Методичка 2020. МетодичкаТВ_и_МС_2020. Миниобранауки россии
 Скачать 1.04 Mb. Скачать 1.04 Mb.
|

|
Поскольку Fрасч = 0,2067 < 3,2388, нулевая гипотеза о равенстве дисперсий не отклоняется. Между дисперсиями внутри каждой группы существенной разницы нет, т. е. условие об однородности данных выполняется . Для проведения однофакторного дисперсионного анализа существует инструмент в пакете анализа Excel, который так и называется « Однофакторный дисперсионный анализ». Здесь задаются следующие параметры: входной интервал (вводится вся таблица с исходными данными); вид группирования (по столбцам/ по строкам); метки; поле указать выходной интервал Результаты анализа для примера (табл.5), приведенного выше, выведены в таблицу Таблица 5
Поскольку Fрасч = 3,4616 При обнаружении значительных различий между математическими ожиданиями необходимо определить, какие именно группы отличаются друг от друга. Для этого используется процедура множественного сравнения Тьюки – Крамера, описанная ниже. Вычисляются разности Вычисляется критический размах процедуры Тьюки – Крамера по формуле где Qu –верхнее критическое значение распределения стьюдентизированного размаха, имеющего c степеней свободы в числителе df1 = c и df2 = n степеней свободы в знаменателе, n-общее число наблюдений, n1 и n2 число наблюдений в i-ой и j-ой группах соответственно. Каждая из c(c – 1)/2 пар разностей математических ожиданий сравнивается с рассчитанным критическим размахом. Элементы пары считаются значительно различными, если модуль разности между ними
Таблица стьюдентизованного распределения Qu κ=df1, ν=df2. 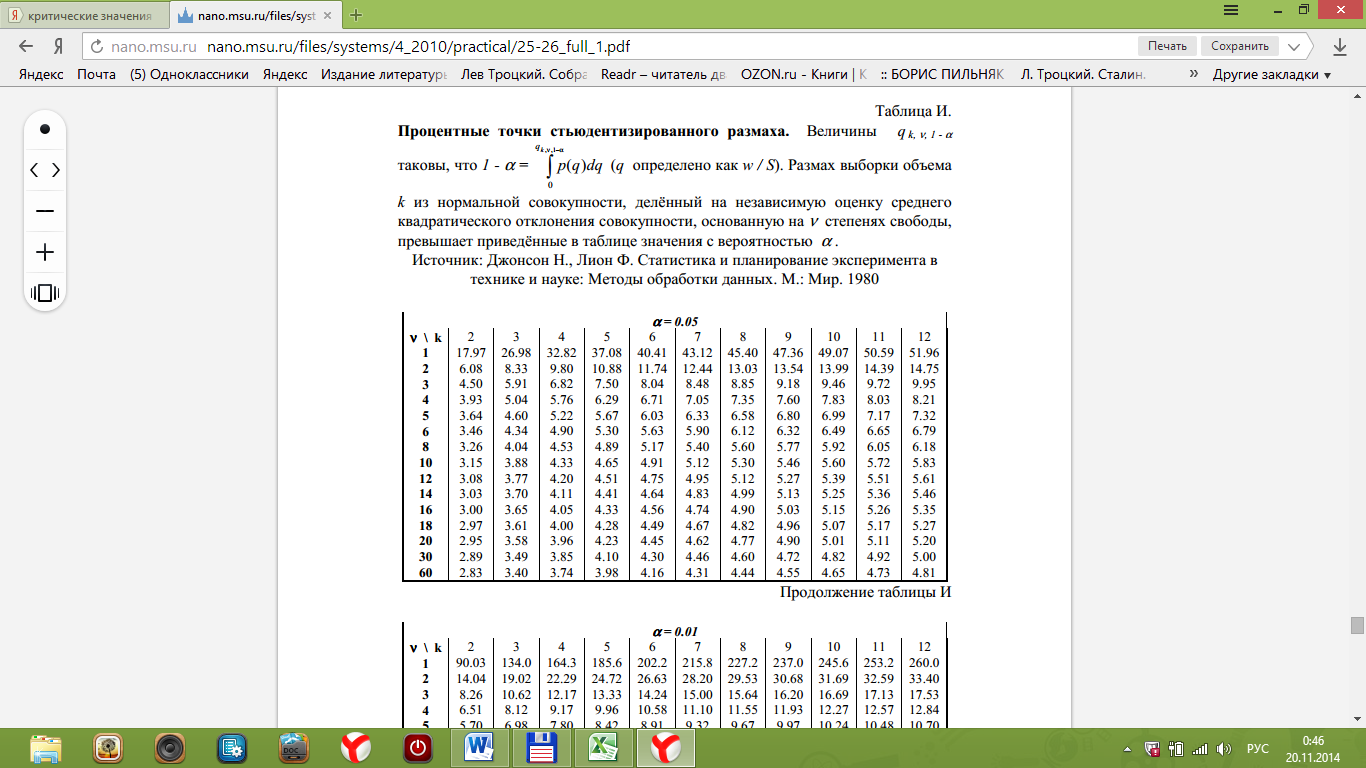 ЗАДАНИЕ Сгенерировать 4 нормально распределенные переменные. Первые 3 переменные генерируется в соответствии с Вашим вариантом. При генерации четвертой переменной математическое ожидание увеличивается на 2, а стандартное отклонение не изменяется Используя модифицированный критерий Левенэ проверить гипотезу о равенстве дисперсий. . Используя инструмент анализа « Однофакторный дисперсионный анализ» проверить гипотезу о равенстве математических ожиданий. При обнаружении значительных различий между математическими ожиданиями необходимо определить, какие именно группы отличаются друг от друга, используя процедуру множественного сравнения Тьюки – Крамера 8. ПРОСТАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ Простая линейная регрессия используется для исследования зависимости двух переменных. Уравнение простой линейной регрессии можно записать в виде yi = a0 + a1xi + i(1) где 1,…n- независимые одинаково распределенные случайные величины, определяющие действие различных неучтенных факторов на изменение результирующего показателя Y. Для определения оценок параметров в уравнении (1) широко используется метод наименьших квадратов (МНК), суть которого заключается в следующем. Определим величину ei следующим образом: ei = yi – (a0 + a1xi). Величина ei называется отклонением (остатком) наблюдаемого значения результирующей переменной yi в i – ом наблюдении от расчетного. Отклонение ei является оценкой случайной компоненты i. Построим оценку параметров (a0, a1) так, чтобы сумма их квадратов отклонений была минимальной: Сумму 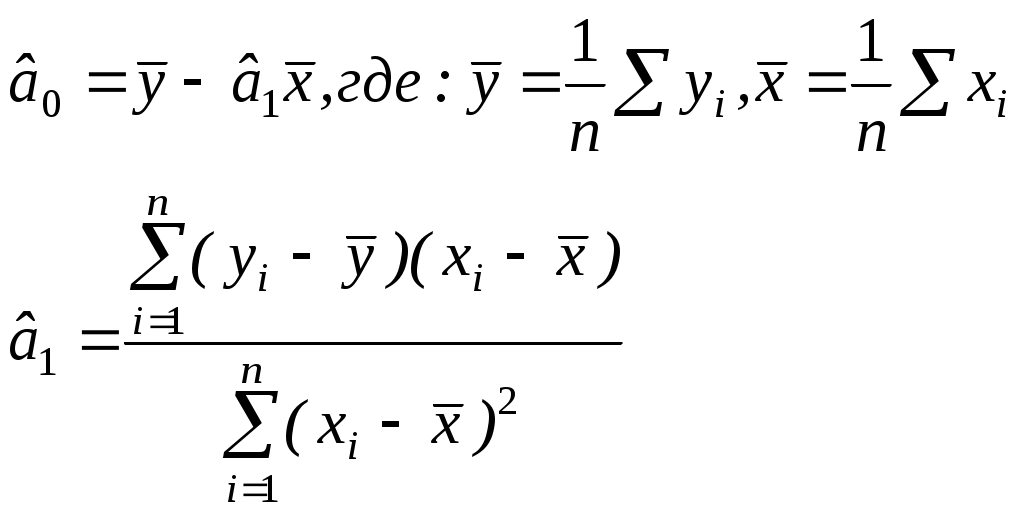 (3) и (4) (3) и (4)Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции ryx. Для линейной регрессии 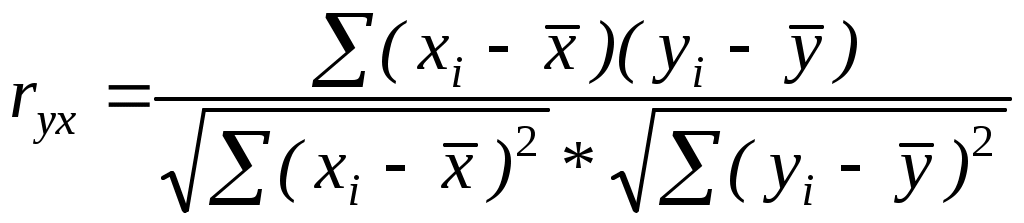 , ,Степень тесноты связи результирующей и факторных переменных можно оценить, используя шкалу Чеддока
Для определения статистической значимости показателя тесноты связи и существенности связи между результирующей и факторными переменными проводится дисперсионный анализ. Задача состоит в исследовании дисперсии результирующего показателя. Проверка гипотезы о существенности связи результирующей и факторных переменных в уравнения регрессии (статистической значимости множественного коэффициента корреляции) осуществляется с помощью F-критерия Фишера. Для проверки вычисляется F-статистика: где : 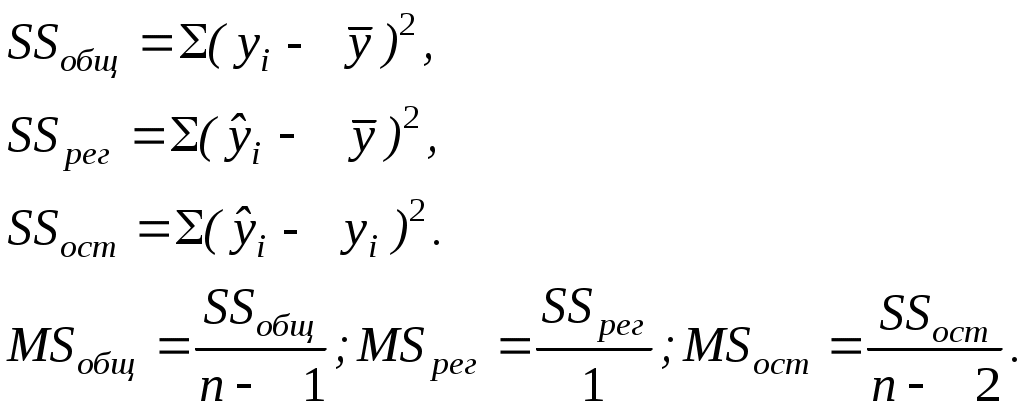 Здесь Из таблиц распределения Фишера определяется критическое значение Fdf1,df2,α при заданном уровне значимости α и степенях свободы df1 = 1, df2 = n-2, где уровень значимости α – вероятность совершения ошибки первого рода. Если Fpасч> Fdf1,df2,α , то полученное значение множественного коэффициента корреляции можно считать статистически значимым. В противном случае полагаем ryx = 0, что свидетельствует об отсутствии линейной зависимости между результирующей и факторными переменными в уравнения регрессии Дисперсионный анализ Для определения статистической значимости показателя тесноты связи и существенности связи между результирующей и факторными переменными проводится дисперсионный анализ. Задача состоит в исследовании дисперсии результирующего показателя. Проверка гипотезы о существенности связи результирующей и факторных переменных в уравнения регрессии (статистической значимости множественного коэффициента корреляции) осуществляется с помощью F-критерия Фишера. Величина F-критерия связана с коэффициентом детерминации R2: Проверка существенности связи в уравнения регрессии с помощью F-критерия проводится при условии нормальности распределения ошибки регрессии. Для проверки вычисляется F-статистика: где : 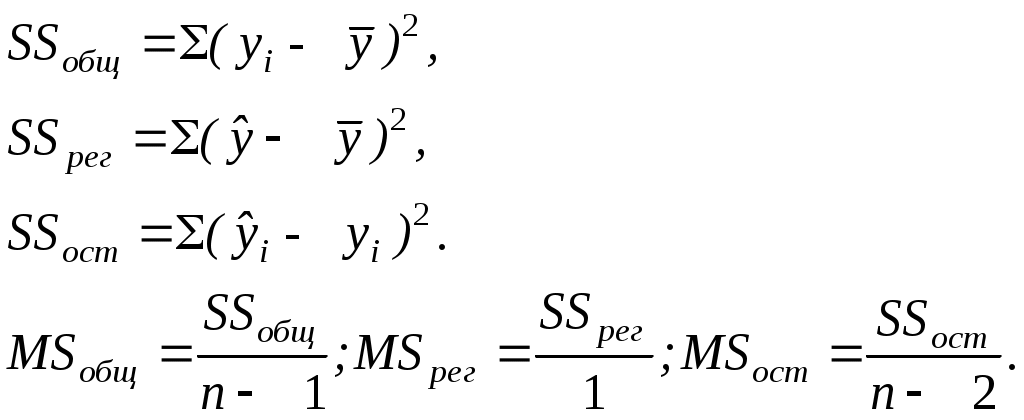 Из таблиц распределения Фишера определяется критическое значение Fdf1,df2,α при заданном уровне значимости α и степенях свободы df1 = 1, df2 = n-2, где уровень значимости α – вероятность совершения ошибки первого рода. Если Fpасч> Fdf1,df2,α , то полученное значение множественного коэффициента корреляции можно считать статистически значимым. В противном случае полагаем R = 0, что свидетельствует об отсутствии линейной зависимости между результирующей и факторными переменными в уравнения регрессии В пакетах программ используется другой способ проверки гипотезы о существенности связи результирующей и факторных переменных в уравнения регрессии. Там автоматически рассчитывается p-уровень (pF),т.е. значение вероятности, соответствующее расчетному значению F-критерия. 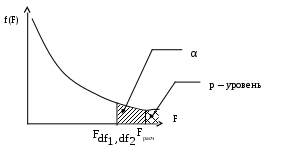 Если pF<α, то полученное значение множественного коэффициента корреляции можно считать статистически значимым. В противном случае полагаем R = 0, что свидетельствует об отсутствии линейной зависимости между результирующей и факторными переменными в уравнения регрессии. Чем меньше значение p-уровня, тем надежнее полученные оценки. Проверка статистической значимости коэффициентов уравнения регрессии При таком же предположении можно проверить гипотезы относительно каждого коэффициента с использованием t-статистики Стьюдента: a0, a1 – коэффициенты уравнения регрессии, r – коэффициент корреляции. t-статистика для коэффициента уравнения регрессии a0 – t-статистика для коэффициента уравнения регрессии a1 – t-статистика для коэффициента корреляции r – Ma0, ma1, mr – стандартные ошибки. 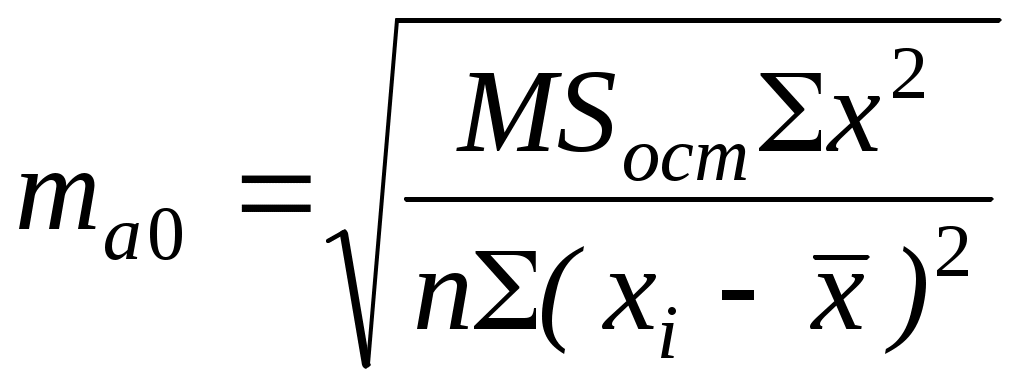 ; ; 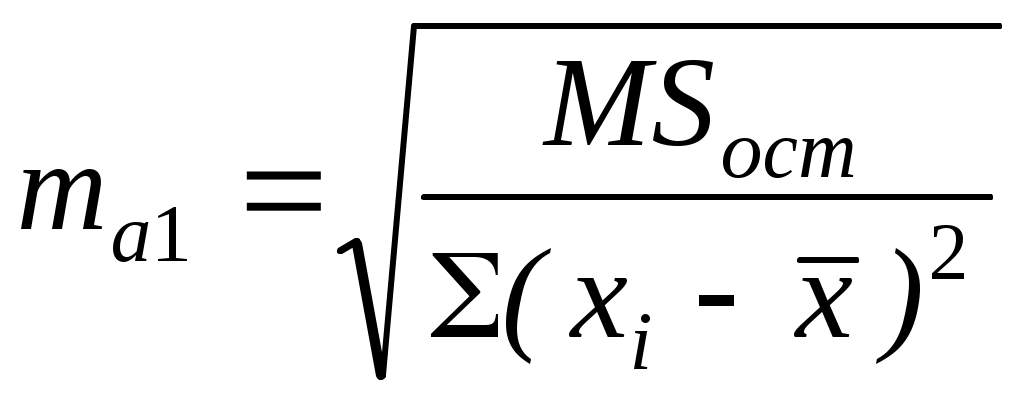 ; ; Для проверки значимости этих коэффициентов необходимо сравнить полученные расчетные значения ta0, ta1, tr с табличным значением распределения Стьюдента с df степенями свободы при уровне значимости α, т.е. с tdf,α (df = n-2). Если расчетное значение по абсолютной величине больше табличного, то нулевая гипотеза H0 Н0: a0 =0, Н0: a1 = 0, Н0: r = 0. отвергается и значение соответствующего коэффициента считается статистически значимым при данном уровне значимости α. Другой способ проверки заключается в сравнении p – уровня критерия Стьюдента (ptj) с уровнем значимости α. Если ptj<α, то полученное значение проверяемого коэффициента уравнения регрессии можно считать статистически значимым. Связь между F-критерием Фишера и t – статистикой Стьюдента выражается равенством: Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равна проверке гипотезы о существенности связи между переменными (результирующей и факторными) в уравнении регрессии. Качество уравнения регрессии можно также оценить с помощью средней ошибки аппроксимации ЗАДАНИЕ: Сгенерировать 45 значений случайной величины ε, считая, что случайная компонента ε распределена нормально с нулевым математическим ожиданием и единичной дисперсией. Для вычисления ε использовать генератор случайных чисел. Таблица1
Рассчитать 45 значений Y используя формулу Y = 11,5 + (0,14N)x + 2ε (5) где ε случайная компонента. Значения X возьмите из таблицы 1 Построить таблицу пар (Y,X), подставляя в уравнение (5) значения X из таблицы 1 и сгенерированные значения ε. N = Ваш номер по списку. Используя данные таблицы (Y,X) рассчитать коэффициенты a0 и a1, а также коэффициент корреляции ryx и записать уравнение регрессии. Сделать вывод о тесноте связи используя шкалу Чеддока. Рассчитать F – статистику Фишера и сделать вывод о статистической значимости коэффициента корреляции. 9. МНОЖЕСТВЕННАЯ РЕГРЕССИЯ Обобщением линейной регрессионной модели с двумя переменными является многомерная регрессионная модель (или модель множественной регрессии). Уравнение линейной регрессии 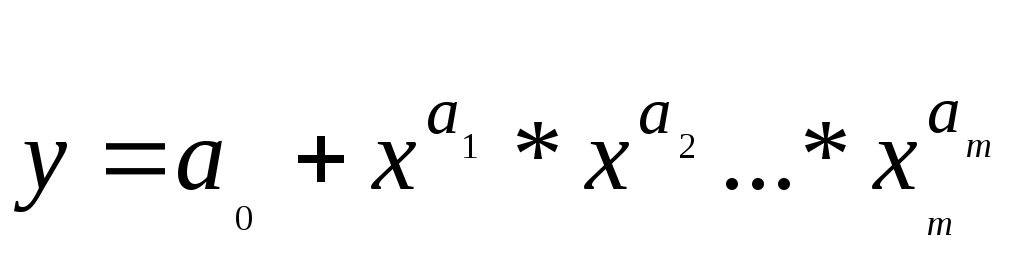 . Эта функция используется для изучения спроса и потребления, для построения производственной функции, где y – выпуск, а x – факторы производства и др. . Эта функция используется для изучения спроса и потребления, для построения производственной функции, где y – выпуск, а x – факторы производства и др.Коэффициенты линейной модели уравнения регрессии называются коэффициентами чистой регрессии. В случае полинома В степенной функции коэффициенты чистой регрессии показывают, на сколько процентов изменится результат, при изменении соответствующего фактора на один процент и при фиксированном значении остальных факторов. Они играют роль коэффициентов эластичности. Задача регрессионного анализа состоит в применении статистических методов для описания взаимосвязей между случайными величинами (признаками) с помощью математических моделей и оценки параметров этих моделей на основе данных статистического наблюдения. Признаки разделяют на два класса: зависимые (результирующие) и независимые (факторные, предикторные, объясняющие), то есть те, от которых зависят результирующие. Для количественной оценки зависимости между результирующими и факторными признаками определяются структура математической модели (вид аппроксимирующей функции) и ее параметры (коэффициенты аппроксимирующей функции). Оценка параметров (коэффициентов) модели производится на основе данных статистического наблюдения по совокупности показателей исследуемой зависимости. При проведении эконометрического исследования предполагается, что значения результирующей переменной носят случайный характер, поскольку зависят не только от факторных переменных, но и от тех факторов, которые мы не учитываем явно. Обозначим: Y - зависимая переменная, а x1, x2,…,xj,…,xm – это m независимых (факторных) переменных. Здесь j – номер факторной переменной. Формально эконометрическая модель записывается следующим образом Y = f(x1, x2,…,xm) + ε. (1) Здесь f(x1, x2,…,xm) - аппроксимирующая функция m независимых переменных (детерминированная компонента), ε – случайная компонента, отражающая влияние факторов, не учтенных в модели. Уравнение вида y = f(x1, x2,…,xm) называется уравнением регрессии. Частным видом эконометрической модели вида (1) является модель множественной линейной регрессии Y = a0 + a1x1 + a2x2 + ... + amxm + ε Коэффициенты a1, a2, …, am называются параметрами уравнения регрессии. Пусть имеется n статистических наблюдений и i – номер наблюдения. Данные статистического наблюдения можно представить в виде таблицы, состоящей из n строк вида (yi, x1i, x2i,…,xji,…,xmi). На основе имеющихся статистических наблюдений можно подобрать параметры a1, a2, …, am таким образом, чтобы уравнение множественной линейной регрессии наилучшим образом описывало бы наблюдаемые данные. Значения параметров a1, a2, …, am, определенные тем или иным способом называются оценками. Зная оценки параметров, модели можно использовать далее для прогнозирования значений результирующих показателей при тех или иных сочетания значений факторных показателей. Используя регрессионные модели можно проводить многовариантные расчеты по принципу «что будет, если…?». Эти модели находят широкое применение при принятии ответственных решений на практике. Решение уравнения регрессии находится с помощью метода наименьших квадратов. Анализ полученного решения заключается в проверке полученного уравнения регрессии путем расчета коэффициента множественной детерминации: 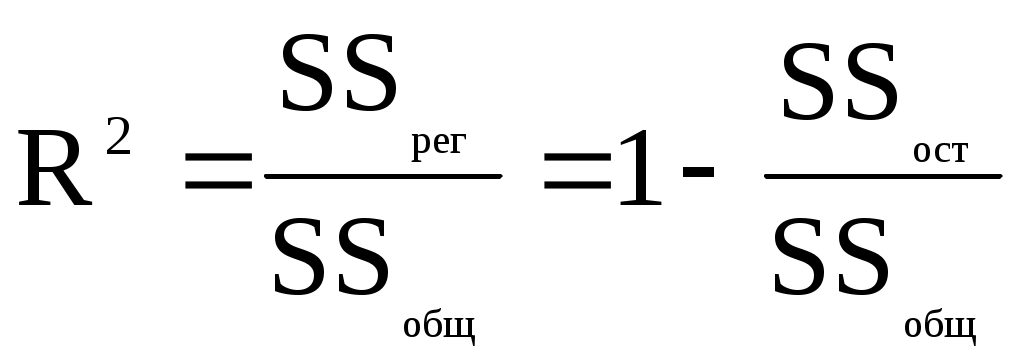 и F – статистики: 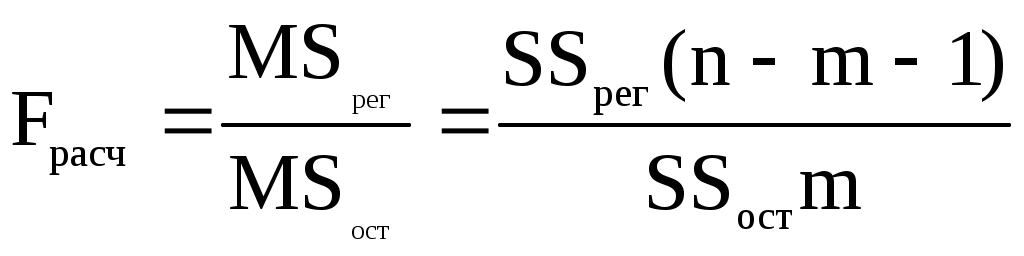 . .Если известен коэффициент детерминации R2, то F – статистка может быть рассчитана следующим образом: Рассчитанное значение сравнивается с табличным Fdf1,df2,α ( Недостатком коэффициента детерминации является то, что он увеличивается при добавлении новых переменных, хотя это и не обязательно означает улучшения качества регрессионной модели. Поэтому лучше пользоваться скорректированным коэффициентом детерминации, который определяется по формуле: Проверка значимости коэффициентов регрессии аналогична проверке коэффициентов парной регрессии и сводится к вычислению значения статистики 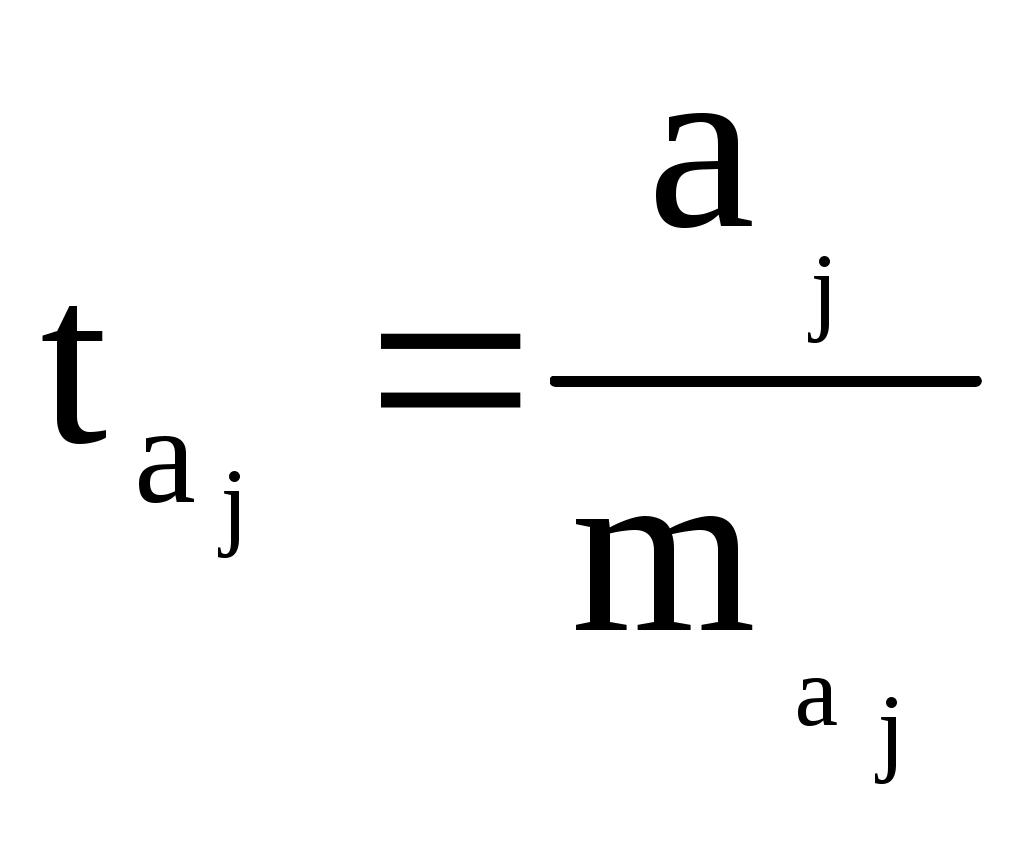 , , где Уравнение регрессии может быть преобразовано к стандартизованному масштабу 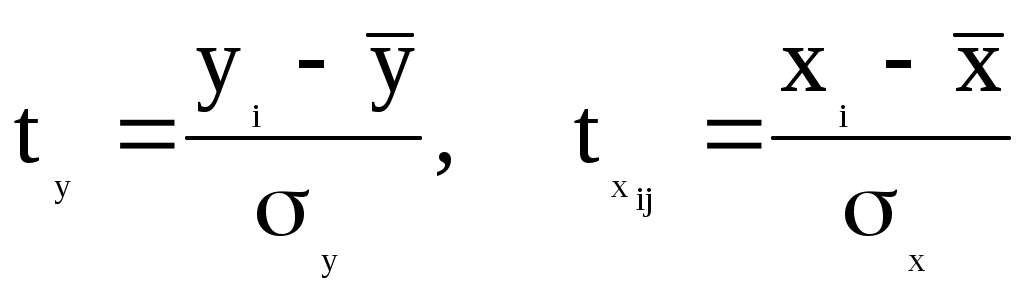 , где j – номер переменной. , где j – номер переменной.Значения коэффициентов j можно определить из уравнения: 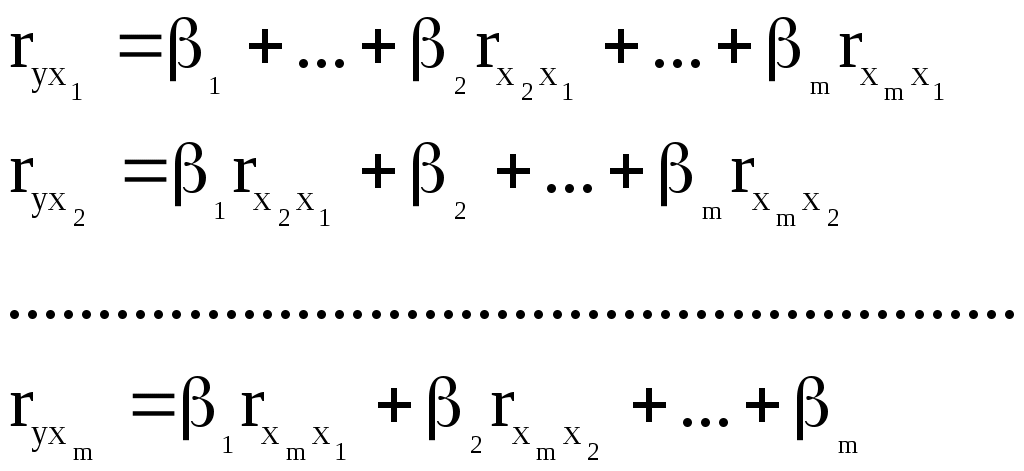 , , где Основное достоинство стандартизованного уравнения регрессии в том, что - коэффициенты позволяют ранжировать факторы по степени их воздействия на результат. Чем больше значение - коэффициента, тем больший вклад вносит соответствующая факторная переменная в значение результирующей. Коэффициенты чистой регрессии bj связаны со стандартизованными коэффициентами j соотношением Решение с помощью MS Exel С помощью инструмента анализа данных Регрессия, помимо результатов регрессионной статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики подбора линии регрессии, остатков и нормальной вероятности. Порядок действия следующий: в главном меню выберите Сервис/Анализ данных/Регрессия. Щелкните по кнопке OK; заполните диалоговое окно ввода данных и параметров вывода. Щелкните по кнопке OK; Пример использования инструмента Регрессия приведен в файле Пример.xls Исходные данные
Две последние строки содержат выборочные средние значения и выборочные стандартные отклонения sx, sy, рассчитанные с помощью функции СТАНДОТКЛ. Исходные данные вводятся в окно ввода (рис.1). 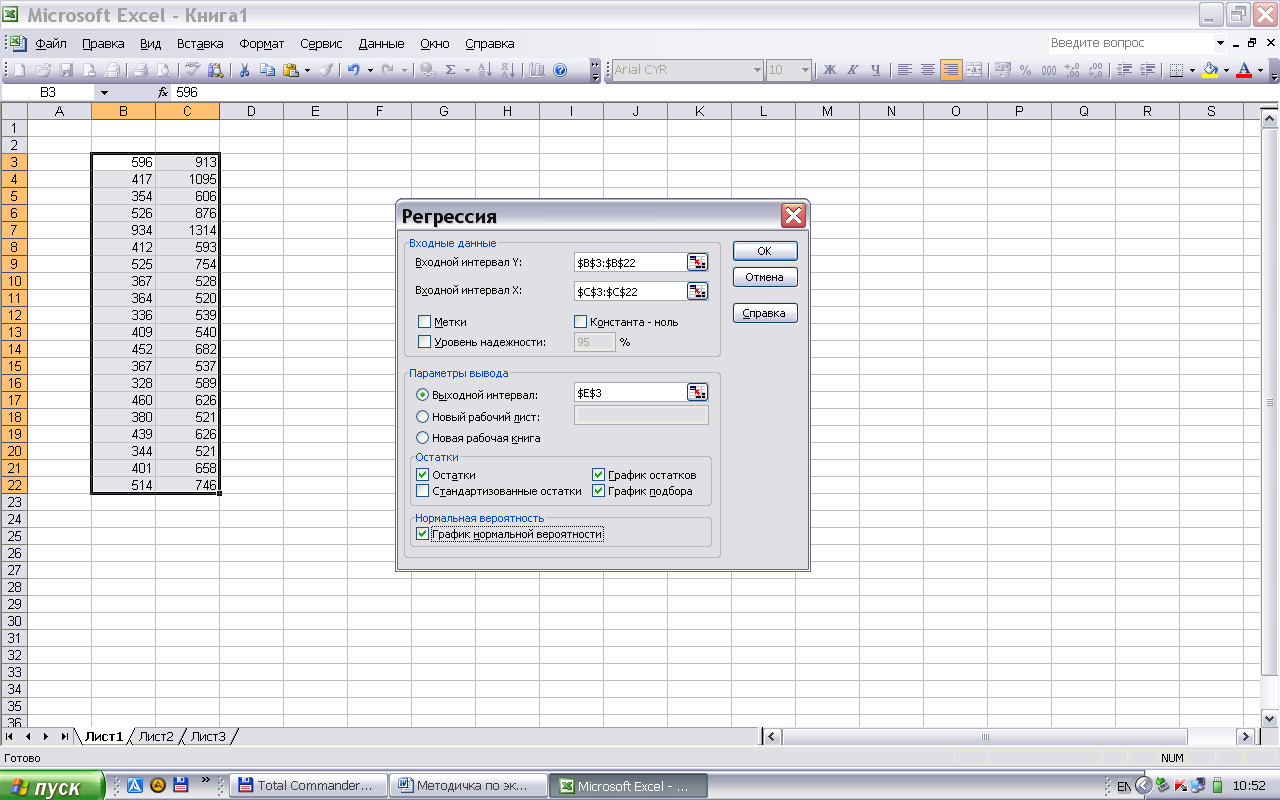 Рис 1. Окно Ввода Результаты расчета приведены ниже. Здесь: Множественный R - R R-квадрат - R2 Нормированный R-квадрат - Значимость F - pF Коэффициенты - значения коэффициентов (оценки) Y-пересечение - a0 Переменная X1 – a1 P-Значение - ptj Предсказанное Y - Остатки
График подбора содержит наблюдаемые и предсказанные значения, иллюстрирует размах отклонений рассчитанных значений от наблюдаемых для переменной Y. 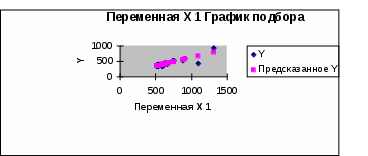 График нормального распределения используется для визуальной проверки выполнения условий Маркова-Гаусса  | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||