курсовая работа измерение и кодирование информации. курсова Ермоченко. Измерение и кодирование информации
 Скачать 150.63 Kb. Скачать 150.63 Kb.
|

Содержание обучения по теме “Измерение и кодирование информации ” на профильном уровне изучения информатики в школеСодержание обучения по теме «Измерение и кодирование информации» на профильном уровне изучения информатики в школе было проанализировано на основе учебника К.Ю. Полякова, Е.А. Еремина «Информатика» 10, 11 класс углубленный уровень. Объемный подход к измерению информации Что такое бит? Рассмотрим электрическую лампочку, она может находиться в двух состояниях: «горит» и «не горит». Тогда на вопрос «Горит ли сейчас лампочка» есть два возможных ответа, которые можно обозначить цифрами 1 («горит») и 0(«не горит»). Поэтому ответ на этот вопрос ( полученная информация) может быть записана как 0 или 1. Цифры 0 и 1 называют двоичными, и с этим связано название единицы измерения количества информации – бит. Бит – это количество информации, которую можно записать (закодировать) с помощью одной двоичной цифры. Представим себе, что на вокзале стоит 4 одинаковых поезда, причем только один из них проследует в Москву. Сколько битов понадобиться для того, чтобы записать информацию о номера платформы, где стоит поезд на Москву? Очевидно, что одного бита будет недостаточно, так как с помощью одной двоичной цифры можно закодировать только два варианта – коды 0 и 1. А вот 2 бита, дают как раз 4 разных сообщения: 00, 01, 10 и 11. Теперь нужно сопоставить эти коды номерам платформ, например, так: 1-00, 2-01, 3-10, 4-11. Тогда сообщение 10 говорит о том, что поезд на Москву стоит на платформе №3. Это сообщение несет 2 бита информации. Три бита дают уже 8 вариантов: 000, 001, 010, 100, 101, 110 и 111. Таким образом, каждый бит, добавленный в сообщение, увеличивает количество вариантов в 2 раза ( см. таб. 1). Таблица 1
Число вариантов можно найти так же по формуле: 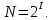 Осталось выяснить, чему равно количество информации, если выбор делается, скажем, из 5 возможных вариантов ( или из любого количества, не являющегося степенью числа 2). С точки зрения приведенного выше рассуждения случаи выбора из 5, 6, 7 и 8 вариантов не различаются – для кодирования двух двоичных цифр мало, а трех – достаточно. Поэтому использование трех битов для кодирования одного из 5 возможных вариантов избыточно, ведь три бита позволяют закодировать целых 8 вариантов. Значит, выбор из 5 вариантов дает меньше трех битов информации. Другие единицы Считать большие объемы информации в битах неудобно хотя бы потому, что придется работать с очень большими числами. Поэтому стоит ввести более крупные единицы. 1 байт=8 битов. Объемы данных, с которыми работают компьютеры, нередко измеряются миллионами и миллиардами байтов. В таких случаях используются единицы, образованные с помощью приставок: 1 Кбайт (килобайт) =1024 байта = 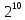 байта = байта = 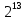 битов. битов.1 Мбайт (мегабайт) = 1024 Кбайт = Кбайт = 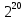 байтов = байтов =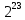 битов. битов.1 Гбайт (гигабайт) = 1024 Мбайт. 1 Тбайт (терабайт) = 1024 Гбайт. Для перевода количества информации из одной единицы в другую нужно использовать приведенные ниже соотношения. При переводе из крупных единиц в мелкие числа умножают на соотношение между единицами. Например: 2 Кбайт = 2∙(1 Кбайт) = 2∙1024 байтов = 2048 байтов = 2048∙(1 байт) = 2048∙8 битов = 16384 бита. 2 Кбайт = 2∙ байтов = 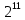 байтов = байтов = 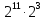 битов = битов = 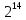 битов. битов.При переводе количества информации из мелких единиц в крупные нужно делить на соотношение между единицами. Например: 8192 бита = 8192∙(1/8 байта) = 8192:8 байтов = 1024 байта = 1024∙(1/1024 Кбайт) = 1024:1024 Кбайт = 1 Кбайт 8192 бита = битов = 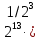 байта) = байтов = байта) = байтов = 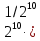 Кбайт) = 1 Кбайт. Кбайт) = 1 Кбайт.Кодирование и измерение текстовой, графической и звуковой информации Кодировка ASCII и ее расширения Для того чтобы упростить передачу текстовой информации, разработаны стандарты, которые закрепляют определенные коды за общеупотребительными символами. Основным международным стандартом является 7-битная кодировка ASCII, в которой входят 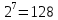 символов с кодами от 0 до 127; символов с кодами от 0 до 127;служебные символы с кодами от 0 до 31; символ «пробел» с кодом 32; цифры от «0» до «9» с кодами от 48 до 57; латинские буквы: заглавные, от «А» до «Z» ( с кодами от 65 до 90) и строчные, от «а» до «z» (с кодами от 97 до 122); знаки препинания: . , : ; ! ? скобки: {} [] (); математические символы: + - * / = < >; некоторые другие знаки: “ ‘ # $ % & ^ @ | \ _ В современных компьютерах минимальная единица памяти, имеющая собственный адрес – это байт (8 битов). Поэтому для хранения кодов ASCII в памяти можно добавить к нему еще один (старший) нулевой бит, таким образом, получая 8-битную кодировку. Кроме того, дополнительный бит можно использовать: он дает возможность добавить в таблицу еще 128 символов с кодами от 128 до 255. Такое расширение ASCII часто называют кодовой страницей. Первую половину кодовой страницы (коды от 0 до 1270 занимает стандартная таблица ASCII, а вторую – символы национальных алфавитов ( например, русские буквы). Для русского языка существуют несколько страниц, которые были разработаны для разных операционных систем. Наиболее известные: кодовая страница Windows-1251 (CP-1251) – в системе Windows; кодовая страница К018-R – в системе Unix; альтернативная кодировка (CP-866) – в системе MS DOS; кодовая страница MacCyrillic – на компьютерах фирмы Apple (Макинтош и др). Проблема состоит в том, что если набрать русский текс в одной кодировки, а просматривать в другой, текст будет невозможно прочитать. Стандарт UNICODE Любая 8-битная кодовая страница имеет серьезное ограничение – она может включать только 256 символов. Поэтому не получается надрать в одном документе часть текста на русском, а часть текста - на китайском. Кроме того, существует проблема чтения документов, набранных с использованием другой кодовой страницы. Все это привело к принятию нового стандарта кодирования символов – UNICODE. В системе Windows используется кодировка UNICODE, называемая UTF-16. В нем все наиболее важные символы кодируются с помощью 16 битов (2 байтов), а редко используемые – с помощью 4 байтов. В UNIX- подобных системах, например Linux, чаще применяется кодировка UTF- 8. В ней все символы, входящие в таблицу ASCII. Кодируются в виде 1 байта, а другие символы могут занимать от 2 до 4 байтов. Кодировки стандарта UNICODE позволяют использовать символы разных языков в одном документе. За это приходиться «расплачиваться» увеличением объема файлов. Кодирование графической информации Растровое кодирование Рисунок состоит из линий и закрашенных областей. И линии и области состоят из бесконечного числа точек. Цвет каждой из них нужно закодировать. Если их бесконечно много, то для этого нужно бесконечно много памяти. Поэтому «поточечным» способом изображение закодировать не удастся. Начнем с черно-белого рисунка. Представим себе, что на изображение ромба наложена сетка, которая разбивает его на квадраты. Такая сетка называется растром. Теперь для каждого квадрата определяется цвет (черный или белый). Для тех квадратов, в которых часть оказалась закрашена черным цветом, а часть – белым, выбирается цвет в зависимости от того, какая часть (черная или белая) больше. Получается так называемый растровый рисунок, состоящий из квадратиков-пикселей. Пиксель-это наименьший элемент рисунка, для которого можно независимым образом задать. Двоичный код для черно-белого изображения, полученного в результате дискретизации, можно построить следующим образом: белые пикселя заменяются на нули, а черные – единицами; выписываются строки таблицы одна за другой. При кодировании изображения в двоичном коде, чаще всего рисунок искажается. Причина искажения в том, что в некоторых квадратиках части исходного рисунка были закрашены разными цветами, а в закодированном изображении каждый пиксель обязательно имеет один цвет. Таким образом, часть исходной информации при кодировании была потеряна. Это наглядно видно, например, при увеличении рисунка – квадратики увеличатся, и рисунок еще больше исказиться. Чтобы уменьшить потери информации, нужно уменьшать размер пикселя, т.е. уменьшит разрешение. Разрешение – это количество пикселе, приходящихся на единицу линейного размера изображения. Разрешение обычно измеряется в пикселях на дюйм (ppi). Например, разрешение 254 ppi означает, что на дюйм (25,4 мм) приходиться 254 пикселя. Если привести дискретизацию рисунка размером 10х15 см с разрешением 254 ppi, высота закодированного изображения будет 100/0,1=1000 пикселей, а ширина – 1500 пикселей. Чем больше разрешение. Тем точнее кодируется рисунок, однако одновременно растет и объем файла. Кодирование цвета Человек воспринимает свет как множество электромагнитных волн. Определенная длина волны соответствует некоторому цвету. Например, волны длиной 55-565нм – это зеленый цвет. Так называемый «белый» свет на самом деле представляет собой смесь волн, длины которых охватывают весь видимый диапазон. Согласно современному представлению о цветном зрении, глаз человека содержит чувствительные элементы трех типов. Каждый из них воспринимает весь поток света, но первые наиболее чувствительные в области красного цвета, вторые – в область зеленого цвета, третьи – в область синего цвета. Цвет – это результат возбуждения всех трех типов рецепторов. Поэтому считается, что любой цвет можно имитировать, использую только три световых луча разной яркости. Следовательно, любой цвет приближенно раскладывается на три составляющих – красную, зеленую и синюю. Меняя силу этих составляющих, можно составить любой цвет. Эта модель цвета получила название RGB. В модели RGB яркость каждой составляющей чаще всего кодируется целым числом от 0 до 255. При этом код цвета – это тройка чисел – яркости отдельных каналов. Цвет (0, 0, 0) – это черный цвет, а (255, 255, 255) – белый. Что бы сделать светло-красный цвет, нужно при максимальной яркости красного цвета (255, 0, 0) одинаково увеличить яркость зеленого и синего каналов, то получиться розовый. Глубина цвета – это количество битов, используемое для кодирования цвета пикселя. Очень часто количество цветов в изображении невелико ( не более 256). В этом случае применяют кодирование с палитрой. Цветовая палитра – это таблица, в которой каждому цвету, заданному в виде составляющих в модели RGB, сопоставляется числовой код. Кодирование с палитрой выполняется следующим образом: выбирается количество цветов N (как правило не больше 256); из палитры исходного цвета ( 16 777 216 цветов) выбираются любые N цветов и для каждого из них находятся составляющие в модели RGB; каждому из выбранных цветов присваивается номер ( код) от 0 до N-1; составляется палитра: сначала записываются RGB-составляющие цвета, имеющего код 0, затем – составляющие цвета с кодом 1 и т.д; цвет каждого пикселя кодируется не в виде значений RGB-составляющих, а как номер цвета в палитре. Код каждого пикселя занимает всего два бита. Чтобы примерно оценить информационный объем рисунка с палитрой, включающей N цветов, нужно: определить размер палитры: 3∙N байтов, или 24∙N битов; определить глубину цвета (количество битов на пиксель), т.е. найти наименьшее натуральное число k, такое что 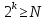 ; ;вычислить общее количество пикселей М, перемножив размеры рисунка; определить информационный объем рисунка ( без учета палитры): М∙k битов. Форматы растрового файла: BMP JPEG GIF PNG Векторное кодирование Для чертежей, схем, карт применяется другой способ кодирование, который позволяет не терять качество при изменении размеров изображения. Рисунок строиться из простейших геометрических фигур (графических примитивов). Такой рисунок называется векторным. Векторный рисунок – это рисунок, построенный из простейших геометрических фигур, параметры которых хранятся в виде чисел. Векторный рисунок можно разобрать на части, растащив мышью его элементы, а потом снова собрать полное изображение. При векторном кодировании для отрезка хранятся координаты его конца, для прямоугольников и ломанных – координаты вершин. Окружность и эллипс можно задать координатами прямоугольника, в который вписана фигура. Векторный рисунок можно рассматривать как программу, в соответствии с которой строиться изображение на конкретном устройстве вывода, с учетом особенностей этого устройства. Среди форматов векторного рисунка отмечают следующие: WMF CDR AL SVG Кодирование звуковой и видеоинформации Оцифровка звука Звук – это колебания среды, которые воспринимает человеческое ухо. С помощью микрофона звук преобразуется в аналоговый электрический сигнал. Современные компьютеры обрабатывают только дискретные сигналы (двоичные коды). Поэтому для работы со звуком необходима звуковая карта – специальное устройство, которое преобразует аналоговый сигнал, полученный с микрофона, в двоичный код, т.е. в цепочку нулей и единиц. Это процедура называется оцифровкой. Оцифровка – это преобразование аналогово сигнала в цифровой код. Число Т называется интервалом дискретизации, а обратная ему величина 1/Т – частотой дискретизации. Частота дискретизации обозначается буквой f и измеряется в герцах (Гц) и килогерцах (кГц). Один герц – это один отсчет в секунду, а 1 кГц – 1000 отсчетов в секунду. Чем больше частота дискретизации, тем точнее мы записываем сигнал, тем меньше информации теряется. Для кодирования звука в компьютере чаще всего используются частоты дискретизации 8 кГц, 11 кГц, 22 кГц, 44,1 кГц, 48 кГц, а так же 96 кГц и 192 кГц. Выбранная частота влияет на качество цифрового звука. Для повышения качества звука, т.е. для большего соответствия между сигналом, принятым микрофоном, и сигналом, выведенным из компьютера на колонки, нужно увеличить частоту дискретизации, однако при этом, увеличивается объем файла. Кроме того что при кодировании звука выполняет дискретизация с потерей информации, нужно учитывать, что на хранение одного отчета в памяти отводиться ограниченное место. При этом вносятся дополнительные ошибки. Преобразование измеренного значения сигнала в целое число называется дискретизацией по уровню или квантованием. Эту операцию выполняет аналого-цифровой преобразователь – специальный блок звуковой карты. Разрядность кодирования – это число битов, используемое для хранения одного отсчета. Среди форматов оцифрованных звуковых файлов наиболее известны: WAV; MP3; WMA; Ogg Vorbis. Все эти форматы являются потоковыми, т.е. можно начинать прослушивание до того момента, как весь файл будет получен. Инструментальное кодирование звука Существует еще один, принципиально иной способ кодирования звука, который можно применить только для кодирования инструментальных мелодий. Он основан на стандарте MIDI. В отличии от оцифрованного звука в таком формате хранятся последовательность нот, коды инструментов, громкость, тембр, время затухания каждой ноты и т.д. Для проигрывания MIDI-файлов использую синтезаторы – электронные устройства, имитирующие звук реальных инструментов. Простейшим синтезатором является звуковая карта компьютера. Кодирование видеоинформации Для того чтобы сохранить видео в памяти компьютера, нужно закодировать звук и изменяющееся изображение, причем требуется обеспечить их синхронность. Для кодирования звука чаще всего используется оцифровка с частотой 48 кГц. Изображение состоит из отдельных растровых рисунков, которые меняются с частотой не менее 25 кадров в секунду, так что глаз человека воспринимает смену кадров как непрерывное движение. Это значит, что для каждой секунды видео нужно хранить в памяти 25 изображений. В последнее время часто используется формат видео высокой четкости – HD – 1280х720 точек и 1920х1080 точек, предназначенные для просмотра на широкоформатных экранах с соотношением сторон 16:9. Наиболее известны следующие видеоформаты: AVI; WMV; MPEG; MP4; MOV; WebM. Вероятностный подход к измерению информации В 1928 г. Американский инженер Ральф Хартли предложил формулу для расчета количества информации, если количество вариантов не равно степени числа 2. 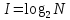 Нужно обратить внимание, что для значений N, которое не равны целой степени числа 2, количество информации в битах – дробное число. С помощью формулы Хартли можно вычислить теоретическое количество информации в сообщении. Предположим, что алфавит включает 50 символов. Тогда информация при получении каждого символа составляет 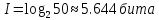 Если сообщение содержит 100 символов, его общий информационный объем примерно равен 5,644∙100=564,4 бита. Такой подход к определению количества информации называют алфавитным. Вероятность событий можно определить с помощью большого количества испытаний. Если из N испытаний нужное нам событие случилось m раз, то вероятность такого события можно оценить как 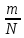 . . Если информация имеет вероятность p, то количество информации в битах, полученное в сообщении об этом событии, равно 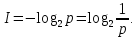 Формулу Хартли нельзя использовать, если вероятности событий разные. Информация играет для нас важную роль потому, что наше знание всего неполно, в нем есть неопределенность. Эта неопределенность мешает нам решать свои задачи, принимать правильные решения. Полученная информация уменьшает неопределенность, полностью или частично. Поэтому количество информации можно оценить по величине уменьшения неопределённости: 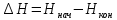 где 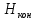 – начальная неопределенность, а – конечная. Если неопределенность полностью снимается, то – начальная неопределенность, а – конечная. Если неопределенность полностью снимается, то 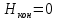 . .Чтобы оценить информацию с этой точки зрения, нужно как –то вычислить неопределенность, выразить ее числом. Эту задачу решил Клод Шеннон. Пусть неопределенность состоит в том, что мы можем получить одно из N возможных сообщений, причем известно, что вероятность получения сообщения с номером i равна 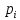 . .Неопределенность знания об источнике данных вычисляется по формуле Шеннона 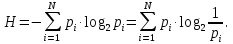 Величина H часто называется информационной энтропией. С точки зрения математики это среднее количество информации, которую мы получаем при полном снятии неопределенности. Неопределенность наибольшая для случая, когда все события равновероятны. При этом вероятность каждого из N событий равна 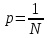 , поэтому по формуле Шеннона , поэтому по формуле Шеннона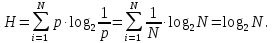 Отсюда следует, что при равновероятных событиях неопределенность совпадает с количеством информации, вычисленной по формуле Хартли. Дидактические единицы и последовательность их изучения Таблица 2
|