Мм в истории. Математические методы в истории. Математические методы в истории
 Скачать 390.5 Kb. Скачать 390.5 Kb.
|

Метод кластерного анализаДля типизации в исторических исследованиях наиболее эффективны методы многомерной типологии. Наиболее широко распространен вид типизации по географическому районированию, благодаря которому можно выделить сплошной территориальный комплекс, что важно для раскрытия тех или иных особенностей исторического развития. С другой стороны, территориальное единство изучаемых объектов само по себе не обеспечивает их содержательной однородности. Поэтому, в дополнение к географическому районированию, историки используют социальную типизацию изучаемых объектов, в основе которой лежит не географическое, а социальное пространство. Такой подход уже носит характер многомерной типологии. Наиболее известным методом многомерной типологии является кластерный анализ. Он позволяет выделить кластеры (от англ. Cluster — скопление), группы объектов со сходными свойствами, расположенные в пространстве. Близость этих объектов друг к другу отражает степень их сходства. Рассмотрим процесс выделения кластеров на примере агломеративно-иерархического метода. Итак, пусть все m признаков будут измерены в количественной шкале. В таком случае каждый n объект будет представлен точкой в m-мерном пространстве признаков. О сходстве объектов можно судить по расстоянию между соответствующими точками. Соответственно, чем ближе объекты находятся друг к другу, тем они более схожи. Расстояние между объектами зависит от «масштаба» признаков, который обычно нормализуют, т.е. все признаки приводят к стандартному виду со средним значением, равным нулю, и стандартным отклонением, равным единице. После нормализации объекты сохраняют свое относительное положение, но «масштаб» измерения признаков уже будет единым. Обычно близость двух кластеров определяется как среднее значение расстояния между всеми парами объектов, где один объект пары принадлежит к одному кластеру, а другой – к другому: На первом шаге процедуры агломеративно-иерархического метода кластерного анализа по начальной матрице расстояний между объектами определяется минимальное расстояние. Затем выделяют наиболее близкие объекты, находящиеся друг от друга на этом расстоянии, и объединяют в один кластер. В матрице вычеркивают строку и столбец, соответствующие первому из этих объектов, а расстояния от нового кластера до всех остальных кластеров вычисляют по вышеприведенной формуле. Эти значения вписывают в строку и столбец матрицы расстояний, соответствующие второму объекту из первого кластера. Второй шаг процедуры предусматривает формирование нового кластера, на основе нового определения минимального расстояния. Этот кластер строят объединением двух объектов, или одного объекта с кластером, построенным на первом шаге. В матрице расстояний вычеркиваются одна строка и один столбец, а одна строка и один столбец пересчитываются и т.д. В конце этой процедуры получится один кластер, объединяющий все n объектов. С помощью методов кластерного анализа была проведена аграрная типология губерний Европейской России на рубеже XIX— XX вв.4 Анализ проводился следующим образом. Для начала были отобраны 19 показателей, характеризующих земельные отношения (размеры крестьянских наделов, удельный вес дворянского землевладения, продажа частновладельческих земель, цена на землю, размеры крестьянской аренды и арендная плата), состояние сельскохозяйственного производства (посевы, сборы и урожайность хлебов, количество рабочего и продуктивного скота, цены на сельскохозяйственную продукцию), глубину и особенности буржуазной аграрной эволюции (применение наемного труда, зарплата сельскохозяйственных рабочих, разложение крестьян). В результате математической обработки данных было выделено 15 взаимосвязанных между собой кластеров с указанием на графике «расстояния», показывающего «близость» губерний, входящих в тот или иной кластер, а, кроме того и самих кластеров. Благодаря такой визуальной подсказке, например, выяснилось, что наиболее сходными по совокупности 19 признаков были губернии VII (Воронежская и Саратовская) и XI (Киевская и Подольская) кластеров. Наименее сходными между собой и в то же время самыми непохожими на все другие были губернии XV кластера (Московская и Петербургская). При этом, однако, кластеры не образовали существенно отличных типов губерний, так как различия между многими из этих кластеров были невелики. Чтобы выделить типы необходимо объединить полученные мини-кластеры в макро-кластеры, после чего уже можно выделить определенные типы. В рассматриваемом примере на основе «расстояний» были выделены следующие типы губерний: I —V кластеры образовали нечерноземный тип аграрного развития, VI—XI кластеры составили среднечерноземный тип, XIII и XIV кластеры обозначили южностепной тип, XV кластер —прибалтийский тип, а XII мини-кластер представлен губерниями столичного типа. Пример таблицы по кластерам с указанием расстояния, показывающей структуру промышленной типологии губерний Европейской России в начале XX в.:
В состав указанных в таблице кластеров входят следующие губернии:
Наиболее характерные различия между типами устанавливаются путем сопоставления средних значений рассматриваемых признаков в каждом из типов. Кластерный анализ – это весьма эффективный метод многомерной типологии, хотя и не лишенный недостатков. К таковым относится его ограниченность по части выделения типов. Кроме того, хотя кластерный анализ и способен показать некое «расстояние» между объектами в мини-кластере и между кластерами, однако эти «расстояния» не способны измерять непосредственно меру сходства и различий между объектами. Тем не менее, этот метод находит применение и в археологии, так как можно изучать кластерную структуру множества памятников по наличию и частоте встречаемости артефактов. В качестве примера применения метода кластерного анализа в археологии можно привести типологию поселений Алтая VI–II вв. до н.э. Исследователями был проведен анализ карты расположения известных археологических памятников, на основании которого был сделан вывод о том, что система расположения древних поселков находилась в прямой зависимости от природно-географических условий данной местности, а именно: стационарные поселки древние жители Алтая предпочитали возводить на более высоких террасах и мысах, чем стоянки, а поселения располагались кустами по 8-16 пунктов на крупных реках чаще, чем на их притоках. Для получения скрытой и неярко выраженной информации исследователи выделили 12 видов орнаментов, присутствовавших на фрагментах керамики, обнаруженной на 39 исследованных поселениях. После чего был осуществлен подсчет каждого вида в процентах по каждому поселению. Однако, кластеры, найденные исследователем, после повторного сбора информации и применения кластерного анализа могут «рассыпаться» из-за случайности выявленной кластерной структуры. Это происходит в том случае, если реальная кластерная структура отсутствует вообще, т. е. исследуемая совокупность является однородной, или когда задано не соответствующее реальности число классов. Чтобы проверить достоверность наличия кластерной структуры, необходимо привлечение дополнительных фактов и исследование классификации с использованием переменных, как участвующих, так и не участвующих в кластеризации. Корреляционный, регрессионный и факторный анализ Первооткрывателем корреляционного метода является французский естествоиспытатель и натуралист Жорж Кювье (George Cuvier, 1769–1832). Закон Корреляции был выведен им средствами сравнительной анатомии. Кювье понял, что органы одного организма соответствуют друг другу и его общим условиям существования. Так, травоядные имеют зубы, приспособленные для пережевывания растений, а на ногах у них копыта для быстрого бега от хищников. У хищников же выдающиеся клыки, а на ногах когти, и т. д. По его утверждению, ему было под силу восстановить всё животное по одной его части. Таким образом, корреляция – показатель, отражающий взаимную зависимость двух или более величин. При этом величины должны выбираются случайно, а зависимость может определяться либо совпадением, либо отношениями причинности. Необходимо выяснить, не является ли корреляция ложной, то есть основанной на совпадении. Для этого вводится еще одна новая случайная величина. Только при изменении значения одной величины, которое влечет за собой неминуемое систематическое изменение значения другой величины, корреляция считается установленной. Такое изменение может быть выражено в виде коэффициента корреляции, или корреляционного отношения. Коэффициент корреляции показывает, насколько тесно две переменных связаны между собой. 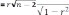 где n – объем выборки. В этой величине известны вероятности всех ее значений. Чем больше значение t, тем меньше его вероятность, т.е. вероятность того, что данная или большая величина корреляции может быть получена в выборке из генеральной совокупности, в которой корреляция равна нулю. В том случае, если эта вероятность окажется меньше выбранного уровня значимости, гипотеза о некоррелированности признаков отклоняется, а связь признается значимой. Для визуального выявления наличия взаимосвязи между количественными переменными полезно строить диаграммы рассеяния (scatterplot). В этом графике по горизонтальной оси  (X) откладывается одна переменная, по вертикальной (Y) другая. При этом каждому объекту на диаграмме соответствует точка, координаты которой равняются значениям пары выбранных для анализа переменных. Различают два вида зависимостей, которые присущи объективным явлениям природы и общества. Функциональнаязависимость– это взаимосвязь между признаками, в которой каждому значению одного признака соответствует единственное значение другого признака. Простейшей ее формой является линейная зависимость, характеризующаяся уравнением: y = ax + b . К другими формами функциональной зависимости, относятся: парабола ( y= ax2 + bx+ c. гипербола (ax by k+= ), логарифмическая функция ( y = a lg x ), экспонента ( y = keax , k > 0, a > 0 ). Функциональная зависимость предполагает изолированность взаимосвязанных признаков от воздействия других факторов. Но такая ситуация в явлениях общественной жизни практически не встречается. В случае, если на связь между признаками влияет множество других факторов, и она проявляется лишь в тенденции, «в среднем», то такая зависимость носит название статистической, или корреляционной. Для того, чтобы определить тесноту связи между двумя признаками, следует высчитать так называемый парныйлинейныйкоэффициенткорреляции,рассчитывающийся по формуле: 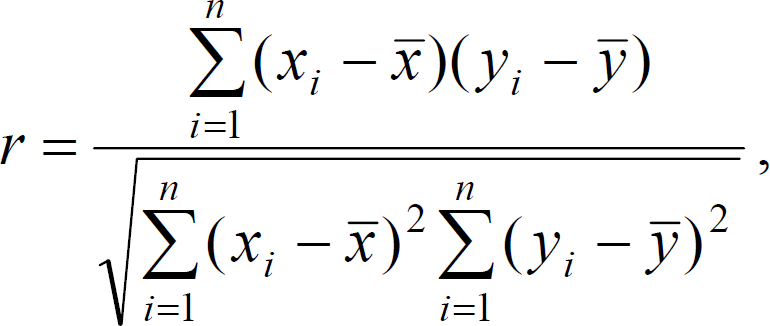 где xi, yi- значения признаков x и y для i-го объекта; n - число объектов; x, y - средние арифметические значения признаков x и y. Линейный коэффициент корреляции может принимать значения от -1 до +1, причем чем ближе величина коэффициента корреляции к предельным значениям, тем теснее будет взаимосвязь между признаками. В том случае, если коэффициент равен нулю, линейная связи между признаками будет отсутствовать. Прямая функциональная зависимость будет иметь место, если коэффициент корреляции равен +1 (или -1). Однако, зачастую необходимо не только оценить тесноту связи между изучаемыми признаками, но и определить ту степень с которой один признак воздействует на другой. В этом случае используется коэффициент детерминации, определяющий процентную долю изменений, происходящих под влиянием факторного признака, в общей изменчивости результативного признака: D = r 2100%, где r - коэффициент корреляции. В качестве примера подобных вычислений приведем данные из книги Б.Н. Миронова «История в цифрах», где была определена степень корреляционной зависимости между доходом и размерами помещичьего хозяйства в России на рубеже XIX-XX вв. по сведениям о размерах (в десятинах) и доходах (в тыс. руб.) десяти помещичьих имений6.Доходность имения зависела от его размера, но, кроме этого на нее влияло и качество земли, и состояние хозяйства, и деловые способности владельца, а также близость рынка и другие факторы. В связи с этим, исследователь поставил задачу узнать, насколько же размер имения влиял на доходность имения. Регрессионный анализ представляет собой совокупность методов математической статистики, которые позволяют определить форму связи между результативным и факторным признаками, установленной корреляционным анализом. Корреляционная связь описывается уравнением регрессии с помощью с помощью подходящей функции. Простейшее уравнение линейной регрессии: y = ax + b, 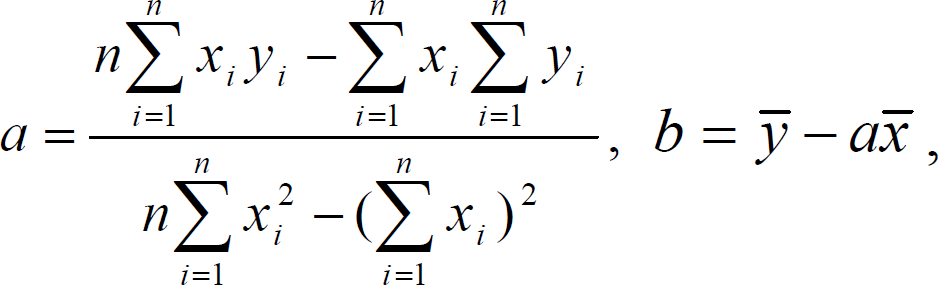 где x - факторный признак; y - результативный признак; a и b – параметры уравнения, которые могут быть найдены методом наименьших квадратов по формулам: где x - факторный признак; y - результативный признак; a и b – параметры уравнения, которые могут быть найдены методом наименьших квадратов по формулам:где xi, yi - i-е значение признаков x и у соответственно; х, у - средние арифметические признаков x и у;n- число значений признаков xиу. Регрессионный анализ не используется для определения наличия связи между переменными, ввиду того, что наличие такой связи и есть предпосылка для применения анализа. Линейная регрессия достаточно хорошо работающим в ряде простых задач. К ее достоинствам относится простота алгоритма и высокое быстродействие. Недостаток только один – неприспособленность к решению существенно нелинейных задач. Корреляционный анализ выявляет структуру взаимосвязей признаков, характеризующих изучаемое явление или процесс, но не способен объяснить, чем обусловлена именно такая структура связей. Ответить на этот вопрос позволяют методы факторного анализа. Факторный анализ объединяет методы анализа структуры множества признаков, характеризующих изучаемые явления и процессы, и выявления обобщенных факторов. В его основе лежит положение о том, что корреляционные связи между большим числом наблюдаемых показателей определяются существованием меньшего числа гипотетически наблюдаемых показателей или факторов. Объяснение множества исходных признаков через небольшое число общих факторов осуществляется сжатием информации, которая содержится в исходных коррелированных признаках. Основными характеристиками факторного анализа являются факторные нагрузки и факторные веса. Факторная нагрузка - это значение коэффициентов корреляции каждого из исходных признаков с каждым из выявленных факторов. Чем теснее связь данного признака с рассматриваемым фактором, тем выше значение соответствующей факторной нагрузки. Положительный знак факторной нагрузки указывает на прямую связь данного признака с фактором, а отрицательный знак – на обратную. Если значение факторной нагрузки близко нулю, то это свидетельствует о том, что этот фактор практически не влияет на данный признак.  В приведенной таблице факторных нагрузок содержится m строк (по числу признаков) и k столбцов (по числу факторов). Данные о факторных нагрузках позволяют судить о выборе исходных признаков, отражающих тот или иной фактор, и об относительной доле отдельных признаков в структуре каждого фактора.  В таблице факторных весов содержится n строк (что соответствует числу объектов) и k столбцов (по числу факторов). Факторные веса – это количественные значения выделенных факторов для каждого из n имеющихся объектов. У объектов с большими значениями факторных весов большая большая степень проявления свойств, присущих данному фактору. Факторы определяются как стандартизированные показатели со средним арифметическим значением 0 и средним квадратическим отклонением 1. Вследствие этого положительные факторные веса соответствуют тем объектам, которые характеризуются степенью проявления свойств больше средней, а отрицательные факторные веса соответствуют тем объектам, в которых степень проявления свойств меньше средней. Объекты ранжируются в пределах каждого фактора исходя из данных о факторных весах. А их, в свою очередь, можно рассматривать как значения индекса, характеризующего уровень развития объектов в рассматриваемом аспекте. Соответственно, факторные веса могут стать основой классификации исследуемых объектов. Создание многомерной типологии на основе факторного анализа особенно эффективно в том случае, если имеется большое число признаков, характеризующих совокупность объектов, но их содержательный отбор представляет значительные трудности. В такой ситуации необходимо «сжатие» информации, после чего проводится классификация по любому из выделенных факторов. В качестве примера эффективного использования факторного анализа можно назвать работу И.Д.Ковальченко и Л.И.Бородкина, посвященную изучению аграрной структуры районов Европейской России на рубеже XIX-XX веков. Исследователи не только охарактеризовали основные компоненты аграрной структуры, определив их сравнительные доли, но и получили обобщенные характеристики общего уровня аграрного развития отдельных районов и губерний страны | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||