лабораторки MPI. Принципы работы mpi в операционной системе Windows Краткая теория
 Скачать 0.61 Mb. Скачать 0.61 Mb.
|

|
Декартова функция разбиения MPI_CART_SUB(comm, remain_dims, newcomm) IN comm communicator для декартовой топологии IN remain_dims i-й элемент remain_dims определяет соответствующую i-ю размерность включаемую в подрешетку (true) или не включаемую (false) OUT newcomm communicator созданных подрешеток int MPI_Cart_sub(MPI_Comm comm, int *remain_dims, MPI_Comm *newcomm) Если декартова топология была создана функцией MPI_CART_CREATE, то может использоваться функция MPI_CART_SUB для разбиения группы, связанной коммуникатором, на подгруппы, которые формируют декартовы подрешетки меньшей размерности, и строить для каждой такой подгруппы коммуникатор, связанный с подрешеткой декартовой топологии. Этот запрос коллективный. ПРИМЕР 3.1. Предположим, что MPI_CART_CREATE(...,comm) определяет (2 х 3 х 4) решетку. Допустим remain_dims =(true, false, true). Тогда запрос к MPI_CART_SUB(comm, remain_dims, comm_new) создаст три коммуникатора каждый с восьмью процессами 2 х 4 в декартовой топологии. Если remain_dims =(false, false, true), то запрос к MPI_CART_SUB(comm, remain_dims, comm_new) создаст шесть непересекающихся коммуникаторов, каждый с четырьмя процессами, в одномерной декартовой топологии. ПРИМЕР 3.2. … int rem[3], dims[3], period[3], reord, i, j; MPI_Comm comm_3D, comm_2D[3], comm_1D[3]; … MPI_Cart_create(MPI_COMM_WORLD, 3, dims, period, reord, &comm_3D); … for(i = 0; i < 3; j++) { for(j = 0; j < 3; j++) rem[j] = (i != j); MPI_Cart_sub(comm_3D, rem, &comm_2D[i]); } for(i = 0; i < 3; j++) { for(j = 0; j < 3; j++) rem[j] = (i == j); MPI_Cart_sub(comm_3D, rem, &comm_1D[i]); } Функции создания топологии графа Функция построения графа MPI_GRAPH_CREATE(comm_old, nnodes, index, edges, reorder, comm_graph) IN comm_old входной коммуникатор IN nnodes количество узлов в графе IN index целочисленный массив для описания узлов графа IN edges целочисленный массив для описания ребер графа IN reorder переупорядочить ранги (true) или нет (false) OUT comm_graph коммуникатор с топологией построенного графа int MPI_Graph_create(MPI_Comm comm_old, int nnodes, int *index, int *edges, int reorder, MPI_Comm *comm_graph) MPI_GRAPH_CREATE возвращает новый коммуникатор, к которому присоединена информация топологии графа. Если reorder==false, то ранг каждого процесса в новой группе идентичен ее рангу в старой группе. Иначе, функция может переупорядочивать процессы. Если размер, nnodes, графа меньше чем размер группы comm_old, то некоторые процессы возвращают MPI_COMM_NULL. Запрос ошибочен, если он определяет граф, который является большим, чем размер группы определяемой comm_old. Эта функция коллективная. Три параметра nnodes, index и edges определяют структуру графа. nnodes - число узлов графа. Узлы маркируются от 0 до nnodes-1. i-й элемент массива index хранит общее число соседей первых i узлов графа. Списки соседних узлов 0,1,...,nnodes-1 хранятся в массиве edges. Массив edges - сжатое представление списков ребер. Общее число элементов в index равно nnodes, и общее число элементов в edges равно числу ребер графа. Определения аргументов nnodes, index, и edges иллюстрируются ниже в примере 1.5. ПРИМЕР 3.3. Предположим, что имеются четыре компьютера 0, 1, 2, 3 со следующей матрицей смежности:
Тогда, входные аргументы будут иметь следующие значения: nnodes = 4 index = (2, 3, 4, 6) edges = (1, 3, 0, 3, 0, 2) Функции запроса графа Если топология графа установлена, может быть необходимо запросить информацию относительно топологии. Эти функции даются ниже и все - локальные вызовы. MPI_GRAPHDIMS_GET(comm, nnodes, nedges) IN comm коммуникатор группы, связанной с графом OUT nnodes количество узлов в графе OUT nedges количество ребер в графе int MPI_Graphdims_get(MPI_Comm_comm, int *nnodes, int *nedges) MPI_GRAPHDIMS_GET(COMM, NNODES, NEDGES, IERROR) INTEGER COMM, NNODES, NEDGES, IERROR MPI_GRAPHDIMS_GET возвращает число узлов и число ребер в графе. Число узлов идентично размеру группы, связанному с comm. nnodes и nedges используются, чтобы снабдить массивы надлежащего размера для index и edges, соответственно, в функции MPI_GRAPH_GET. MPI_GRAPHDIMS_GET возвратил бы nnodes = 4 и nedges = 6 в примере 1.5. MPI_GRAPH_GET(comm, maxindex, maxedges, index, edges) IN comm коммуникатор группы со структурой графа IN maxindex длина вектора index в вызвавшей программе IN maxedges длина вектора edges в вызвавшей программе OUT index массив чисел, определяющих узлы графа OUT edges массив чисел, определяющих узлы графа int MPI_Graph_get(MPI_Comm comm, int maxindex, int maxedges, int *index, int *edges) MPI_GRAPH_GET(COMM, MAXINDEX, MAXEDGES, INDEX, EDGES, IERROR) INTEGER COMM, MAXINDEX, MAXEDGES, INDEX(*), EDGES(*), IERROR MPI_GRAPH_GET возвращает index и edges какими они были в MPI_GRAPH_CREATE. maxindex и maxedges по крайней мере такие же как nnodes и nedges, соответственно, какие возвращаются функцией MPI_GRAPHDIMS_GET. Неблокированные посылающая и получающая функции Можно улучшить выполнение многих программ, выполняя обмен данными и вычисления с перекрытием, т.е. параллельно. Это особенно хорошо реализуется на системах, где связь может быть выполнена автономно от работы компьютера. Многоподпроцессный режим - один из механизмов для достижения такого перекрытия. В то время как один из подпроцессов блокирован, ожидая завершения связи, другой подпроцесс может выполняться на том же самом процессоре. Этот механизм эффективен, если система поддерживает многоподпроцессный режим. Неблокированные функции MPI_ISEND(buf, count, datatype, dest, tag, comm, request) IN buf адрес посылаемого буфера IN count количество элементов в посылаемом буфере IN datatype тип элементов в передаваемом буфере IN dest номер принимающего процессора IN tag тег передаваемых данных IN comm имя коммуникатора связи (communicator) OUT request имя (заголовка) запроса int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) Неблокированая передача данных, инициализирует посылающее действие, но не заканчивает его. Функция возвратит управление прежде, чем сообщение скопировано вне посылающегося буфера. Неблокированная посылающая функция указывает, что система может начинать копировать данные вне посылающегося буфера. Посылающий процесс не должен иметь доступ к посылаемому буферу после того, как неблокированное посылающее действие инициировано, до тех пор, пока функция завершения не возвратит управление. MPI_IRECV(buf, count, datatype, source, tag, comm, request) OUT buf адрес буфера приема данных IN count максимальное количество принимаемых элементов IN datatype тип принимаемых элементов IN source номер передающего процесса IN tag тег сообщения IN comm имя коммуникатора связи (communicator) OUT request имя (заголовка) запроса int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) Неблокированый прием данных, инициализирует получающее действие, но не заканчивает его. Функция возвратит управление прежде, чем сообщение записано в буфер приема данных. Неблокированная получающая функция указывает, что система может начинать писать данные буфер приема данных. Приемник не должен иметь доступ к буферу приема после того, как неблокированное получающее действие инициировано, до тех пор, пока функция завершения не возвратит управление. Эти обе функции размещают данные в системном буфере, и возвращают заголовок этого запроса в request. request используется, чтобы опросить состояние связи. Функции завершения неблокированных операций Чтобы закончить неблокированные посылку и получение данных, используются завершающие функции MPI_WAIT и MPI_TEST. Завершение посылающего процесса указывает, что он теперь свободен к доступу посылающегося буфера. Завершение получающего процесса указывает, что буфер приема данных содержит сообщение, приемник свободен к его доступу. MPI_WAIT(request, status) INOUT request имя запроса OUT status статус оъекта int MPI_Wait(MPI_Request *request, MPI_Status *status) Запрос к MPI_WAIT возвращает управление, после того как операция, идентифицированная request, выполнилась. То есть это блокированная функция. Если объект системы, указанный request был первоначально создан неблокированными посылающей или получающей функциями, то этот объект освобождается функцией MPI_WAIT, и request устанавливается в MPI_REQUEST_NULL. Статус объекта содержит информацию относительно выполненной операции. MPI_TEST(request, flag, status) INOUT request имя запроса OUT flag true, если операция выполнилась, иначе false OUT status стаус объекта int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) Запрос к MPI_TEST возвращает flag = true, если операция, идентифицированная request, выполнилась. В этом случае, статус состояния содержит информацию относительно законченной операции. Если объект системы, указанный request был первоначально создан неблокированными посылающей или получающей функциями, то этот объект освобождается функцией MPI_TEST, и request устанавливается в MPI_REQUEST_NULL. Запрос возвращает flag = false, если операция не выполнилась. В этом случае, значение статуса состояния неопределено. То есть это не блокированная функция. Синхронные посылающие функции MPI_SSEND(buf, count, datatype, dest, tag, comm) IN buf адрес передаваемого буфера IN count количество передаваемых элементов IN datatype тип передаваемых элементов IN dest ранг приемника IN tag тег сообщения IN comm коммуникатор (communicator) int MPI_Ssend(void* buf, int count, MPI_Datatype datatype,intdest, int tag, MPI_Comm comm) MPI_SSEND - блокированная, синхронная функция передачи данных. MPI_ISSEND(buf, count, datatype, dest, tag, comm, request) IN buf адрес передаваемого буфера IN count количество передаваемых элементов IN datatype тип передаваемых элементов IN dest ранг приемника IN tag тег сообщения IN comm коммуникатор (communicator) OUT request заголовок запроса int MPI_Issend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) MPI_ISSEND - неблокированная, синхронная функция передачи данных. Если соответствующей принимающей функцией является неблокированная принимающая функция MPI_IRECV, то передающая функция MPI_ISSEND синхронизуется с переданными в систему параметрами соответствующей не блокированной принимающей функции. А функции Wait и Test со стороны передающей функции только проверяют наличие этих выставленных параметров со стороны неблокированной принимающей функции. При синхронных взаимодействиях пересылаемый буфер передается в принимаемый буфер "напрямую" (память-память) минуя сохранение в промежуточных буферах. Коллективные взаимодействия Коллективная связь обеспечивает обмен данными среди всех процессов в группе, указанной аргументом коммуникатора. Коллективные сделаны более ограниченными чем point-to-point операции. В отличие от point-to-point операций, количество посланных данных в этих функциях должно быть точно согласовано с количеством данных, указанных приемником. Коллективные функции имеют только блокированные версии. Коллективные функции не используют аргумент тега. Аргумент типа данных должен быть одним и тем же во всех процессах, участвующих во взаимодействии. Внутри каждой области связи, коллективные запросы строго согласованы согласно порядку выполнения. В коллективном запросе к MPI_BCAST должны участвовать все процессы, объединенные коммуникатором. Коллективные функции не согласуются с функциями парных взаимодействий. Синхронизация MPI_BARRIER(comm) IN comm коммуникатор int MPI_Barrier(MPI_Comm comm) MPI_BARRIER блокирует вызывающий оператор, пока все элементы группы не вызовут его. В любом процессе запрос возвращается только после того, как все элементы группы вошли в запрос. Трансляционный обмен данными MPI_BCAST(buffer, count, datatype, root, comm) INOUT buffer адрес буфера IN count количество элементов в буфере IN datatype тип данных IN root ранг корневого процесса IN comm коммуникатор int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm) MPI_BCAST передает сообщение из процесса с рангом root ко всем процессам группы. Аргументы корня и на всех других процессах должены иметь идентичные значения, и comm должна представлять ту же самую область связи. После возвращения, содержимое буфера buffer из корня копируется ко всем процессам в буфер buffer.  Рис. 4.1. Иллюстрация коллективных передающих функций для группы из шести процессов. В каждой клетке представленны локальные данные в одном процессе. Например, в broadcast передает данные A0 только первый процесс, а другие процессы принимают эти данные. Сбор данных MPI_GATHER(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm) IN sendbuf адрес передаваемого буфера IN sendcount количество передаваемых элементов IN sendtype тип передаваемых элементов OUT recvbuf адрес буфера приема IN recvcount количество принимаемых элементов в каждом процессе IN recvtype тип принимаемых данных IN root ранг принимающего процесса IN comm коммуникатор int MPI_Gather(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm) Каждый процесс (включая процесс корня) посылает содержимое его посылаемого буфера к процессу корня. Процесс корня получает сообщения и хранит их в порядке рангов, посылающих процессов. Результат выглядит так, как будто каждый из n процессов в группе (включая процесс корня) выполнил запрос к MPI_SEND(sendbuf,sendcount,sendtype,root, ...), и корень выполнил n запросов к MPI_RECV(recvbuf+i*recvcount,recvcount, recvtype,i,...). Приемный буфер игнорируется для всех процессов не равных корню. Аргумент recvcount в корне указывает число элементов, которые получает корень от каждого процесса, а не общее число элементов, которые он получает всего. ПРИМЕР 4.1. Прием корнем 100 элементов от каждого процесса группы. (рис. 4.2). MPI_Comm comm; int gsize, sendarray[100]; int root, *rbuf; ... MPI_Comm_size(comm, &gsize); rbuf = (int *)malloc(gsize*100*sizeof(int)); MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm); 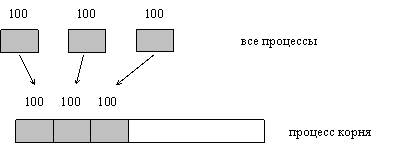 Рис. 4.2. Процесс корня принимает 100 элементов от каждого процесса группы. Сбор данных (векторный вариант) MPI_GATHERV(sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, root, comm) IN sendbuf адрес передаваемого буфера IN sendcount количество передаваемых элементов IN sendtype тип передаваемых элементов OUT recvbuf адрес буфера приема IN recvcounts целочисленный массив, указывающий количество принимаемых элементов в каждом процессе IN displs целочисленный массив смещений принятых пакетов данных относительно друг друга IN recvtype тип принимаемых данных IN root ранг принимающего процесса IN comm коммуникатор (communicator) int MPI_Gatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int *recvcounts, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm) MPI_GATHERV расширяет функциональные возможности MPI_GATHER, позволяя изменяющийся counts данных из каждого процесса, так как recvcounts - теперь массив. Она также допускает большее количество гибкости относительно того, где данные размещаются на корне, обеспечивая новый аргумент, displs. Данные, посланные из процесса j, размещаются в j-м блоке в буфере приема recvbuf на процессе корня. Блок j-й в буфере recvbuf начинается в смещении от начала предыдущего пакета в displs[j] элементов (в терминах recvtype). Буфер приема игнорируется для всех процессов, не принадлежащих корню. Все аргументы в функции на корне процесса значимы, в то время как на других процессах, значитмы только аргументы sendbuf, sendcount, sendtype, root, и comm. Аргументы должны иметь идентичные значения на всех процессах, и comm должна представлять ту же самую область связи. |