Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214
 Скачать 452.53 Kb. Скачать 452.53 Kb.
|

|
Локальные данные. Здесь в течение времени жизни данной активации функции хранятся значения объектов, объявленных в ее теле. Размер этого поля, как правило, может быть вычислен во время трансляции вызываемой функции. Существуют языки программирования, в которых возможно исключение из этого правила, такие как С/С++: допускающие возможность объявления в функции локальных массивов, размеры которых зависят от значений фактических параметров. Их значения желательно размещать в регистрах процессора на время выполнения функции. Результаты промежуточных вычислений. В том случае если в инструкциях вызываемой функции имеются сложные выражения наподобие a*b+c*d, возникает необходимость временного хранения значения произведения a*b (или c*d, или и того и другого) от момента его вычисления и, по крайней мере, до момента последнего использования. Такие данные во многом эквивалентны локальным данным функции, но не имеют никакого имени, присвоенного программистом в тексте программы. В процессе трансляции по мере необходимости образования объектов для хранения промежуточных результатов имена для них могут формироваться и использоваться семантическим анализатором и генератором объектного кода/виртуальной машиной. Как будет показано ниже, перечень и типы данных объектов, необходимых для хранения промежуточных результатов, могут быть определены транслятором в процессе преобразования постфиксной записи в последовательность тетрад/триад. Таким образом, размер этого поля тоже может быть вычислен во время трансляции вызываемой функции. Регистры процессора. В этом поле сохраняется состояние регистров процессора, каким оно было непосредственно перед вызовом функции и, соответственно, каким должно быть сразу после возврата из нее. В частности, здесь же обычно хранится адрес возврата, поскольку он является значением одного из регистров, а именно – счетчика команд. Размер памяти, необходимой для сохранения значений регистров, определяется архитектурой компьютера и фиксируется в качестве константы на этапе разработки транслятора. Связь по доступу. Используется для обеспечения доступа из вызываемой функции к нелокальным данным, хранящимся в другой записи активации. Размер этого поля фиксирован и равен размеру любого указательного значения. Связь по управлению. Это поле используется для хранения указателя на запись активации вызывающей функции. Размер его фиксирован. Используется в реализациях языков, обеспечивающих не текстуальную, а динамическую видимость нелокальных объектов. Фактические параметры. Обычно фактические параметры стремятся передавать через регистры процессора. Тем не менее всегда необходимо учитывать возможность того, что количество фактических параметров превысит доступное количество регистров, поэтому в записи активации функции для них должно предусматриваться место. Большинство языков программирования предусматривает фиксированное количество и типы значений параметров каждой функции. В этом случае размер поля фактических параметров может быть определен во время трансляции вызываемой функции. Однако существуют языки (С/С++), допускающие возможность приема вызываемой функцией заранее неопределенного количества фактических параметров. В этом случае размер поля фактических параметров может быть определен только при трансляции текста вызывающей функции. Поле возвращаемого значения используется вызываемой функцией для возврата значения вызывающей функции. Для повышения эффективности программы это значение, как правило, возвращается в регистре. Если же для возвращаемого значения резервируется поле в записи активации, то его размер определяется типом значения и может быть легко определен во время трансляции функции. Не во всех языках используется каждое из этих полей (и не все компиляторы с одного и того же языка делают это одинаково). В силу того что поля записи активации интенсивно используются при выполнении функции, для хранения наиболее часто используемых из них разработчики трансляторов стремятся использовать регистры процессора. За формирование полей записи активации обычно отвечают и вызывающая и вызываемая функции, но каждая – строго за определенные поля записи. Запись активации может создаваться (здесь имеется в виду выделение памяти для нее, а не формирование значений полей) следующими способами: статически при трансляции функции; динамически в куче; динамически в стеке времени исполнения программы. Первый способ – создание записи активации в процессе трансляции – преследует цель минимизировать накладные расходы по времени на вызовы функций при исполнении программы. Типичный пример применения – язык Fortran. С каждой функцией связана в точности одна запись активации, поскольку статически невозможно создать большее, но заранее не известное количество записей активации, а создание ограниченного, но большего единицы количества записей никак не решает проблему рекурсивности вызовов, но приводит к росту накладных расходов. При статическом создании записей активации не может быть разрешен рекурсивный вызов функций. Записи активаций функций размещаются транслятором в области статических данных (см. рис. 8.6). Динамическое создание записей активации в куче во время исполнения программы предполагает наличие механизма управления кучей (библиотеки функций, выполняющих учет свободного пространства и обработки запросов на выделение связного блока требуемого размера и, возможно, освобождение ранее выделенного блока). Вполне вероятно, что куча будет использоваться не только для хранения записей активации, поэтому необходимо обеспечивать учет созданных записей (см. рис. 8.6, поле связи по управлению, которое в данном случае становится обязательным). Следовательно, реализация этого способа приводит к высоким накладным расходам по времени на вызовы, но обеспечивает наибольшую гибкость во взаимодействии вызывающих и вызываемых функций. В частности, при этом способе время жизни активации вызываемой функции в принципе может быть дольше, чем время жизни вызывающей ее активации (см. ниже). Возможна также реализация таких экзотических возможностей, как, например, сопрограммы. Средняя между предыдущими способами величина накладных расходов в сочетании с наиболее естественной текстуальной видимостью нелокальных данных обеспечивается при динамическом создании записей активации в стеке исполняемой программы. Аппаратная реализация стека минимизирует накладные расходы по времени на выделение памяти для записей активации вызываемых функций. Рекурсивные вызовы функций допускаются, при этом количество записей активации одной и той же функции может быть сколь угодно большим, и ограничиваться только размером области памяти, отведенной под стек программы. При создании записей активации функций в стеке последовательность их уничтожения обратна последовательности образования. Поэтому время жизни активации любой функции не может быть больше времени жизни активации вызывающей функции. Другими словами, две произвольные активации любых функций (возможно, одной функции) либо не пересекаются во времени, либо одна из них полностью вложена в другую. На рис. 8.7 показано перемещение потока управления между активациями двух функций во времени. 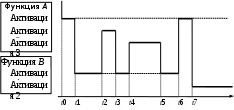 Внизу сплошной линией со стрелкой обозначена ось времени. Сплошные вертикальные линии показывают либо вызовы функций, либо возвраты из них. Жирными горизонтальными линиями показаны процессы исполнения соответствующих активаций функций. Пунктирными горизонтальными линиями для некоторых активаций выделены интервалы, когда активации существуют, но не исполняются, поскольку в это время процессор занят исполнением другой активации либо той же самой функции (интервалы t2 – t3 и t4 – t5 для активации 1 функции А), либо другой функции (интервалы t1 –t2, Внизу сплошной линией со стрелкой обозначена ось времени. Сплошные вертикальные линии показывают либо вызовы функций, либо возвраты из них. Жирными горизонтальными линиями показаны процессы исполнения соответствующих активаций функций. Пунктирными горизонтальными линиями для некоторых активаций выделены интервалы, когда активации существуют, но не исполняются, поскольку в это время процессор занят исполнением другой активации либо той же самой функции (интервалы t2 – t3 и t4 – t5 для активации 1 функции А), либо другой функции (интервалы t1 –t2, t3 –t4, t5 –t6 и t6 –… для активации 1 функции А, t2 –t3 и t4 –t5 для активации 1 функции В). Рис. 8.7. Времена жизни активаций функций Согласно дисциплине существования элементов стека после создания, к примеру, активации 2 функции А и до ее завершения не может завершиться существование ни активации 1 функции В, ни активации 1 функции А. Заметим, что и то и другое событие в принципе возможно при динамическом создании записей активаций функций в куче. Для реализации этих событий нужно просто обеспечивать явное уничтожение записей ненужных активаций и возвраты по адресам, предварительно взятым из них. На рис. 8.8. показана последовательность состояний стека программы, соответствующая моментам времени t0, … t7. Записи активаций обозначены буквенным названием функции (А или В) и порядковым номером активации. Для изображения того, как управление передается активациям и покидает их, может оказаться полезным так называемое дерево активаций. Это графическое представление процесса исполнения совокупности функций, для которого выполняются следующие условия:
Рис. 8.8. Последовательность состояний стека программы Корень дерева представляет активацию основной программы. Каждый узел представляет активацию функции. Узел А является родительским для узла В тогда и только тогда, когда поток управления передается из активации А в активацию В (узел В называется потомком узла А). Если два узла В и С являются потомками одного и того же узла, то узел В располагается слева от узла С тогда и только тогда, когда время жизни активации В начинается раньше времени жизни активации С. Поскольку каждый узел представляет единственную активацию, и наоборот, удобно говорить о том, что управление находится в узле, когда оно находится в активации, представленной этим узлом. Если пометить каждый узел дерева именем (обозначением) функции и порядковым (во времени) номером ее активации, то все узлы дерева будут иметь уникальные пометки. Фрагмент дерева активаций для случая, изображенного на рис. 8.7, может выглядеть так, как показано на рис. 8.9. 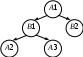 Рис. 8.9. Фрагмент дерева активаций Последовательность событий создания/уничтожения активаций функций может быть получена путем обхода дерева, начинающегося с корня и заключающегося в последовательном посещении всех поддеревьев каждой вершины строго слева направо. Размещение записей активации функций в стеке исполняемой программы наиболее часто используется в реализациях языков программирования общего назначения. Независимо от того, где хранятся записи активации в процессе исполнения программы, для любой из них должен быть отведен связный блок памяти такого размера, чтобы в нем размещались все поля записи. Другими словами – к моменту фактического выделения блока памяти под запись активации необходимо точно знать его требуемый размер, который равняется сумме размеров всех полей. Рассмотрим, каким образом определяются размеры полей локальных данных. Способы формирования полей промежуточных вычислений и фактических параметров будут рассмотрены позже. Остальные поля записи активации, как уже упоминалось, имеют фиксированные размеры. Локальные данные функций Для определения размера поля локальных данных транслятор должен разметить (распределить) его образ памяти. Для каждой функции этот процесс начинается с фиксации начального адреса образа памяти поля локальных данных, обычно равного сумме размеров всех предшествующих полей записи активации. Далее последовательно перебираются наименования объектов, ассоциации которых должны быть активными при исполнении инструкций функции. Текущее значение адреса первого свободного элемента (обычно – байта) памяти заносится в соответствующую объекту запись таблицы ассоциаций (обычно это просто таблица идентификаторов), из этой записи извлекается тип объекта, по нему определяется требуемое количество байт памяти и на это количество увеличивается счетчик занятых байт (т.е. указатель первого свободного байта). При генерации объектного кода сформированный таким образом адрес объекта будет использован в качестве смещения в любой команде, оперирующей с этим объектом. При исполнении программы в момент вызова функции адрес записи активации будет занесен в строго определенный регистр процессора (если записи активации размещаются в стеке, то для доступа к ним может использоваться указатель стека).
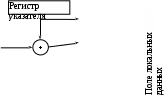
Рис. 8.10. Формирование исполнительного адреса, объект внутри поля локальных данных Для обеспечения этого транслятор формирует и помещает в точку входа в функцию дополнительные команды. Доступ к значению любого локального объекта осуществляется по адресу, вычисляемому как сумма базового адреса записи активации (из регистра процессора, специально выделяемого для этой цели) со смещением (из команды). Если стек растет в направлении увеличения адресов памяти, то все значения смещений будут отрицательными. Для ситуации, представленной на рис. 8.10, предполагается, что стек растет в сторону уменьшения адресов памяти, поэтому значения смещений положительны. Кажущаяся примитивность процесса формирования смещений локальных объектов осложняется двумя обстоятельствами. Первое состоит в том, что на компоновку памяти для объектов данных сильное влияние оказывают ограничения системы адресации целевого компьютера и/или требования оптимизации по времени выполнения. Пусть, например, выборка данных из памяти выполняется четырехбайтными кадрами, адрес первого из которых должен быть кратен четырем. В таком случае для доступа к двухбайтному целому значению может потребоваться два обращения к памяти, если его адрес нечетен. Такой случай возможен, если транслятор экономно использует память и размещает данные слитно. Если же при трансляции преследуется цель построения быстрой программы, то определение размера памяти, отводимой под каждый объект, должно производиться с учетом оптимального выравнивания адреса его первого байта. Второе усложняющее обстоятельство ранее уже упоминалось: если в функции в качестве локального объявлен динамический массив, у которого хотя бы одна граница изменения индекса зависит от значений фактических параметров, то во время трансляции размер этого массива определить невозможно. Следовательно, до момента вызова функции невозможно определить размер записи активации. Существует по меньшей мере два способа преодоления этой трудности. Независимо от того, какой способ применяется, в точку входа в функцию неявно для программиста транслятор добавляет инструкции, вычисляющие для каждого такого массива требуемый размер памяти. 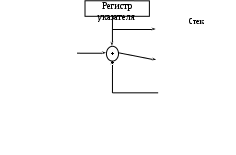 При первом способе (см. рис. 8.11) окончательное определение размера поля локальных данных и размера всей записи активации откладывается до момента входа в функцию. При первом способе (см. рис. 8.11) окончательное определение размера поля локальных данных и размера всей записи активации откладывается до момента входа в функцию. Рис. 8.11. Формирование исполнительного адреса, элемент динамического массива внутри поля локальных данных Ясно, что адреса всех таких массивов, кроме первого из них, не могут быть зафиксированы во время трансляции. Следовательно, машинные команды, оперирующие с элементами второго и всех последующих массивов, не могут быть построены тем же способом, что и команды, работающие с обычными локальными данными. Вызвано это тем, что для формирования исполнительного адреса элемента массива теперь приходится складывать три величины: базовый адрес записи активации; смещение первого элемента динамического массива внутри записи активации (вычисляется после входа в функцию и хранится в качестве локального объекта, построенного транслятором); смещение элемента массива (берется из команды либо вычисляется до ее выполнения, если транслятору неизвестны индексы этого элемента). Второй способ, показанный на рис. 8.12, состоит в том, что память для динамических массивов не резервируется в записи активации, а выделяется из кучи после того, как вычислен требуемый размер массива.  Рис. 8.12. Формирование исполнительного адреса, память для динамического массива выделяется из кучи В записи активации во время трансляции резервируется фиксированное количество байт памяти для хранения указателя на память, взятую из кучи. Указатель используется в командах, оперирующих с элементами массива, которые строятся транслятором не так, как команды, работающие с обычными локальными данными (в том числе массивами). Адрес памяти для доступа к элементу динамического массива при хранении его в куче вычисляется так: вначале известное транслятору смещение указателя массива складывается с адресом записи активации и используется для выборки адреса массива и помещения его в регистр процессора; затем значение этого регистра складывается со смещением нужного элемента массива и по полученному адресу извлекается операнд. Главным достоинством использования кучи для хранения динамических массивов является вычисление размера записи активации во время трансляции, а не во время исполнения программы. Вызывающие последовательности Вызовы функций реализуются путем исполнения так называемых вызывающих последовательностей команд. Эти последовательности размещаются частично в вызывающей, частично в вызываемой функции. Они обеспечивают передачу управления и данных из вызывающей функции в вызываемую (последовательность вызова), и наоборот – из вызываемой в вызывающую (последовательность возврата). Последовательность вызова создает запись активации и заполняет ее поля необходимой информацией. Последовательность возврата восстанавливает состояние машины таким образом, чтобы вызывающая функция могла продолжать исполнение. Последовательности вызовов и структура записи активации различаются даже в разных реализациях одного и того же языка. Коды в последовательностях вызова и возврата зачастую разделяются между вызывающей и вызываемой функциями. Не существует однозначного разграничения задач между вызывающей и вызываемой функциями – исходный язык, целевая машина и операционная система налагают свои требования, в силу которых может оказаться предпочтительным то или иное решение. Поскольку каждый вызов имеет собственные фактические параметры, вызывающая функция обычно вычисляет фактические параметры и передает их в запись активации вызываемой функции. В стеке времени исполнения запись активации вызывающей функции находится непосредственно под записью активации вызываемой функции, как показано на рис. 8.13. Размещение полей параметров и возможного возвращаемого значения вслед за записью активации вызывающей функции дает некоторый выигрыш за счет того что вызывающая функция может получить доступ к таким полям, используя только смещения от конца собственной записи активации. Для этого не нужна полная информация о компоновке записи активации вызываемой функции. В частности, при трансляции вызывающей функции, как правило, ничего не известно о локальных переменных вызываемой функции. Несмотря на то что размер поля для временных значений в конечном счете фиксируется во время компиляции, он может быть неизвестен вплоть до окончания этапов оптимизации и первой фазы генерации объектного кода. На этих этапах количество временных переменных для хранения промежуточных значений может быть уменьшено, а следовательно, на этапе семантического анализа размер этого поля может быть неизвестен. Поэтому поле временных переменных лучше размещать после поля локальных данных, поскольку изменения его размера не будут влиять на смещение прочих локальных объектов. Если вызов функции встречается в тексте программы n раз, то часть последовательности вызова в вызывающих функциях будет построена транслятором n раз, в то время как часть последовательности вызова в вызываемой функции генерируется лишь единожды. Следовательно, для экономии памяти желательно разместить как можно большую часть последовательности вызова в коде вызываемой функции. Однако, очевидно, не всю работу по организации вызова можно переложить на вызываемую функцию. Для выполнения всей работы необходимы два регистра процессора: указатель стека и указатель текущей записи активации. Указатель стека (УС) в любой момент времени разделяет занятое и свободное пространства в стеке и используется всегда для доступа к единственному объекту, находящемуся на верхушке стека. Он не может быть использован для доступа к любым другим объектам в силу того, что значение этого указателя постоянно изменяется в результате выполнения различных команд. Поэтому для хранения базового адреса записи активации, как правило, выделяется еще один регистр процессора – указатель записи активации (УЗ). С использованием двух регистров типичная последовательность действий по вызову функции выглядит так. Перед началом процесса вызова регистр УЗ указывает на конец поля состояния машины в записи активации. Вызывающая функция вычисляет фактические параметры и заносит их в стек, модифицируя УС. Вызывающая функция сохраняет адрес возврата и старое значение УЗ в записи активации вызываемой функции, после чего устанавливает значение УЗ равным значению УС, как показано на рис. 8.13. Таким образом, УЗ перемещается за локальные и временные данные вызывающей функции, параметры и поле состояния машины вызываемой функции. Управление передается вызываемой функции, которая сохраняет в стеке значения регистров и другую информацию о состоянии машины и модифицирует УС таким образом, чтобы зарезервировать место под свои локальные данные и временные значения. Вызываемая функция инициализирует локальные данные и переходит к исполнению своего тела. 
Рис. 8.13. Разделение задач между вызывающей и вызываемой функциями Возможная последовательность возврата из функции выглядит следующим образом. Вызываемая функция размещает возвращаемое значение после записи активации вызывающей программы. Используя информацию в поле состояния машины, вызываемая функция восстанавливает УЗ и другие регистры и передает управление по адресу возврата в коде вызывающей функции. Хотя значение УЗ было уменьшено, вызывающая функция может скопировать возвращаемое значение в собственную запись активации и использовать его в вычислениях. Приведенные выше последовательности вызова позволяют реализовывать функции с переменным числом аргументов. Транслятор, обрабатывая вызывающую функцию, может подсчитать количество фактических параметров. Следовательно, при формировании кода вызывающей функции ему известен размер поля параметров, который может быть неявно передан тоже в виде параметра. Теперь остается только таким образом формировать код вызываемой функции, чтобы он правильно обрабатывал неизвестное при трансляции, но получаемое в момент вызова количество параметров. Другой возможный вариант способа реализации переменного количества параметров – функции типа printf в языке С. Первый параметр такой функции содержит перечень и типы остальных параметров в виде текстовой строки. Поэтому, как только код тела функции printf выбирает первый параметр, он может по нему определить способ доступа к произвольному количеству остальных параметров. Доступ к нелокальным объектам Правила области видимости языка определяют способ работы со ссылками на нелокальные объекты – такие, объявления которых находятся вне текста функции, в которой объект используется. Существует общее правило, именуемое правилом текстуальной (или статической) области видимости, согласно которому видимость любого объекта определяется исключительно расположением его объявления в тексте программы. В языках Pascal, С и Ada и многих других используется текстуальная область видимости с добавлением правила «ближайшее вложенное». В некоторых языках программирования используется другое правило динамической области видимости, при котором ассоциация наименования любого объекта с его объявлением определяется не текстом программы, а совокупностью имеющихся на данный момент активаций функций. Согласно этому правилу доступ к значению нелокального объекта осуществляется путем поиска его имени в таблицах, ассоциированных с активациями функций. Просмотр активаций функций должен осуществляться в заранее обусловленной последовательности. Правило динамической области видимости используется в таких языках, как Lisp, APL и Snobol. Исторически понятие нелокальных объектов появилось в языке Algol и связано с впервые введенной в этом языке конструкцией блоков. Блок представляет собой последовательность инструкций, содержащую объявления собственных локальных данных. Основная отличительная особенность понятия блока заключается во вложенности структуры. Блоки либо следуют друг за другом, либо один блок является полностью вложенным в другой. Невозможно такое перекрытие блоков В1 и В2, при котором первым по тексту начинается блок В1, после чего начинается блок В2, затем заканчивается блок В1, а затем – В2. Начало и конец блока оформляются специальными ограничителями (в С для этой цели используются фигурные скобки { и }; в Algol и Pascal – ключевые слова begin и end). Блочные области видимости Область видимости любого объекта в языке с блочной структурой определяется правилом ближайшего вложенного, суть которого состоит в следующем: Область видимости объявления в блоке В включает весь блок В. Если объект х не объявлен в блоке В, то все появления имени х в В находятся в области видимости объявления х во внешнем окружающем блоке Во, таком, что: Во содержит объявление объекта с именем х; Во является ближайшим окружающим В блоком среди всех, содержащих объявление х. Для пояснения того, как действует правило ближайшего вложенного, приведем следующий фрагмент программы на языке С (рис. 8.14). В нем каждое объявление инициализирует объявляемый объект числом, равным номеру блока, в котором оно появляется. Обратим внимание на то, что область видимости целой переменной b, объявленной в блоке В0, не включает блока В1, поскольку в блоке В1 объявлена другая переменная с тем же именем b. Такой разрыв называется «дырой» в области видимости объявления. main() 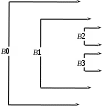 {int a=0; {int a=0;int b=0; {int b=1; {int a=2; printf(“a=%d b=%d\n”,a,b); } {int b=3; printf(“a=%d b=%d\n”,a,b); } printf(“a=%d b=%d\n”,a,b); } printf(“a=%d b=%d\n”,a,b); } Рис. 8.14. Блоки и видимость переменных в С-программе Всего в этом тексте объявлено пять разных объектов, области видимости которых приведены в табл. 8.2:  Таблица 8.2
Результаты работы этой программы иллюстрируют правило «ближайшего вложенного». При ее исполнении управление передается внутрь блока из точки, находящейся непосредственно перед ним, а затем из блока возвращается в точку, следующую прямо за ним в исходном тексте. Инструкции печати выполняются в последовательности В2, В3, В1 и В0 (в порядке, в котором завершается исполнение блоков). Значения переменных а и b в этих блоках показаны в табл. 8.3.  Таблица 8.3
Блочная структура программы может быть реализована с использованием стекового распределения памяти. Поскольку область видимости объявления не выходит за пределы того блока, в котором оно записано, память для объявленного объекта может быть выделена при входе в блок и освобождена при выходе из него. Это эквивалентно использованию блока как «процедуры/функции без параметров», вызываемой только из одной точки непосредственно перед блоком и возвращающей управление в точку непосредственно за блоком. Нелокальная среда ссылок для блока может поддерживаться с использованием технологий для функций, которые будут рассмотрены в этой главе ниже. Заметим, что с точки зрения разработчика транслятора реализация блоков несколько проще, чем реализация функций, поскольку блокам не передаются параметры, а поток управления строго следует статическому тексту программы (не осуществляются передачи управления). Другая возможная реализация программ с блочной структурой состоит в однократном выделении памяти для всех локальных объектов функции в тот момент, когда ей передается управление. При наличии блоков в функции размер поля локальных данных ее записи активации рассчитывается транслятором с учетом всех объявлений внутри блоков. Для переменных программы, приведенной на рис. 8.14, можно выделить память так, как показано на рис. 8.15. Индексы у локальных переменных а и b на этом рисунке соответствуют блоку, в котором они объявлены.
Рис. 8.15. Локальные объекты в записи активации Заметим, что для объектов a2 и b3 может быть отведена одна и та же область памяти, поскольку блоки B2 и B3 не пересекаются. При отсутствии динамических массивов (и других данных переменной длины) максимальное количество памяти, необходимой для выполнения блока, может быть определено в процессе компиляции (с данными переменной длины можно работать, используя указатели). Определение этого размера транслятор должен выполнять исходя из предположения, что при исполнении программы будут пройдены все возможные пути управления по тексту функции. Текстуальная область видимости без вложенных функций Для изучения того, каким образом реализуется видимость нелокальных объектов в языке, не допускающем текстуально вложенных функций, рассмотрим программу сортировки элементов массива на языке С (рис. 8.16). Эта программа предназначена для демонстрационных целей, ее не следует (как и приведенную ниже программу на языке Pascal) рассматривать в качестве образца программирования или реализации методов сортировки. Правила текстуальной области видимости в языке С проще, чем в языке Pascal (для языка Pascal они обсуждаются позже) вследствие того, что определение функции не может находиться внутри другой функции. Если в некоторой функции используется не объявленный в ней объект X, то предполагается, что его объявление находится вне любой функции. Область видимости любого такого объявления состоит из тел функций, следующих за ним (объявлением) по тексту файла (с дырами, если внутри функций имеются объявления объектов с точно такими же именами). int arr[ ]; void ReadArray(void) { ... аrr ... } int PartExch(int iBeg,int iEnd) { int i, j, k, mVal; i=iBeg; j=iEnd; mVal=arr[i+(j-i)/2]; while(i for( ;arr[i] for( ;arr[j]>mVal;j-=1); if(i } //end while return i; } //end PartExch void QuickSort(int iBeg,int iEnd) { int iMid; if(iBeg iMid=PartExch(iBeg,iEnd); if(iBeg if(iMid+1 } } //end QuickSort void main() { ReadArray();QuickSort(0,(sizeof(arr)/sizeof(int))-1); } //end main Рис. 8.16. С-программа с нелокальным массивом arr При отсутствии вложенных функций для языка с текстуальными областями видимости можно использовать стратегию стекового распределения памяти для локальных объектов. Память для объектов, объявленных вне функций, может быть выделена статически. Положение этой памяти известно в процессе компиляции, так что даже если некоторый объект нелокален в теле данной функции, транслятор будет использовать статически определенный адрес объекта для построения команд, оперирующих с его значением. Важное преимущество статического выделения памяти для нелокальных объектов заключается в том, что любые функции могут свободно передаваться в качестве параметра другим функциям и возвращаться как результат вызова (в языке С функция передается как параметр путем передачи указателя на нее). При использовании текстуальной области видимости и отсутствии вложенных функций любой нелокальный для одной функции объект является нелокальным и для всех остальных функций, а следовательно, его статический адрес может использоваться всеми функциями одинаково и независимо от того, каким образом они активируются. Это справедливо для любой функции, в том числе и для функций, которые вызываются по вычисляемым ссылкам. Доступ к другим элементам среды ссылок следует изучить по [6-9]. Порядок выполнения работы (рекомендуется использовать в качестве примера систему правил Samples/Sample8): Расширить систему действий синтаксического анализатора, построенного при выполнении лабораторных работ 3 – 7, действиями для исполнения последовательности тетрад (триад/пентад согласно варианту задания на курсовую работу); Обеспечить выполнение некоторых семантических проверок для выявления ошибок времени исполнения при интерпретации; Построить интерпретатор (виртуальную машину) для учебного языка или его подмножества, убедиться в его работоспособности. Подготовить, сдать и защитить отчет к лабораторной работе. Требования к содержанию отчета. Отчет должен содержать: цель работы; краткое изложение задач, возникающих при интерпретации псевдокода; описание структур данных и алгоритмов совокупности действий, разработанных для реализации виртуальной машины для заданного варианта учебного языка; выводы и заключение. Контрольные вопросы Что такое побочный эффект вызова процедуры/функции? Что такое глобальный, локальный и нелокальный объект? Что такое текстуальная область видимости без вложенных функций? Что такое передача аргумента по имени? Как она реализуется? Перечислите способы передачи аргументов в функцию. Что такое жизненный цикл наименования объекта? Что такое кодированное представление типов данных? В чем состоят его достоинства и недостатки? Что такое вложенность процедур/функций? Что такое нелокальная среда ссылок? Расшифруйте словами тип данных языка С: (int*[](unsigned)). Что такое именное представление типов данных? В чем состоят его достоинства и недостатки? Что такое передача аргументов методом копирование-восстановление? Что такое запись активации процедуры/функции? Как делится ответственность за формирование записи активации между вызывающей и вызываемой функциями? Что такое дерево активации функций? Перечислите минимально необходимые поля записи активации функции. Что такое блочная область видимости переменной? Что такое вызывающая последовательность? Что такое l-value и r-value? ЛитератураМалявко А.А. Формальные языки и компиляторы: учебное пособие для вузов. – М., Изд-во Юрайт, 2021 Малявко А.А. Формальные языки и компиляторы: учебник НГТУ. – Изд-во НГТУ, 2014, 004 М219, Id = 000184529 Малявко А.А. Системное программное обеспечение. Формальные языки и методы трансляции: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2010. – Ч.1, 004 M 219, Id = 143812 Малявко А.А. Системное программное обеспечение. Формальные языки и методы трансляции: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2011. – Ч.2, 004 M 219, Id=155235 Малявко А.А. Системное программное обеспечение. Формальные языки и методы трансляции: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2012. – Ч.3, 004 M 219, Id=170641 Ахо А., Сети Р., Ульман Д. Компиляторы: принципы, технологии и инструменты. – М.: «Вильямс», 2001, Id=16803 Карпов Ю.Г. Теория и технология программирования. Основы построения трансляторов: учеб. пособие. – СПб.: БХВ-Петербург, 2005, Id=64347 Свердлов С. З. Языки программирования и методы трансляции: учебное пособие для вузов - СПб., 2007, Id=65534 Гавриков М.М., ИванченкоА.Н., Гринченков Д.В. Теоретические основы разработки и реализации языков программирования. – М.: Кнорус, 2010. |