ГОС. Программирование. Программное обеспечение. Основные этапы решения задач на ЭВМ. Жизненный цикл программного средства
 Скачать 0.72 Mb. Скачать 0.72 Mb.
|

|
Виртуальная память — технология управления памятью ЭВМ, разработанная для многозадачных операционных систем. Позволяет увеличить эффективность использования памяти несколькими одновременно работающими программами, организовав множество независимых адресных пространств, и обеспечить защиту памяти между разными приложениями. Также позволяет программисту использовать больше памяти, чем установлено в компьютере, за счет откачки неиспользуемых страниц на вторичное хранилище. Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично-сегментное распределение памяти, а также свопинг. Страничное распределение памяти Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками). При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру - таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск. При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти. Сегментное распределение памяти. При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным. Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Кроме того, разбиение программы на "осмысленные" части делает принципиально возможным разделение одного сегмента несколькими процессами. При сегментном распределении виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту. Недостатком данного метода распределения памяти является фрагментация на уровне сегментов. Сегментно-страничное распределение. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов. 5. БАЗЫ ДАННЫХ.
База данных (БД) – совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отражающая состояние объектов и их взаимосвязей в рассматриваемой предметной области. Логическую структуру данных называют моделью представления данных. К основным моделям представления данных относятся: иерархическая, сетевая, реляционная, объектно-ориентированная. Система управления базами данных (СУБД) – совокупность программных средств, предназначенная для создания, сопровождения и совместного использования БД. Обычно СУБД различают по используемой модели данных. Также может выполнять функции словаря данных (хранение, защиту данных, ограничение доступа, связи и т.п.). С точки зрения пользователя, СУБД реализует функции хранения, изменения (пополнения, редактирования и удаления) и обработки информации, а также разработки и получения различных выходных документов. Основные функции СУБД:
Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала до конца. Если по каким-либо причинам транзакция окажется незавершенной, то она отменяется. Классификация СУБД:
Модель данных — это определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь. Таким образом, конкретная модель данных отражает структуру данных и способы взаимодействия с ними. Каждая БД и СУБД строится на основе некоторой явной или неявной модели данных. Все СУБД, построенные на одной и той же модели данных, относят к одному типу. Наиболее известными являются модели данных:
В иерархической модели связи между данными можно описать в виде упорядоченного графа (или дерева). 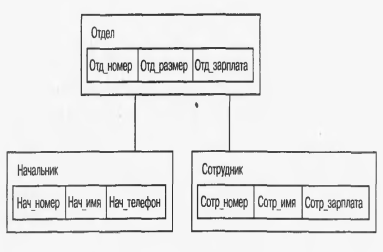 Иерархическая база данных представляет собой упорядоченную совокупность экземпляров данных типа «дерево», содержащих экземпляры типа «запись». Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание базы данных. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. К достоинствам иерархической модели относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель удобна для работы с иерархически упорядоченной информацией. Недостатком является громоздкость иерархической модели для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Можно сказать, что иерархической БД является файловая система, состоящая из корневой директории, в которой имеется иерархия поддиректорий и файлов. Сетевая модель данных позволяет отображать различные взаимосвязи элементов в виде произвольного графа, обобщая тем самым иерархическую модель. Сетевая БД состоит из набора записей и связей. Особых ограничений на связи не накладывается. Достоинства: эффективное использование памяти, скорость. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. Недостатки сетевой модели: высокая сложность и жёсткость схемы базы данных, построенной на основе, а также слабый контроль целостности вследствие допустимости установления произвольных связей между записями. Реляционная модель основывается на понятии отношение. Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является привычная двумерная таблица. Таблица имеет строки (записи) и столбцы (колонки). Достоинства: простота, понятность и удобство. Недостатки: неэффективное использование памяти, меньшая скорость сложность описания иерархических и сетевых связей. Объектно-ориентированная модель. В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Структура объектно-ориентированной базы данных представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или типом, конструируемым пользователем (определяется как class). Каждый объект – экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в базе данных образуют связную иерархию объектов. 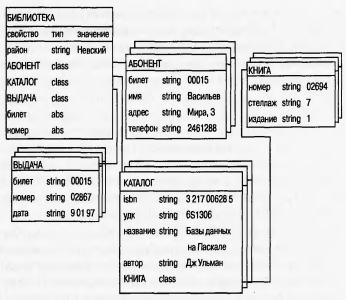 Основным достоинством объектно-ориентированной модели в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель позволяет идентифицировать отдельную запись базы данных и определять функции их обработки. Недостатками являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
Реляционная модель опирается на систему понятий, важнейшие из которых: отношение, сущность, атрибут, домен, кортеж, первичный ключ, внешний ключ. Все операции над реляционной базой данных сводятся к манипуляциям с таблицами. Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка - конкретный объект. Строки таблицы называются также кортежами. Таблица "Сотрудники отдела" содержит, например, сведения обо всех сотрудниках отдела, каждая ее строка - набор значений атрибутов конкретного сотрудника. Значения конкретного атрибута выбираются из домена – множества всех возможных значений атрибута объекта. Имя столбца должно быть уникальным в таблице. Столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. Любая таблица должна иметь по крайней мере один столбец. В отличие от столбцов строки не имеют имен. Порядок следования строк в таблице не определен, а количество логически не ограничено. Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции - среди них не существует "первой" и "последней". Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом. В таблице "Сотрудники отдела" первичным ключом служит столбец "Номер пропуска". В таблице не должно быть строк, имеющих одно и то же значение первичного ключа. Если таблица удовлетворяет этому требованию, она называется отношением. Взаимосвязь таблиц в реляционной модели поддерживается внешними ключами. Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами.
Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение. Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации (каждый неключевой атрибут встречается в отношениях по одному разу). Нормализация осуществляется путем разбиения отношения на 2 или более таким образом, чтобы в каждом отношении хранились только первичные факты (то есть факты, не выводимые из других хранимых фактов). Процесс проектирования БД с использованием метода нормальных форм является итерационным и заключается в последовательном переводе отношения из первой нормальной формы в нормальные формы более высокого порядка по определенным правилам. Каждая следующая НФ ограничивает определенный тип функциональных зависимостей, устраняет соответствующие аномалии при выполнении операций над отношениями БД и сохраняет свойства предшествующих НФ. Основные нормальные формы: 1) Первая нормальная форма. Отношение находится в первой нормальной форме (1НФ) тогда и только тогда, когда в любом допустимом значении отношения каждый его кортеж содержит только одно значение для каждого из атрибутов. В реляционной модели отношение всегда находится в первой нормальной форме по определению понятия отношение. 2) Вторая нормальная форма. Отношение находится во второй нормальной форме (2НФ), если оно находится в первой нормальной форме, и при этом любой его неключевой атрибут функционально полно зависит от ключа. Таким образом, во 2НФ нет неключевых атрибутов, зависящих от части составного потенциального ключа. Пример: Отношение ПОСТАВКИ (N_ПОСТАВЩИКА, ТОВАР, ЦЕНА). Поставщик может поставлять различные товары, а один и тот же товар может поставляться разными поставщиками. Тогда ключ отношения – <N_ПОСТАВЩИКА, ТОВАР>. Пусть все поставщики поставляют товар по одной и той же цене. Тогда имеем следующие функциональные зависимости: <N_ПОСТАВЩИКА, ТОВАР> ЦЕНА ТОВАР ЦЕНА Неполная функциональная зависимость атрибута "цена" от ключа приводит к следующей аномалии: при изменении цены товара необходим полный просмотр отношения для того, чтобы изменить все записи о его поставщиках. Данная аномалия является следствием того факта, что в одной структуре данных объединены два семантических факта. Следующее разложение дает отношения во 2НФ: ПОСТАВКИ (N_ПОСТАВЩИКА, ТОВАР) ЦЕНА_ТОВАРА (ТОВАР, ЦЕНА) |