо что идея укоренится где-нибудь еще. В обоих случаях ГИС возьмет эту величину и начнет просмотр во все стороны, пока не достигнет дистанции радиуса поиска, наращивая по пути объем применения метода (по сути, измеряя площадь полигонов или их групп). В результате получаются малые, средние и большие группы полей, на которых, по-видимому, используется эта новая практика. ГИС обработала исходную территорию таким образом, что все полигоны или ячейки растра, которые попадают в заданный радиус друг от друга, получают один и тот же атрибут. Группы номеруются по порядку обнаружения. Каждая может быть потом переклассифицирована в соответствии со своим размером. Возможно, что мы придем к выводу, что фермеры в больших группах соседства более общительны между собой, или что сами фермы больше, или что эти фермеры знакомы с людьми из расположенного поблизости сельскохозяйственного колледжа. В любом случае, полученные значения показывают, что либо в больших окрестностях по сравнению с малыми имеют место различные механизмы распространения этой идеи, либо существуют иные причины различия размеров этих групп. Интерпретация причин получения таких результатов обычно потребует дальнейшей проверки, но здесь важно то, что функция соседства в ГИС позволила нам эти различия обнаружить. В предыдущем описании окрестностей мы рассматривали одиночный атрибут выбранных групп в пределах заданного радиуса. Однако, часто мы больше заинтересованы в определении сходств и различий в пределах выбранной окрестности, нежели в группах однородных полигонов или групп ячеек растра. Например, мы хотим определить средний возраст людей в заданном регионе на основе данных переписи. Выбираем радиус поиска, как и раньше, программа просматривает атрибуты всех полигонов участков переписи или ячеек растра, и затем выполняет простое усреднение этих величин. В конечном итоге мы получаем новое покрытие со средним возрастом на основе этих расчетов. Но не только усреднение может использоваться для определения новых окрестностей. Например, мы интересуемся определенным видом животных, которых особенно привлекает разнообразие ландшафта. Чем оно выше, тем больше это окружение нравится таким животным, оно дает множество мест для отдыха, питания, укрытия от солнца и от хищников. Нам также известно, что таким животным нужна определенная территория для жизни. Мы преобразуем эту известную величину площади в радиус поиска и далее действуем как и прежде. В данном случае программа просматривает все различные типы ландшафтов в пределах радиуса поиска и подсчитывает их, возвращая число этих типов в качестве пространственного или ландшафтного разнообразия. Области наибольшего разнообразия скорее всего и будут избираться животными этого вида для обитания. Как вы могли догадаться, раз мы можем выполнять усреднение по полигонам или ячейкам растра окрестности, то можем также выполнять и другие расчеты. Возможно вычисление некоторого максимального значения по окрестности, как, например, наибольшее число преступлений в окрестности за указанный год. Или мы могли бы поискать минимальное значение, например, среди цен домов этой окрестности, чтобы решить, сможем ли мы себе позволить там жить. Другие операции включают подсчеты общего количества всех видов, определение медианы, наивысшей и наинизшей частот, отклонения от центральной точки по отношению к среднему окружающих значений и даже доли окрестности, имеющей те же атрибуты, что и в центральной точке окрестности. Указанные в предыдущих двух абзацах операции могут выполняться многими различными способами. Например, результат операции над окрестностью (среднее, медиана, дисперсия и т.д.) может присваиваться центральной точке, передаваемой в новое покрытие. Мы можем также не назначать радиус окрестности, а использовать вместо этого скользящее окно для охарактеризования всего покрытия на основе тех же расчетов, что и прежде (среднее, медиана, дисперсия и т.д.). В этом случае выходная величина будет присваиваться не центральной точке, а всем ячейкам окна, давая нам представление о тенденциях изменений от одной части покрытия к другой. В одних случаях мы можем создавать окрестность и выполнять операции на основе значений ячеек одного покрытия, в других - использовать разные покрытия для целевых ячеек и для построения окрестности. Например, если мы хотим знать величину разнообразия ландшафта в окрестностях известных местоположений птичьих гнезд, то могли бы взять покрытие с положением гнезд в качестве целевых ячеек, а другое покрытие - с типом ландшафта -для построения окрестностей. Используя материал Главы 8, мы можем увидеть, что способность ГИС измерять размер и форму дает и другие пути создания окрестностей. Например, измерение размера часто объединяется с определением групп одного значения атрибута полигонов. Чаще всего эта информация используется для ранжирования или упорядочивания результатов аналитических операций, которые группируют данные в локализованные или регионализованные группы. Размеры групп могут быть очень важны в нашем анализе. Например, экологи знают о размерах территории, требующейся волкам и другим крупным хищникам [Forman and Godron, 1987]. Они также знакомы с минимальными требованиями отдельных лесных массивов для поддержки необходимого разнообразия животных видов и даже для того, чтобы продолжать существовать как лес. В некоторых случаях может потребоваться объединение меры разнообразия окрестности (где большее разнообразие означает лучшую среду обитания) с определением размеров (когда предпочтительны большие площади). Могут применяться и другие комбинации. Давайте рассмотрим пример. Ягуары - крупные хищные кошки, которым требуются разнообразные элементы среды обитания, особенно растительность джунглей, для укрытия, и проточные водоемы, так как большая часть их диеты состоит из рыбы. Для простоты скажем, что ягуарам требуется примерно 200 кв. миль территории для проживания и что им требуется только два типа среды -джунгли и речной коридор. Далее примем, что требования к территории таковы, что на одну часть речного коридора должно приходиться 10 частей леса. Мы можем идентифицировать отношение между целевыми точками вдоль реки из речного покрытия и площади окружающего (соседствующего) леса в растительном покрытии, которое включает речной коридор как одну из категорий. Мы можем переклассифицировать покрытие растительности в речной коридор и лесную растительность, чтобы упростить наши вычисления. Затем, используя функцию соседства, которая вычисляет отношение площади окрестности той же категории, что и целевое местоположение, мы можем определить окрестности, которые имеют по меньшей мере одну десятую речного коридора. Наконец, после создания окрестностей, которые удовлетворяют требованием проживания ягуаров, мы можем рассмотреть размер. Окрестности, которые имеют площадь не менее 200 кв. миль и отношение 1:10 речного коридора к лесу, являются идеальными местами для обитания ягуаров. Предположим, однако, что обнаруженная в результате нашего анализа окрестность выглядит подобно профилю песочных часов, и река протекает через ее наиболее узкую часть. Области снаружи нашего леса и речного коридора не заселены людьми, которых ягуары обычно избегают. Речной коридор в этом бутылочном горлышке может быть недостаточен для деятельности животных. То есть, два конца этой фигуры могут быть функционально раздельными областями обитания, каждая из которых недостаточно велика для выживания ягуаров. Используя умение ГИС измерять расстояния поперек полигональных объектов, мы можем провести анализ, который обнаруживает и классифицирует регионы на основе некоторой величины узости, обычно самой узкой части полигона. Таким образом, мы применили еще одну меру окрестности, в данном случае основанную на форме. Но и другие меры формы, представленные в Главе 8 (функция Эйлера, развитость границы, и др.), могут комбинироваться или использоваться по отдельности для описания окрестностей. На самом деле, количество команд и их опций, предназначенных для классификации и переклассификации окрестностей, в большинстве ГИС довольно велико. Нам нет нужды ограничивать себя анализом окрестностей на основе двухмерных покрытий. В качестве источника характеристик окрестностей мы можем использовать также и топографические данные. Хотя конкретно поверхности и операции с ними мы рассмотрим более детально позже, уже сейчас мы можем рассмотреть применение трехмерных поверхностей в переклассифицировании окрестностей. Тогда мы вспомним и о том, как мы могли бы использовать поверхности в описании окрестностей. ПЕРЕКЛАССИФИКАЦИЯ ПОВЕРХНОСТЕЙ Наиболее широко используются следующие четыре характеристики трехмерных поверхностей для описания окрестностей: уклон, азимут (экспозиция склона), форма и взаимная видимость. В той или иной степени все они могут применяться и в векторных и в растровых ГИС, опять же в зависимости от сложности программного обеспечения. Во многих случаях, как при переклассификации двухмерных покрытий, эти характеристики могут быть использованы и в сочетании друг с другом. Сейчас мы рассмотрим их по отдельности. Закончим их сочетаниями для более сложных видов анализа. Уклон Если вы планируете построить домик на горе, то, вероятно, захотите узнать, где находятся наиболее пологие участки, чтобы ваш новый дом не решился однажды переехать к подножию торы. Или, намереваясь спилить некоторую часть деревьев на склоне горы, вы можете использовать этот же склон, чтобы скатывать только что срезанные стволы вниз (не общепринятый метод, между прочим). Или вы, возможно, планируете лыжную базу и хотите предложить клиентам три разных величины уклона: "новичок", "любитель" и "профи". Во всех этих случаях нужно знать кое-что об уклоне, но вас интересует не столько кратчайший маршрут вниз, сколько общий обзор мест крутого, умеренного и малого уклона. Концептуально процесс довольно прост: вам нужно узнать связь между расстоянием по горизонтали и соответствующей разницей высот. Отношение второй величины к первой и является обычным способом выражения уклона. Чтобы сделать это в векторной системе, вам нужна модель данных, подобная нерегулярной сети триангуляции (TIN), рассмотренной ранее. Конечно, растровая система может сразу же с этим справиться, хотя потребуется некоторая компенсация ошибок из-за дискретности растрового пространства. Обычный метод вычисления уклона состоит в том, чтобы провести наиболее подходящую поверхность через соседние точки и измерить отношение изменения высоты на единицу расстояния [Clarke, 1990]. Вернее, ГИС просчитает это отношение по всему покрытию, создавая набор категорий величины уклона, во многом подобно тому, как мы поступали бы, определяя границы классов. Если нам нужно меньшее число категорий, чем реально получилось, то мы можем переклассифицировать набор, произведенный ГИС. Хотя методы, разработанные для построения уклона на топографической поверхности, применяются широко, поверхность не должна быть обязательно топографической. Как мы увидим в Главе 10, наше представление о поверхностях может быть обобщено на любые виды поверхностных данных, которые измеряются в шкалах рангов, интервалов и отношений. Они называются статистическими поверхностями (statistical surfaces) и являются поверхностным представлением пространственно-распределенных статистических данных. Таким образом мы могли бы анализировать величину уклона (градиент) в изменении населенности, осадков, атмосферного давления — любой величины, которая является или может быть принята непрерывной по покрытию. Данные номинальной шкалы здесь не подходят по определению. Представьте себе растровую БД со следующими кодами атрибута землепользования: 1 = сельское хозяйство, 2 = город, 3 = производство и т.д. Любая поверхность, созданная на основе этого набора атрибутов, - бессмысленна, так как эти числа, хотя и могущие казаться принадлежащими порядковой шкале, шкале интервалов или шкале отношений, на самом деле к ним не относятся. То есть, в такой попытке мы ошибочно применили бы арифметические операции к несравнимым именам категорий. Здесь мы хотим настойчиво подчеркнуть, что недостаток понимания основных шкал измерения данных может привести к невероятно бесполезным результатам. Пара примеров правильного и уместного использования уклона может оказаться поучительной. Допустим, мы ищем склоны, крутизна которых менее 25% (т.е. 25 м высоты на 100 м расстояния по горизонтали) для определения областей, пригодных для строительства коттеджа. Для определения уклона программа просто сравнивает разность высот между вершинами каждой грани TIN (TIN facets) с соответствующими горизонтальными расстояниями. На самом деле, поскольку модель TIN хранит эти вычисленные значения в своих таблицах атрибутов, то расчеты вообще не требуется проводить. Каждое значение грани может быть выбрано из БД, и уклоны могут быть сгруппированы на те, что имеют крутизну менее 25%, и те, что имеют 25% или более. Мы можем назвать их как "непригодные" (>=25% - слишком круто для строительства) и "пригодные" (<25% - приемлемо для строительства). Таким образом мы переклассифицировали топографическую поверхность по величине уклона для содействия принятию решения о пригодности для строительства. Существует множество путей обработки информации об уклонах, в особенности такие, которые используют методы нелинейной интерполяции (о них - чуть позже), и такие, которые генерализуют топографию для показа общего тренда поверхности. Мы обратимся к ним в Главе 10. Как простые, так и сложные методы переклассификации на основе только лишь уклона могут выполняться и в растровых ГИС. Простейший способ состоит в оценке восьми непосредственных соседей каждой ячейки растрового покрытия. Программа строит плоскость по восьми ближайшим соседним ячейкам поиском либо наибольшей величины уклона для окружения ячеек растра, либо среднего уклона (обычно выбор - за пользователем). Для каждой группы ячеек программа использует разрешение растра в качестве меры расстояния по горизонтали и сравнивает значения атрибута (высоты) в центральной точке со всеми окружающими ячейками (Рисунок 9.3). 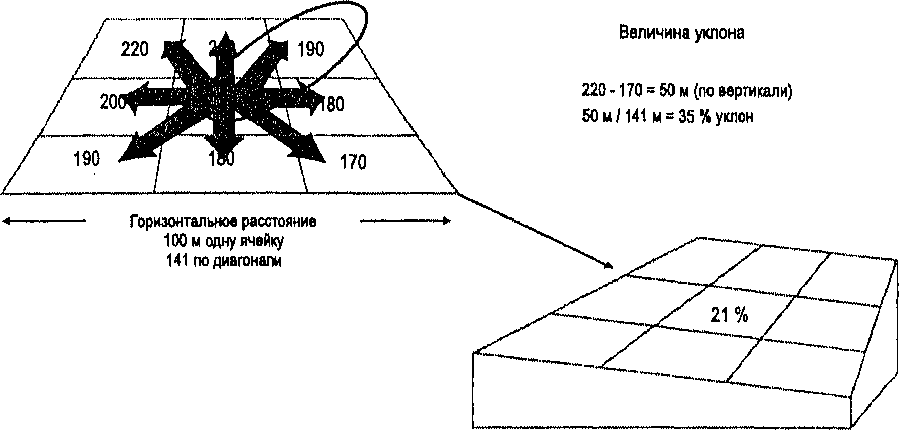 Рисунок 9.3. Поверхность тренда в растре. Растровый метод определения уклона с подгонкой плоскости к восьми соседям центральной ячейки. Растровая ГИС укажет наибольший уклон в результате сравнения центральной ячейки с ее соседями. Например, если мы строим лыжную базу и хотим отобрать склоны с крутизной не более 15% для новичков, от 16 до 25% для любителей и от 26 до 45% для профессионалов, мы можем создать три этих класса простой переклассификацией, идентифицируя все области с максимальным (или средним) уклоном 0-15%, 16-25% и 26-45%. Все склоны круче 45% будут названы непригодными, так как они слишком круты для лыж. Как и векторные, растровые ГИС могут применять методы нелинейной интерполяции, такие как кригинг (kriging) и процессы подгонки поверхностей (surface-fitting). Многие из них основаны на применении методов поиска во время выполнения анализа [Hodgson, 1989]. Если ваша программа не поддерживает их как отдельные алгоритмы, возможен путь создания близкого приближения к некоторым из этих методов использованием нескольких вызовов имеющегося метода. Например, можно сгладить склоны для получения поверхности тренда использованием любого алгоритма вашей программы, затем - повторением процесса уже по отношению к результату первого шага. Другими словами, вы выполняете несколько итераций определения уклона. Чем больше итераций, тем более ровной будет выглядеть ваша поверхность. Если продолжать, то в конце концов вы получите одну лишь плоскость. Технически это называется переходом к поверхности тренда первой степени от некоторой поверхности более высокого порядка. Экспозиция склонов (аспект) Поскольку поверхности имеют уклон, они имеют также и ориентацию, называемую экспозицией или аспектом (aspect). Идеи уклона и экспозиции неразделимы как в физическом, так и в аналитическом плане. Без уклона невозможен топографический аспект. Существует множество применений этой идеи. Например, биогеографы и экологи знают, что часто существует заметное различие между растительностью на северных склонах и тех, что обращены на юг [Brown and Gibson, 1983]. Главной причиной этого является различие количества солнечной радиации, поступающей на единицу площади склона, но нас сейчас интересует то, что ГИС позволяет нам разделить ориентированные на север и на юг склоны для сравнения с другими тематическими покрытиями, такими как почва и растительность. Другой пример использования информации об экспозиции склонов - размещение ветроэлектрогенераторов. Их нужно устанавливать высоко на склонах, чтобы они получали максимум энергии ветра, но при этом на тех склонах, которые обращены к преобладающим ветрам, а не на тех, что закрыты от них. Для геологов преобладающий уклон сдвигов может быть путем к пониманию подземных процессов. Садовод может пожелать разместить свой сад на солнечной стороне холма, чтобы использовать преимущества большей освещенности. Все эти анализы могут выполняться при помощи функций, которые классифицируют поверхности на основе их экспозиции. В векторных ГИС, использующих модель данных, подобную TIN, работа с аспектами относительно проста. Каждая грань модели TIN имеет определенные уклон и аспект. Аспект определяется как азимут нормали каждой треугольной грани поверхности [Evans, 1980]. Когда производятся вычисления с участием аспекта, эти значения могут выбираться из БД TIN без дополнительных вычислений. И, как и раньше, мы можем группировать их в классы. Например, если мы - биогеографы, заинтересованные только склонами, ориентированными на юг и на север, мы можем создать три разных класса на основе выбранного критерия. Так, склоны могут быть классифицированы как имеющие северную ориентацию, если их азимут находится в диапазоне от 345° до 15°, а южно-ориентированным склонам будет приписан аспект от 165° до 195°. То есть, классы имеют диапазон в 30° - по 15° с каждой стороны от главного направления. Все остальные значения аспекта могут быть классифицированы как "неподходящие", так как они не нужны для анализа биогеографа. Конечно же, вы можете выбрать свои собственные границы классов для этих окрестностей в соответствии с вашими потребностями. В случае растра, опять же, нужно провести анализ по всему покрытию, в котором последовательно все точки как центральные точки окрестности сравниваются со своими соседями. Здесь поверхность, подогнанная к матрице из девяти ячеек, дает направление по среднему или максимуму посредством просмотра больших и меньших значений высоты в пределах матрицы. Если, например, наивысшее значение находится в середине вверху, а наинизшее - в середине внизу, решением данного случая будет общее направление на юг (предполагается, что покрытие имеет географическую привязку). Или вы можете обнаружить, что высшая и низшая величины находятся соответственно в левом верхнем и правом нижнем углах. Это даст юго-восточный аспект данного участка поверхности. Результаты растрового анализа аспекта могут выражаться как в градусах (0-360), так и более простым набором векторов, напоминающим цепочечные коды Фримэна, где, например, север, юг, восток и запад могут обозначаться как соответственно 0,2,4 и 6, а северо-восток, юго-восток, юго-запад и северо-запад - как 1,3, 5,7. Реальные номера и методы зависят от программного обеспечения. Профиль поверхности Другой полезный пример переклассификации статистических поверхностей - оценка их формы. Простейший способ визуализации формы поверхности — ее поперечный профиль (cross-sectional profile). Это распространенная практика во многих курсах географии и геологии, где от студентов требуют изобразить профиль топографической поверхности вдоль линии, проведенной между двумя точками. Он строится переносом каждого отсчета высоты на лист бумаги в клетку, где по горизонтали откладывается расстояние от одной из выбранных точек, а вертикальная ось несет значения высоты. Процесс легко выполняется в векторной ГИС с использованием модели TIN, где линия (необязательно прямая) проводится по какому-то участку покрытия. Тогда программа создает профиль, идентичный тому, что был бы создан вручную по бумажной карте. Однако помните, что это изображение - не покрытие, и результаты используются лишь как средство интерпретации того, что там имеется. Известно, например, что V-образный профиль чаще всего связан с долинами рек, а U-образный — с долинами ледников. Чем больше вы знаете о поверхностных процессах, с которыми работаете, тем лучше может быть ваша интерпретация результатов. Ваша растровая ГИС может не иметь средств создания поперечных профилей. Однако, многие используют альтернативный метод, который производит растровое покрытие в результате сравнения центральной ячейки с двумя непосредственными соседями. Вы можете выбрать ориентацию этого поиска такой, чтобы он был способен характеризовать набор профилей для ячеек растра посредством просмотра горизонтальных рядов, вертикальных колонок, или даже диагональных наборов ячеек растра. Программа будет брать ячейки растра группами по три и сравнивать центральную с двумя соседями. Она будет описывать каждую ячейку присвоением одного из номеров типов формы: плоская, растущая, падающая, плоская, затем растущая, плоская, затем падающая, растущая, затем падающая (выпуклая как холм) и падающая, затем растущая (вогнутая как долина). Они характеризуются кодами, помещаемыми в новое покрытие (Рисунок 9.4), Затем коды должны интерпретироваться вручную. 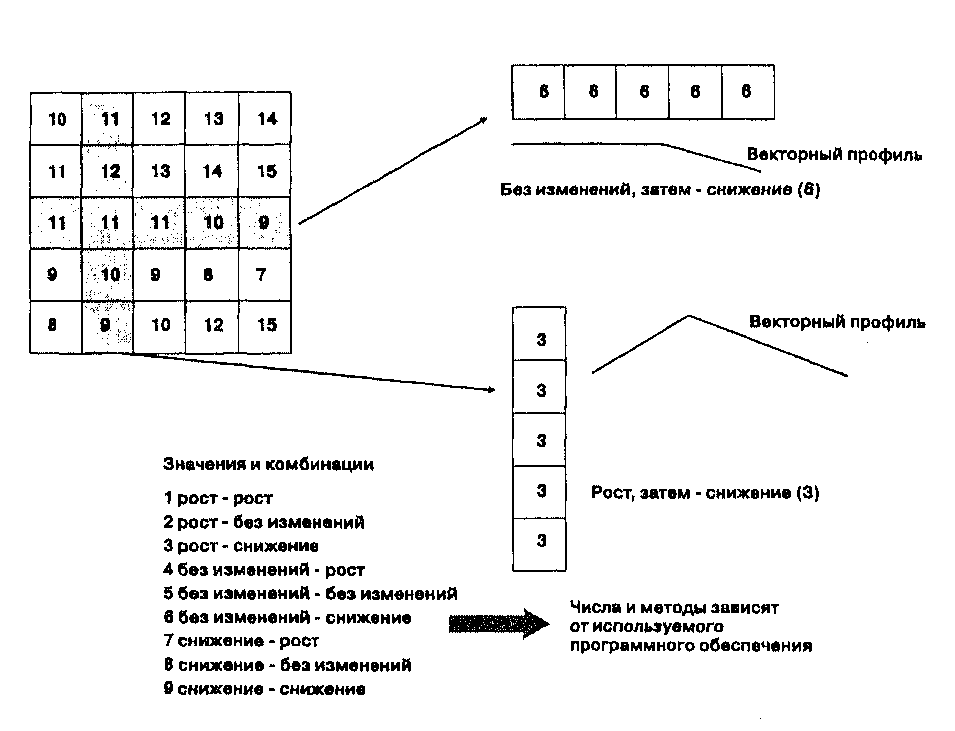 Рисунок 9.4. Описание формы поверхности в растре. Растровые и векторные результаты описания окрестности на основе формы. В векторной модели результатом является поперечный профиль, в растровой - покрытие, которое показывает отношения каждой ячейки с ее двумя непосредственными соседями, которые находятся рядом с ней по вертикали, горизонтали или диагонали. |