Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214
 Скачать 452.53 Kb. Скачать 452.53 Kb.
|

Лабораторная/практическая работа № 7Название работы: «Семантика языков программирования. Семантический анализ и генерация псевдокода». Цели работы: изучение семантических свойств объектов транслируемой программы, методов их выявления и использования, типов данных и методов контроля типов, областей видимости переменных, локальных и нелокальных сред ссылок, способов передачи параметров, приобретение навыков преобразования ПФЗ в псевдокод. Основные теоретические сведения: Задачи семантического анализа Совокупность исходных данных для семантического анализа формируется предыдущими этапами процесса трансляции. Постфиксная форма записи (ПФЗ) или ее эквивалент – синтаксическое дерево транслируемой программы – промежуточное представление, которое образуется в процессе синтаксического анализа. Набор информационных таблиц, в которых накоплены сведения об используемых программой данных. Постфиксная форма записи обладает замечательным свойством: в ней порядок следования знаков операций строго совпадает с предусматриваемой алгоритмом решения задачи последовательностью их выполнения (в отличие от исходного текста программы, где этого обычно и не требуется). Реальное исполнение выявленной транслятором последовательности операций с целью преобразования исходных данных транслируемой программы в ее результаты возможно различными способами, все множество которых принято делить на две основные группы – компиляция и интерпретация. Компиляция – продолжение преобразований представления программы на стадии трансляции, завершающееся формированием и сохранением так называемого объектного (целевого) кода, который впоследствии может многократно исполняться процессором компьютера (реальной машиной) уже без какого бы то ни было участия транслятора. Интерпретация – исполнение последовательности операций непосредственно транслятором (прямая интерпретация) или специально разработанной для этого программой (так называемой виртуальной машиной – отложенная интерпретация), возможно, с предварительным преобразованием постфиксной записи в более удобную промежуточную или сохраняемую форму. Четкой границы между компиляцией и интерпретацией не существует. На практике, как правило, реализуются смешанные варианты последовательности действий трансляции/исполнения. Например, в скомпилированных программах обычно содержатся вызовы функций из библиотек так называемого run-time окружения (поддержки), которые, по существу, интерпретируют операции, являющиеся примитивными в языке программирования, но не реализуемые аппаратурой компьютера на уровне машинных команд. Для обеспечения исполнения подобных операций транслятор вставляет в компилируемый им объектный код команды вызова таких интерпретирующих функций. В свою очередь, многие системы программирования (такие как Visual Basic), которые первоначально были ориентированы на прямую интерпретацию, впоследствии приобрели ряд признаков компиляции, выполняя перевод текста программы в псевдокод (или байт-код). Псевдокод сохраняется во внешней памяти и может многократно интерпретироваться виртуальной машиной уже без использования таких частей транслятора, как лексический и синтаксический анализаторы. Для того чтобы исполнять программу в целом (после компиляции или при отложенной интерпретации) или даже по частям (при прямой интерпретации), необходимо предварительно убедиться в том, что каждая исполняемая операция действительно может быть применена к значениям своих операндов и сформировать требуемый результат. Именно это является основной целью семантического анализа. Таким образом, в логической последовательности этапов процесса трансляции семантический анализ занимает позицию непосредственно после синтаксического и перед генерацией объектного кода в случае компиляции либо перед исполнением вычислений в случае интерпретации. Реальная последовательность выполнения этапов при трансляции совсем не обязательно совпадает с логической последовательностью. Семантическая проверка некоторого фрагмента программы может предшествовать во времени синтаксическому анализу последующего по тексту фрагмента и/или осуществляться после интерпретации текстуально предыдущего фрагмента (или его преобразования в объектный код). Однако применительно к каждому конкретному синтаксически целостному фрагменту текста (модулю/файлу, подпрограмме/функции, блоку, оператору, …) логическая последовательность этапов трансляции всегда строго соблюдается. Преобразуются в объектный код при компиляции или исполняются при интерпретации только те фрагменты текста, для которых все этапы анализа (лексический, синтаксический и семантический) завершились успешно. В том случае если возможно выполнение всех этапов анализа произвольного фрагмента текста программы без обработки всего ее текста целиком, говорят, что язык допускает однопроходную трансляцию. Ряд языков (Pascal, С и др.) был спроектирован таким образом, чтобы обеспечить возможность быстрой однопроходной трансляции. Однако существуют и такие языки программирования, в которых выполнение всех функций анализа некоторого фрагмента текста программы невозможно без предварительной обработки последующих фрагментов для извлечения и накопления сведений об используемых объектах и их свойствах (например, Алгол-68 или Ада). Трансляторы с таких языков вынужденно реализуют более чем один проход по тексту программы (или по одному из ее промежуточных представлений – последовательности токенов (лексем), постфиксной записи, …). Увеличение количества проходов, с одной стороны, приводит к росту затрат времени на трансляцию программ и сложности транслятора, а с другой – хорошо согласуется с потребностями алгоритмов оптимизации программы. Семантический анализатор транслятора в процессе проверки правильности транслируемой программы осуществляет преобразование ее постфиксной формы записи (или эквивалента ПФЗ – дерева операций), формируемой синтаксическим анализатором, в псевдокод, как показано на рис. 7.1. 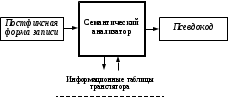 Рис. 7.1. Структура семантического анализатора Например, пусть транслятор с языка С/С++ обрабатывает функцию вычисления наибольшего общего делителя двух аргументов: int nod( int first, int second ){ while ( first != second ) if ( first < second ) second –= first; else first –= second; return first; } Постфиксная запись этой функции, построенная синтаксическим анализатором, может выглядеть так: nod int functionActivate first int getArgument second int getArgument label#0#0: first second != label#0#1 jmpOnFalse first second < label#1#0 jmpOnFalse second first –= label#1#1 jmp label#1#0: first second –= label#1#1: label#0#0 jmp label#0#1: first return Здесь: nod int functionActivate first int getArgument second int getArgument – ПФЗ заголовка функции; label#0#0: first second != label#0#1 jmpOnFalse – ПФЗ заголовка оператора цикла; first second < label#1#0 jmpOnFalse second first –= label#1#1 jmp label#1#0: first second –= label#1#1: – ПФЗ условного оператора, составляющего тело цикла; label#0#0 jmp – ПФЗ завершения оператора цикла; label#0#1: first return – ПФЗ оператора возврата значения функции. В этой форме записи для наглядности подчеркнуты все знаки операций. Большинство знаков операций (functionActivate, getArgument, !=, jmpOnFalse, <, –=) являются бинарными, но есть и унарные знаки (jmp и return). Требуемая последовательность выполнения операций программы выявлена и зафиксирована в постфиксной форме записи, что позволит впоследствии построить последовательность машинных команд, которые процессор будет выбирать из рядом расположенных ячеек памяти. Однако с этой формой записи могут быть связаны и другие проблемы. Рассмотрим, например, фрагмент ПФЗ заголовка цикла: label#0#0: firstsecond!=label#0#1 jmpOnFalse У бинарного знака операции jmpOnFalse в этом фрагменте первым операндом является другой бинарный знак операции !=. В действительности это означает, что первым операндом операции jmpOnFalse является булево значение, вырабатываемое операцией сравнения. Это значение должно быть сохранено либо в стеке времени выполнения, либо в переменной, формируемой транслятором. Для того чтобы выявить все такие переменные и выполнить соответствующие семантические проверки, транслятором формируется очередное внутреннее представление текста программы, называемое псевдокодом. Псевдокод – это последовательность операций в системе команд некоторой виртуальной машины. Эта машина может быть, например, трехадресной, в этом случае каждая ее команда включает в себя 4 поля (и называется тетра дой): код операции, наименования двух операндов и наименование результата. Фрагмент псевдокода тела функции вычисления наибольшего общего делителя для такой виртуальной машины может выглядеть так, как показано в табл. 7.1. Виртуальная машина, псевдокод которой показан в этой таблице, является стековой. Результаты некоторых операций заносятся в стек с помощью указания имени верхушки стека push и извлекаются из стека в последующих тетрадах с использованием другого имени верхушки стека pop. Недостатком тетрад является то, что для объявления имени (метки) какой-либо операции приходится добавлять специальную тетраду с кодом операции «Создать метку». Этого недостатка лишены виртуальные машины, у которых каждая операция имеет дополнительной поле метки. Команды такой виртуальной машины называют пентадами (по количеству полей). Таблица 7.1.
В табл. 7.2. показан псевдокод той же функции в виде последовательности пентад. Количество операций уменьшилось за счет удаления операций «Создать метку». В этом варианте виртуальной машины для хранения промежуточных результатов вычислений вместо стека используются временные переменные, создаваемые семантическим анализатором транслятора. Таблица 7.2
Возможны и другие варианты организации виртуальных машин. Пример псевдокода той же функции для виртуальной машины, операции которой (триады) не имеют ни поля метки, ни поля наименования результата, показан в табл. 7.3. Таблица 7.3.
В этом примере вместо имен операций и промежуточных результатов используется относительная адресация. Числа вида +8 или –1 в полях наименований операндов означают указание триады, находящейся на расстоянии 8 вперед или 1 назад по отношению к текущей триаде. Если относительный номер триады используется в операции преобразования данных, то под ним понимается результат, вырабатываемый адресуемой триадой. Все три вида промежуточного представления программы – тетрады, триады и пентады примерно одинаковым образом могут быть получены из постфиксной записи. Рассмотрим один из алгоритмов такого преобразования. Преобразование постфиксной записи в последовательность тетрад Шаг 1. Подготовка. Очистка стека, установка первого слова постфиксной записи в качестве текущего. Шаг 2. Выявление назначения текущего слова ПФЗ. Если это наименование операнда, то переход к шагу 3, иначе (знак операции) – к шагу 4. Шаг 3. Текущее слово заносится в стек и удаляется с входа (текущим становится следующее слово ПФЗ). Возврат к шагу 2. Шаг 4. Знак операции удаляется с входа и заносится в тетраду. Определяется арность этого знака операции, далее формируются наименования операндов тетрады согласно выявленному случаю. Случай 0 – оба наименования операндов устанавливаются равными null. Случай 1 – с верхушки стека снимается одно наименование и заносится в тетраду в качестве первого операнда, в качестве второго операнда устанавливается null. Случай 2 – с верхушки стека снимаются два наименования и заносятся (в порядке извлечения из стека) в тетраду в качестве операндов. Случай k>2 – с верхушки стека снимаются k слов, для каждого строится вспомогательная тетрада со знаком операции присваивания, снятым со стека наименованием в качестве первого операнда, значением null в качестве второго операнда и наименованием формального аргумента процедуры/функции в качестве результата. Каждая вспомогательная тетрада выдается на выход. После этого формируется тетрада с наименованием процедуры/функции в качестве знака операции и пустыми (null) наименованиями операндов. Если для знака операции последней сформированной тетрады подразумевается образование промежуточного результата вычислений, то создается, заносится в таблицу идентификаторов и записывается в тетраду наименование результата, иначе в качестве наименования операнда используется последний снятый со стека операнд. Построенная тетрада выдается на выход. Шаг 5. Если был достигнут конец входной ПФЗ, то выполняется останов процесса преобразования, иначе – переход к шагу 2. Конец алгоритма. Следует отметить, что этим алгоритмом не предусматривается никаких проверок корректности входной постфиксной записи. ПФЗ формально является корректной, если для любого знака операции на шаге 4 из стека удается извлечь соответствующее его арности количество наименований операндов и если в момент завершения преобразования стек оказывается пустым. Предполагается, что ПФЗ строится в процессе синтаксического анализа и является правильной, если транслируемая программа не содержит синтаксических ошибок. В том случае, если это предположение несправедливо, легко можно дополнить данный алгоритм соответствующими проверками состояния стека. Кроме того, заметим, что для случая k-арного знака операции при k> 2 возможна модификация соответствующего случая шага 4 алгоритма, согласно которой строится k – 2 вспомогательных тетрады, а 2 последних извлекаемых из стека слова используются в качестве наименований операндов последней формируемой тетрады. В рассматриваемом ниже примере это привело бы к исчезновению тетрад 3 и 4 и замене обозначений null на x в поле операнд1 и на y в поле операнд2 тетрады. Теперь, когда мы выяснили как выглядит внутреннее представление транслируемой программы в виде псевдокода, основную функцию семантического анализа можно определить так. Для каждой операции виртуальной машины требуется: определить тип данных первого операнда; определить тип данных второго операнда; проверить, применим ли код операции к данным этих типов; сформировать и запомнить тип данных результата операции. Все эти задачи можно решать и прямо в процессе формирования операций псевдокода. Аналогичным образом можно преобразовывать ПФЗ в пентады и различные виды триад. Порядок выполнения работы (рекомендуется использовать в качестве примера систему правил Samples/Sample7): Расширить ранее разработанную грамматику путем включения в нее действий для выполнения статических семантических проверок, соответствующих заданному варианту курсовой работы. Реализовать преобразование постфиксной записи транслируемой программы в псевдокод в формате, заданном вариантом курсовой работы. Построить компилятор с учебного языка на псевдокод, убедиться в его работоспособности на тестовых примерах программ на учебном языке. Подготовить, сдать и защитить отчет к лабораторной работе. Требования к содержанию отчета. Отчет должен содержать: цель работы; краткое изложение задач семантического анализа; описание структур данных и алгоритмов совокупности действий, разработанных для реализации семантического анализатора по заданному варианту курсовой работы; результаты тестирования разработанного транслятора в виде связанного описания фрагментов ПФЗ и полученных из нее фрагментов псевдокода; выводы и заключение. Контрольные вопросы В чем состоят функции контроля структуры программы? Перечислите известные Вам способы представления типов данных. Что такое тетрада? Опишите этапы алгоритма преобразования постфиксной записи в последовательность тетрад. Перечислите известные Вам способы образования производных типов данных. |
