1. Метод наименьших квадратов алгоритм метода условия применения
 Скачать 281.01 Kb. Скачать 281.01 Kb.
|

Y(t) = Y(t-1) + a(t) где a(t) – белый шум.Интересно, что процесс Y(t) = 0,999*Y(t-1) + a(t) является стационарным Принципиальную возможность избавиться от нестационарности называют интегрируемость. Применяют различные способы избавления от нестационарности: 1. Вычитание тренда, что мы и делали в предыдущем разделе; 2. Использование разностей 1-го, 2-го и т.д. порядков, что можно делать только после сглаживания временного ряда (или энергетического спектра), иначе все эффекты будут подавлены статистическими флуктуациями: дисперсия разности равна сумме дисперсий. Для исследования рядов цен на фондовом рынке применяются модели, использующие белый шум и авторегрессию, то есть взаимную зависимость уровней временного ряда. Модель MA(q) (moving average) – линейная комбинация последовательных элементов белого шума X(t) = a(t) – K(1)*a(t-1) – …. – K(q)*a(t-q) Модель AR(p) (авторегрессия): линейная комбинация лаговых переменных X(t) = b0 + b1*X(t-1) + …. + bp*X(t-p) Особенно популярны их комбинации ARMA(p,q) = AR(p) + MA(q) и ARIMA(p, i ,q): то же, с интегрируемостью i –го порядка. 52. Структурная и приведённая формы спецификации эконометрических моделей. Система совместных, одновременных уравнений (или структурная форма модели) обычно содержит эндогенные и экзогенные переменные. Эндогенные переменные – это зависимые переменные, число которых равно числу уравнений в системе и которые обозначаются через Экзогенные переменные – это предопределенные переменные, влияющие на эндогенные переменные, но не зависящие от них, независимые переменные, которые определяются вне системы. Обозначаются через В качестве экзогенных переменных могут рассматриваться значения эндогенных переменных за предшествующий период времени (лаговые переменные). Предопределенными переменными наз. экзогенные и лаговые эндогенные переменные сис-мы. Структурная форма модели позволяет увидеть влияние изменений любой экзогенной переменной на значения эндогенной переменной. Структурная форма модели в правой части содержит при эндогенных переменных коэффициенты  Использование МНК для оценивания структурных коэффициентов модели дает, как принято считать в теории, смещенные и несостоятельные оценки. Поэтому обычно для определения структурных коэффициентов модели структурная форма модели преобразуется в приведенную форму модели. Приведенная форма модели представляет собой систему линейных функций эндогенных переменных от экзогенных: 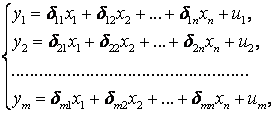 (3.4) (3.4)где По своему виду приведенная форма модели ничем не отличается от системы независимых уравнений, параметры которой оцениваются традиционным МНК. Применяя МНК, можно оценить Коэффициенты приведенной формы модели представляют собой нелинейные функции коэффициентов структурной формы модели. Структурные модели можно подразделить на три вида: - идентифицируемые;-неидентифиц.;- сверхидентифицируемые. Условие идентифицируемости модели может быть записано в виде следующего правила: Предопределённых + 1 = Эндогенных идентифицируемо Предопределённых + 1 < Эндогенных неидентифицируемо Предопределённых + 1 > Эндогенных сверхидентифицируемо 53. Алгоритм проверки значимости регрессора в парной регрессионной модели. По t-статистике, по F-статистике. При проверке качества спецификации парной регрессии наиболее важной является задача установления наличия линейной зависимости между эндогенной переменной и регрессором модели. С этой целью проверяют значимость оценки параметра b (при регрессоре модели). Алгоритм проверки значимости параметра b выполняется в следующей последовательности: 1) оценка параметров парной регрессии 2) оценка дисперсии возмущений S2 3) оценка 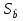 среднего квадратичного отклонения параметра b среднего квадратичного отклонения параметра b4) выбор значения tкр (по заданному уровню значимости 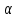 и числу степеней свободы (n-2) из таблиц распределения Стьюдента) и числу степеней свободы (n-2) из таблиц распределения Стьюдента)5) проверка неравенства 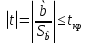 при Н0: b=0 при Н0: b=0Если данное неравенство выполняется, то регрессор признается незначимым, если не выполняется, то данная гипотеза отвергается и регрессор признается значимым, т.е. между эндогенной переменной и регрессором присутствует линейная зависимость. 54.Свойства рядов цен на фондовом рынке. Принципы построения портфеля Марковица С.93,102 Применяемый алгоритм при анализе временных рядов цен на фондовом рынке с использованием автокорреляций высоких порядков с целью обоснования методов прогнозирования с применением волнообразных колебаний: 1. Считывание временных рядов из торговой системы, например, FINAM. 2. Оценка целесообразности работы с рядом, отбраковка рядов с резкими скачками цен и с отсутствием волнообразных колебаний. 3. Вычитание трендов. 4. Проверка остатков на стационарность (см.раздел 8.3). 5. Расчёт автокорреляций и построение коррелограмм 6. Классификация рядов и коррелограмм. 7. Оценка целесообразности применения методов технического анализа с использованием волнообразных колебаний. 8. Аппроксимация участка ряда функцией с синусоидой. 9. Оценка точности аппроксимации и прогноза. Доходность портфеля определяется как сумма доходностей ценных бумаг, его составляющих, взвешенных на их доли в портфеле: D = Σdixi Требуется составить оптимальный портфель ценных бумаг по известным доходностям ценных бумаг за некоторый промежуток времени, имеющий максимальную доходность при заданном риске (портфель Марковица), или заданную доходность при минимальном риске. Мерой риска доходности одной бумаги является стандартное отклонение значений доходностей за некоторый промежуток времени. Если имеется тренд, то есть ряд не является стационарным, то его надо вычесть, а потом вычислять риск (СКО). При отсутствии взаимной зависимости доходностей ценных бумаг (т.е. при нулевых коэффициентах корреляции) суммарная дисперсия равна сумме дисперсий S2 = хi 2 *Si2 , где хi – количество (или процент) закупаемых ценных бумаг i-ой фирмы. При коэффициентах корреляции, равных 1 суммарное стандартное отклонение (риск портфеля) S равно сумме стандартных отклонений Si с соответствующими знаками. При составлении портфеля из ценных бумаг двух фирм квадрат риска равен S2 = x12*S12 + x22*S22 + 2x1*x2* Cov(d1,d2), где ковариация Cov(d1,d2) = ( (d1i – d1cp)*(d2i – d2cp))/(N – 1 ) Если портфель составляется из ценных бумаг большего количества n фирм, то дисперсия портфеля (квадрат риска) вычисляется по формуле S2= xi*xj* Cov(di,dj). Обозначим bij = Cov(di,dj), тогда S2 = x1*x1*b11 + x1*x2*b12 + … + x1*xn*b1n + x2*x1*b21 + x2*x2*b22 + … + x2*xn*b2n …………………………………………………. + xn*x1*bn1 + xn*x2*bn2 + … + xn*xn*bnn 55.Динамическая модель из одновременных линейных уравнений (привести пример) с.105. Многие экономические модели требуют для своего описания систем взаимосвязанных уравнений. Для настройки этих моделей обычно используют временные ряды уровней различных переменных, часть которых принимают за эндогенные, а часть за экзогенные. Выбор переменных определяется исследователем, но обычно экзогенные переменные или не зависят от нас (температура воздуха, курс доллара, цена нефти), или мы можем ими управлять (инвестиции, выпуск продукции). В качестве примера рассмотрим Модель спроса и предложения на конкурентном рынке, а также рыночной цены (p) в зависимости от величины дохода (x) на душу населения. Её называют “паутинной моделью”, так как движение спроса и предложения к равновесию в соответствующей системе координат напоминает паутину. Пример взят из учебника В.А.Бывшева [2]. Изменение во времени спроса, предложения и цены на конкурентном рынке закреплено в следующих утверждениях экономической теории:
Кратко это можно записать, с учётом случайных возмущений: Спрос =a0 + a1· цена + a2· доход +Возмущение1 Предложение = b0 + b1· цена вчера + Возмущение2 Спрос = Предложение (тождество) Соответствующая система уравнений и тождеств: d= a0 + a1· p + a2· x + u1 s = b0 + b1 · p(t-1) + u2 ( 9.1) d = s a1<0, a2>0, b1>0 В данном случае d, s, p эндогенные, x, p(t-1) предопределённые (экзогенная и лаговая) Второе уравнение является обычным уравнением регрессии, и его можно настраивать, используя обычный метод наименьших квадратов. А с первым уравнением так поступить нельзя, так как в него входят две эндогенных переменных. Такая модель называется структурной, она возникает непосредственно из экономических предпосылок. Требуется преобразовать модель к приведённому виду, где в левой части будут стоять эндогенные переменные, а в правой – предопределённые. Можно решать эту задачу путём последовательной замены эндогенных переменных. Мы рассмотрим метод, основанный на преобразовании матриц. Объединим эндогенные переменные в вектор Y, а предопределённые – в вектор Х: Y= (d, s, p) ; X = (1, p(t-1), x) Единица в векторе Х появилась, чтобы работать с коэффициентами a0 и b0. В матричном виде система уравнений и тождеств выглядит AY + BX =0 или 1· d + 0· s - a1· p + (- a0) ·1 + 0 ·p(t-1) + (-a2)· x = 0 0 ·d + 1· s + 0· p + (- b0) · 1 + (-b1) · p(t-1) + 0· x = 0 1 ·d + (-1) · s +0 ·p + 0 · 1 + 0· p(t-1) + 0· x = 0 Здесь матрицы А и В: 1 0 -a1 - a0 0 -a2 A 0 1 0 B - b0 -b1 0 1 -1 0 0 0 0 Приведённая форма модели Y = M X. Компоненты матрицы М 0 1 2 M 0 1 2 0 1 2 получим преобразованием М = А-1В, где А-1 означает обратную к А матрицу. Приведённая форма модели: d = 0 + 1· p(t-1) + 2· x s = 0 + 1· p(t-1) + 2· x p = 0 + 1· p(t-1) + 2· x где 0 = b0 ; 1 =b1 ; 2 = 0 ; 0 = (b0-a0)/a1 ; 1 =b1/a1; 2 = - a2/a1 56. Метод наибольшего правдоподобия: принципы и целесообразность использования Метод наибольшего правдоподобия -- метод поиска модели, наилучшим в каком-то смысле образом описывающей обучающую выборку, полученную с некоторым неизвестным распределением. Описание метода Пусть на вход подается некоторая величина x, а на выходе имеется величина y. Также существует условная вероятность Обоснование метода Заметим, что в силу независимости элементов обучающей выборки вероятность получить набор выходных значений 57. Этапы исследования модели множественной регрессии с.74-79. 1. Построить корреляционную матрицу по всем переменным, включая время. Построить графики всех переменных в зависимости от времени. Выбрать вид модели. 2. Выбрать мультипликативную модель и линеаризовать её логарифмированием: Ln Ŷ = Ln b0+ b1*LnX1+b2*LnX2+b3*LnX3+b4*LnX4 после переобозначения Z^ = a + b1V1 + b2V2 +b3V3 + b4V4 3. Построить корреляционную матрицу t V1 V2 V3 V4 Z t 1 V1 0,995 1 V2 0,879 0,882 1 V3 0,926 0,932 0,968 1 V4 0,983 0,973 0,898 0,938 1 Z 0,924 0,912 0,661 0,774 0,877 1 |