Учебное пособие по дисциплине Разработка языков программирования высокого уровня
 Скачать 1.74 Mb. Скачать 1.74 Mb.
|

4.9. Раздельная и независимая компиляцияВозможность компилировать части программы без компиляции всей программы существенна при создании больших систем программного обеспечения. Следовательно, языки, разрабатываемые для таких приложений, должны допускать такой вид компиляции. Существуют два разных подхода к компиляции частей программы: раздельная компиляция, независимая компиляция. Части программ, которые могут компилироваться отдельно, называются единицами компиляции. Раздельная компиляция означает, что: единицы компиляции могут компилироваться в разное время, между единицами компиляции существует связь по данным, осуществляется проверка типов данных и протоколов модулей при компиляции. Примером раздельной компиляции может служить возможность организации модулей Unit в языке Pascal. Ниже приведен код на языке Pascal, демонстрирующий описание и подключение модуля Cmplx к программе. Unit Cmplx; Interface Type Complex = record re, im : real end; procedure Addc (x, y : complex; var z : complex); procedure Subc (x, y : complex; var z : complex); Implementation procedure Addc ; begin ……. end; procedure Subc ; begin ……. end; end { Unit }; Program test ; uses Cmplx; var a, b, c : complex ; begin a.re := 1; a.im =1; b.re:=1; b.im:=2; Addc(a, b, c) Writeln( ‘ ‘ , c. re :5 : 1, c . im :5 :1); End. В некоторых языках, среди которых выделяются ранние версии языков С и Fortran, допускалась независимая компиляция. При независимой компиляции: - программные модули компилируются без связи с другими программными единицами, -проверка типов и интерфейсов модулей не осуществляется. Интерфейс подпрограммы на языке Fortran-77 представляет собой список параметров. Когда подпрограмма компилируется отдельно, типы ее параметров не хранятся вместе с компилируемым кодом или в библиотеке. Следовательно, при компиляции другой программы, вызывающей данную подпрограмму, типы фактических параметров в вызове не могут проверяться на совместимость с типами формальных параметров подпрограммы, даже если доступен машинный код вызываемой подпрограммы. ГЛАВА 5. ОСНОВНЫЕ ПОНЯТИЯОБЪЕКТНО-ОРИЕНТИРОВАННОГО ПРОГРАММИРОВАНИЯКонцепция объектно-ориентированного программирования (ООП) уходит корнями в язык SIMULA67, который был предназначен исключительно для моделирования систем. Основным слабым местом языков того времени при использовании их для моделирования были подпрограммы. Для моделирования требовались подпрограммы, позволяющие перезапускать их с того места, на котором их выполнение было ранее прервано. Подпрограммы с таким типом управления называются сопрограммами, реализации их была сделана в языке АЛГОЛ-60. Для поддержки сопрограмм в языке SIMULA67 была разработана конструкция класса. Это усовершенствование положило начало нашим понятиям об абстрактных типах данных и ООП. Класс в языке SIMULA67 поддерживал инкапсуляцию (объединение данных и кода их обработки), обладал некоторыми свойствами наследования, определял абстрактный тип данных, но не ограничивал доступ клиента к сущностям класса, т.е. не обеспечивал надежного сокрытия информации в классе. Идеи ООП, возникшие при разработке SIMULA67, нашли свое развитие и воплощение в языке Smalltalk80, который явился первым чисто объектным языком. На уровне объектов здесь реализовано все: от целочисленных констант до больших сложных систем программного обеспечения. Все вычисления на языке Smalltalk80 выполняются одним и тем же универсальным способом: объекту данных отправляется сообщение, вызывающее один из его методов. Главное отличие между посылкой сообщения и вызовом подпрограммы заключается в том, что сообщение посылается объекту данных, который затем обрабатывается с помощью метода (программного кода, оформленного как функция), связанного с этим объектом, в то время как вызов подпрограммы посылает данные на обработку в саму подпрограмму. Концепция ООП как методология программирования в настоящее время получила широкое распространение. Поэтому основные императивные языки(C, Pascal, Fortran, Ada) имеют свои объектно-ориентированные диалекты (C++, Delphi, Fortran90, Ada95 и пр.). Итак, методология объектно-ориентированного программирования базируется на следующих основным понятиях: Инкапсуляция. Абстрактный тип данных (АТД). Объект как основной элемент абстракции в отличие от переменной – основного элемента абстракции структурного программирования. Наследование. Полиморфизм. Инкапсуляция Понятие инкапсуляции ООП выросло из императивной части языка, предшествует абстрактным типам данных и поддерживает их. Когда размер программы достигает нескольких тысяч строк, возникают три практические проблемы: Организация хорошо управляемой структуры программы. Решить эту проблему можно, разделив программу на синтаксические единицы(подпрограммы, модули и т.п.), которые содержат группы логически связанных операторов обработки и данных. Повторная компиляция. Для маленькой программы повторная компиляция всей программы после каждой модификации стоит немного. Однако, когда размер программы возрастает до нескольких тысяч строк, затраты на повторную компиляцию становятся значительными. Таким образом, необходимо было найти способ избежать повторной компиляции неизменных частей программы. Это можно сделать, составив программу из наборов синтаксических единиц и данных, каждый из которых можно компилировать отдельно, без повторной компиляции остальной части программы. Повторное использование отдельных частей кода в других программах. Все три проблемы решает организация структуры программы с использованием инкапсуляций. Люди пишут программы, размер которых превышает несколько тысяч строк еще со второй половины двадцатого века, так что техника создания инкапсуляций развивается уже довольно давно. В императивной части языка идея инкапсулирования реализовалась в виде подпрограмм, модулей, а в ООП получила дальнейшее развитие. Инкапсуляция – это способ объединения в единое целое данных и кода, который эти данные обрабатывает, ее общая структура представлена на рисунке 5.1 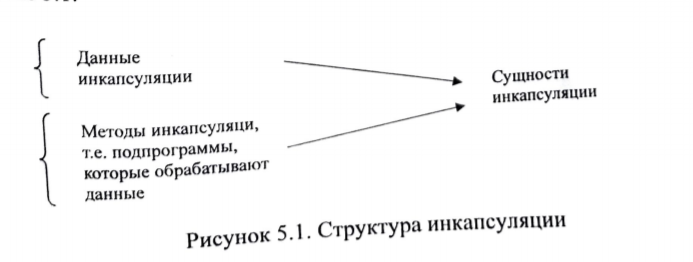 Рисунок 5.1 Рисунок 5.1Структура инкапсуляции При организации инкапсуляции возникает задача обеспечения безопасности инкапсуляции. Для этого необходимо: осуществлять проверку типов интерфейсов при обращении к инкапсуляциям, разграничить доступ к данным и методам инкапсуляции со стороны других синтаксических единиц. Чтобы обеспечить безопасность инкапсуляции существует система доступа к сущностям инкапсуляции. Она заключается в том, что сущности с точки зрения их доступности могут быть представлены следующими типами: private – видимы и доступны только внутри данной инкапсуляции, public – видимы и доступны для других программных единиц, осуществляют внешний интерфейс protected – доступны только потомкам по определенным првилам. 5.2. Определение абстрактного типа данных Понятие абстрактного типа данных есть результат развития абстракций данных и процесса ЯПВУ. Под абстракцией процесса понимают такие структурные единицы кода как программа, модуль. Словом, любая синтаксическая единица, инициация которой порождает отдельный вычислительный процесс или подпроцесс. Развитие абстракций данных в языках программирования связано с представлением на уровне программного кода объектов оперативной памяти. При этом выделаются следующие этапы: Ячейка – переменная одного типа. Абстракция данных в языке началась с понятием переменной, которая представляет собой абстракцию ячейки ОП. При этом одной переменной определенного типа ставится в соответствие одна (условно) ячейка соответствующего типа. Ячейка – разнотипные переменные. Оператор EQUIVALENCE в FORTRAN или Union в C, C++ позволяют в разные моменты времени в течение работы программы загружать в одну и ту же ячейку переменные различных типов. Область ячеек – объединение однотипных переменных – массив, который представляет область ячеек памяти одного типа. Область ячеек – объединение разнотипных переменных. Возможность описания области ячеек памяти одной структурой разнотипных объектов( например, таблица данных разного типа ), так в ЯП появился тип запись или структура. В языках объектно-ориентированного программирования произошел синтез абстракции данных и абстракции процесса на принципах инкапсуляции. Возникла идея определить новый тип, инкапсулируя какой-либо тип данных и методы их обработки. Таким образом, абстрактный тип данных ( АТД ) – это инкапсуляция данных одного типа и операций (методов) для их обработки. При этом следует иметь в виду, что в инкапсуляции, конечно, описывается несколько видов данных ( переменные, массивы, структуры ), но если среди них есть один, обработка которого с помощью операций инкапсуляции является целью создания АТД с точки зрения семантики задачи. Например, создаем АТД для обработки таблицы с бухгалтерскими данными. Тогда инкапсуляция должна иметь основной типа данных запись ( структура ) для описания таблицы, операции (методы) для обработки таблицы и какие-то вспомогательные переменные. Определение. Абстрактный тип данных(АТД) – это типа данных, который удовлетворяет следующим условиям: определение типа и операции над объектами данного типа содержатся в одной синтаксической единице; переменные же данного типа можно создавать и в других модулях; внутренняя структура объектов данного типа скрыта от программных модулей, использующих этот тип, так что над такими объектами можно производить лишь те операции, которые прямо предусмотрены в определении типа. Встроенные операции, которые можно выполнять над объектами АТД: присваивание, проверка на равенство и неравенство, конструктор и деструктор объектов. Конструкторы используются для инициализации вновь создаваемых объектов. Деструкторы используются для освобождения областей динамической памяти, которые могут быть заняты объектами абстрактного типа. В ООП по аналогии с языком SIMULA67 абстрактный тип данных принято называть классом. Экземпляр класса (переменная типа класса) является объектом. Класс – шаблон для создания объекта. Формат описания класса следующий (нотация языка C++): Class <имя класса> Private : < приватные сущности класса > Protected : < защищенные сущности класса > Public : < общие сущности класса > } [ список объектов класса]; Здесь важно понять преемственность классического понятия типа данных в императивном и объектном смыслах: Отношения между классом и объектом такие же, как и между переменной и типом в императивном языке. Поэтому синтаксис оператора описания объекта (экземпляр класса) такой же, как и синтаксис оператора описания переменной Методы класса являются операциями, сконструированными пользователями и, фактически, дополняющие встроенный в язык набор операций классических императивных типов данных. Метод – это действие, которое можно выполнить над объектом. Вызвать метод (обратиться к нему) означает послать сообщение объекту. Весь набор методов объекта называется протоколом (интерфейсом) сообщения. Синтаксис сообщения следующий: < имя объекта >, < имя метода>. Программные модули, которые используют некоторый АТД, называются клиентами этого типа. Все вычисления в среде ООП выполняются с помощью передачи сообщения от клиента к объекту для вызова одного из его методов. Атрибуты объекта (свойства объекта) – это общие данные (public). Чтобы изменить характеристики объекта, надо изменить его свойства: < имя объекта >.< свойство >=< значение > Все экземпляры класса совместно используют единый набор методов, но каждый экземпляр получает свой собственный набор данных класса (в отличие от подпрограмм). 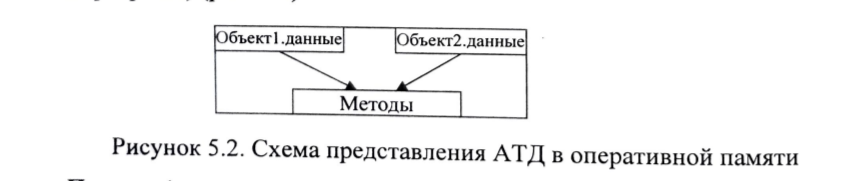 Рисунок 5.2 Схема представления АТД в оперативной памяти Пример 1. Опишем новый класс – очередь. Class queue { Private : Int q[100]; //массив(очередь) Int sloc, rloc; //указатели на первый и последний элемент очереди Public: Void init (void); {….} //инициализация массива (очереди) Void qput (int m); { … } // выдача элемента Int qget ( void ); { … } // заполнение массива (очереди) } main ( void ) { queue a, b : a.init ( ); b.init ( ); a.qput ( 7 ); b.qput ( 20 ); a.qget ( ); b.qget ( ); } Наследование Во второй половине 1980-х годов для многих разработчиков программного обеспечения (ПО) стало очевидным, что одной из наилучших возможностей для повышения производительности их труда является повторное использование программ. Вполне очевидно, что АТД с их инкапсуляцией и управлением доступом должны использоваться многократно. Однако здесь возникали следующие проблемы: Свойства и возможности существующих типов не вполне подходят для нового использования. Старые типы необходимо, по крайней мере, минимально, модифицировать. Такие модификации могут быть трудновыполнимыми и требовать от человека понимания существующего кода. Определения АТД являются независимыми и находятся на одном и том же уровне иерархии. Это часто не позволяет структурировать программу так, чтобы она соответствовала своей проблемной области. Во многих случаях исходная задача содержит категории связанных между собой объектов, являющихся как наследниками одних и тех же предков (т.е. находящихся на одном и том же уровне иерархии), так и предками и наследниками ( т.е. состоящих в отношении некоторой субординации друг с другом). Наследование позволяет решить как проблемы модификации, так и проблемы организации программ. Если новый абстрактный тип данных может наследовать данные и функциональные свойства некоторого существующего типа, а также модифицировать некоторые из этих сущностей и добавлять новые сущности, то повторное использование значительно облегчается без необходимости вносить изменения в повторно используемый абстрактный тип данных. Класс, который определяется через наследование от другого класса, называется производным классом, или подклассом, или потомком. Класс, от которого производится новый класс, называется родительским классом, или суперклассом, или предком. При наследовании существует три возможности: Потомок наследует все сущности (переменные и методы) родительского класса. Это наследование можно усложнить, введя управление доступом к сущностям родительского класса в соответствии с рисунком 5.3. 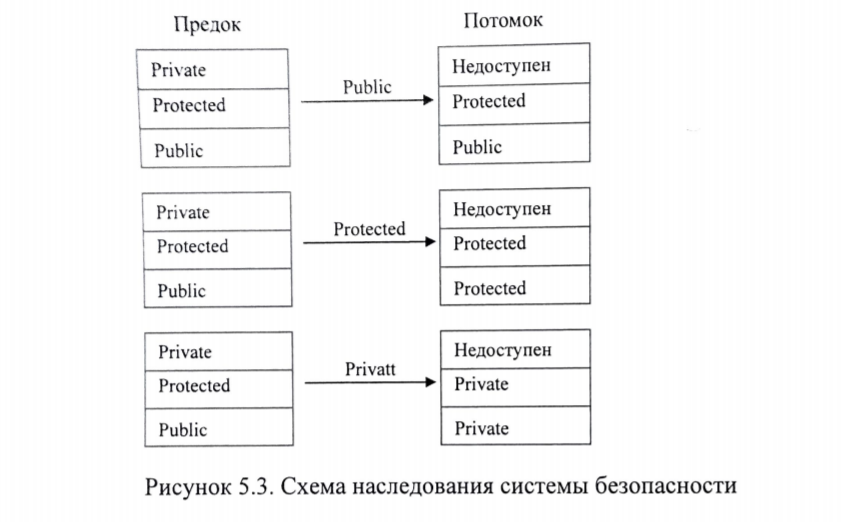 Рисунок 5.3 Схема наследования системы безопасности Синтаксис такого наследования следующий: Class < имя потомка > : < режим доступа > < имя родителя > { …… } [список объектов] Здесь < режим доступа > один из режимов Private | Protected | Public. Потомок модифицирует некоторые методы предка. Модифицированный метод имеет то же самое имя и часто тот же самый протокол, что и метод, модификацией которого он является. Говорят, что новый метод замещает наследуемую версию метода, который называется замещаемым методом: < имя метода > < протокол > = < имя старого метода >< протокол старого метода >; Наиболее общее предназначение замещающего метода – выполнение операции, специфической для объектов производного класса, но не свойственной для объектов родительского класса. Потомок добавляет новые методы. Если потомок имеет один родительский класс, то этот процесс называется одиночным наследованием и представляется в виде дерева наследования. Если класс имеет несколько предков, то такой процесс называется множественным наследованием ( multiple inheritance ). Взаимоотношения классов при множественном наследовании можно изобразить с помощью графа наследования. Синтаксис при этом следующий Class < имя потомка > : < список предков > { ……. } [ список объектов ]; Здесь < список предков > = < режим доступа > < имя предка1 >, < режим доступа > < имя предка 2> … < режим доступа > < имя предка n >. Разработка программы для объектно-ориентированной системы начинается с определения иерархии классов, описывающей отношения между объектами, которые войдут в программу, реализующие поставленную задачу. Чем лучше эта иерархия классов соответствует проблемной части, тем более естественным будет полное решение. Пример 2. Class queue { Private : Int q [100] ; Int sloc, rloc; Public : Void init (void); {…} //инициализация массива – очереди Void qput (int m); {…} // выдача элемента Int qget (void); {…} // заполнение массива – очереди } Class queue1 : public queue { Int sum Public : Int get_sum (void); Void show_sum (void); } main () { queue1 obj; obj . init (); for i = 0 ; i<5 I = i+1 { obj.qput(100 + i); obj.get_sum() ; obj.show_sum(); } |