Педогагическая практика. Отчет по практике студента группы ивт5 зфо фролова Евгения Сергеевича Уровень подготовки
 Скачать 304.63 Kb. Скачать 304.63 Kb.
|

|
Тема занятия. «Классификация моделей данных» Цели занятия: Предметные: познакомить, закрепить, обобщить знания студентов по теме «Классификация моделей данных». Метапредметные: познавательные: развивать поиск и выделение необходимой информации, умение структурировать знания, обобщить и закрепить знания о системе счисления. коммуникативные: постановка вопросов, умение выражать свои мысли, умение вести диалог, умение задавать вопросы. регулятивные: целеполагание, планирование, контроль. личностные: смыслообразование, самоопределение, морально-этическая ориентация. Вид и форма занятия: Лекция. Время занятия: 90 мин Методы обучения: словесный, наглядный. Форма обучения: коллективная, индивидуальная. Оборудование: интерактивная доска, проектор. Ход занятия. Организационное начало занятия (1 мин.) Добрый день все ли готовы к новому занятию? Давайте проверим все ли сегодня присутствуют. Проверка д/з (3 мин.) Итак, наше занятие начнём с проверки д/з. Все успешно с ним справились? Сейчас проверим домашнее задание. Актуализация знаний (12 мин) На прошлом занятии мы проходили тему Жизненный цикл баз данных. По не большому опросу я увижу кто как освоил данную тему. Какие уровни включает архитектура баз данных? Какие основные компоненты включает система баз данных? Открытие нового знания (50 мин.) Итак, сегодня мы с Вами поговорим на тему: «Классификация моделей данных». Для начала запишем: Основная задача построения моделей данных – адекватное описание предметной области для последующего перевода на язык информационных систем. При этом одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных». Теперь отложите ручки и послушайте: Категория «данные» тесно связана с понятием «информация». Под информацией понимают любые сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые воспринимают информационные системы (в том числе и живые организмы) в процессе жизнедеятельности и работы. Под данными можно понимать информацию, фиксированную в определённой форме, пригодной для последующей обработки, хранения и передачи. Понятие данные в концепции баз данных – это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. В энциклопедии технологий баз данных данные определяются как «представление фактов о предметной области системы баз данных или информационной системы в форме, допускающей их хранение и обработку на компьютерах, передачу по каналам связи, а также восприятие человеком». Примеры данных: ткань платьевая «Вечер», $50 и т.д. Для использования данных пользователь должен задать им определённую структуру с учётом смыслового содержания. Поэтому центральным понятием в области баз данных является понятие модели данных. Под моделью понимается представление реальных сущностей, при котором отражаются только некоторые их свойства и которое может материализоваться в различных формах. В теории баз данных используются разные модели: модели предметной области, модели данных, архитектурные модели, модели транзакций. Для их описания используются математический аппарат, графическая нотация, специально разработанные дескриптивные языки и т.д. Не существует однозначного определения термина «модель данных», у разных авторов эта абстракция определяется с некоторыми различиями. Сейчас запишем определение: Модель данных – это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их как сведения, содержащие не только данные, но и взаимосвязь между ними. Рассмотрим классификации моделей данных, для этого включим проектор и посмотрим на доску и перечертим схему в тетради. 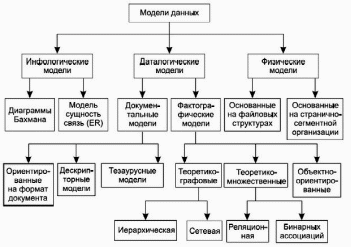 А сейчас разберём каждую модель по подробнее. В соответствии с рассмотренной ранее трёхуровневой архитектурой ANSI/SPARC можно определить понятие модели данных по отношению к каждому уровню. Физическая организация данных оказывает основное влияние на эксплуатационные характеристики базы данных. Разработчики пытаются создать наиболее производительные физические модели данных, предлагая пользователям тот или иной инструментарий для поднастройки модели под конкретную СУБД. Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хеширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными. Модели данных, используемые на концептуальном уровне, характеризуются большим разнообразием. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных. При проектировании базы данных выделяют ещё один уровень, предшествующий рассмотренным трём уровням. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими. Инфологическая модель отображает реальный мир в некоторые, понятные человеку концепции, полностью независимые от параметров среды хранения данных. Термин «инфологическая модель» означает «концептуальная модель в самом широком смысле», многие авторы вместо него используют термины «абстрактная модель», «концептуальная в широком смысле модель». Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложений. Инфологическая модель должна быть отображена в компьютерно-ориентированную даталогическую модель, поддерживаемую конкретной СУБД. В даталогическом аспекте рассматриваются вопросы представления данных в памяти информационной системы. Документальные модели данных применяются для представления слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке (монографий, публикаций в периодике, текстов законодательных актов и т.п.). Модели, ориентированные на формат документа, связаны, прежде всего, с языками разметки документов. Стандартный обобщённый язык разметки документов SGML (Standard Generalized Markup Language) позволяет отделить аспекты содержания документов от аспектов его представления. Описание документов в этом языке не зависит от программно-аппаратной платформы, на которой осуществляется их обработка. На его основе разработаны программные системы управления документами, а также браузеры для просмотра размеченных документов. На основе языка SGML разработан язык гипертекстовой разметки HTML (Hyper Text Markup Language), применяемый для отображения статистических данных на Web-страницах. Этот язык определяет оформление элементов документа и имеет некий ограниченный набор инструкций – тегов, при помощи которых осуществляется процесс разметки. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете. Однако HTML сегодня уже не удовлетворяет современным требованиям. И ему на смену был предложен новый язык гипертекстовой разметки XML (Extensible Markup Language). Язык XML стал основой активно развивающейся новой более перспективной и совершенной платформы для среды Web. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. Сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания. Тезаурусные модели основаны на принципе организации словарей и содержат определённые языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах подчиняется тезаурусным моделям. Дескрипторные модели – самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор – описатель. Этот дескриптор имел жёсткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и ещё ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, т.е. по тем параметрам, которые характеризовали патент, а не по самому тексту патента. Фактографические модели представлены в виде специальным образом организованных совокупностей формализованных записей данных. Основанные на таких моделях фактографические системы используются не только для реализации информацинно-справочных функций (в отличие от документальных систем), но и для решения задач обработки данных. Под обработкой данных понимается специальный класс решаемых на ЭВМ задач, связанных с вводом, хранением, сортировкой, отбором и группировкой данных однородной структуры. Центральным функциональным звеном фактографических систем является СУБД. На этом закончим и поговорим о том, что мы сегодня прошли. Закрепление открытых знаний (14 мин.) А сейчас мы поговорим о том, что мы сегодня изучали, для этого задам Вам несколько вопросов по пройденной теме: Привести классификацию моделей данных согласно архитектуре ANSI/SPARC. Дать характеристику инфологическим моделям. Какие языки используются для описания моделей, ориентированных на формат данных? Подведение итогов (5 мин.) Сегодня было достаточно плодотворное занятие. Итак, что мы с вами сегодня изучили? (ответы студентов). Д/З (1 мин.) Подготовить ответы на контрольные вопросы. Выставление оценок (3 мин.) Оценки получают активно работающие на занятии студенты. Организационное окончание занятия (1 мин.) Наше занятие подошло к концу. Спасибо, что активно себя проявили. Хорошего дня! План-конспект занятия, проведенного самостоятельно Тема занятия. «Разновидности инфологических моделей данных» Цели занятия: Предметные: познакомить, закрепить, обобщить знания студентов по теме «Разновидности инфологических моделей данных». Метапредметные: познавательные: развивать поиск и выделение необходимой информации, умение структурировать знания, обобщить и закрепить знания о системе счисления. коммуникативные: постановка вопросов, умение выражать свои мысли, умение вести диалог, умение задавать вопросы. регулятивные: целеполагание, планирование, контроль. личностные: смыслообразование, самоопределение, морально-этическая ориентация Вид и форма занятия: Лекция. Время занятия: 90 мин Методы обучения: словесный, наглядный. Форма обучения: коллективная, индивидуальная. Оборудование: интерактивная доска, проектор. Ход занятия. Организационное начало занятия (1 мин.) Добрый день все ли готовы к новому занятию? Давайте проверим все ли сегодня присутствуют. Проверка д/з (10 мин.) Итак, наше занятие начнём с проверки д/з. Все успешно с ним справились? Сейчас проверим домашнее задание. Актуализация знаний (4 мин) На прошлом занятии мы проходили тему «Классификация моделей данных» и там мы узнали, что такое инфологическая модель данных, кто помнит определение? Открытие нового знания (60 мин.) А сегодня мы рассмотрим их разновидности, так что послушайте внимательно: Информационная алгебра была разработана рабочей группой комитета CODASYL. Целью данной работы являлось создание структуры машинно-независимого языка описания задач, ориентированного на системный уровень обработки данных. Основой концептуальной модели является представление, что информационная система имеет дело с объектами и событиями реального мира, которые представляются в виде данных. Информационная алгебра оперирует понятиями «сущность» и «свойства». Запишем определение: Сущность – нечто физически существующее в реальном мире. Сущность имеет свойства. Для каждой сущности каждому из её свойств приписывается значение из множества значений свойства. Слушаем дальше: Также в информационной алгебре вводится ряд понятий: система координат, точка значений, пространство свойств. Вводятся также понятия комплекса и агрегата. При описании задач основной операцией является отображение одного подмножества пространства свойств на другое. Рассматриваются два типа отображений. Одно соответствует операциям в данном файле (можно, например, определить отображение группы из пятиточек для каждого рабочего в одну новую точку, которая будет содержать итог за неделю). Эта операция называется агрегированием. Второй тип отображения соответствует операции обработки файлов, при которой точки из некоторого числа входных файлов обрабатываются для получения нового выходного файла – комплексирование данных. Создатели информационной алгебры надеялись, что развиваемый подход приведёт к появлению трансляторов, позволяющих переводить реляционные выражения в процедурную форму. Проектировщики должны специфицировать релевантные (существенные для задачи) наборы данных, а также связи и правила их объединения, в соответствии с которыми данные обрабатываются, классифицируются и объединяются в различные подмножества, в том числе в выходные результаты. Важно заметить, что в модели информационной алгебры выделены основополагающие элементы: сущности, свойства, значения свойства, которые позволяют адекватно описать некоторую предметную область и реально существующие объекты. Выделение этих элементов следует считать важным достижением. Здесь выделены три основные составляющие, присущие природе данных: носитель свойств («сущность»), сами свойства («свойства»), каждому из которых приписывается значение («значение свойства»), также вводится понятие пространства – «пространство свойств». Однако данная модель не отражает ряд важных моментов, присущих природе данных, в частности не учитывается, что: − носители свойств могут находиться в определённых отношениях друг с другом и образовывать некоторую структуру; − сами свойства между собой также могут находиться в некоторых отношениях. В модели CODASYL введено понятие значения показателя, при этом также необходимо указать некоторую характеристику упорядочения, такую как номер наблюдения, дату измерения показателя, время и т.п., чтобы была возможность различать ряд значений определённого бъекта по определённому показателю. Данная характеристика, ввиду её природой естественности, в модели CODASYL присутствует неявно и входит в свойства. Выделение характеристики упорядочения позволяет при необходимости исследовать динамику изменения показателей, задать отношения: быть позже, быть раньше, относиться к одному интервалу (к неделе, месяцу, году), отстоять на определённый промежуток времени и др.; ввести операции усреднения по интервалам и подсчёта итоговых сумм за период. То есть использование характеристики упорядочения даёт возможность в значительной мере автоматизировать процесс подготовки данных для последующего анализа, в том числе статистического. Рассмотрим и зарисуем два вида связи в модели Смитов, для этого включим проектор и посмотрим на интерактивную доску: 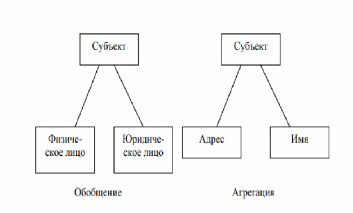 Модель Смитов. В семантическом моделировании проектируется схема понятий прикладной области в их взаимосвязи. Предлагались и предлагаются различные пути такого моделирования. Вот, например, какие метапонятия рассматривали для концептуального моделирования в конце 1970-х гг. Дж. Смит и Д. Смит. Исходными базовыми понятиями в трактовке этих двух специалистов являются объекты и связи между объектами. Связи могут быть двух видов: обобщение и агрегация. Обобщение интуитивно ясно, и связывает одни объекты с другими, по смыслу более общими. Например, объект «животное» есть обобщение для объектов «собака» и «лошадь». Агрегация связывает разнородные объекты по признаку компонентного вхождения в другие объекты, как например, «колеса» и «кузов» связаны с «автомобилем» тем, что последний состоит из первых. Независимо оба вида связей образуют каждый свою иерархию среди объектов модели. Кроме этих базовых имеются и другие понятия концептуальной модели, как-то атрибут, отношение, экземпляр, индивид. Самое замечательное в модели Смитов – это относительность перечисленных понятий. Одно и то же явление может быть и объектом, и отношением, и атрибутом, и экземпляром, и индивидом, и всё определяется точкой зрения на явление. Зависимость интерпретации от точки зрения на явление (а точнее – возможность выбора точек зрения с разной интерпретацией) – это очень мощное свойство, придающее концептуальной модели большую гибкость и приспособляемость в описании проектируемой ИС. Это свойство, например, будь оно реализовано, позволило бы в информационной системе смотреть на «адрес» то как на объект реестра адресов, то как на атрибут «лица», то как на отношение, связывающее владельца с остальными жильцами – когда, где и кому как нужно. Наиболее близко к концептуальной в этом отношении подошла (теоретическая) реляционная модель данных, а вот объектный подход с его фиксированной интерпретацией структуры отстоит от реляционного на шаг назад. В модели Смитов выделяются две иерархии – иерархия агрегаций (отношение разнородных объектов) и иерархия обобщений (по типу «собака, лошадь – животное»), в точках пересечения появляются абстрактные объекты. Вводится также ряд понятий: индивиды, категории, компоненты. Для успешной интеграции понятий существует «принцип относительности объектов», который утверждает, что индивиды, категории, отношения и компоненты – разные способы рассмотрения одних и тех же объектов. Разработана методология спецификаций, основанная на принципах относительности объектов и сохранения индивидов. Отказ от чёткого разграничения ролей объектов является одновременно и сильной и слабой стороной данной модели. Слабые стороны данной модели проявляются в тех случаях, когда можно чётко разделить объекты (носители свойств) и свойства, что характерно для систем статистической обработки. Можно отметить, что не существует формализма, позволяющего отличить объект от свойства, поэтому это должно задаваться извне для построения более конкретной модели. напоминает навигационную модель страниц и ссылок сегодняшнего Интернета, её иногда называют моделью навигации данных. На диаграммах Бахмана изображают типы записей и связи между типами записей. Следует учитывать, что это одна из первых инфологических моделей. Чарльз Бахман в GE (General Electric) построил прототип системы навигации по данным. За руководство работы инициативной группой DBTG, разработавшей стандартный язык определения данных и манипулирования данными, Бахман получил Тьюринговскую премию. В своей Тьюринговской лекции он описал эволюцию моделей плоских файлов к новому миру, где программы могут осуществлять навигацию между записями, следуя связям между записями. Идеологическая основа работы Бахмана (более «научно» называемая моделью базы данных) IDS, за которую Бахман заслуженно был удостоен в 1973 г. высшей компьютерной награды ACM, получила название «сетевой» (network). Модель «сущность-связь». Наиболее популярной семантической моделью является модель «сущность-связь» (E/R – Entity/Relationship), предложенная Питером Пин-Шен Ченом в 1976 г. На использовании разновидностей E/R модели основано большинство современных подходов к проектированию баз данных (в основном реляционных). Данная модель имеет графическую природу, в ней используются изображения в виде диаграмм с прямоугольниками и стрелками, представляющие главные элементы данных и их связи. В данной модели выделены объекты (объектом называется «предмет, который может быть чётко идентифицирован») и свойства объектов. Таким образом, определяются отношения типа «объект-свойство». В связи с наглядностью представления данных модели «сущность-связь» получили широкое распространение в CASE-системах. Запишем основные определения: Объектная модель – логическая схема объектной БД в одной из общепринятых систем описания (обозначений). Хотя, по выражению К. Дж. Дейта, «не существует общепринятой, абстрактной и формально определённой "объектной модели данных"» и применительно к «объектной "модели"» правильнее говорить об «удобном ярлыке для целой совокупности некоторых взаимосвязанных идей», конкретные CASE-системы, реализующие на свой лад некоторые из этих идей, всё же существуют. Объектная схема – схема БД конкретной объектной СУБД, для описания модели данных используются основные принципы объектноориентированного программирования. Многомерная схема – схема данных в одной из многомерных систем представления данных. Данные представляются посредством гиперкуба (некоторого куба со множеством измерений). Информационные системы масштаба предприятия, как правило, содержат приложения, применяемые менеджерами высшего звена и предназначенные для комплексного многомерного анализа данных, их динамики, тенденций и т.п. Такой анализ в конечном итоге призван способствовать принятию решений. Нередко эти системы так и называются – системы поддержки принятия решений (DSS). Указанные приложения обычно обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Чаще всего такие агрегатные функции образуют многомерный (а, следовательно, нереляционный) набор данных (нередко называемый гиперкубом или метакубом, оси которого содержат параметры, а ячейки – зависящие от них агрегатные данные). Пример многомерной модели показан на слайде: 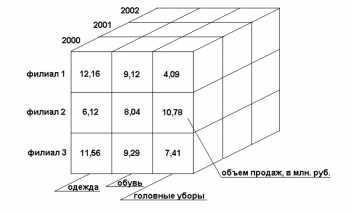 С середины 1990-х гг. интерес к многомерным моделям стал приобретать массовый характер. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения. Многомерные СУБД предназначены для интерактивной аналитической обработки. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. К основным понятиям многомерных моделей относятся измерение и ячейка. Измерение образуют множество однотипных данных, образующих одну из граней гиперкуба. Ячейка – это поле, значение которого однозначно определяется фиксированным набором значений. Тип поля определён как цифровой. Вдоль каждого измерения данные могут быть организованы в виде иерархии, отражающей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчёты, получать подмножества данных. При использовании более трех измерений представить и изобразить такой куб в рамках 3-мерного пространства, ограниченного высотой, шириной и глубиной, невозможно. В данном случае разработчики применяют специальные методы для отображения неотображаемого, например показ нескольких последовательностей (series) на одном графике. Каждая последовательность закрашивается отдельным цветом. Группа последовательностей представляет собой значение одного 4-го измерения. Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing). Концепция OLAP была описана в 1993 г. известным исследователем баз данных и автором реляционной модели данных Э. Ф. Коддом. Нередко для повышения скорости выполнения запросов пользователей данные кубов вычисляются заранее и хранятся в многомерной базе данных. Отметим, что многомерный анализ данных может быть осуществлён как в клиентском приложении, так и на сервере баз данных. Все производители ведущих серверных СУБД (IBM, Informix, Microsoft, Oracle, Sybase) производят серверные средства для такого анализа. Существует мнение, причём вполне обоснованное, что многомерные модели используются не для описания данных, а для их представления, так как «универсализация» отношений приводит к «потере точности» описания, но зато и к удобству восприятия информации конечным пользователем. Таким образом, значение многомерных схем – преимущественно «интерфейсное» (они удобны конечным пользователям), а не описательное. Объект-роль – модель концептуального описания, принятая в системе Info Modeler фирмы Visio. В этой системе для модели «объектроль» используется два языка: графический и [условно-] естественный. В данной модели предполагается отсутствие принципиального различия между объектами и свойствами, в ряде случаев они могут меняться местами, всё зависит от «роли», которой исполняет объект при определённом описании. Приведённая классификация не является законченной и всеобъёмлющей. Можно выделить ряд «гибридных» моделей, имеющих отношения к разным классам. Например, RM/T – расширенная реляционная модель, предложенная в 1979 г. Коддом для «лучшего учёта семантики» прикладной области. В отличие от реляционной модели, RM/T вообще не получила никакого воплощения в реальных системах, но она также имеет большое методологическое значение. Закрепление открытых знаний (7 мин.) Теперь если у Вас остались вопросы или хотите что-либо уточнить, спрашивайте. Подведение итогов (5 мин.) Сегодня было достаточно плодотворное занятие. Итак, что мы с вами сегодня изучили? (ответы студентов). Д/З (1 мин.) Подготовиться к контрольной работе по теме: «Модели представления данных». Выставление оценок (1 мин.) Оценки получают активно работающие на занятии студенты Организационное окончание урока (1 мин.) Наше занятие подошло к концу. Хорошего дня! План-конспект занятия, проведенного самостоятельно |