Мет_ЛР_ТССА_2017_2. Методичні вказівки до лабораторних робіт з дисциплін теорія систем та системний аналіз
 Скачать 1.02 Mb. Скачать 1.02 Mb.
|

|
4.3 Опис лабораторної установки У якості лабораторної установки використовується персональний комп'ютер типу IBM PC. Виконання завдань лабораторної роботи здійснюється за допомогою CASE-засобу All Fusion Process Modeler (BpWin). 4.4 Порядок виконання роботи і методичні вказівки з її виконання 4.4.1 Завдання на лабораторну роботу Кожному виконавцю згідно варіантом, обраним до виконання для лабораторної роботи № 3, потрібно розробити діаграму потоків даних за стандартом DFD та визначити структуру даних бази даних системи. 4.4.2 Порядок виконання роботи Стандарт Data Flow Diagrams (DFD) входить до методології графічного структурного аналізу. Згідно стандарту DFD створюється моделі потоків даних систем, що досліджуються або розробляються. Стандарт методології моделювання потоків даних DFD включає: нотацію моделювання (умовні позначки), що складається з елементів, за допомогою яких будується модель потоків даних; метод моделювання (спосіб аналізу), що включає опис порядку та правил використання елементів нотації DFD. Діаграми потоків даних системи, що створюється за допомогою стандарту DFD, може бути використані: для аналізу функцій існуючої системи та визначення вимог до її доробки, у тому числі структури даних (бази даних); для визначення функціональних вимог до розроблювальної системи; для визначення вимог до структури даних (бази даних), видів та типів даних, що потрібні для виконання функцій системою, що розробляється. Таблиця 4.1 – Нотації DFD
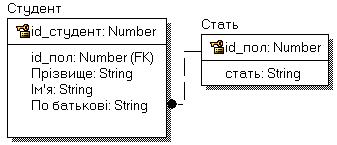
Зовнішній по відношенню до системи об'єкт, що обмінюється з нею потоками даних.   Вимоги до функцій та структури бази даних представляються у вигляді ієрархії процесів, зв'язаних з потоками та сховищами даних (таблицями баз даних, об’єктами даних). Діаграми потоків даних показують, як кожний процес (функція) системи перетворює свої вхідні дані у вихідні, зберігає або забирає дані зі сховищ даних, виявляють відносини між цими процесами. DFD-діаграми використовуються як доповнення до моделі IDEF0 для опису даних документообігу і обробки інформації. Подібно IDEF0, DFD представляє систему як мережу зв'язаних функцій (робіт, бізнес-процесів). Згідно стандарту DFD для опису діаграм потоків даних використовуються дві нотації – Йордана Де Марко (Yourdon) і Гейна-Сарсона (Gane-Sarson). Розходження полягає в графічних формах об'єктів. Нотації являють собою діаграми потоків даних (табл. 4.1). В CASE-засобі All Fusion Process Modeler (BpWin) реалізована нотація Гейна-Сарсона, яка включає наступні елементи: функції (роботи, бізнес-процеси) системи (Activity) – відображають процеси обробки і зміни інформації. Activity являють собою функції системи, що перетворять входну інформацію на вихідну. Незважаючи на то, що функції зображуються прямокутниками з округленими кутами, зміст їх збігається зі змістом функцій IDEF0 (рис. 4.1). Вони (Activity) мають входи і виходи, але не підтримують «Управління» і «Механізм», як в нотації IDEF0. Стрілка (Arrow) може заходити в блок з будь-якої сторони Activity; Функція (робота) системи, яка перетворює або використовує потік даних  Рисунок 4.1 – Елемент Activity в нотації DFD дуги або стрілки (Arrow) – відображають інформаційні потоки (рис. 4.2). На відміну від стрілок (Arrow) IDEF0, які являють собою жорсткі взаємозв'язки, стрілки DFD показують, як об'єкти (включаючи дані) рухаються від однієї функції (роботи) до іншої. Ця представлення потоків разом зі сховищами даних і зовнішніми сутностями робить моделі DFD більш схожими на фізичні характеристики системи – рух об'єктів даних, їх зберігання, постачання і розповсюдження;  Рисунок 4.2 – Елемент Arrow в нотації DFD сховища даних (Data Store) – відображають дані (таблиці бази даних, інформація документів, сховища даних, накопичувачі даних і т.д.), до яких здійснюється доступ. Ці дані використовуються, створюються або змінюються функціями (Activity) системи (рис. 4.3);  Рисунок 4.3 – Елемент Data Store в нотації DFD зовнішні сутності (External References) – відображають об'єкти даних, з якими відбувається взаємодія (діючі особи, що надають інформацію; джерела даних, сховища даних, дані документів і т.д.).  Рисунок 4.4 – Елемент External References в нотації DFD Створення DFD діаграми здійснюється за допомогою CASE-засобу All Fusion Process Modeler (BpWin). Пакет BpWin дозволяє створити DFD модель системи 2-мя способами: створення DFD моделі без використання функціональної моделі, створеної по стандарту IDEF0. створення DFD моделі шляхом декомпозиції функціональної моделі IDEF0 у діаграму DFD. Порядок побудови DFD моделі за допомогою CASE-засобу All Fusion Process Modeler наступний: а) відкрити функціональну модель IDEF0, виконану на лабораторній роботі № 3; б) визначити структуру (схему) бази даних у вигляді сутностей (таблиць). Визначити їх найменування та інформацію, яка зберігається в кожній з них; в) визначити функції системи щодо використання інформації з кожної (конкретної по найменуванню) таблиці бази даних; г) провести ідентифікацію основних потоків інформації, що циркулює між системою та зовнішніми об'єктами даних (клієнтами, постачальниками і т.д.); ґ) провести декомпозицію функціональної моделі IDEF0, створену на ЛР № 3 у діаграму DFD; д) провести перевірку контекстної діаграми DFD і внести в неї зміни, що включають об'єднання всіх процесів функціональної діаграми IDEF0 в один процес, а також групування потоків; е) зробити перевірку основних вимог контекстної діаграми DFD до розроблювальної системи; є) провести декомпозицію кожного процесу (функції, роботи, Activity) поточної DFD за допомогою діаграми, що деталізує функцію системи; ж) зробити перевірку основних вимог до діаграм декомпозиції DFD підсистем відповідного рівня; з) провести додавання нових визначених функцій (Activity), потоків (Arrow), зовнішніх (External References) і внутрішніх (Data Store) об’єктів даних у словник даних при кожному використанні на діаграмах. Для додавання внутрішніх (Data Store) джерел даних у вигляді таблиць БД (Entity) та їх атрибутів необхідно використовувати вікно редактора «Entity and Attribute Editor», що визивається за допомогою пункту головного меню редактора «Model» / «Entity/Attribute Editor…»; и) зробити перевірку повноти і наочності моделі DFD після побудови трьох її рівнів; і) вивести звіти «Arrow Report» та «Data Usage». Сутності (Entity) розробленої схеми бази даних та їх атрибути, що використовуються в моделі DFD, необхідно експортувати в файл з розширенням «*.BPX» для подальшого використання в наступній роботі. 4.5 Зміст звіту Звіт повинен містити: мету роботи; опис найменувань таблиць (Entity) та їх атрибутів, що входять до бази даних програмної системи; схема даних бази даних програмної системи; діаграма верхнього рівня (контекстна діаграма) DFD; декомпозиція діаграми DFD верхнього і подальших рівнів для повного опису моделі потоків даних системи; звіт у вигляді списку об'єктів Activity (Activity Report); звіт у вигляді списку об'єктів Arrow (Arrow Report); аналіз отриманих результатів і висновки по роботі. 4.6 Контрольні запитання та завдання Для рішення яких завдань застосовується системний аналіз? Яке призначення має методології структурного аналізу і проектування SADT? Яке призначення має сімейство методологій IDEF? Яке призначення стандарту DFD? Які складові входять до стандарту DFD? Перелічить елементи, що входять до нотації стандарту DFD. Пояснить призначення елементу нотації DFD Activity. Пояснить призначення елементу нотації DFD Arrow. Визначите поняття «зовнішній об'єкт» і поясните, яким образом відбувається його ідентифікація. Визначите поняття «сховище даних» і поясните, яким-образом відбувається його ідентифікація. Які існують типи сховища даних? Поясните поняття «інформаційний» та «матеріальний» потоки». Чим нотація DFD відрізняється від нотації IDEF0? Визначите поняття «бізнес-процес» і «потік даних». Поясните, яким-образом відбувається їх ідентифікація при структурному аналізі? Сформулюйте правила з'єднання елементів діаграми (інформаційних потоків) між собою. Сформулюйте поняття «модель потоків даних системи». Для вирішення яких завдань створюється модель потоків даних системи? Для чого застосовується візуальне проектування? Для вирішення яких завдань використовуються CASE-засоби? Яке призначення і функції пакета All Fusion Process Modeler (BpWin)? Вкажіть основні етапи процесу створення моделі потоків даних системи за стандартом DFD. 5 СТРУКТУРНЕ МОДЕЛЮВАННЯ ДАНИХ СИСТЕМИ 5.1 Мета роботи Ознайомитися з особливостями логічного та фізичного моделювання структури даних системи за стандартом IDEF1X. Отримати практичні навички створення логічної та фізичної моделі структури даних системи з використанням CASE-засобу All Fusion Data Modeler (ERWin). 5.2 Методичні вказівки з організації самостійної роботи студентів Під час підготовки до виконання лабораторної роботи необхідно: вивчити основні завдання системного аналізу; вивчити зміст основних етапів розробки програмних систем та їх життєвого циклу; вивчити призначення методології структурного аналізу і проектування систем SADT; вивчити призначення сімейства методологій IDEF; вивчити призначення стандарту IDEF1X та ознайомитися з його нотаціями; вивчити призначення CASE-засобів та функції програмного пакета All Fusion Data Modeler (ErWin); вивчити основні етапи процесу створення логічної моделі структури даних системи за стандартом IDEF1X. Для підготовки до лабораторної роботи необхідно використовувати навчальний посібник [1], конспект лекцій [2], методичні вказівки до самостійної роботи [3] і рекомендовану літературу [4-11]. 5.3 Опис лабораторної установки У якості лабораторної установки використовується персональний комп'ютер типу IBM PC. Виконання завдань лабораторної роботи здійснюється за допомогою CASE-засобу All Fusion Data Modeler (ErWin). 5.4 Порядок виконання роботи і методичні вказівки з її виконання 5.4.1 Завдання на лабораторну роботу Кожному виконавцю згідно варіантом, обраним до виконання для лабораторної роботи № 3,4 потрібно розробити логічну та фізичну модель структури даних системи за стандартом IDEF1X. 5.4.2 Порядок виконання роботи Стандарт IDEF1X (IDEF1 eXtended) є розширенням методології стандарту IDEF1, з можливістю використання в CАSE-засобах автоматизації розробки структури баз даних (БД) для програмних систем різного призначення. Стандарт IDEF1X реалізований в CАSE-засобі AllFusion ErWin Data Modeler (далі за текстом – ErWin). Стандарт методології IDEF1X включає: нотацію моделювання (умовні позначки) у вигляді ER-діаграм, що складаються з елементів, за допомогою яких розробляється логічна та фізична моделі структури даних; метод моделювання (спосіб аналізу), що включає опис порядку та правил використання елементів нотації IDEF1X. При розробці структури даних системи згідно класичної теорії їх створення прийнято виділяти наступні етапи, за допомогою яких здійснюється перехід від предметної області до її конкретної реалізації. Етап 1. Створення інфологічної (концептуальної) моделі БД системи. На цьому етапі здійснюється опис об'єктів предметної області і зв'язків між ними: атрибутів сутностей, ключових атрибутів сутностей, складених ключових атрибутів сутностей, зв'язків між сутностями (ключовими атрибутами), визначення доменів. Етап 2. Створення даталогічної (логічної) моделі БД системи. На цьому етапі здійснюється конкретизація типів даних атрибутів (у тому числі і ключових) сутностей для конкретної платформи, на якій планується реалізувати БД. Етап 3. Реалізація даталогічної моделі БД системи на платформі обраної системи управління базами даних (СУБД). У термінології CASE-засобу ErWin створювані інфологічна модель має назву «Логічна» (Logical), а даталогічна – «Фізична» (Physical). Згідно з даним підходом прийнято виділяти наступні етапи розробки БД за допомогою CASE-засобів. Етап 1. Створення функціональної моделі (IDEEF0) та моделі потоків даних (DFD) системи, що розробляється за допомогою CASE-засобу All Fusion Process Modeler (BpWin). Етап 2. Імпорт визначених на першому етапі сутностей та їх атрибутів з BpWin до ErWin і створення логічної моделі БД в автоматизованому режимі. Етап 3. Модифікація логічної моделі БД, шляхом створення нових сутностей, атрибутів сутностей та вставлення зв’язків між сутностями. Етап 4. Створення фізичної моделі БД системи в автоматизованому режимі за допомогою інтерфейсу ErWin для обраної платформи системи управління базами даних (СУБД). Етап 5. Створення файлу БД системи. На цьому етапі в автоматизованому режимі фізична модель згідно обраної платформи СУБД передається до файлу БД, або генерується у вигляді файлу-скрипта, який необхідно запустити на виконання на стороні сервера. Розглянемо поетапне виконання завдання лабораторної роботи. На першому етапі розробляється логічна модель БД за допомогою CASE-засібу ErWin. Пакет ErWin дозволяє створювати логічну модель БД системи 2-мя способами: створення логічної моделі БД з використанням імпорту сутностей та їх атрибутів з DFD та IDEF0 моделей, розроблених в пакеті BpWin; створення нової логічної моделі БД «з нуля», з використанням інтерфейсу пакета ErWin. Для імпорту сутностей та їх атрибутів з DFD та IDEF0 моделей в пакеті ErWin необхідно виконати пункт головного меню «File» / «Import» / «From All Fusion Process Modeler…» і відкрити файл з розширенням «*.BPX», створений при виконанні лабораторної роботи № 4. Для створення нової логічної моделі БД необхідно виконати пункт меню «File»/«New» і в діалоговім вікні «Create Model» (рис. 5.1) встановити перемикач у положення «Logical»/«Physical», а в списках «Target Database» вибрати в якості цільовий БД – «Access» і її версію –«2000/2002/2003». Згідно із завданням на лабораторну роботу ER-моделі повинні бути розроблені в нотації IDEF1X. Для вибору нотацій моделі необхідно виконати команду меню «Model»/«Model Properties». Далі у вікні «Model Properties» (властивості моделі) вибрати закладку «Notation» (нотація) і встановити перемикачі розділів «Logical Notation» (нотація логічної моделі ) та «Physical Notation» (нотація фізичної) у позицію «IDEF1X» (рис.5.2) 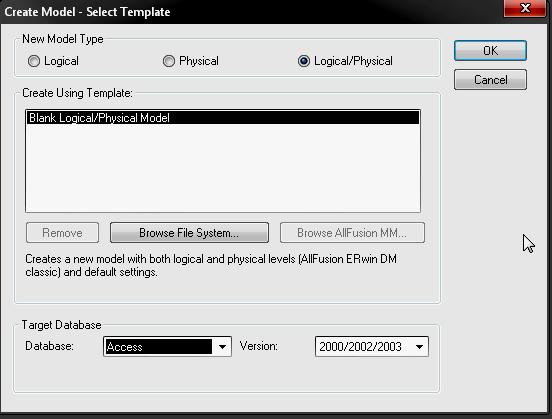 Рисунок 5.1 – Діалогове вікно «Create Model» 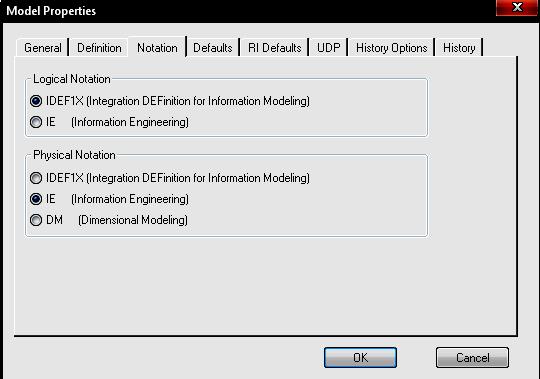 Рисунок 5.2 – Закладка «Notation» діалогового вікна «Model Properties» Логічна модель БД створюється з використанням специфічної термінології, зв’язаної з нотацією IDEF1X. У якості нотацій в методології IDEF1X використовуються діаграми «сутність – зв'язок» (Entity Relationship Diagram, ERD). Побудова ER-діаграм полягає у визначенні сутностей (Entity), атрибутів (Attributes) сутностей і зв'язків (Relationship) між сутностями. Сутність – це клас об'єктів предметної області, що володіють загальними атрибутами або характеристиками. Кожної сутності в ER-моделі привласнюється унікальне ім'я, яким є граматичний оборот іменника (іменник, у якого можуть бути прикметники і прийменники). Якщо ім'я складається з декількох слів, то бажане, щоб першим стояв іменник. Сутність може мати атрибути, причому один або декілька з них повинні бути ключовими. Атрибут – це характеристика або елемент даних, що характеризує сутність. Атрибути сутності можуть бути: не ключовими; первинними ключами; альтернативними ключами; зовнішніми ключами. Метою опису доменів атрибутів є визначення діапазону всіх можливих значень, які може прийняти атрибут. Доменом називається деякий діапазон значень, елементи якого вибираються для присвоєння значень одному або декілька атрибутам. Домени містити дані про набір припустимих значень для атрибута та відомості про розмір і формат кожного з атрибутів. Визначення атрибутів здійснюється згідно строго визначених правил. Правила визначення атрибутів у нотації IDEF1X: а) Кожний атрибут ідентифікується унікальним ім’ям. б) Сутність може мати будь-яку кількість атрибутів. Кожний атрибут належить тільки однієї сутності. в) Сутність може мати будь-яку кількість наслідуваних атрибутів, але наслідуваний атрибут повинен бути частиною первинного ключа відповідної до сутності-батька або загальної сутності. г) Для кожного екземпляра сутності повинне існувати значення кожного його атрибута не рівне нулю (правило не звернення до нуля). ґ) Жоден з екземплярів сутності не може мати більш ніж одним значенням для пов'язаного з нею атрибута (правило не повторення). д) Сутність повинна мати атрибут або комбінацію атрибутів, чиї значення однозначно визначають кожний екземпляр сутності. Ці атрибути утворюють первинний ключ сутності. У нотації IDEF1X установлені наступні правила ключів: кожна сутність повинна мати первинний ключ; кожна сутність може мати будь-яке число альтернативних ключів; первинний і альтернативний ключ може складатися з одного атрибута або комбінації атрибутів; окремий атрибут може бути частиною більш ніж одного ключа, первинного або альтернативного; атрибути, що входять у первинні або альтернативні ключі сутності, можуть бути власними для сутності або успадковуватися через відношення; первинні або альтернативні ключі повинні містити тільки необхідні для однозначної ідентифікації атрибути, тобто при виключенні із ключа будь-якого атрибута не всі екземпляри сутності можуть бути однозначно визначені (правило найменшого ключа); якщо первинний ключ полягає більш ніж з одного атрибута, то значення будь-якого не ключового атрибута повинне функціонально залежати від усього первинного ключа, тобто якщо первинний ключ відомий, то відоме значення кожного не ключового атрибута, і значення не ключового атрибута не може бути визначене за допомогою тільки частини первинного ключа (правило повної функціональної залежності); кожний не ключовий атрибут повинен функціонально залежати тільки від первинного і альтернативних ключів, тобто значення не ключового атрибута не може визначатися значенням іншого не ключового атрибута (правило відсутності транзитивної залежності).
Рисунок 5.3 – Створення сутності Для створення нової сутності необхідно на панелі інструментів редактора ErWin клацнуть мишкою по ярлику сутності «Entity». Редактор автоматично вставляє сутність (рис. 5.3) з областю вводу імені сутності і її номером (номер сутності редактор ErWin привласнює автоматично). Для присвоєння імені сутності необхідно виконати команду контекстного меню «Entity Properties». У вікні «Entities» на вкладці «Definition» (рис. 5.4) у поле «Name» необхідно задати ім'я сутності, а в текстовім полі «Definition» ввести коментар.  Рисунок 5.4 – Властивості сутності Вкладки (рис. 5.4) «Note», «Note 2», «Note 3», «UDP» (User Defined Properties – властивості, що визначаються користувачем) служать для внесення додаткових коментарів і визначень до сутності. На вкладці «Note 1» (рис. 5.4) можна вказати корисне зауваження, що описує яке-небудь бізнес-правило або угоду по організації діаграми. На вкладці «Note 2» можна задокументувати деякі можливі запити, які будуть використовуватися стосовно сутності в БД. Вкладка «Note 3» дозволяє вводити приклади даних для сутності в довільній формі. На вкладці «Icon», сутності можна поставити у відповідність зображення, яке буде відображатися в режимі перегляду моделі на рівні іконок. Вкладка «Volumetric» використовується для чисельного опису сутності з метою її генерації у фізичній моделі. Для завдання атрибутів сутності використовується команда контекстного меню «Attributes». У вікні «Attributes» (рис.5.5, а) необхідно нажати кнопку ««New» і викликати вікно «New Attributes» (рис.5.5, б). Для завдання властивостей атрибута використовується поля: поле «Attribute Name» (ім'я атрибута) – ім'я атрибута в логічній моделі; поле «Column Name» (ім'я колонки – ім'я поля таблиці у фізичній моделі). При введенні імені колонки «Column Name» необхідно пам'ятати про ті обмеження, які накладає обрана СУБД на імена таблиць і поля записи; за допомогою поля зі списком «Icon» можна зв'язати іконку з атрибутом (для її подальшого відображення); встановлення прапорця «Primary Key» дозволяє задати первинний ключ.
Рисунок 5.5 – Завдання атрибутів сутності Призначення вкладок вікна «Attributes» (рис. 5.5, б): вкладка «Datatype» дозволяє визначити домен (тип даних) для атрибутів сутності; вкладка «Constraint» дозволяє ввести умови перевірки правильності введення значення атрибута і значення, що використовується за замовчуванням; вкладка «Definition» дозволяє описувати визначення окремих атрибутів; вкладка «Note» дозволяє додавати зауваження про одне або декількох атрибутах сутності, які не ввійшли у визначення; вкладка «UDP» (User Defined Properties) служить для завдання значень властивостей, визначених користувачем; вкладка «Key Group» дозволяє включити атрибут до складу первинного, альтернативного або інвертованого ключа. Наступними діями по створенню логічної моделі є завдання зв’язків між сутностями. У нотації IDEF1X використовується термін «потужність зв’язку» (кардинальність зв’язку). Потужність зв'язку визначає, яка кількість екземплярів сутності-нащадка може існувати для кожного екземпляра сутності-батька. Розрізняють чотири типи потужності: загальний випадок, коли одному екземпляру батьківської сутності відповідають «0», «1» або «багато» екземплярів дочірньої сутності. Ця потужність установлюється за замовчуванням, не позначається літерою, і відповідає типу зв’язку «один до багатьох»; символом «Р» (positive) позначається випадок, коли одному екземпляру батьківської сутності відповідають «1» або «багато» екземплярів дочірньої сутності (виключене нульове значення). Відповідає типу зв’язку «один до багатьох»; символом «Z» (zero) позначається випадок, коли одному екземпляру батьківської сутності відповідають «0» або «1» екземпляр дочірньої сутності (виключені множинні значення). Відповідає типу зв’язку «один до одного»; цифрою позначається випадок точної відповідності, коли одному екземпляру батьківської сутності відповідає заздалегідь задане число екземплярів дочірньої сутності. Відповідає типу зв’язку «один до N». Редактор ErWin також підтримує установку зв’язку типу «багато до багатьох». Крім завдання потужності нотація IDEF1X підтримує наступні види зв'язків – «що ідентифікують» або «що не ідентифікують». Якщо екземпляр дочірній сутності однозначно визначається своїм зв'язком із батьківською сутністю, то зв'язок називається ідентифікуючим, а якщо ні, то – не ідентифікуючим. У нотації IDEF1X ідентифікуючий зв'язок позначається безперервної, а не ідентифікуючий – пунктирною лінією. Відповідно до існуючого виду зв’язку між сутностями в нотації IDEF1X виділяють два види дочірній сутності: «незалежну» і «залежну». Дочірня сутність є незалежної, якщо кожний її екземпляр може бути однозначно ідентифікований без визначення його відносин (зв’язків) з батьківськими сутностями (відповідає не ідентифікуючому зв’язку). Сутність називається залежної, якщо однозначна ідентифікація її екземпляра залежить від його відношення до батьківської сутності (відповідає ідентифікуючому зв’язку). У нотації IDEF1X незалежні сутності відображаються прямокутниками, а залежні – прямокутниками зі округленими кутами (рис. 5.6, а, б, в). Для встановлення не ідентифікуючого зв'язку між сутностями необхідно клацнути на ярлику «не ідентифікуючий зв'язок» панелі інструментів редактора. Потім клацнути спочатку по батьківській, а потім по дочірній сутності. При встановленні не ідентифікуючого зв'язку атрибути первинного ключа батьківської сутності автоматично переносяться до складу атрибутів дочірньої сутності. У дочірній сутності нові атрибути позначаються як зовнішній ключ «FK» (Foreign Key). Не ідентифікуючі зв'язки зображуються пунктирною лінією, лінії закінчуються точкою з боку «багато» дочірньої сутності і прозорим ромбом з боку «один» батьківської сутності. Для встановлення ідентифікуючого зв'язку між сутностями необхідно клацнути на ярлику «ідентифікуючий зв'язок» панелі інструментів, потім клацнути спочатку по батьківській, а потім по дочірній сутності. При встановленні ідентифікуючого зв'язку атрибут первинного ключа батьківської сутності автоматично переноситься до складу ключових атрибутів дочірньої сутності, з позначкою «FK» (Foreign Key). Ідентифікуючі зв'язок зображуються суцільною лінією, лінія закінчуються точкою з боку з боку «багато» дочірньої сутності. Дочірня сутність змінює свій зовнішній вигляд на прямокутник з округленими кутами (залежна сутність).
Рисунок 5.6 – Завдання властивостей зв’язку між сутностями Для редагування властивостей зв'язку необхідно вибрати в контекстному меню зв'язка пункт «Relationship Properties» (властивість зв'язку). У вкладці «General» вікна «Relationship» (рис. 5.6, г) для не ідентифікуючого зв’язку задається: у поле «Name» – ім'я зв'язку (за замовчуванням ім'я зв'язку привласнює редактор ErWin); у розділі «Verb Phrase» вказується ім’я зв'язку. Для зв’язку «один до багатьох» – з боку дочірньої сутності, а для зв’язку «багато до багатьох» – з боку батьківської та дочірньої сутностей; у розділі «Cardinality» – потужність (кардинальність) зв'язку; у розділі «Relationship Type» – тип зв'язку «Non-Identifying» – не ідентифікуючий зв'язок; у розділі «Nulls», якщо встановлений тип зв'язку «Non-Identifying» доступні 2 тригерних перемикача. Встановлення значення «Nulls Allowed» дозволяє приймати значення «Null» зовнішньому ключу, тобто зв'язок необов'язковий і позначається зі сторони «один» не зафарбованим ромбом (рис.5.6, а). Якщо встановлено значення «No Nulls», значення «Null» для зовнішнього ключа заборонені, зв'язок обов'язковий і зі сторони «один» ніяк не позначається (рис.5.6, б). Якщо у розділі «Relationship Type» (рис. 5.6, г) вказаний тип зв'язку «Identifying» – ідентифікуючий зв'язок, розділ «Nulls» стає недоступним, а зовнішній ключ входить до складу ключових атрибутів і сумісно з первинним ключем утворюють складовий ключ дочірньої сутності (рис.5.6, в). Для створення фізичної моделі БД системи необхідно в списку відображення типу моделі на панелі інструментів редактора вибрати пункт «Physical» – фізична модель. Фізична модель створюється редактором автоматично. При цьому ураховується платформа обраної СУБД (в нашому випадку – СУБД Access). В нотації IDEF1X фізичної моделі, на відміну від логічної, найменування «сутність» змінюється на «таблиця» (Tables), а найменування «атрибута» сутності – на найменування «поле» (Columns) таблиці. При генерації імен таблиць або їх полів за замовчуванням усі пробіли автоматично перетворяться в символи підкреслення, а довжина імені скорочується до максимально можливої довжини, припустимої для обраної СУБД. Усі зміни, зроблені в редакторах «Tables» або «Columns», не відбиваються на іменах сутностей і атрибутів, оскільки інформація на логічному і фізичному рівнях редактор ErWin зберігається окремо. Також відповідно до стандарту опису даних для обраної платформи СУБД редактор ErWin автоматично змінює найменування доменів для кожного поля таблиці. Для редагування властивостей таблиць фізичної моделі БД використовується редактор «Tables». Для виклику редактора потрібно в контекстному меню таблиці вибрати пункт «Tables properties» або виконати команду головного меню редактора «Model»/«Tables». Для генерації структури БД в файл необхідно створити «порожній» файл бази даних у форматі СУБД Access з розширенням «*.MDB». У редакторі Erwin виконати команду меню «Tools»/ «Forward Engineering» / «Schema Generation». У закладці «Options» вікна «Schema Generation» задаються опції генерації об'єктів бази даних. Для завдання опцій генерації якого-небудь об'єкта потрібно вибрати об'єкт у лівому списку закладки, після чого включити відповідну опцію в правому списку. У закладці «Summary» вікна «Schema Generation» відображаються всі опції, що задані у вкладці «Options». Список опцій в «Summary» можна редагувати так само, як і в «Options». У закладці «Comment» вносяться коментар для кожного набору опцій генерації. Для контролю може використовуватись кнопка «Print» вікна «Schema Generation» призначена для виводу на друк створеного редактором скрипту SQL. |



 Зовнішня сутність
Зовнішня сутність