Майкл ДМерс ГИС. Инициаторы проведения этого новаторского события надеются привлечь к нему внимание мировой общественности и широких масс пользователей географических информационных систем из всех стран.
 Скачать 4.47 Mb. Скачать 4.47 Mb.
|

|
Глава 9 Оба варианта, растровый и векторный, используют изменения поверхностной величины, которые могут интерпретироваться пользователем для представления определенных образований. Как отдельные топографические объекты при дальнейшем анализе могут идентифицироваться горные хребты, проливы, пики, площади водосбора и т.д. Например, водосбор (watershed) определяется как вся площадь, с которой происходит сток в сеть реки. Это больше чем просто направление стока, водосборы функционируют как экологически цельные, единые регионы. Эколога, гидрологи, инженеры, эксперты по контролю наводнений и загрязнений и многие другие нуждаются в точном определении этих областей. Мы рассмотрели только простейший метод, но к этому же типу задач применяются другие, более сложные методы. По мере роста вашего мастерства, вы сами сможете узнать об этом больше [Band, 1986,1989; Douglas, 1986; White et al., 1992]. Взаимная видимость В то время как рассмотренные выше способы классификации поверхностей характеризуют всю поверхность или ее точки по отношению к соседним, рельеф может анализироваться и более сложным образом. Взаимная видимость (intervisibility) показывает, что если вы расположены в определенной точке топографической поверхности, то одни области рельефа будут вам видны (области видимости), а другие нет. Многочисленные применения этого метода включают размещение телевизионных и радиопередатчиков, ретрансляторов сотовой телефонной связи, пожарных башен, прокладку скоростных шоссе, которые не видимы для местных жителей, планирование огневых позиций артиллерии [Clarke, 1990]. Всякое планирование антропогенных объектов, которые должны быть либо хорошо видимы, либо скрыты, может быть улучшено с помощью анализа видимости. В векторной системе простейший метод состоит в соединении точки наблюдателя с каждой возможной целевой точкой покрытия. Затем выполняется трассировка лучей (ray tracing), т.е. вы следуете вдоль линии (луча), ища отметки высоты, которые выше этой линии [Clarke, 1990]. Более высокие точки будут загораживать для наблюдателя то, что за ними (Рисунок 9.5). Существуют многие способы определения областей видимости для векторных структур данных, включая TIN [DeFlorianietal., 1986; Sutherland et al., 1974]. В наши задачи не входит углубление в эти алгоритмы, поэтому мы лишь кратко рассмотрим идею анализа видимости, чтобы увидеть, что он делает и как он может быть применен. Допустим, вы планируете построить дом у подножия горной цепи и хотите видеть с крыльца как можно больше окрестностей. Вы ограничились тремя возможными местами. Для каждого из них, определенного в топографическом (terrain) покрытии ГИС (модель TIN), программа идентифицирует вершины модели во всех направлениях. Затем она выберет значения высоты для этих точек. Затем она сравнит эти высоты с высотой потенциальной строительной площадки. Все области, которые выше (и которые находятся за этими отметками), невидимы от вас и должны быть классифицированы как невидимые; все остальные области видимы. Результирующее полигональное покрытие показывает вам, какая площадь просматривается с каждой потенциальной площадки. Сравнив площади видимой части для всех трех мест, вы можете легко определить, которое вам больше подходит для строительства. 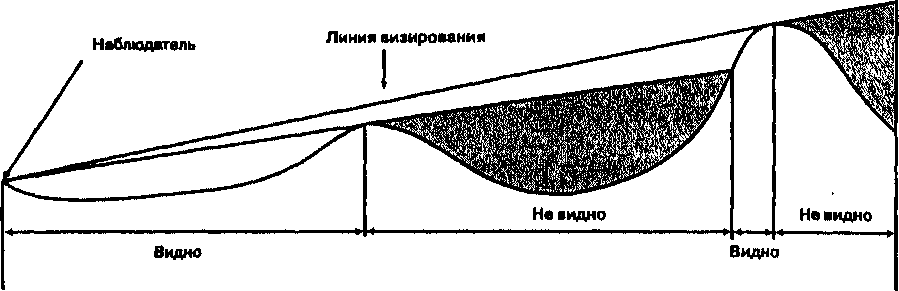 Рисунок 9.5. Анализ видимости. Трассировка лучей: линия визирования (луч) проводится от наблюдателя к каждой точке покрытия. Если на его пути оказываются другие точки выше его высоты, то целевая точка не будет видима, Растровые методы определения видимости действуют почти так же, но они менее элегантны и имеют большую вычислительную стоимость. Процесс начинается с определения ячейки наблюдателя как отдельного покрытия, с которым будет сравниваться покрытие высот. Начиная от положения ячейки наблюдателя, программа оценивает высоту во втором покрытии, которая соответствует этому местоположению. Затем она двигается по всем направлениям, по ячейке за шаг, сравнивая значения высоты каждой новой встречающейся ячейки растра с высотой ячейки наблюдателя. Каждый раз, когда встречается ячейка растра со значением высоты, большим, чем высота ячейки наблюдателя, она классифицирует ее как невидимую и присваивает соответствующий код. Если же высота этой ячейки ниже, чем наблюдателя, то ей присваивается код видимой ячейки. Это, конечно, простейший способ реализации этого метода. Существуют и другие, и каждый дает различные, но вычислительно достоверные результаты [Anderson, 1982; Dozier et al., 1981]. Имеет смысл заглянуть в документацию на вашу систему с целью оценки пригодности в вашей работе того или иного метода [Fisher, 1993]. Области видимости обычно строятся на основе только лишь топографических поверхностей, но в некоторых случаях такая поверхность может иметь лесной покров с известными высотами отдельных деревьев или их групп. Для выполнения анализа при известных высотах этих или других препятствующих объектов, они должны включаться в анализ наряду со значениями высот топографического покрытия. Они могут складываться как в векторных, так и растровых системах посредством наложения покрытий с арифметическим сложением (см. Главу 12). Там, где при определении видимости собственно топография не играет роли, высоты препятствий могут использоваться самостоятельно. Применения анализа области видимости неисчислимы, и этот метод широко распространен в анализе поверхностей. БУФЕРЫ Еще одним распространенным методом переклассификации является процесс построения буферов. Буфер (buffer) - это полигон, с границей на определенном удалении от точки, линии или границы области. 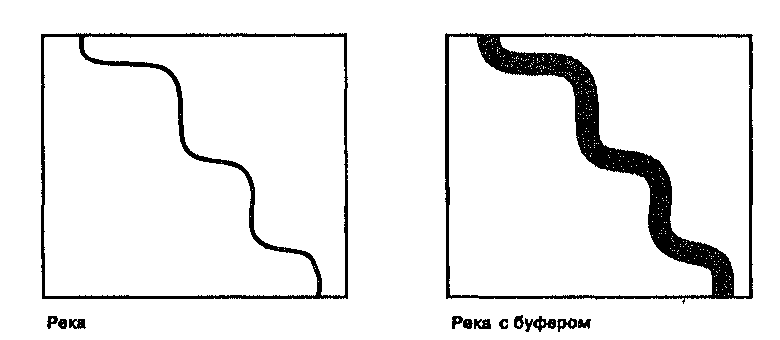 Рисунок 9.6. Буфер линейного объекта. Река и ее буфер, заданный только выбранным пользователем расстоянием. Поскольку он связан с положением, формой и ориентацией объекта, мы можем легко отнести буферизацию к методам переклассификации на основе положения. Однако, буфер может быть больше чем только отмеренное расстояние от двухмерного объекта; он может быть также связан с, и даже управляться, присутствием поверхностей трения, рельефа, барьеров, и т.д. То есть, хотя буферизация основана на положении, она имеет также и другие существенные компоненты. Область, окружающая реку, которая сообщает Классификация что-то о коридоре реки, является примером буфера. На Рисунке 9.6 буфер был создан переклассификацией области на обеих сторонах для отличия его от аморфного фона. Хотя рисунок показывает и реку, и буфер, обычно буфер создается как отдельный объект и часто хранится в отдельном покрытии. Для создания такого буфера требуется всего лишь отсчет заданного расстояния по всем направлениям от каждой точки границы выбранного объекта. Мы знаем, как ГИС выполняет измерение расстояний в растре и векторах; в действительности, создание буфера - всего лишь расширение этой процедуры. Но поскольку эта процедура весьма полезна и часто применяется, большинство ГИС имеют специальные команды для построения буферов. 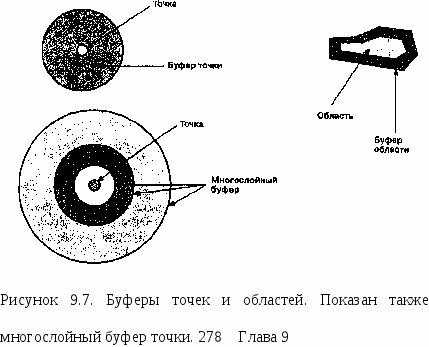 Буферизация — дело измерения расстояния от объекта, будь то точка, линия или область. В случае точки мы отмеряем одно расстояние по всем направлениям от этой точки (Рисунок 9.7). Буфер линейного объекта показан на Рисунке 9.6. Буфер площадного объекта строится на заданном расстоянии от его периметра. Может даже понадобиться построить второй буфер вокруг первого, третий — вокруг второго и т.д., которые вместе называются многослойным буфером (doughnut buffer), который также показан на Рисунке 9.7. Процедура его построения относительно проста, так как каждый новый слой буфера - всего лишь новый буфер вокруг предыдущего слоя. В векторных системах мы должны явно закодировать топологическую информацию для каждого вновь создаваемого полигона. В частности, от нас требуется предоставить топологическую информацию о связях между полигонами. Процедура многослойной буферизации пытается создать островной полигон, который не соединен явно с соседним полигоном. Трудность создания многослойного буфера в векторной системе - в основном следствие используемой модели данных, но, следуя указаниям программы, вы, как правило, можете его получить. Возможно, вам стоит поэкспериментировать на тестовой БД перед тем, как создавать многослойные буферы в реальной работе. Теперь обратимся к вопросу о величине буфера: насколько широким он должен быть? Этот вопрос часто возникает на семинарских занятиях, когда студентов просят создать буфер вокруг некоторого объекта. К сожалению, часто следует ответ: "Это не важно, вам просто нужно попробовать создать буфер". Но: как мы видели, просто создание буфера не многого стоит, если вы не знаете зачем и какой величины. В действительности, цель создания часто если не определяет размер буфера, то, по меньшей мере, влияет на него. Так какого же размера должен быть буфер? Некоторые буферы показывают, что вокруг объекта, на неизвестное, или даже не могущее быть известным, расстояние простирается регион, который требует защиты, исследования, охраны или иного особого обращения. Такой сценарий не так уж необычен, как можно подумать. Многие буферные зоны в реальном мире так же произвольны, как и те, что мы устанавливаем в наших ГИС. Строители обычно сами создают буфер вокруг стройплощадки, чтобы защитить прохожих от тяжелых машин и падающего строительного мусора. Границы областей, загрязненных ядовитыми газами, радиоактивными материалами, разливами опасных жидкостей обычно устанавливаются правительственными агентствами или правоохранительными органами. Но довольно часто эти зоны устанавливаются лишь предположительно, это произвольные буферы (arbitrary buffers). Чаще всего предположения строятся на интуиции или дилетантской информации из неизвестных источников. Однако, все они, как правило, больше, чем необходимо. Лишняя площадь буфера, часто так мешающая населению, обычно добавляется к произвольному буферу для безопасности. Размеры буфера могут также основываться на любой процедуре измерения или переклассификации, которые нам до сих пор встречались, будь они двухмерные или трехмерные. Например, мы могли бы создать другой тип буфера, основанного на функциональном, а не евклидовом расстоянии от объекта. Это был бы мотивированный буфер (causative buffer) - основанный на априорном знании площади буфера. Допустим, например, что мы создаем буфер вдоль реки, чтобы показать возможность загрязнения почвы по обеим ее сторонам. И мы знаем, что с одной стороны реки почва -глинистая, в то время как на другой - песчаная. Поскольку загрязняющие вещества проникают через песок быстрее, чем через глину, буфер должен строиться на основе фрикционных или импедансных свойств (frictional or impedance quality) глинистой почвы. В результате буфер будет менее широким со стороны глины, нежели со стороны песка, отражая различия в проницаемости почв разных типов. Использование фрикционных поверхностей и барьеров - обычная практика при построении буферов, так как они дают некоторое основание для выбора размера буфера. Однако, поскольку точное определение величины фрикционного или барьерного импеданса часто затруднительно, буфер, построенный на основе этой величины, может оказаться не более полезным, чем произвольный буфер, построенный из простых соображений. Буфер может также быть основанным на мерах взаимной видимости. В таком случае буфер выбирается не на основе произвольной или плохо известной фрикционной величины, а на основе определенной, измеримой величины, это - измеримый буфер (measurable buffer). Это третий тип буферов, который мы можем использовать. Измерения - не произвольны, а весьма точны, так как основаны на измеримых феноменах. Конечно, всегда есть возможность комбинирования второго и третьего методов буферизации, полагаясь на измеримый феномен, чье влияние на размер буферной области трудно четко определить. Например, мы знаем, что деревья вдоль речного коридора могут играть роль фильтра от загрязняющих материалов. Мы также знаем, что чем больше деревьев, тем лучше фильтрация. Поэтому, мы можем измерить плотность растительности вдоль речного коридора и затем использовать эти значения для создания поверхности импеданса, а уже ее использовать для определения размера буфера. Но при этом мы не имеем точного знания о том, как плотность деревьев связана с движением загрязнителя через растительность в реку. Таким образом, у нас есть некоторые измеримые параметры, и они могут быть логично применены; но при этом мы не знаем точных отношений между ними. Такое часто случается при построении буферов. Существует еще четвертый вид буферов - нормативный (mandated buffer), когда буферизация определяется нормативными актами. Например, если вы строите дом в пределах столетней зоны наводнений, то, скорее всего не сможете приобрести страховку от наводнений. Хотя размер этой зоны -измеримая величина, страховая компания могла бы так же легко избрать 75-летнюю зону или 150-летнюю. Другими словами, сама величина измерима, но выбор ее среди других измеримых величин произволен. Для создания буфера подобного рода обычно нужна БД местности и возможность рассчитать объем воды, который заполнил бы пойму, если бы действительно случилось наводнение такого масштаба, который вряд ли имеет место более одного раза в столетие. Но могут применяться и другие нормативные буферы. Нам говорят, насколько близко к пожарному гидранту мы можем парковать машину, и какая часть палисадника в действительности принадлежит местному сообществу. Строительные нормы указывают расстояния вокруг объектов коммунальных служб и между зданиями; природоохранные организации создают защитные полосы; вдоль железных дорог и линий электропередачи по закону устанавливаются буферы отчуждения, и т.д. В каждом случае есть нормативное основание для создания буфера определенного размера. 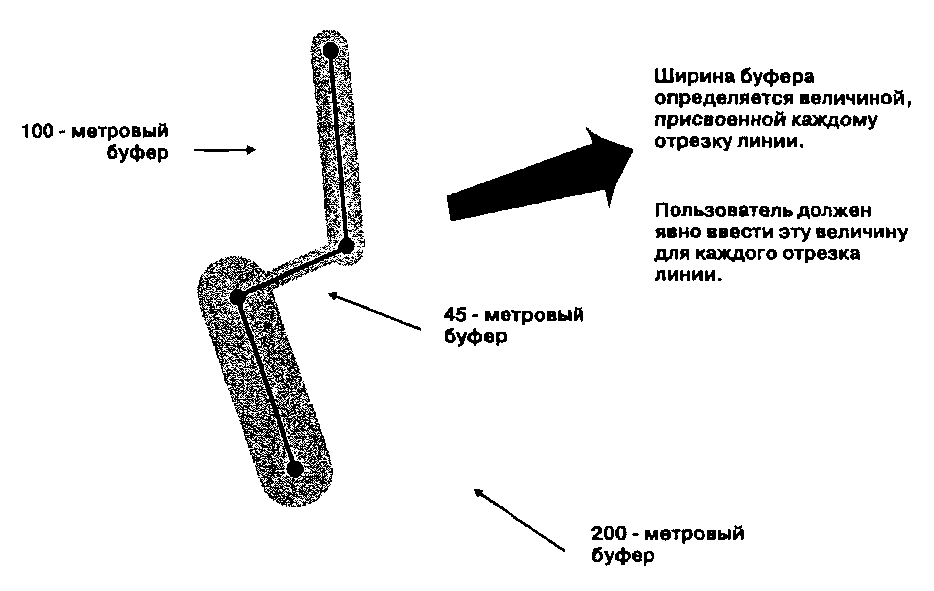 Рисунок 9.8. Варьируемый буфер. Такие буферы создаются с помощью различных значений импеданса с каждой стороны линии или указанием своей ширины буфера для каждого отрезка линии. Во втором случае каждый отрезок должен иметь идентифицирующие узлы на каждом конце (в векторной системе); или для каждого набора образующих объект ячеек растра должно отмеряться свое расстояние до границы буфера (в растровой системе). Независимо от типа буфера (произвольный, мотивированный, измеримый или нормативный) всегда есть вероятность того, что буфер не будет иметь одинаковую ширину вдоль всего линейного объекта или со всех сторон полигона. Такие различия, проиллюстрированные нашим примером Классификация буфера разной ширины вдоль реки в зависимости от типа почвы, создают класс буферов, называемых варьируемыми (variable buffers) (Рисунок 9.8). Варьируемый буфер может определяться импедансом, барьерами или любой другой функцией окрестности. Он может выбираться произвольно, на основе измеримого параметра ландшафта, или устанавливаться законом. В каждом случае при создании буфера должны выполняться специальные процедуры. В векторной модели данных узлы между отрезками линии чаще всего могут использоваться для установления различий буфера вдоль линии. В растре ячейки должны выборочно кодироваться, чтобы можно было устанавливать буфер для каждой группы ячеек; чаще всего эти буферы позднее объединяются в отдельное буферное покрытие. Буферы полезны для классификации ландшафта и являются обычной составной частью многих случаев анализа в ГИС. Основная проблема с буферами состоит в том, что они часто требуют от нас больше знаний о взаимодействии элементов нашего ландшафта, чем мы имеем. Вы всегда должны пытаться преодолеть это препятствие поиском всех возможных знаний о каждой ситуации перед тем, как двигаться дальше. Чем больше вы знаете, тем более надежен ваш выбор определенной ширины буфера. Если же у вас недостаточно сведений для выбора размера буфера, то лучше сделать его с запасом. Вопросы
буфер? Как он строится в растре? Как - в векторной системе? В каких случаях его можно использовать? 19. Опишите четыре основных метода определения ширины буфера. |