Курс лекций по дисциплине Эконометрика
 Скачать 2.09 Mb. Скачать 2.09 Mb.
|

3.2. Оценивание коэффициентов КЛММРметодом наименьших квадратовПрименяя к (3.1) с учетом (3.2)-(3.5) МНК, получаем из необходимых условий минимизации функционала: т.е. обращения в нуль частных производных по каждому из параметров: 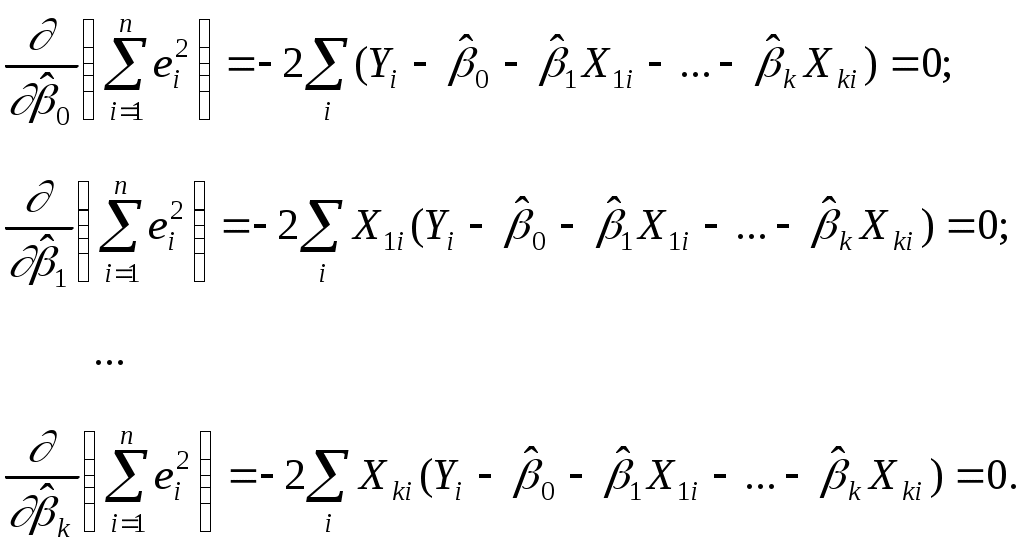 Упростив последние равенства, получим стандартную форму нормальных уравнений, решение которых дает искомые оценки параметров: 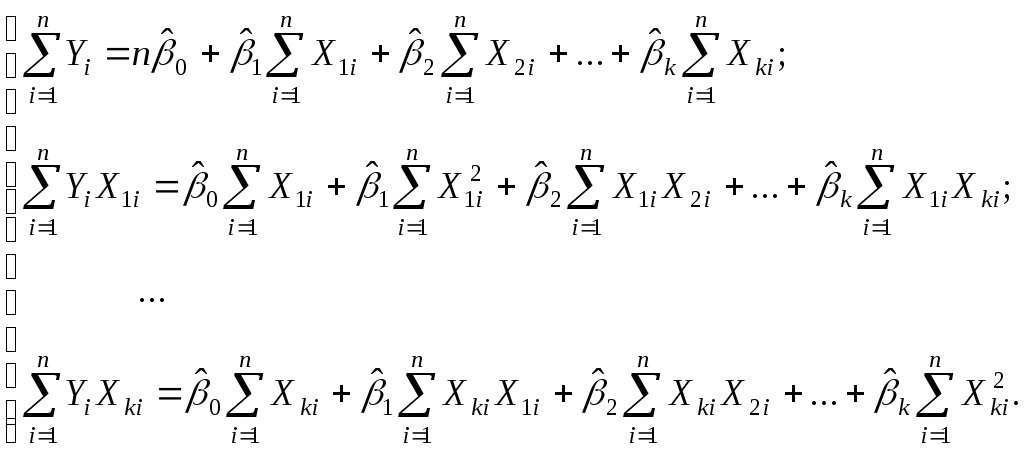 (3.6) (3.6)Сложность решения системы линейных уравнений (3.6) с (k+1) неизвестными увеличивается быстрее, чем растет k. В зависимости от количества уравнений система может быть решена методом исключения Гаусса или методом Крамера или другим численным методом решения системы линейных алгебраических уравнений. Поскольку для большинства практических задач изучаются несколько альтернативных спецификаций модели (3.1), то широкое применение ЭВМ, а также специальных статистических пакетов позволяет значительно упростить процедуру оценивания. В результате решения системы4 (3.6) получим оценки коэффициентов Возможна и другая запись уравнения (3.1) в так называемом стандартизованном масштабе: где для которых среднее значение равно нулю: а среднее квадратическое отклонение равно единице: Нетрудно установить зависимость между коэффициентами "чистой" регрессии причем Соотношение (3.8) позволяет переходить от уравнения вида (3.7) к уравнению вида (3.1). Стандартизованные коэффициенты регрессии показывают, на сколько "сигм" изменится в среднем результат (Y), если соответствующий фактор В силу того, что все переменные центрированы и нормированы, коэффициенты Нетрудно показать, что оценки МНК Как было уже указано раньше, достоинством метода множественной регрессии является возможность выделения влияния каждого из факторов Xj в условиях, когда воздействие многих переменных на результат эксперимента не удается контролировать. Степень раздельного влияния каждого из факторов характеризуется оценками Пример 1. Исследуется зависимость между стоимостью грузовой автомобильной перевозкиY(тыс. руб), весом груза X1 (тонн) и расстоянием X2(тыс.км) по 20 транспортным компаниям. Исходные данные приведены в таблице 3.1. Таблица 3.1
В данном примере мы располагаем пространственной выборкой объема n=20, число объясняющих переменных k=2. Модель специфицируем в виде линейной функции: Следовательно, система нормальных уравнений для модели (3.9) будет иметь вид 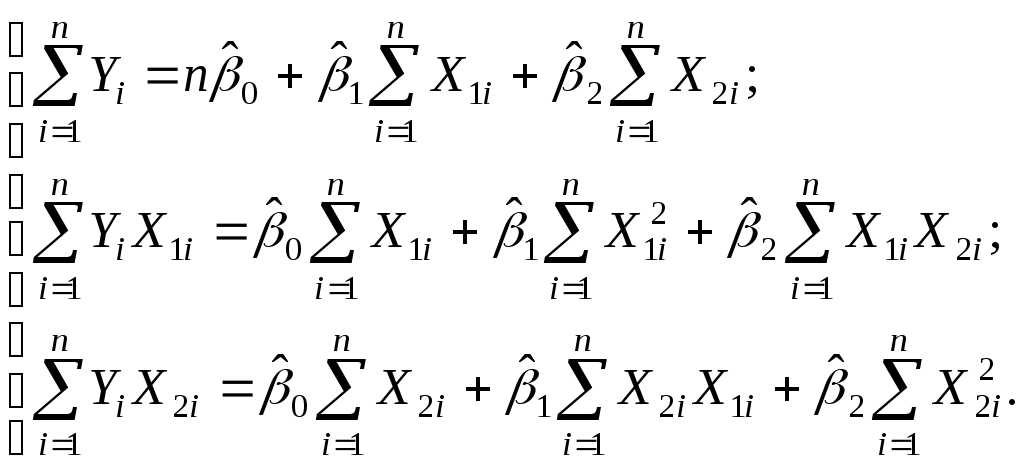 (3.10) (3.10)Рассчитаем по данным табл. 3.1 необходимые для составления указанной системы суммы:
Получим систему нормальных уравнений (3.10) в виде: 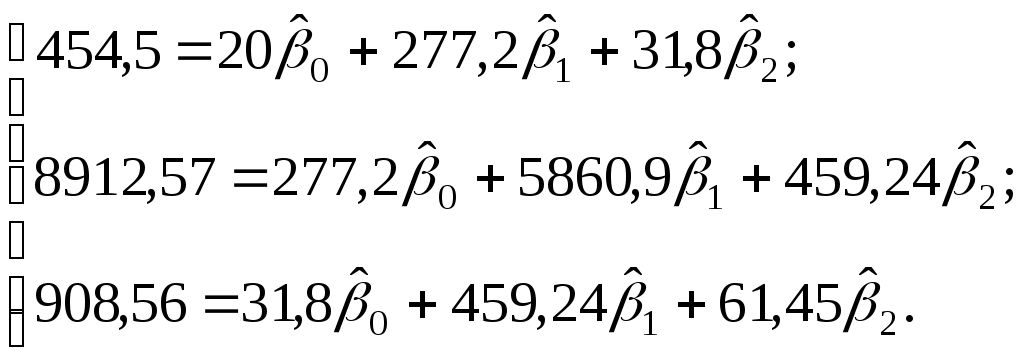 Решая последнюю систему линейных алгебраических уравнений, например методом Крамера, получим: Уравнение регрессии имеет вид: Y=-17,31+1,16X1+15,10X2. Или, с учетом (3.8) и расчетов: уравнение регрессии в стандартизованном масштабе: То есть с ростом веса груза на одну сигму при неизменном расстоянии стоимость грузовых автомобильных перевозок увеличивается в среднем на 0,77 сигмы. Поскольку 0,77>0,56, то влияние веса груза на стоимость грузовых автомобильных перевозок больше, чем фактора расстояния. Рассчитаем коэффициенты эластичности С увеличением среднего веса груза на 1% от его среднего уровня средняя стоимость перевозок возрастет на 0,71% от своего среднего уровня, при увеличении среднего расстояния перевозок на 1% средняя стоимость доставки груза увеличится на 1,05%. Различия в силе влияния факторов на результат полученные при сравнении уравнения регрессии в стандартизованном масштабе и коэффициентов эластичности объясняются тем, что коэффициент эластичности рассчитывается исходя из соотношения средних, а стандартизованные коэффициенты регрессии из соотношения средних квадратических отклонений. Поскольку обычно статистики используют показатель грузооборота, вычисляемый как сумма произведений массы перевезенных грузов на расстояние перевозки, то построим регрессию стоимости 1 км грузовых автомобильных перевозок Y на грузооборот Q (Q=X1X2): P = 5,88 + 0,48Q 0,003Q2, причем регрессор Q2 = Q*Q включен исходя из соображений известного экономического закона убывающей предельной полезности, согласно которому в данном случае стоимость перевозки на 1 км должна уменьшаться с ростом грузооборота, т.е. коэффициент при Q2 должен иметь (и в построенном уравнении имеет) отрицательный знак. Как уже говорилось в разделе 2.3, регрессионные модели не ограничиваются классом линейных функций. Линеаризация нелинейных функций в уравнении регрессии имеет особенности, рассмотренные в примере. Пример 2. Исследуется зависимость между выпуском Q(млн. $) и затратами труда L (чел.) и капитала K (млн. $) в металлургической промышленности по 27 американским компаниям. Исходные данные приведены в таблице 3.2. Таблица 3.2
Мы располагаем пространственной выборкой объема n=27, число объясняющих переменных k=2. Модель зависимости между выпуском и затратами труда и капитала, как правило, специфицируется в виде производственной функции, чаще всего Кобба-Дугласа: Поскольку модель (3.11) является нелинейной, преобразуем ее к виду линейной по параметрам. Для этого возьмем логарифм от обеих частей в уравнении (3.11): Переобозначим для удобства Y=lnQ, 0=lnA,X1=lnL, X2=lnK, u=ln, тогда имеем линейную модель вида: Исходные данные к модели вида (3.11) получаются логарифмированием чисел, представленных в таблице 3.2. Соответственно получим табл. 3.3. После процедуры лианеризации система нормальных уравнений для модели (3.11) будет иметь такой же вид, как и система (3.10) Рассчитаем по данным табл. 3.3 необходимые для составления указанной системы суммы:
Таблица 3.3
Получим систему нормальных уравнений после подстановки соответствующих значений в (3.10) в виде: 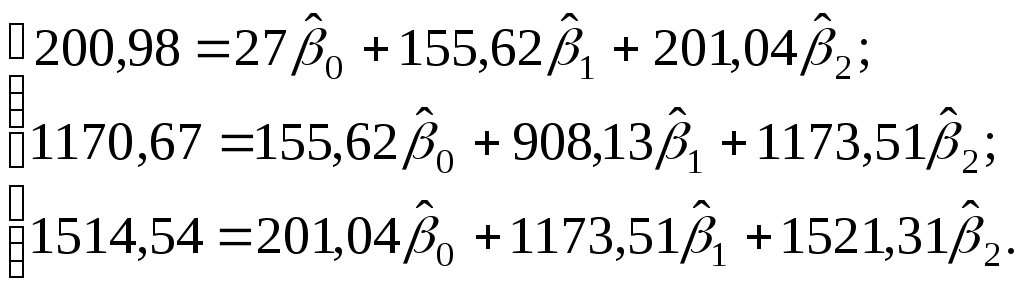 Решая последнюю систему методом Крамера, получим: Уравнение регрессии имеет вид: Y=1,11+0,56X1+0,41X2. Или, с учетом (3.8) и расчетов: Нетрудно восстановить (учитывая, что A= Эластичность выпуска продукции Q по труду L равна 0,56, а эластичность выпуска продукции Q по капиталу K равна 0,41. Следовательно увеличение затрат труда на 1% приведет к росту выпуска продукции на 0,56%, а увеличение затрат капитала на 1% приведет к росту выпуска продукции на 0,41%. Очевидно, что обе величины Продолжая интерпретацию результатов регрессии 3.3 Парная и частная корреляция в КЛММР В случаях, когда имеется одна независимая и одна зависимая переменные, естественной мерой зависимости (в рамках линейного подхода) является выборочный (парный) коэффициент корреляции между ними. Использование множественной регрессии позволяет обобщить это понятие на случай, когда имеется несколько независимых переменных. В этом случае необходима корректировка, так как высокое значение коэффициента корреляции между зависимой и какой-либо независимой переменной может означать высокую степень линейной зависимости, но может означать и то, что третья переменная, оказывает значительное влияние на две первых и, что именно она служит основной причиной их высокой корреляции. Поэтому необходимо найти "чистую" корреляцию между двумя переменными, исключив влияние других факторов путем расчета коэффициента частной корреляции. Коэффициенты частной корреляции для уравнения регрессии с двумя независимыми переменными рассчитываются как: 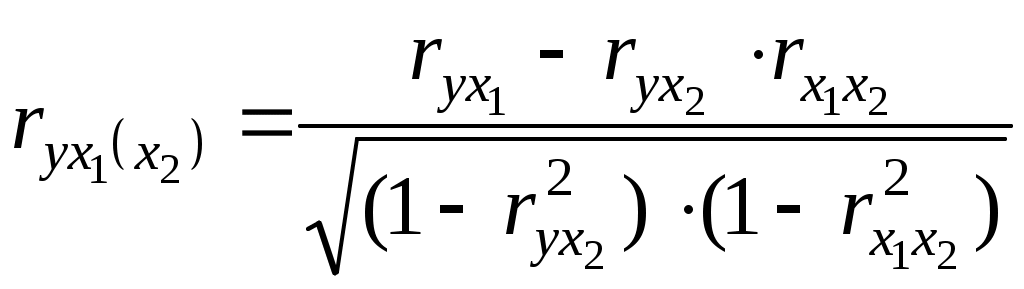 , (3.13) , (3.13)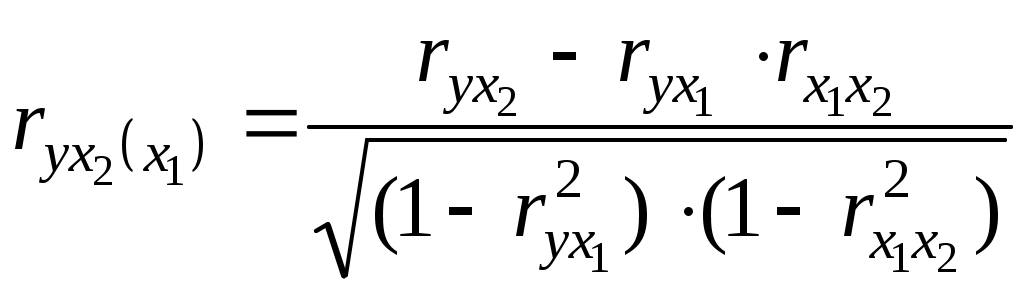 , (3.14) , (3.14)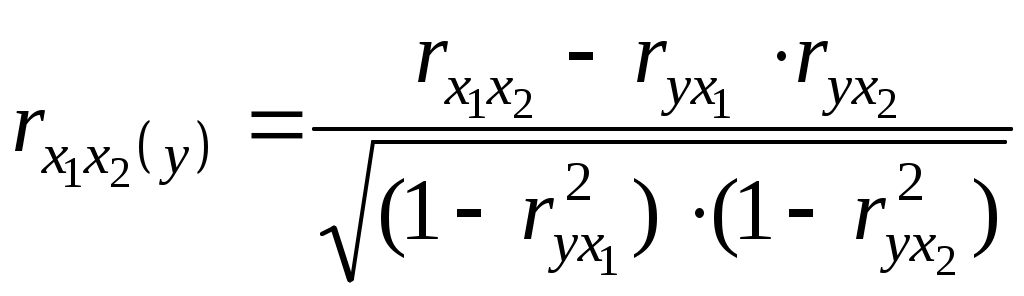 , (3.15) , (3.15)где Заметим, что парные линейные коэффициенты корреляции, стоящие в правых частях формул (3.13)-(3.15), могут быть рассчитаны с помощью формулы (2.9). Коэффициенты частной корреляции более высоких порядков можно определить через коэффициенты частной корреляции более низких порядков по следующей рекуррентной формуле: 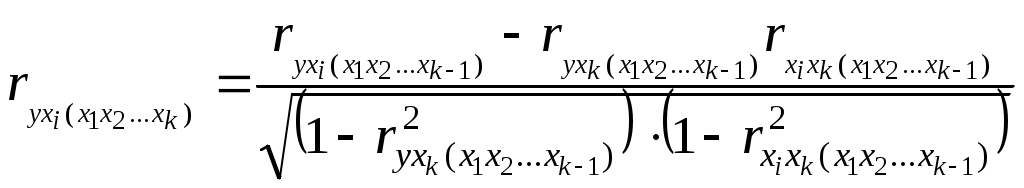 (3.16) (3.16)Коэффициенты частной корреляции широко используются на стадии формирования модели, при отборе факторов. Так, например, при построении многофакторной модели применяется метод исключения переменных, в ходе которого строится уравнение регрессии с полным набором переменных, затем рассчитывается матрица частных коэффициентов корреляции. Далее проверяется статистическая значимость каждого из коэффициентов согласно t-критерию Стьюдента. Независимая переменная, имеющая наименьшую и несущественную корреляцию с зависимой переменной, исключается. Затем строится новое уравнение регрессии, и процедура продолжается до тех пор, пока не окажется, что все частные коэффициенты корреляции статистически значимы, то есть существенно отличаются от нуля. Проверка статистической значимости частного коэффициента корреляции суть проверка гипотезы о том, что он равен нулю Н0: Рассчитывается статистика: 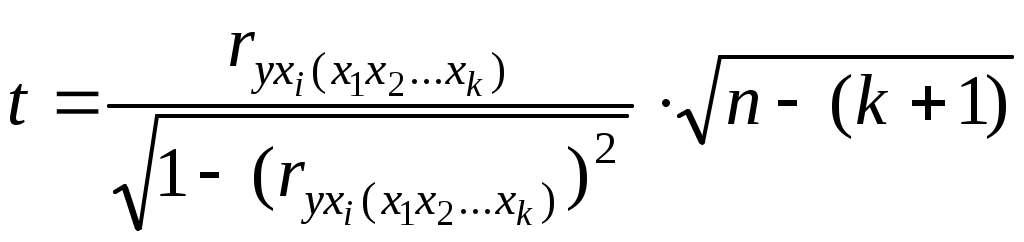 (3.17) (3.17)Вывод о значимости частного коэффициента корреляции делается при t>t, где t соответствующее табличное значение t-распределения с (n- (k+1)) степенями свободы. Пример (продолжение примера 1). Рассчитаем парные линейные коэффициенты корреляции, применяя формулу (2.9) и одновременно проверяя их статистическую значимость. 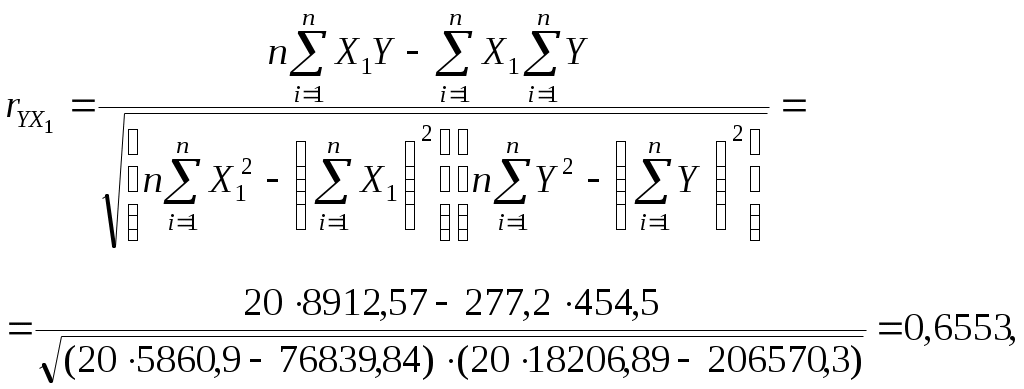 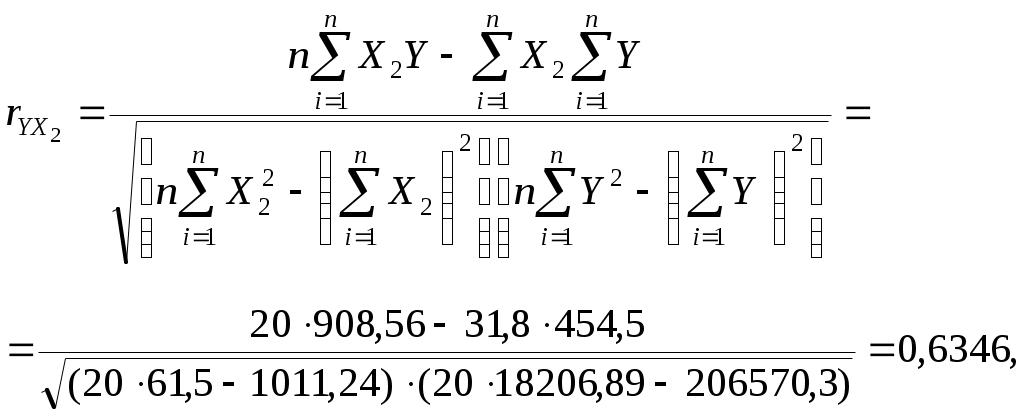 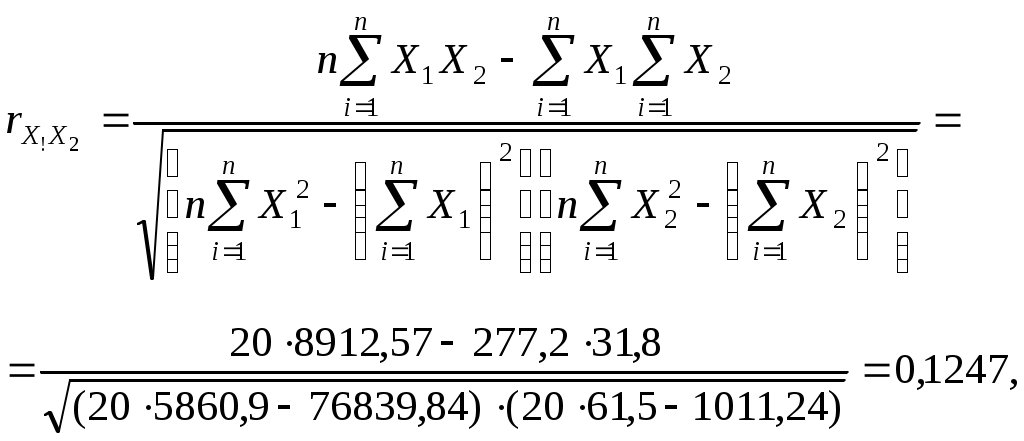 Составим матрицу парных линейных коэффициентов корреляции (в скобках значение t-статистик):
Коэффициент корреляции между y и x1, свидетельствует о прямой статистически значимой связи между стоимостью перевозки и весом перевозимого груза. Коэффициент корреляции между y и x2 также свидетельствует о прямой и статистически значимой связи между стоимостью перевозки и расстоянием перевозки. Величина статистически значимого коэффициента корреляции между x1 и x2 означает практическое отсутствие взаимосвязи между расстоянием перевозки и весом груза, что не противоречит первоначальным предположениям о том, что расстояние перевозки не может быть обусловлено весом груза и наоборот. Рассчитаем коэффициенты частной корреляции согласно формулам (3.13)-(3.15) и проверим их значимость согласно (3.17): Составим матрицу частных коэффициентов корреляции (в скобках значение t-статистик):
Как уже говорилось ранее, частные коэффициенты корреляции показывают "чистую" корреляцию пары переменных, исключающую влияние прочих переменных, включенных в уравнение. Таким образом, наиболее сильной является взаимосвязь между стоимостью перевозки и весом груза. Однако заметим, что частные коэффициенты корреляции между y и x1, y и x2 свидетельствуют о более сильных взаимосвязях независимых переменных с зависимой, чем это показывают значения парных коэффициентов корреляции. Это произошло потому, что парный коэффициент корреляции завысил тесноту связи между x1 и x2, занизив при этом тесноту связи между y и x1, y и x2. Отметим также, что все частные коэффициенты корреляции статистически значимы. |

 ,6346 (3,60)
,6346 (3,60)