математическое моделирование. Т 1 МАТ. Моделирование. Литература по теме 197 Вопрос Узловые операторы. 201 Вопрос Текст программной модели смо. 202 Вопрос Сборка и запуск исполнительного модуля модели. 205
 Скачать 1.51 Mb. Скачать 1.51 Mb.
|

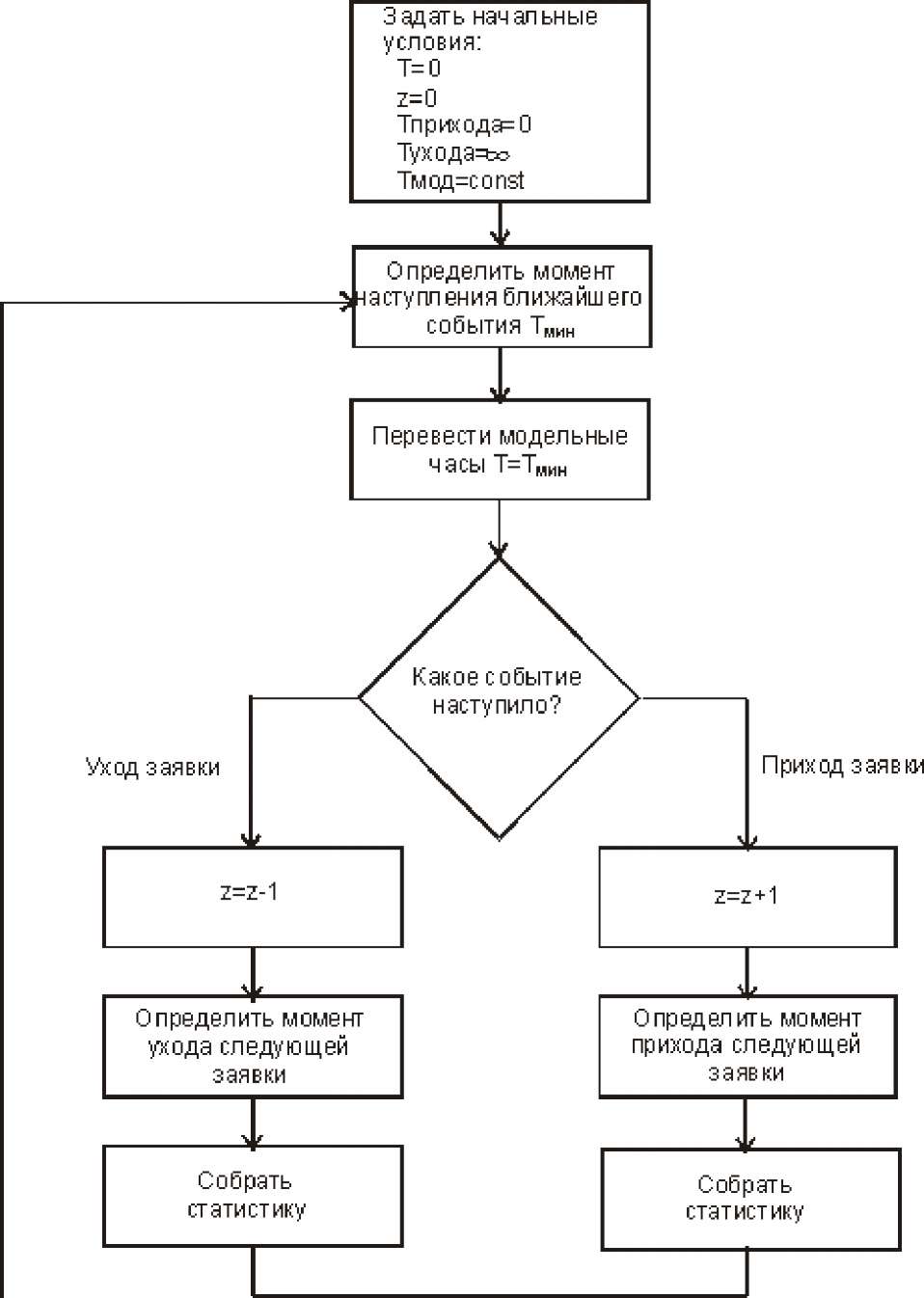
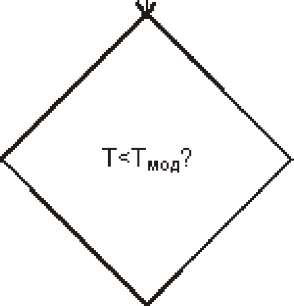
Тема 8. Основы имитационного моделированияизучить сущность имитационного моделирования систем и процессов. изучить принципы построения имитационных моделей; изучить способы имитации случайных величин и событий; изучить методы обработки результатов имитационного моделирования. когда применяется и как реализуются имитационные модели; как имитируется в программной модели параллельное протекание реальных процессов; способах преобразования описаний в исполнительные компьютерные программы; какие алгоритмы используются для имитации случайных величин с заданным законом распределения; как реализуется имитация в программе случайного события с заданной вероятностью; как найти математическое ожидание и дисперсию показателя на основе полученных с помощью модели данных. Концепции имитационного моделирования. Имитация случайных величин с заданными законами распределения. Обработка результатов запусков программной модели. находится момент наступления ближайшего события, событие с минимальным временем — наиболее раннее событие; стрелки модельных часов передвигаются на этот момент времени; определяется тип происшедшего события; в зависимости от типа события модифицируются значения переменных, описывающих состояние системы (в данном случае, число находящихся в системе заявок), и определяются следующие моменты наступления событий. Рис. 23. Блок-схема имитации работы одноканальной СМО с очередью В процессе выполнения алгоритма производится накопление значений существенных параметров моделируемой системы. По окончании моделирования осуществляется статистическая обработка полученных величин и выдача результатов. Описанный алгоритм носит название событийного алгоритма. Альтернативным способом построения алгоритма имитационного моделирования является перемещение по временной оси с фиксированным интервалом (шагом). После каждого перехода на новую временную отметку проводится сканирование всех протекающих в моделируемой системе процессов и выявление всех свершившихся на данный момент существенных событий. Такой алгоритм носит название пошагового алгоритма. Преимуществом пошагового алгоритма является простота его программной реализации. Вместе с тем, в условиях, когда наступление событий, обусловленных разными процессами, происходит с сильно отличающимися интервалами, то значительное время моделирования оказывается затраченным впустую (например, при моделировании производственного процесса на предприятии, работающем в односменном режиме, все вечернее и ночное время программная модель не будет выполнять никакой содержательной работы). Поэтому большинство программных реализаций имитационных моделей использует событийный алгоритм имитации. Имитационное моделирование представляет собой процесс, реализуемый с помощью средств вычислительной техники, что позволяет автоматизировать решение таких задач как: а) Создание или модификация имитационной модели. б) Проведение модельных экспериментов и интерпретация получаемых результатов. В случаях разработки сложных моделей, предназначенных для проведения большого объема экспериментов, для решения этих задач используются моделирующие комплексы (системы). Имитационное моделирование как информационная технология включает несколько основных этапов. На этапе структурного анализа процессов проводится формализация реального процесса, его декомпозиция на подпроцессы, которые могут также подвергаться декомпозиции. Задачи, решаемые на этом этапе, соответствуют задачам создания модели деловых процессов, вместе с тем, в зависимости от применяемых средств моделирования результат может потребовать преобразования формы представления в вид, наиболее полно соответствующий задачам, решаемым на дальнейших шагах. Описание модели в вербальном, графическом или полуформализованном виде должно быть представлено на специальном (формальном) языке для ввода в моделирующую систему. При этом могут применяться: Ручной способ. Описание составляется на языке какой-либо системы моделирования, например, GPSS, Pilgrim или алгоритмическом языке, например, Visual Basic (размер результирующего текста в последнем случае будет многократно превосходить размер текста на языке специальных систем). Автоматизированный способ. Текст на формальном языке получается в результате автоматической генерации описания, которое строится в интерактивном режиме с помощью высокоуровневого графического конструктора. Такой конструктор, которым оснащена, в частности, система Pilgrim, позволяет фактически совместить этап разработки программной модели с этапом системного анализа. Созданное формальное описание далее преобразуется в компьютерную программу, способную воспроизводить реальные процессы. Преобразование, которое обычно представляет собой трансляцию и редактирование связей, осуществляется в некоторой программной среде, может проводиться в двух режимах. Интерпретация. В этом режиме специальная программа- интерпретатор осуществляет всю процедуру имитации, непосредственно выполняя инструкции формального описания. Примером системы, где предусмотрен режим интерпретации, является система GPSS. Компиляция. В этом режиме на основе формального описания создается отдельная программа (исполнительный модуль), который может запускаться независимо от программной среды, в которой он был создан. Примером системы, где предусмотрен режим интерпретации, является система Pilgrim. Целью следующего этапа является обоснование модели, заключающегося в демонстрации пригодности модели для получения нужных показателей, т.е., обеспечение необходимых точности и надежности получаемых на ее основе результатов. Основной, последний этап моделирования сводится к проведению машинных экспериментов с программной моделью, сбору, накоплению, обработке и анализу собранных данных. Вопрос 2. Имитация случайных величин с заданными законами распределения. Значительную роль в программных средствах и системах имитационного моделирования играют методы и процедуры получения случайных величин, подчиняющихся тому или иному закону распределения. Рассмотрим основные из этих методов, а также приемы обработки результатов, получаемых с помощью имитационных моделей. Метод обратной функции. Пусть непрерывная случайная величина v задана законом распределения: FV У) = j7v( y)dy —X где fV - плотность распределения вероятностей, F - функция распределения вероятностей. Тогда случайная величина %. V j fv(у)dy распределена равномерно на интервале (0,1). . Отсюда следует, что искомое значениеy может быть определено из уравнения: = jfv( y)dy которое эквивалентно уравнению: X = F (у) где y - значение случайной величины v , x - значение случайной величины £. Решение уравнения можно записать в общем виде через обратную функцию F—1(х): У = F "1( х) Основной недостаток метода заключается в том, что интеграл не всегда является берущимся, а уравнение не всегда решается аналитическими методами. Имитация величины, распределенной по показательному закону. Для ряда весьма важных случаев решение уравнения для нахождения значения случайной величины можно найти. В частности, в соответствии с методом обратной функции существует преобразование, позволяющее вычислить значения случайной величины п, распределенной по показательному закону, который особенно часто используется для исследования систем массового обслуживания и определения показателей надежности систем. Функция плотности для показательного закона имеет вид: f,=teM (y>0) Воспользуемся методом обратной функции, вычислим интеграл и получим уравнение вида y х = J eXy My 0 или х = 1 - e Тогда 1 - х = eMy и, прологарифмировав и разрешив уравнение через у, будем иметь: y = —— ln х Получая значение х с помощью датчика равномерно распределенных на интервале (0,1) случайных чисел, можно получить значения у в соответствии с полученным выражением. Программа на языке С++: float expont(float m ) { return(m*(-log(rundum()) ) ); } Имитация случайного числа по данным наблюдения. Довольно часто значения случайной величины доступны в виде данных наблюдения, которые можно непосредственно использовать для модельных экспериментов без аппроксимации теоретическим распределением.
Если считать, что значения Pk хранятся в массиве P[9] (с индексом первого элемента равным 1), то построенный на основе метода обратной функции алгоритм получения случайной величины к для данного примера можно записать в таком виде: a=x k=0 ЦИКЛ-ПОКА a < P[k+1] И k<8 k=k+1 ВСЕ-ЦИКЛ где x - значение псевдослучайного числа, равномерно распределенного на интервале 0,1.
9 Вычислим значение N = X f = 80 и дополним таблицу строкой со k=1 9 X f\ Приводимый ниже текст программы на языке С++ обеспечивает генерацию случайной величины с произвольными значениями, которые задаются элементами массива vals. Массив nums задает значения частот появления значений (обозначены в примере как fk). Аргумент parts - число значений случайной величины (в примере - 9). float partval(int parts, int nums[], float vals[]) { int i; float sum, bleft,rnd=rundum(); for (i=0,sum=0; i for (i=0, bleft=0; i && rnd>=bleft; bleft+=(float)nums[i]/sum, i++) ; return(vals[i-1]); } Вопрос 3. Обработка результатов запусков программной модели. В процессе имитационного моделирования формируется большое количество реализаций, являющихся исходным статистическим материалом для нахождения приближенных значений (оценок) показателей эффективности. Основные результаты моделирования включают, как правило, функцию распределения (наиболее информативное описание) какого-то состояния системы или процесса (события, явления) и/или числовые характеристики, такие как оценка вероятности, математическое ожидание и дисперсия случайной величины. Оценка вероятности. В качестве оценки вероятности используется частота m P (A) = — , N где m - число случаев наступления события А в экспериментах, N - число проведенных экспериментов. Для получения оценки вероятности обычно организуют на программном уровне два счетчика, в которых накапливаются: общее количество проведенных экспериментов N; общее количество экспериментов с положительным исходом m. Закон распределения. В ряде случаев в качестве характеристики исследуемой системы выступает закон распределения (плотности распределения). Его приближенно можно представить с помощью гистограммы. Для этого интервал изменения случайной величины разбивается на отрезки At., каждому из них сопоставляется счетчик, где накапливаются т/ - количество попаданий значений этой величины д/.. На основании полученных значений счетчиков для д/. можно m построить гистограмму - набор прямоугольников с высотами — . N Практический прием сбора данных и построения графика вместе с текстом компьютерной программы будет рассмотрен далее. Оценка математического ожидания. Оценку математического ожидания m получают как среднее арифметическое значение случайной величины yi: 1 " m=—у yt N у У Для получения суммы в программных моделях обычно используется переменная, значение которой получает приращение после каждого проведенного испытания. Оценка дисперсии Оценка дисперсии получается с помощью формулы: S2 {уг-т)2 1 Выводы: Применение метода статистических испытаний дает хорошие результаты в случаях, когда требуется найти статические характеристики системы. Для моделей динамических систем и, в первую очередь, для стохастических моделей мощным инструментом решения задач является имитационное моделирование, воспроизводящее с помощью ЭВМ протекание реальных процессов. Для реализации программных моделей применяются стандартные механизмы имитации событий. В случае, когда необходимо добиться наиболее быстрого выполнения алгоритма обычно применяется событийный алгоритм имитации. Создание имитационных моделей требует выполнения ряда задач в определенной последовательности. Непосредственная реализация программы может осуществляться на основе интерпретации или компиляции. Каждый из этих вариантов имеет свои достоинства и недостатки, выбор подхода обусловлен требованиями конкретной задачи. В имитационных моделях стохастических систем широко используются случайные величины, распределенные по определенным законам. Для получения таких величин используются различные методы и приемы, одним из наиболее распространенных является метод обратной функции. 5. Данные, полученные в результате прогона имитационных моделей, необходимо обрабатывать. В зависимости от типа результатов используются свои методы обработки. Типичными случаями обработки данных запусков стохастических моделей являются получение средних значений и дисперсии какого-либо показателя, для вычисления которых по собранным данным применяются соответствующие математические выражения. Вопросы для самопроверки: Что такое имитационное моделирование? Для решения каких задач используется имитационное моделирование? Что такое пошаговый алгоритм имитации протекания процессов? Что такое событийный алгоритм имитации протекания процессов? Каковы сравнительные достоинства и недостатки пошагового и событийного алгоритмов? Из какие основных этапов состоит процесс моделирования? В чем заключается задача этапа структурного анализа процессов? Какие способы используются для формализации содержательного описания модели? Какие способы используются для получения программного кода по формальному описанию модели? Как реализуется метод обратной функции для имитации случайной величины, распределенной по показательному закону? Как оценить величину вероятности наступления события по результатам моделирования? Как оценить математическое ожидание случайной величины по результатам моделирования? Как оценить дисперсию случайной величины по результатам моделирования? Литература по теме: 1. Емельянов А.А., Власова Е.А., Дума Р.В. Имитационное моделирование экономических процессов / Под ред. А.А. Емельянова. - М.: Финансы и статистика, 2009. - 480 с. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||