Всё о метрологии. Предмет и задачи метрологии Метрология наука об измерениях
 Скачать 435.9 Kb. Скачать 435.9 Kb.
|

|
Пример. В условиях предыдущей задачи найти доверительную границу погрешности результата измерений для доверительной вероятности P=0.99. По данным табл. П.5 при k=4 находим tp=4.604 и, следовательно, доверительная граница: мм. Итог измерений: L = (15.785±0.023) мм, P = 0.99. При n→∞, а практически уже при n = 20–30 распределение Стьюдента переходит в нормальное распределение и где Φ(tp) — интегральная функции нормированного нормального распределения. В тех случаях, когда распределение случайных погрешностей не является нормальным, все же часто пользуются распределением Стьюдента с приближением, степень которого остается неизвестной. Кроме того, на основании центральной предельной теоремы теории вероятностей можно утверждать, что при достаточно большом числе наблюдений распределение среднего арифметического как суммы случайных величин Xi/n будет сколь угодно близким к нормальному. Тогда, заменяя дисперсию σ²X ее точечной оценкой [см. п. 4.4. Нормальное распределение], можно для оценки доверительной границы погрешности результата воспользоваться равенством (35). Число наблюдений n, при котором это становится возможным, зависит, конечно, от распределения случайных погрешностей. Соотношения (38) показывают, что итог измерения не есть одно определенное число. В результате измерений мы получаем лишь полосу значений измеряемой величины. Смысл итога измерений, например, L=20.00±0.05 заключается не в том, что L = 20.00, как для простоты считают, а в том, что истинное значение лежит где-то в границах от 19.95 до 20.05. К тому же нахождение внутри границ имеет некоторую вероятность, меньшую, чем единица, и, следовательно, нахождение вне границ не исключено, хотя и может быть очень маловероятным. Теперь найдем доверительные интервалы для дисперсии и среднеквадратического отклонения результатов наблюдений. Если распределение результатов наблюдений нормально, то отношение (43) имеет так называемое χ²-распределение Пирсона с k=n–1 степенями свободы. Его дифференциальная функция распределения описывается формулой 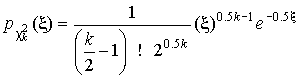 (44) (44)Кривые плотности χ²-распределения при различных значениях k, вычисленные по формуле (44), представлены на рис. 9. 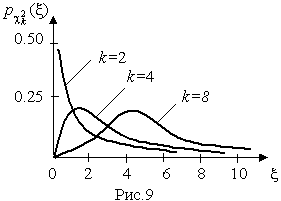 Значения χ²kp, соответствующие различным вероятностям Р того, что отношение (43) в данном опыте будет меньше χ²kp, представлены в табл. П.6 приложения для различных вероятностей Р и чисел k степеней свободы. Пользуясь этой таблицей, можно найти доверительный интервал для оценки дисперсии результатов наблюдений при заданной доверительной вероятности. Этот интервал строится таким образом, чтобы вероятность выхода дисперсии за его границы не превышала некоторой малой величины q, причем вероятности выхода за обе границы интервала были бы равны между собой и составляли соответственно q/2 (рис.10). 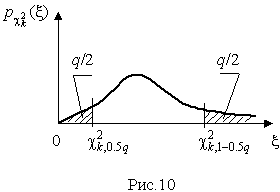 Границы χ²k,0.5q и χ²k,1–0.5q такого доверительного интервала находят из равенства F(χ²k,0.5q) = 0.5q, F(χ²k,1-0.5q) = 1-0.5q (45) Теперь, зная границы доверительного интервала для отношения χ²kp, запишем доверительный интервал для дисперсии: 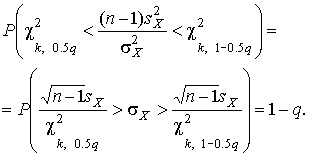 (46) (46)Полученное равенство означает, что с вероятностью α=1-q истинное значение σX среднеквадратического отклонения результатов наблюдений лежит в интервале ( ], границы которого равны 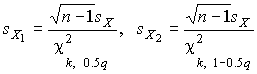 (47) (47)Пример. Даны результаты двадцати измерений длины li мм детали (табл.3). Таблица 3
В качестве оценки математического ожидания длины детали принимаем ее среднее арифметическое мм. Точечная оценка среднеквадратического отклонения результатов наблюдений составляет: 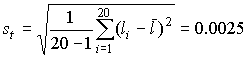 мм. мм.Приняв уровень доверительной вероятности α=1-q=0.90, находим для числа степеней свободы k = n–1 = 20–1 = 19 в табл. П.6 приложения: χ²k,0.5q = χ²19,0.05 = 10.117, χ19,0.05 = 3.18, χ²k,1-0.5q = χ²19,0.95 = 30.144, χ19,0.95 = 5.49. Границы доверительного интервала для среднеквадратического отклонения результатов наблюдений находим по формуле (47): 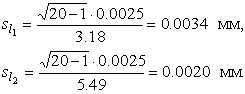 Полученные результаты говорят о том, что истинное значение среднеквадратического отклонения результатов наблюдений с вероятностью 0.90 лежит в интервале 0.0020–0.0034 мм. В табл. П.6 приведены значения χ²k только при числах степеней свободы от 1 до 30. При k>30 можно пользоваться приближенной формулой где tp определяется из условия Φ(tp)=P по табл. П.3, в которой помещены значения интегральной функции нормированного нормального распределения. Тогда границы доверительного интервала для среднеквадратического отклонения результатов наблюдений при доверительной вероятности α=1-q вычисляются по формулам (47) при значениях χk, равных 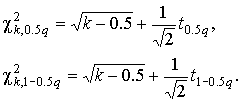 (49) (49)Так, если в условиях предыдущей задачи среднеквадратическое отклонение определено на основании n=42 измерений, то для α=1-q=0.90 из табл. П.3 находим: t0.5q = t0.05 = –1,6449, t1-0.5q = t0.95 = +1,6449. Величины χk при k=n–1=41 составляют: 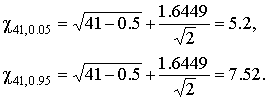 Границы доверительного интервала: 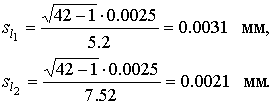 4.7. Проверка нормальности распределения результатов наблюдений В предыдущих разделах было показано, что результаты наблюдений можно оценить наиболее полно, если их распределение является нормальным. Поэтому исключительно важную роль при обработке результатов наблюдений играет проверка нормальности распределения. Эта задача представляет собой частный случай более общей проблемы, заключающейся в подборе теоретической функции распределения, в некотором смысле наилучшим образом согласующейся с опытными данными. При большом числе результатов наблюдений (n>40) данная задача решается в следующем порядке. Весь диапазон полученных результатов наблюдений Xmax…Xmin разделяют на r интервалов шириной ΔXi (i=1,2,…r) и подсчитывают частоты mi, равные числу результатов, лежащих в каждом i-м интервале, т. е. меньших или равных его правой и больших левой границы. Отношения (50) где n — общее число наблюдений, называются частостями и представляют собой статистические оценки вероятностей попадания результата наблюдений в i-й интервал. Распределение частот по интервалам образует статистическое распределение результатов наблюдений. Если теперь разделить частость на длину интервала, то получим величины (51) являющиеся оценками средней плотности распределения в интервале ΔXi. Отложим вдоль оси результатов наблюдений (рис. 11) интервалы ΔXi в порядке возрастания индекса i и на каждом интервале построим прямоугольник с высотой, равной pi*. Полученный график называется гистограммой статистического распределения. 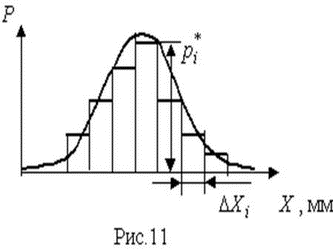 Площадь суммы всех прямоугольников равна единице: 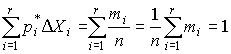 При увеличении числа наблюдений число интервалов можно увеличить. Сами интервалы уменьшаются, и гистограмма все больше приближается к плавной кривой, ограничивающей единичную площадь, — к графику плотности распределения результатов наблюдений. При построении гистограмм рекомендуется пользоваться следующими правилами: 1. Число интервалов выбирается в зависимости от числа наблюдений согласно рекомендациям табл.6. Таблица 6
2. Длины интервалов удобнее выбирать одинаковыми. Однако если распределение крайне неравномерно, то в области максимальной концентрации результатов наблюдений следует выбирать более узкие интервалы. 3. Масштабы по осям гистограммы должны быть такими, чтобы отношение ее высоты к основанию составляло примерно 5÷8. Пример. Было выполнено 100 измерений среднего диаметра резьбового калибра. Результаты наблюдений лежат в диапазоне 8.911–8.927 мм, т. е. зона распределения результатов составляет 0.016 мм. Весь диапазон удобно разделить на восемь равных интервалов через 0.002 мм. В табл. 7 приведены частоты mi, частости Pi* и плотности p* статистического распределения. Таблица 7
После построения гистограммы надо подобрать теоретическую плавную кривую распределения, которая, выражая все существенные черты статистического распределения, сглаживала бы все случайности, связанные с недостаточным объемом экспериментальных данных. Принципиальный вид теоретической кривой выбирают заранее, проанализировав метод измерения, или хотя бы по внешнему виду гистограммы. Тогда определение аналитического вида кривой распределения сводится к выбору таких значений его параметров, при которых достигается наибольшее соответствие между теоретическим и статистическим распределением. Одним из методов решения этой задачи является метод моментов. При его использовании параметрам теоретического распределения придают такие значения, при которых несколько важнейших моментов совпадают с их статистическими оценками. Так, если статистическое распределение, определяемое гистограммой, приведенной на рис. 11, мы хотим описать кривой нормального распределения, то естественно потребовать, чтобы математическое ожидание и дисперсия последнего совпадали со средним арифметическим и оценкой дисперсий, вычисленным по опытным данным. В предыдущем примере мм, sX=0.0028 мм и уравнение кривой нормального распределения, лучше всего согласующегося со статистическим распределением, должно иметь вид: 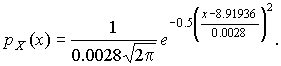 Далее законно возникает вопрос, объясняются ли расхождения между гистограммой и подобранным теоретическим распределением только случайными обстоятельствами, связанными с ограниченным числом наблюдений, или они вызваны тем, что результаты наблюдений в действительности распределены иначе? Для ответа на этот вопрос используют методы проверки статистических гипотез. Идея их применения заключается в следующем. На основании гистограммы, полученной при обработке опытных данных, строится гипотеза, состоящая в том, что результаты наблюдений подчиняются распределению FX(x) с плотностью PX(x). Для того чтобы принять или опровергнуть эту гипотезу, выбирается некоторая величина U, представляющая собой меру расхождения теоретического и статистического распределений. В качестве меры расхождения можно принять сумму квадратов разностей частостей и теоретических вероятностей попадания результатов наблюдений в каждый интервал, взятых с некоторыми коэффициентами: (52) где tp — коэффициенты, называемые весами разрядов; Pi — теоретические вероятности, определяемые как , (53) Здесь pX(x) — предполагаемая плотность распределения. Мера расхождения U является случайной величиной и, независимо от исходного распределения подчиняется χ²-распределению с k степенями свободы — см. формулу (44). Если значения всех частот mi>5, число измерений стремится к бесконечности, а веса ci выбираются равными n/Pi. Число степеней свободы распределения k = r–s, где r — число разрядов гистограммы статистического распределения, а s — число независимых связей, наложенных на частости Pi*. Если проверяется гипотеза о нормальности распределения, то к числу этих связей относится равенство среднего арифметического математическому ожиданию, а точечной оценки дисперсии - дисперсии предполагаемого нормального распределения. Кроме того, всегда требуется, чтобы сумма частостей по всем интервалам была равна единице. Поэтому в данном случае s = 3. По табл. П.6 можно при заданной доверительной вероятности α=1-q найти тот доверительный интервал (χ²k,0.5q, χ²k,1-0.5q) значений χ²k, в который мера расхождения может попасть по чисто случайным причинам. Если вычисленная по опытным данным мера расхождения окажется в указанном интервале, то гипотеза принимается. Это, конечно, не значит, что гипотеза верна. Можно лишь утверждать, что она правдоподобна, т.е. не противоречит опытным данным. Если же она выходит за границы доверительного интервала, то гипотеза отвергается как противоречащая опытным данным. Поскольку проверка гипотезы основывается на опытных данных, то при принятии решения всегда возможны ошибки. Отвергая в действительности верную гипотезу, мы совершаем ошибку первого рода. Вероятность ошибки первого рода называется уровнем значимости и составляет q=1-a. Принимая в действительности неверную гипотезу, мы совершаем ошибку второго рода. Вычислить ее вероятность, вообще говоря, невозможно, поскольку для этого нужно рассмотреть все прочие возможные гипотезы, являющиеся альтернативой обсуждаемой гипотезы. Можно лишь утверждать, что при уменьшении ошибки первого рода ошибка второго рода увеличивается, поэтому не имеет смысла брать слишком высокие значения доверительных вероятностей. Описанная процедура проверки гипотезы о том, что данное статистическое распределение является распределением с плотностью pX(x), называется критерием согласия χ². Проверка нормальности распределения согласно критерию χ² сводится к следующему. 1. Данные наблюдений группируют по интервалам, как при построении гистограммы, и подсчитывают частоты mi. Если в некоторые интервалы попадает меньше пяти наблюдений, то такие интервалы объединяют с соседними. При этом число степеней свободы k, конечно, уменьшается. 2. Вычисляют среднее арифметическое и точечную оценку среднеквадратического отклонения результата наблюдений sX, которые принимают в качестве параметров теоретического нормального распределения с плотностью pX(x). 3. Для каждого интервала находят вероятности попадания в них результатов наблюдений либо по общей формуле (29), либо приближенно как произведение плотности теоретического распределения в середине интервала на его длину: . (54) 4. Для каждого интервала вычисляют величины χ²i(i=1,2,…,r) и суммируют их по всем i, в результате чего получают меру расхождения χ². 5. Определяют число степеней свободы k=r-3 и, задаваясь уровнем значимости q=1-a, находят по табл. П.6 приложения значения χ²k,0.5q и (χ²k,0.5q, χ²k,1-0.5q). Если χ²k,0.5q < χ²k < χ²k,1-0.5q, то распределение результатов наблюдений считают нормальным. Критерий согласия χ²k, построенный на предельном переходе при n→∞, рекомендуется применять, если общее число наблюдений больше сорока. При малом числе наблюдений 11<n<50 нормальность распределения результатов наблюдений проверяется с помощью двух критериев. Первый критерий основан на вычислении статистики 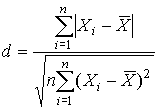 . (55) . (55)Гипотеза о нормальности распределения на основании первого критерия принимается, если при данном числе наблюдений и выбранном уровне значимости q1 соблюдается условие , где и — квантили, выбираемые из табл. П.8. На основании второго критерия гипотеза о нормальности распределения принимается, если не более m разностей превосходят уровень sXZ0.5(1+α), где sX — оценка среднеквадратического отклонения результатов наблюдения, Z0.5(1+α) — квантиль интегральной функции нормированного нормального распределения, определяемый по данным табл. П.2 приложения при значении Φ(Z0.5(1+α))=0.5(1+α) Величина α находится при заданном уровне значимости q2 второго критерия по данным табл. П.9. Распределение результатов наблюдения считается отличным от нормального, если оно не соответствует хотя бы одному из этих двух критериев. Уровень значимости составного критерия q ≤ q1+q2. При малом числе наблюдений для оценки нормальности можно воспользоваться понятием статистической функции распределения результатов наблюдений. Для ее построения полученные в процессе эксперимента результаты группируют в так называемый вариационный ряд X*(1),X*(2),…,X*(n) члены которого располагаются в порядке их возрастания, так что всегда X*(1)≤X*(2)≤…≤X*(n). Статистическую функцию распределения Fn(xk) определяют по формуле (56) Fn(xk) представляет собой ступенчатую линию, скачки которой соответствуют значениям членов вариационного ряда. Каждый скачок равен , если все n членов ряда различны. Если же для некоторого k X*(k)=X*(k+1)≤…≤X*(k+i), то Fn(x) в точке x=Xk возрастает на , где i – число равных между собой членов ряда. Если число наблюдений безгранично увеличивать, то статистическая функция распределения сходится по вероятности к истинной функции Fn(x). Для проверки нормальности распределения результатов наблюдений по табл.3 приложения находят значения zk, соответствующие полученным значениям Fn(xk) статистической функции распределения Φ(zk)=Fn(xk). Но переменная z определяется через результаты наблюдений как и если в координатах z, x нанести точки zk, xk, то при нормальном распределении они должны расположиться вдоль одной прямой линии. Если же в результате такого построения получится некоторая кривая линия, то гипотезу о нормальности распределения придется отвергнуть как противоречащую опытным данным. |