вар. 58. Обобщите результаты оценивания параметров модели и результаты проверки модели на адекватность
 Скачать 281 Kb. Скачать 281 Kb.
|

|
Как следует из данных, полученных с помощью Excel методом наименьших квадратов, полученная многофакторная модель будет иметь вид: Y = -1046,49 + 2,0334∙X1 + 1828,83∙X2 (1.1) (t) (-2,311) (6,181) (3,265) Уравнение (1.1) выражает зависимость валового внутреннего продукта (Y) от экспорта товаров и услуг (Х1), обменного курса евро к национальной валюте (Х2). Коэффициенты уравнения показывают количественное воздействие каждого фактора на результативный показатель при неизменности других. В нашем случае валовой внутренний продукт увеличивается на 2,033 ед. при увеличении экспорта товаров и услуг на 1 ед. при неизменности показателя обменного курса евро к национальной валюте; валовой внутренний продукт увеличивается на 18,288 ед. при увеличении обменного курса евро к национальной валюте на 1 ед. при неизменности показателя экспорта товаров и услуг. Случайное отклонение для коэффициента при переменной Х1 составляет 0,329; при переменной Х2 – 5,601; для свободного члена –452,86. Помощь на экзамене онлайн. Табличное значение критерия Стьюдента, соответствующее доверительной вероятности = 0,95 и числу степеней свободы v = n – m – 1 = 29; tкр. = t0,025;29 = 2,364. Сравнивая расчетную t-статистику коэффициентов уравнения с табличным значением, заключаем, что все коэффициенты уравнения регрессии будут значимы, за исключением свободного члена в уравнении регрессии. Коэффициент детерминации R2 = 0,8099; Скорректированный на потерю степеней свободы коэффициент множественной детерминации AR2 = 0,7968; Критерий Фишера F = 61,766; Уровень значимости модели р < 0,0000; Согласно критерию Фишера данная модель адекватна. Так как уровень значимости модели меньше 0,00001. Проверим остатки на наличие автокорреляции. Для этого найдем значение статистики Дарбина-Уотсона. 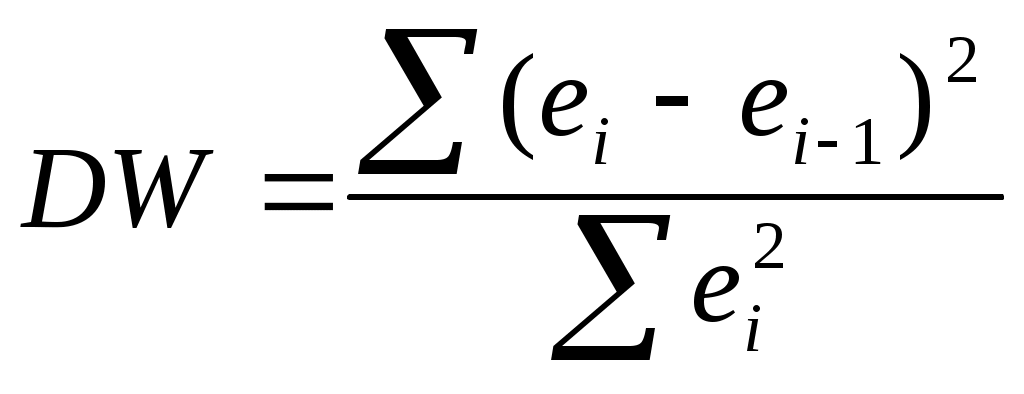 Промежуточные расчеты поместим в таблицу 1.4. Таблица 1.4.
DW = 1,1576. По таблице приложения 4 [1] определяем значащие точки dL и dU для 5% уровня значимости. Для m = 2 и n = 32: dL = 1,28; dU = 1,57. Так как DW < dL (1,1576<1,28), то нулевую гипотезу об отсутствии автокорреляции мы не можем принять. Следовательно, в модели присутствует автокорреляция остатков случайных отклонений. Проверим наличие автокорреляции, используя тест Бреуша-Годфри. Тест основан на следующей идее: если имеется корреляция между соседними наблюдениями, то естественно ожидать, что в уравнении (где et— остатки регрессии, полученные обычным методом наименьших квадратов), коэффициент ρ окажется значимо отличающимся от нуля. Значение коэффициента ρ представлено в таблице 1.5. Таблица 1.5.
Проверим значимость коэффициента корреляции, находим наблюдаемое значение по формуле: T>tкр, следовательно коэффициент корреляции значим, и в модели присутствует автокорреляция остатков случайных отклонений. Проведем графический анализ гетероскедастичность. Построим график, где по оси абсцисс будем откладывать расчетные значения Y, полученные из эмперического уравнения регрессии, а по оси ординат квадраты остатков уравнения е2. График представлен на рисунке 1.1. Рисунок 1.1. 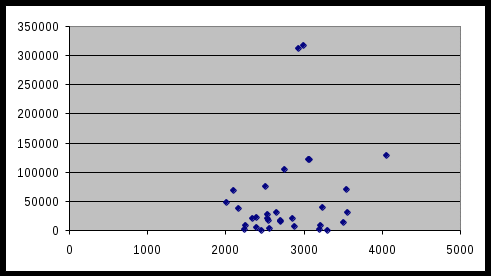 Анализируя график, можем предположить непостоянство дисперсий. Т. е. наличие гетероскедастичности в модели. Проверим наличие гетероскедастичности, используя тест Вайта. Строим регрессию: ε2 = a + b1x1 + b11x12 + b2x2 + b22x22+ b12∙x1∙x2 Результаты теста представлены в таблице 1.6. Таблица 1.5.
Результаты теста Уайта показывают отсутствие гетероскедастичности, так как при 5% уровне значимости Fфакт Для проверки наличия гетероскедастичности воспользуемся тестом Парка. В Excel рассчитаем логарифмы значений e2, X1 и X2 (см. табл. 1.7). Таблица 1.7.
Построим для каждой объясняющей переменной зависимости Результаты в таблицах 1.8– 1.9. Таблица 1.8.
Таблица 1.9.
В таблицах 1.8 – 1.9 рассчитана t-статистика для каждого коэффициента . Определяем статистическую значимость полученных коэффициентов . По таблице приложения 2 [1] находим табличное значение коэффициента Стьюдента для уровня значимости = 0,05 и числа степеней свободы v = n – 2 = 29. t/2; v = t0,025; 29 = 2,364. Сравнивая рассчитанную t-статистику с табличной, получаем, что ни один коэффициент не является статистически значимым. Это говорит о отсутствии в модели гетероскедастичности. Результаты теста Парка, подтвердили результаты теста Уайта. Вывод: Построенное уравнение регрессии (1.1), хотя и адекватно экспериментальным данным (имеет высокий коэффициент детерминации и значимую F-статистику, все коэффициенты регрессии статистически значимы), не может быть использовано в практических целях, так как оно имеет следующие недостатки: присутствует автокорреляция остатков случайных отклонений, имеется мультиколлинеарность. Перечисленные недостатки могут привести к ненадежности оценок, выводы по t- и F- статистикам, определяющим значимость коэффициентов регрессии и детерминации, возможно, неверны. |