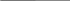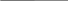Методичка проектирования. Методичка Проектирование (бакалавриат) 1 часть. Лабораторная работа 1 Создание контекстной диаграммы
 Скачать 1.03 Mb. Скачать 1.03 Mb.
|

Задание на лабораторную работу №6Создайте две диаграммы IDEF 3, как декомпозиции любых двух процессов, согласно шагам, описанным выше. На каждой диаграмме должно быть не менее 4 перекрестков. Лабораторная работа №7 Создание диаграммы DFD Цель работыПолучение студентом основных сведений о принципах построения и сущности диаграмм DFD; получение практических навыков работы с ними в BPwin. Диаграммы потоков данных (DFD – Data Flow Diagram) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами. Диаграммы потоков данных известны очень давно. В фольклоре упоминается следующий пример использования DFD для реорганизации переполненного клерками офиса, относящийся к 20-м годам. Осуществлявший реорганизацию консультант обозначил кружком каждого клерка, а стрелкой – каждый документ, передаваемый между ними. Используя такую диаграмму, он предложил схему реорганизации, в соответствии с которой двое клерков, обменивающиеся множеством документов, были посажены рядом, а клерки с малым взаимодействием были посажены на большом расстоянии. Так родилась первая модель, представляющая собой потоковую диаграмму – предвестника DFD. Для изображения DFD традиционно используются две различные нотации: Йодана (Yourdon) и Гейна-Сарсона (Gane-Sarson). Далее при построении примеров будет использоваться нотация Йодана, все исключения будут предварительно оговариваться. Основные символы DFD изображены на Рисунке 4. Опишем их назначение. На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных.
Рисунок 4 -Основные символы диаграммы потоков данных Потоки данных являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации. Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним - двунаправленным. Назначение процесса состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, «вычислить максимальную высоту»). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели. Хранилище (накопитель) данных позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет «срезы» потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме. Несмотря на это, рекомендуется всегда указывать имена потоков на диаграмме. Внешняя сущность (терминатор) представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, склад товаров. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке. Контекстная диаграмма и детализация процессов Декомпозиция DFD осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD нижнего уровня. Важную специфическую роль в модели играет специальный вид DFD - контекстная диаграмма, моделирующая систему наиболее общим образом. Контекстная диаграмма отражает интерфейс системы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель или природу системы насколько это возможно. И хотя контекстная диаграмма выглядит тривиальной, несомненная ее полезность заключается в том, что она устанавливает границы анализируемой системы. Каждый проект должен иметь ровно одну контекстную диаграмму, при этом нет необходимости в нумерации единственного ее процесса. DFD первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме. Построенная диаграмма первого уровня также имеет множество процессов, которые в свою очередь могут быть декомпозированы в DFD нижнего уровня. Таким образом строится иерархия DFD с контекстной диаграммой в корне дерева. Этот процесс декомпозиции продолжается до тех пор, пока процессы могут быть эффективно описаны с помощью коротких (до одной страницы) миниспецификаций обработки (спецификаций процессов). При таком построении иерархии DFD каждый процесс более низкого уровня необходимо соотнести с процессом верхнего уровня. Обычно для этой цели используются структурированные номера процессов. Так, например, если мы детализируем процесс номер 2 на диаграмме первого уровня, раскрывая его с помощью DFD, содержащей три процесса, то их номера будут иметь следующий вид: 2.1, 2.2 и 2.3. При необходимости можно перейти на следующий уровень, т.е. для процесса 2.2 получим 2.2.1, 2.2.2. и т.д. Рекомендации по построению диаграмм потоков данных. Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями: 1. Размещать на каждой диаграмме от 3 до 6-7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса. 2. Не загромождать диаграммы несущественными на данном уровне деталями. 3. Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов; эти две работы должны выполняться одновременно, а не одна после завершения другой. 4. Выбирать ясные, отражающие суть дела, имена процессов и потоков для улучшения понимаемости диаграмм, при этом стараться не использовать аббревиатуры. 5. Однократно определять функционально идентичные процессы на самом верхнем уровне, где такой процесс необходим, и ссылаться на него на нижних уровнях. 6. Пользоваться простейшими диаграммными техниками: если что-либо возможно описать с помощью DFD, то это и необходимо делать, а не использовать для описания более сложные объекты. 7. Отделять управляющие структуры от обрабатывающих структур (т.е. процессов), локализовать управляющие структуры. Пример построения DFD диаграммы. В данном примере рассмотрим модель потоков данных на примере деятельности хлебобулочной пекарни. Предполагается, что студенты знакомы с функциональным моделированием (IDEF0) и моделированием бизнес-процессов (IDEF3). Хлебобулочная пекарня работает по следующему принципу: клиенты заказывают продукцию, заказы оформляются и хранятся до тех пор, пока клиент не получит готовую продукцию. Клиенту отписывается счет, после оплаты которого заказ становится действительным. Компоненты на изготовление продукции поступают со склада. Вся продукция (тесто и выпечка) проходит тестирование на качество – информация об этом тоже будет сохраняться. Для создания новой DFD модели необходимо выбрать пункт меню File New, а в открывшемся окне выбрать тип модели (Type) Data Flow (DFD), ввести наименование модели и нажать OK. В открывшемся при этом окне указать фамилию автора-составителя модели и его инициалы. Значения всех остальных параметров можно оставить по умолчанию. 1. Построим контекстную диаграмму системы. Для этого изобразим основную функцию рассматриваемой системы и внешние по отношению к ней сущности, а также взаимосвязи между внешними сущностями и функцией системы. Контекстная диаграмма будет выглядеть следующим образом (рисунок 5). Здесь сущность Склад является внешней по отношению к системе, т.к. рассматриваемая система не выполняет складских операций. Таким образом она лишь получает необходимую для работы информацию от Склада. Клиенты делают заказы на хлебобулочную продукцию и получают хлебобулочную продукцию, что изображено в виде стрелок с соответствующими наименованиями. Двунаправленная стрелка «счета, статусы, запросы» в данном случае указывает на то, что клиент получает информацию о счетах и статусах своих заказов, и может передавать в систему информацию о запросах (тех же статусов заказов).  Рисунок 5 - Контекстная DFD деятельности хлебобулочной пекарни При создании модели в BPWin существует возможность изменения отображения элементов модели (стрелок, прямоугольников, надписей). Для изменения параметров элемента необходимо щелкнуть по нему правой кнопкой мыши и в открывшемся списке выбрать опцию Style (для стрелок) или Box Style (для остальных элементов). 2. После создания контекстной диаграммы, постараемся рассмотреть функции системы более подробно и построить в результате диаграмму детализации первого уровня. Для создания диаграммы детализации необходимо щелкнуть правой кнопкой мыши по наименованию декомпозируемой диаграммы (в нашем случае – Деятельность хлебобулочной пекарни) в окне Проводник модели (Model Explorer) и выбрать пункт Декомпозировать (Decompose) в контекстном меню. В открывшемся окне Activity Box Count указать количество работ, размещаемых на диаграмме декомпозиции (в дальнейшем это число можно изменить) и тип диаграммы (в нашем случае – DFD). Нажать OK. Как мы увидим, здесь уже будут стрелки с надписями «Заказы», «Счета, статусы, запросы», «Хлебобулочная продукция» и «Компоненты». И это нормально – мы ведь рассматриваем детализацию контекстной диаграммы, а точнее функции «Деятельность хлебобулочной пекарни», в которую входили и из которой выходили все вышеперечисленные стрелки. Диаграмма детализации создается для более подробного, конкретизированного рассмотрения деятельности системы, а именно: расписывается подробная структура деятельности пекарни. Разместим хранилище заказов («Заказы»), хранилище счетов («Счета»), хранилище «Брак» и «Клиенты». Все хранилища в нашем случае представляют собой базы данных, в которые заносится информация о заказах («Заказы»), о состоянии счета клиента («Счета»), о браке выпускаемой продукции («Брак»), о клиентах («Клиенты»). Также на этой диаграмме разместим функции «Обработка заказов», «Отгрузка», «Приготовление хлебобулочной продукции», «Прием оплаты». Весь поток данных от функции к функции, от функции к хранилищу и от хранилища к функции обозначен стрелками с соответствующими надписями. Диаграмма детализации первого уровня будет выглядеть следующим образом – Рисунок 6. Следует обратить внимание на то, что несмотря на наличие на контекстной диаграмме сущности Клиенты, диаграмма детализации содержит хранилище Клиенты. Это связано с тем, чтобы явно показать необходимость использования информации о клиентах в функциях системы, создав для этого хранилище данных. Если бы этого создано не было, информация о клиентах все равно использовалась бы в работе функций системы, однако это не было бы так наглядно изображено на диаграмме. В практике построения DFD диаграмм всегда рекомендуется использовать подобный прием кроме самых очевидных ситуаций.  Рисунок 6 – Диаграмма детализации первого уровня «Деятельность хлебобулочной пекарни» Задание на лабораторную работу №7Декомпозируйте любые два из процессов в виде диаграммы DFD. На каждой диаграмме DFD должно быть не менее 2 внешних сущностей, не менее 4 хранилищ данных и не менее 4 процессов. |