Метод_указания к Лабораторным работам (1). Структурную и функциональную классификацию вс
 Скачать 2.03 Mb. Скачать 2.03 Mb.
|

Данные для вариантов 4-38
Таблица 3 Данные для вариантов 39-50
В вариантах 1-3 вывести на печать сообщения о ходе проверки и исправления имеющихся искажений. В вариантах 4-38 (Таблица 2) вывести на печать полученные числа с контрольными знаками, а также модуль и весовые коэффициенты. В вариантах 39-50 (Таблица 3) сформировать входной массив из имён файлов, подлежащих кодированию (или декодированию), произвести действия над ними и вывести на печать входной и выходной алфавиты, исходное и полученное кодированное (или декодированное) слово. Предусмотреть дополнительный массив из знаков, заполняющий пробелы в конце слова с фиксированной конечной его длиной (в случае, когда входное слово состоит, например, из 5 букв, а выходное из 7 букв). Варианты 39-45 (Таблица 3) предлагают кодирование исходных слов, варианты 46-50 - декодирование. Блок-схема и листинг программы проверки цифровых данных на оригинальность (вариант 2, рис.1) Исходные данные: S(10) - массив 5-тизначных чисел, проверяемый на оригинальность (избыточность). SD(10) - тот же массив S(10), но уже с удалёнными избыточными (дублированными) данными. В блоке 1 осуществляется ввод в оперативную память вычислительной машины и вывод на экран монитора исходного массива S(10). В блоках 2-5 осуществляется проверка данных на избыточность. Она осуществляется следующим образом: 1-й элемент массива сравнивается со вторым (блок 4). Если элементы равны, то значение второго элемента становится равным нулю (блок 5), а в противном случае происходит переход к 3-му элементу массива, и производится проверка уже 3-го и 1-го элементов массива. Когда проверка осуществилась до конца массива, т. е. проверка значений элементов 1 и 10 уже дала какой-либо результат, осуществляется переход ко 2-му элементу массива и проверка его с 3-м, 4-м и т. д. элементами. И так далее до конца, пока не будут сравнены 9 и 10-й элементы. Затем полученный массив переименовывается в SD(10) в выводятся на печать (блоки 6-8). 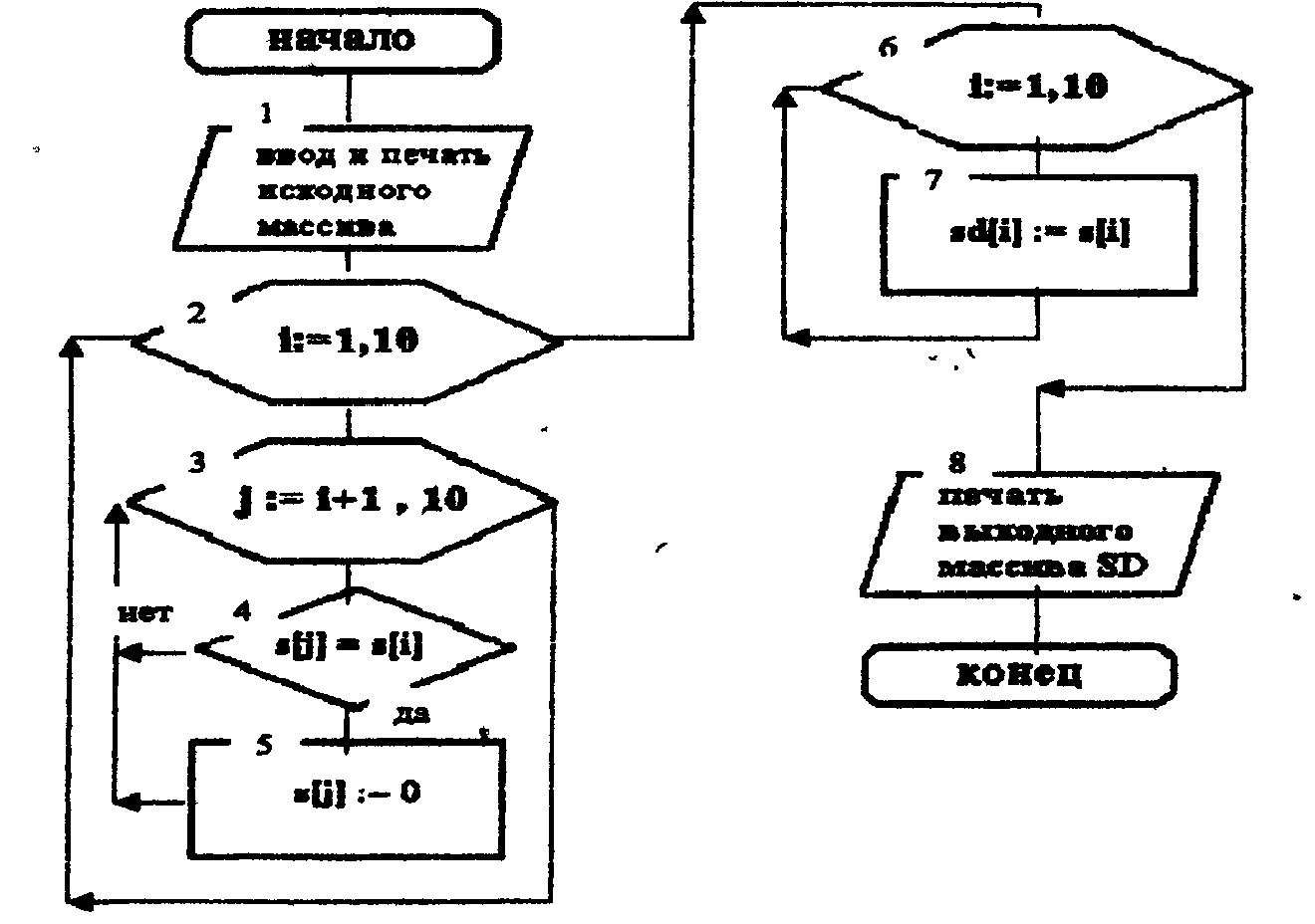 Рис.1. Блок-схема программы проверки цифровых данных на оригинальность program demo1; var s,sd:array[1..10] of integer; i,j:integer; begin {ввод массива} for i:=1 to 10 do begin writeln('введите ',I,'-й элемент массива -32768 <= X <= 32767'); readln(s[i]); end; {печать входного массива} writeln('элементы входного массива:'); for i:=1 to 10 do write(s[i],' '); writeln; {проверка данных на избыточность} for i:=1 to 10 do begin for j:=i+1 to 10 do if (s[j]=s[i]) then s[j]:=0; end; for i:=1 to 10 do sd[i]:=s[i]; {печать выходного массива} writeln('элементы выходного массива:'); for i:=1 to 10 do write(sd[i],' '); writeln; end. -------------------------------------------------------------------- ТЕСТИРОВАНИЕ элементы входного массива: 23 1 56 78 789 1 4 5 34 78 элементы выходного массива: 23 1 56 78 789 0 4 5 34 0 элементы входного массива: 1 1 1 1 1 1 1 1 1 1 элементы выходного массива: 1 0 0 0 0 0 0 0 0 0 -------------------------------------------------------------------- Блок-схема и листинг программы контроля входного числового массива методом контрольных знаков (вариант 5, рис. 2) \ Исходные данные: А(4) - массив весовых коэффициентов. S(7) - массив 4-хзначных чисел. J - счетчик чисел. I - счетчик цифр каждого числа из массива S(7) и цифр массива весовых коэффициентов А(4). В данной программе используется внутренняя передача данных 2. В блоке 1 осуществляется ввод в оперативную память ПЭВМ исходных массивов А(4) и S(7). Массив N(7) в результате выполнения программы выводится на печать. Он состоит из шестизначных чисел, первые два знака каждого числа отведены под контрольный знак. Остальные 4 знака в числе занимают цифры, скопированные с соответствующего проверяемого числа. В блоке 4 выбирается первое по порядку число из массива Ν(7),т. е. N(1). В блоке 5 происходит заполнение с 3 по 6 позиции числа N(1) цифрами из числа S(1), в этом же блоке обнуляется счетчик контрольной суммы Р. В блоке 6 описывается начало другого цикла со счетчиком I, вложенного в первый цикл со счетчиком J, начинающегося в блоке 4. В блоке 7 переменной D присваивается символьное значение первой позиции числа S(1), выбранного ранее. В этом же блоке происходит внутренняя передача данных: символьная переменная D ставится в соответствие арифметической переменной E (например, символ 2 стал цифрой 2). В блоке 8 вводится промежуточная неиндексированная переменная AN символьного типа, что и массив А(4). Этот же блок также осуществляет внутреннюю передачу данных: символьная переменная AN становится цифровой переменной С. В блоке 9 начинается подсчет контрольной суммы Ρ после чего осуществляется переход к блоку 6. Где происходит выделение из числа уже второй позиции, и далее следуют опять те же операции, описанные выше, до тех пор, пока не будет подсчитана контрольная сумма по всем позициям числа, и не произойдет выход из цикла при достижении счетчика I значения 5. Если I стало по величине больше 4, то осуществляется переход к блоку 10., где происходит деление контрольной суммы Ρ на модуль равный 7. Функция MOD находит остаток от деления двух чисел. В блоке 10 находится операция, выполняющая вычисление контрольного знака. Блок 11 осуществляет проверку контрольного знака на отрицательность и переход к блоку 12, где происходит внутренняя передача числового значения контрольного знака К в символьную переменную R длиной в две позиции. В блоке 13 происходит заполнение первых двух позиций N(1) значением переменной R. После чего переходим к блоху 4, если J > 7, то происходит выход из цикла и на печать выводится нужная текстовая и цифровая информация. 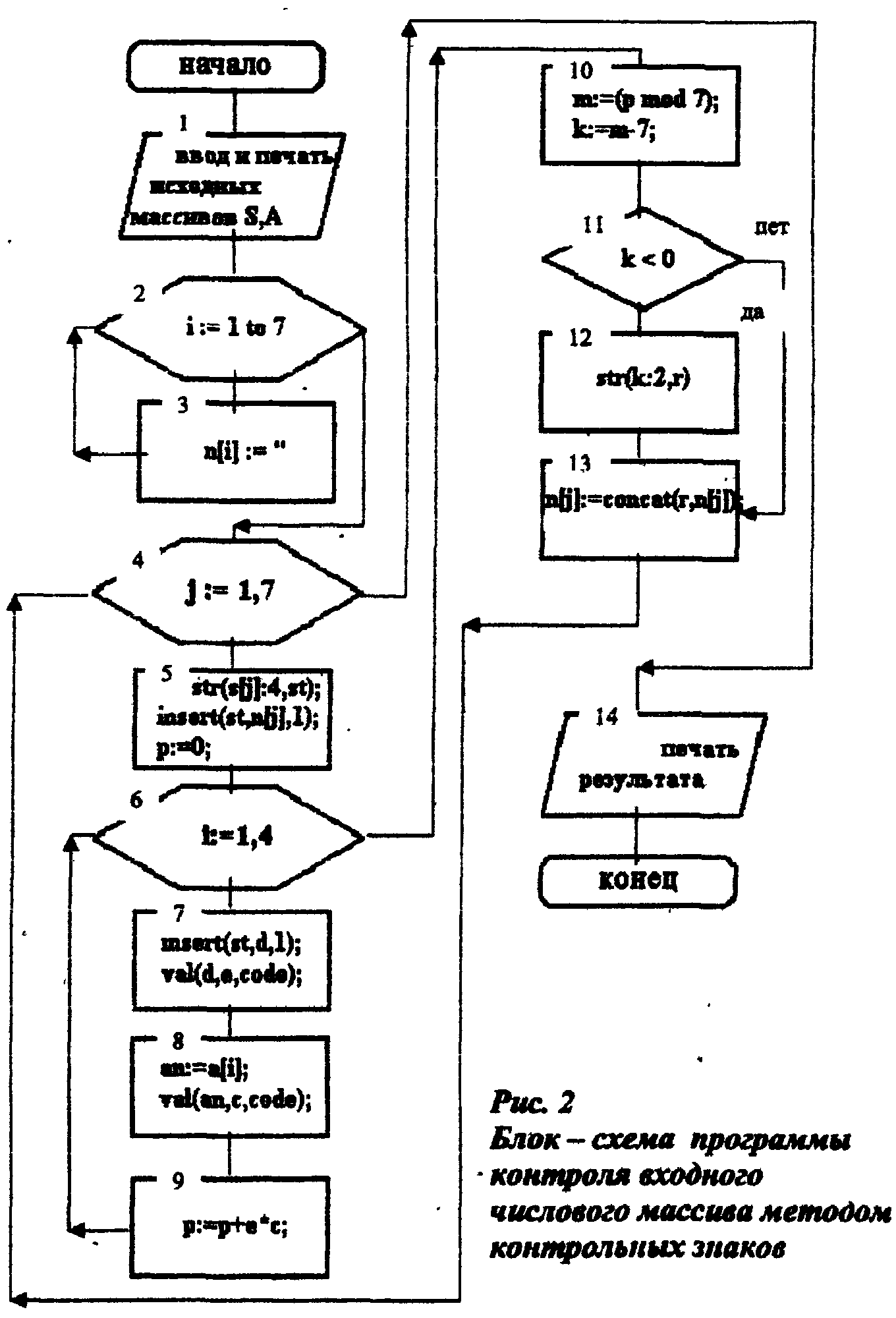 Рис.2. Блок – схема программы контроля входного числового массива методом контрольных знаков. program demo2; var a:array[1..4] of char; s:array[1..7] of integer; n:array[1..7] of string[6]; st:string[4]; d:string[1]; r:string[2]; an:char; i,j,p,e,code,c,m,k:integer; begin {ввод массивов} for i:=1 to 7 do begin writeln('Введите ',i,'-й элемент массива (4-хзначное число):'); readln(s[i]); end; for i:=1 to 4 do begin writeln('Введите ',i,'-й элемент массива 1 <= Х <= 9'); readln(a[i]); end; {печать исходных массивов} writeln('элементы входного массива "s":'); for i:=1 to 7 do write(s[i],' '); writeln; writeln('элементы входного массива "а":'); for i:=1 to 4 do write(a[i],' '); writeln; {контроль входного числового массива} for i:=1 to 7 do n[i]:=''; for j:=1 to 7 do begin str(s[j]:4,st); insert(st,n[j],1); p:=0; for i:=1 to 4 do begin insert(st,d,1); val(d,e,code); an:=a[i]; val(an,c,code); p:=p+e*c; end; m:=(p mod 7); k:=m-7; if (k<0) then str(k:2,r); n[j]:=concat(r,n[j]); end; {печать выходного массива} writeln('элементы выходного массива:'); for i:=1 to 7 do write(n[i],' '); writeln; end. -------------------------------------------------------------------- ТЕСТИРОВАНИЕ элементы входного массива “s”: 1234 2334 4556 6789 5667 3445 5667 элементы выходного массива “a”: 2 4 6 8 выходной массив: -11234 –22334 –44556 –66789 –55667 –33445 -55667 -------------------------------------------------------------------- Блок-схема и описание программы кодирования слов методом перемешивания (вариант 40, рис. 3) Исходные данные: S - входной алфавит, состоящий из 26 латинских букв. SW - новый алфавит, состоящий из 26 русских букв, поставленных в соответствие латинским буквам по порядковому номеру. А - кодируемое слово, записанное латинскими буквами. Блок 1 осуществляет ввод в ПЭВМ исходных массивов S(26), SW(26), слова А. Блок 3 описывает цикл с переменной I. В блоке 4 вводится переменная М, которой присваивается текущее значение I-й позиции входного кодируемого слова. В блоке 5 начинается второй, вложенный по отношению к первому, цикл с переменной J. В блоке 6 происходит поиск выделенной буквы из кодируемого слова в исходном (латинском) алфавите. Если эта буква найдена, переходим к блоку 7, если не найдена, переходим к блоку 5, где осуществляется переход к следующей букве алфавита S(26) и проверка, не вышли ли мы за пределы цикла. Если не вышли, то осуществляется переход к блоку 6 и цикл повторяется снова. Блок 7 описывает присвоение текущей I-й позиции закодированного слова буквы из русского алфавита по порядковому номеру J. Затем происходит переход к следующей букве кодируемого слова (блок 3) и проверка, не закончилось ли оно еще. Если не все ещё буквы закодированы, то после блока 3 из кодируемого слова выделяется следующая буква, запоминается, ищется в исходном алфавите и далее до тех пор, пока все буквы не будут закодированы. После этого на печать выводится интересующая текстовая информация. 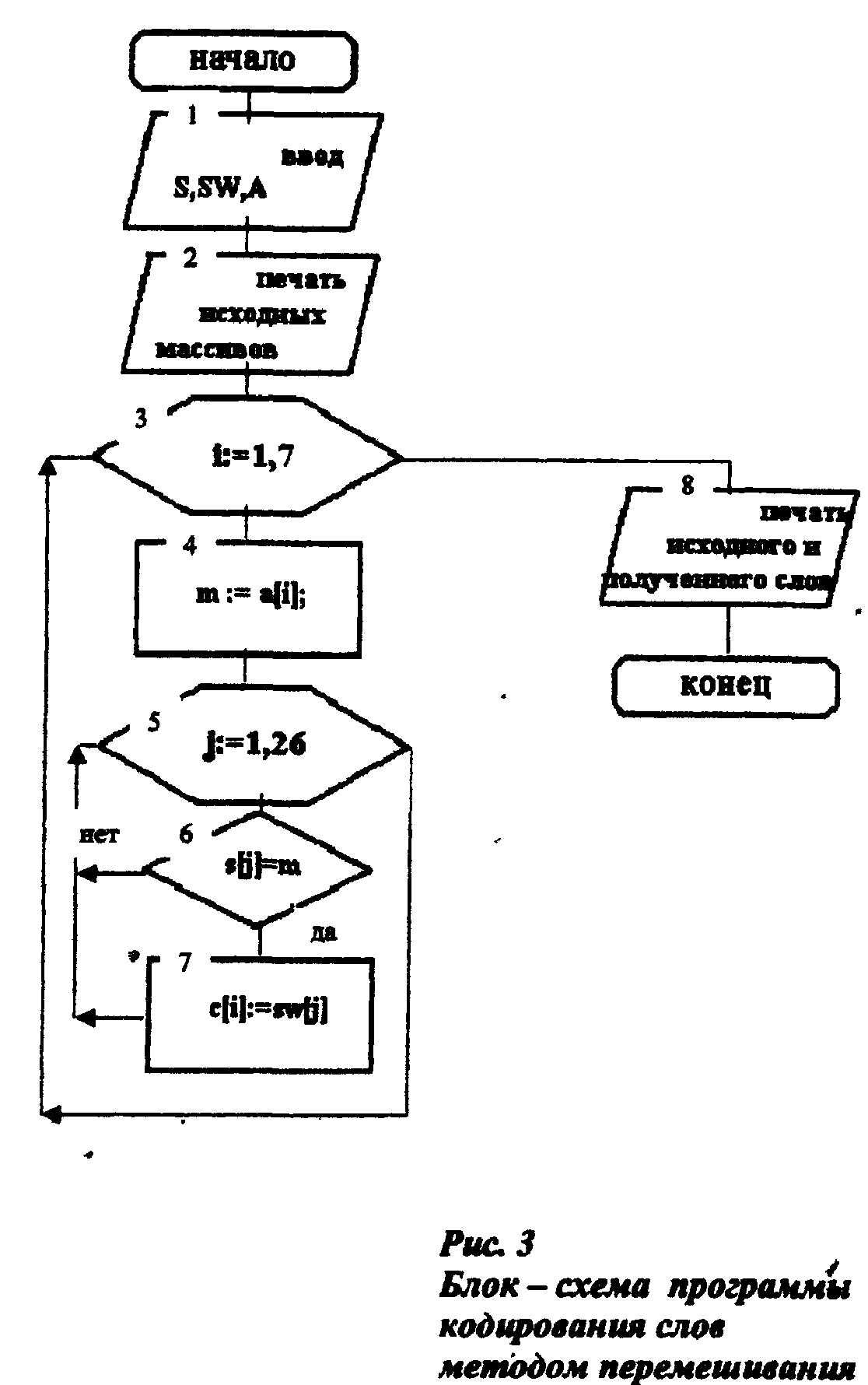 Рис.3. Блок- схема программы кодирования слов методом перемешивания. program demo3; var s:array[1..26] of char; sw:array[1..26] of char; a,c:string[7]; m:char; i,j:integer; begin {ввод массивов} for i:=1 to 26 do begin writeln('введите ',i,'-й элемент массива "s":'); readln(s[i]); end; for i:=1 to 26 do begin writeln('введите ',i,'-й элемент массива "sw":'); readln(sw[i]); end; writeln('введите кодируемое латинское слово (7-мь букв):'); readln(a); {печать исходных массивов} writeln('элементы входного массива "s":'); for i:=1 to 26 do write(s[i],' '); writeln; writeln('элементы входного массива "sw":'); for i:=1 to 26 do write(sw[i],' '); writeln; {кодирование} for i:=1 to 7 do begin m:=a[i]; for j:=1 to 26 do if (s[j]=m) then c[i]:=sw[j]; end; {печать исходного и полученного слова} writeln('кодируемое слово: ',a); write('закодированное слово: '); for i:=1 to 7 do write(c[i]); writeln; end. -------------------------------------------------------------------- ТЕСТИРОВАНИЕ элементы входного массива “s”: a b c d e f g h I j k l m n o p q r s t u v w x y z элементы входного массива “sw”: а б ц д е ф г х и й к л м н о п ж р с т у в ю х э я кодируемое слово: gallery закодированное слово: галлерэ -------------------------------------------------------------------- ЛАБОРАТОРНАЯ РАБОТА № 6 Тема: «Информационный поиск» ЦЕЛЬ РАБОТЫ: изучение видов информационного пояска в массивах документов, заиндексированных с помощью различных информационно-поисковых языков. 1. Сущность информационного поиска Информационный поиск (ИП) - это поиск документов, свдений о них или фактов, соответствующих информационному запросу, для осуществления ИП разрабатывается специальный информационно-поисковый язык (ИПЯ). Поисковым образом запроса (ПОЗ) называется запрос, поступающий в информационно-поисковую систему. ПОЗ - это текст, выражающий на ИПЯ содержание информационного запроса. Поисковые образ документа (ПОД) - это текст выражающий на ИПЯ основное содержание документа, используемого для ИП. Смысловую характеристику содержания документов в документальных информационно-поисковых системах называют ПОД. Для выражения на ИПЯ содержания информационного запроса и последовательности выполнения логических операций в процессе информационного поиска в ИПС используются поисковые предписания. Сущность ИП заключается в сопоставлении ПОД с поисковым предписанием. Процесс поиска можно разбить на два этапа, которые определяются характером решаемых задач. 1 этап: начинается с поступления поискового образа запроса и заканчивается выдачей адреса документа (например, название статьи с указанием название и номера журнала, в котором она была напечатана). Задачи, решаемые на первом этапе, сводятся к установлению смысловых (семантических) связей между ПОЗ и документом. 2 этап: начинается с поступлением адреса и заканчивается выдачей запрашиваемого документа. Это по существу технический этап, и он не имеет отношения к смысловому содержанию документа. Такое разделение ИП на два этапа отражает лишь крайние случаи. Существуют системы, занимающие промежуточные положения. Немаловажную роль при проведении ИП играет знание информационного массива и особенностей поисковых систем, среда которых трудно отдать предпочтение какой-либо, т.к. каждая из реализуемых действующих ИПС специально разрабатывается для выполнения определенных задач. 2. Основные условия поиска 2.1. Поиск по совпадению Задается единственное значение признака и требуется выделить все записи, у которых ключевой признак имеет это значение. 2.2. Поиск по интервалу В условии поиска, задав числовой интервал a<=q<=b, где а,b-границы интервала. Требуется выделить все записи, значение признаков которых заключены между границами интервала. Поскольку значения ключевого признака изменяются дискретно, то поиск по интервалу можно реализовать как несколько поисковых операций по совпадению. 2.3. Поиск по близости Результат поиска есть запись, для которой (pi - q) минимально среди всех записей, т.е. запись с ближайшим к q значением pi. Вероятность совпадения числовых признаков в нескольких записях принимается малой, т.е. считается, что в результате поиска выделяется одна запись. Если совпадение нескольких признаков все же имеет место, то в соответствии с условием поиска выделяется одна из нескольких записей с совпадающими значениями признака. 2.4. Поиск по арифметическому условию Вводится некоторая функция от значений признаков записей и выделяются записи у которых значения функции равно некоторой константе или попадает в заданный интервал, или удовлетворяет условиям близости константе. 2.5. Поиск по семантическому условию Поиск осуществляется среди признаков с нечисловыми значениями. Это могут быть нетекстовые величины или коды иерархической классификации. Условие совпадения означает равенство заранее заданного двоичного кода текстовой величины со значением соответствующего признака в записях массива. 3.Основные методы поиска 3.1. Поиск по полному массиву Просматриваются ключевые признаки всех записей массивов. Априорные сведения об упорядоченности массива отсутствуют, и нет уверенности, что проверка признаков одной записи окажется достаточной для завершения поиска, поэтому требуется просмотр всех записей. Этот метод практически всегда применяется при небольших массивах, т.к. число сравнения равно числу записей в массиве. 3.2. Последовательный поиск Все записи упорядочены по типу используемого поискового признака. Если данные о размещении записей отсутствуют или же записи хранятся в ЗУ с последовательной выработкой, то требуется просмотр каждой записи, пока не будут найдены нужные. Если будет найдена запись, значение ключа сортировки которой больше значения поискового признака (pi > q), то поиск прекращается. При больших массивах этот метод работает медленно. 3.3. Дихотомический поиск Суть метода состоит в деления интервала [а1,а2] пополам так, что количество записей в полуинтервалах либо равны, либо отличаются на 1: если k целая часть n/2, то поиск закончен, если 3.4. Поиск с непосредственным доступом Точный адрес хотя бы первой затки, значение ключевого признака которой соответствует условию поиска, известен еще до начала поиска. 4.Методы организации информационно-поискового массива Составной частью любой информационно-поисковой системы, предназначенной для хранения, войска и выдачи документов является информационно-поисковый массив (ИПМ). Он может подразделяться на 2 массива - активный и пассивный. Активный массив содержит ПОД либо вместе с самим документом, либо с их макро копиями, либо с библиографическими описаниями и адресами хранения этих документов в пассивном массиве. Под адресами хранения этих документов понимается их расстановочные шифры или их порядковые номера в хранилище. В активном массиве ведется информационный поиск, проверяется условия выполнения критерия выдачи и принимается решение о выдаче или невыдаче каждого документа на данный запрос. Пассивный массив образуют сами документы или их микро копии, если поиск в массиве ведется по адресным шифрам предположительно релевантных документов. Если документальная ИПС имеет лишь активный массив, то она называется одноконтурной, если в ИПС два массива, то - двухконтурная. Предпочтительно иметь двухконтурную схему ИПС. Обычно применяются 2 способа организации активного поиска массива: прямой и инверсный. При прямой организации ИПМ в адресную часть каждой ячейки ЗУ записывается ПОД ,а ее информационную часть составляет оригинал, микро копия или номер хранения этого участка. Поиск документов осуществляется путем поочередного сравнения ПО каждого источника массива с ПОЗ и выдачи технических источников информации, для которой выполняется заданный критерий выдачи. Документы в ИПМ могут быть либо неупорядочены, либо упорядочены по номерам. При инверсном способе организации ИПМ в адресную часть каждой ячейки ЗУ записывается отдельный дескриптор (ключевое слово), а в её информационной части - номера всех источников информации, в поисковые образы входит дескриптор. Дескриптор - это словарная единица ИПЯ, выраженная словом, словосочетательным кодом, является именем класса условной эквивалентности, в которую включены эквивалентные и близкие по смыслу ключевые слова. Для удобства пользования в ИПМ записи дескрипторов располагаются в алфавитном порядке. При этой организации поиск состоит из двух этапов: на первом этапе ЗУ необходимо найти ячейки, содержащие дескрипторы, составляющие ПОД. При этом из информационных частей ячеек должны быть переписаны все содержащиеся в них номера документов. На втором этапе осуществляется выявление в информационном массиве всех номеров документов, которые одновременно содержаться во всех ячейках ЗУ, найденных на первом этапе поиска и в отношении которых выполняются все логические условия, заданные в поисковом предписании. Если номер документа содержится во всех ячейках, то это означает, что в ПОД с таким номером входят все дескрипторы, составляющие ПОЗ и таким образом, этот документ является релевантным. 5.Виды информационно-поискового языка 5.1. Фасетные классификации На основе разработок этих языков лежит теория классификации Т.Ранганата, так называемая "классификация с двоеточием". Он разработал таблицы, построенные на основе какой-либо одной характеристики или аспекта, который в дальнейшем получил название " фасетов". Индексы, отражающие содержание каждого элемента строятся из обозначений, принятых каждой такой таблице, и соединяющиеся друг с другом при помощи двоеточия. Этот метод комбинация индексов был похожей в основу названия системы. В системах фасетных классификаций не ставится задача перечислить все сложные понятия. Такие системы предполагают лишь основные структурные блоки, которые получаются в результате тщательного анализа содержания документов. На основе этого анализа определяются основные категории или фасеты. Порядок следования фасетов в фасетной формуле является строго фиксированным и определяется с учетом спецификации предмета, для которого разрабатывается фасетная классификация. Каждый термин фасета называется фокусом. При построении фасетной классификации следующим этапом, если необходима детализация, является деление фасетов на субфасеты. Затем в классификационной системе терминов используется система шифров (индексов), называемых нотациями и используемых для сокращения терминов, а так же фиксации последовательности классификации. Фасетная классификация не предусматривает необходимость пользоваться только готовыми классами, а дает возможность строить название классов из различных сочетаний фокусов, пропуская в фасетной формуле ненужные фасеты. 5.2. Дескрипторные информационно-поисковые языки При реализации дескрипторных языков в небольших узкоспециализированных фондах могут быть использованы дескрипторные словари без грамматики. Примером этого ИПЯ служит система "Унитерм", основанная на предположении, что смысл документов может быть выражен с полнотой достаточной для поисковых целей, набором слов из текстов, документов. Такие слова в этой системе называются унитермами. Язык системы - это перечень унитермов, характерных для данной области, т.е. специалист, индексирующий данный документ не располагает заранее составленным списком, унитермов. Перевод документов на ИПЯ состоит в том, что индексатор выделяет из текста те слова, которые лучше всего передают смысл документа. Совокупность отобранных унитермов представляет собой ПОД. Запрос на информационное обслуживание поступает в систему в виде перечня унитермов. Практика индексирования по данной системе сводится к вписыванию дополнительных унитермов, которые являются либо синонимами, либо более общими терминами. ПОД содержит унитермы, как имеющиеся в тексте, так и отсутствующие в нем. Улучшению работы системы можно достигнуть путем аналогичного индексирования запросов. Особенностью системы является наличие 2 массивов. Первый информационный состоит из документов, среди которых ведется поиск. Документы этого массива пронумерованы и расставлены по номерам. Второй массив - поисковый. Он состоит из унитермов. 5.3. Семантические коды Семантический код состоит из 3-х частей: семантического множителя, алфавитного индекса и числового суффикса. Семантический множитель - основной элемент смыслового кода - используется для выражения общих понятий и обозначается трехбуквенными комбинациями. Между 1 и 2 буквами оставляется свободное место. Алфавитные индексы обозначаются латинскими буквами и помещаются на свободное место в семантическом множестве. Алфавитные индексы используются для указания отношений к понятиям, выраженным семантическим множителем. Семантический множитель в сочетании с алфавитным индексом является частью смыслового кода и позволяет выразить отношение кодируемого объекта к классу понятий. Для представления конкретного термина в семантический код включается числовой суффикс и индекс. Числовой суффикс - это группа цифр, помещающихся после комбинации "семантический множитель" алфавитный инфикс и указывает на конкретный термин из числа тех, которые могут быть обеспечены этой комбинацией. Если смысловой код, в котором есть числовой индекс, входит в состав более сложного кода, то числовой суффикс превращается в числовой инфикс, отличающийся от суффикса знаком "X". 6.Правила индексирования Одним из основных процессов ввода документов в ИПС и выдачи их по запросу является индексирование. Под индексированием понимается процесс перевода основного содержания документов. Применяются ручные и автоматизированные средства индексирования. Ручное индексирование приводит к однозначному результату: разные исполнители могут по-разному заиндексировать один и тот же документ с помощью одного языка понятий. В связи с этим целесообразно применять автоматизированное индексирование, в основе которого лежит соответствующим образом построенный тезаурус и комплекс программ, обеспечивающих опознание терминов тезауруса в тексте. Основа автоматизированного индексирования-это соответствующим образом построенный тезаурус и комплекс программ обеспечивающих поиск и опознание терминов тезауруса в тексте. Большинство систем, в которых используется автоматическое индексирование, ориентировано на индексирование документов по текстам рефератов или названий статей. Автоматизация процессов индексирования часто сталкивается с рядом трудностей принципиального характера. В связи с этим все еще широко используют ручные методы индексирования. На основе индексация ИПС выдает документы на запрос по определенному предмету. Метод описания документов, основанный на этом принципе называется предметным индексированием. 7.Метод описания документов При этом индексировании под предметным документом или информационным запросом понимают конкретный объект, который рассматривается или упоминается в документе или информационном запросе. Обычно в каждом документе рассматривается не один, а несколько таких объектов. Для выполнения предметного индексирования необходимо установить центральную систему или предмет документа. Центральной темой или предметом документа считаются те, которым посвящен документ, исследования показали, что центральная тема или предмет документа, довольно часто полно отражаются в его заголовке. Однако в специализированных ИПС, предназначенных для обслуживания узкого круга ученых и специалистов, центральной темой или предметом документа можно считать вопрос, интересующий пользователей системы. Для обеспечения единого подхода при индексировании документов для каждого ИПЯ разрабатывается специальная методика классификации, под которой понимается совокупность правил и примеров образования индексов, отражающих существенные особенности документов, подлежащих индексированию в целях быстрого нахождения. Методики классификации принято подразделять на общие и частные. Задачей общих методик является разработка правил и приемов индексирования, вытекающих из особенностей схемы классификации в целом, а также правил и приемов, типичных для всех и большинства разделов рассматриваемой схемы. В частных методиках учитываются случаи, связанные с особенностями классификации, а также типичные случаи принятия классифицируемого решения, характерного для отдельных разделов и подразделов классифицируемой схемы. При фасетной организации процедура индексирования осуществляется так: сначала на естественном языке формируется основное смысловое содержание документа; затем с помощью цепочки фокусов, взятых из фасетов, формируется основное смысловое содержание документа в терминах фасетной классификации. Эти термины должны быть расположены в строго фиксированном порядке. Наконец, словесные выражения понятий заменяются индексами. Такая процедура позволяет создать группы для документов, содержание которых выражается сочетанием нескольких разноаспектных характеристик. Так как фасетная классификация не требует безусловного использования только готовых классов, то в процессе индексирования можно формировать новые классы из различных сочетаний терминов. Метод координатного индексирования и основанные на нем дескрипторные ИПЯ заключается в том, что центральная тема документа или тема информационного запроса выражается в виде перечня слов и словосочетаний естественного языка, обычно являющихся именами простых классов. Такие слова и словосочетания служат как бы координатами. Таким образом, координатное индексирование текста или какого-либо материального объекта путем перечисления ключевых слов или дескрипторов, логическое произведение, которых выражает центральную тему или предмет данного текста, либо же образуют целостную характеристику данного объекта. Перечисление (координацией, логическим умножением) понятий называется операция отыскания в них таких членов, которые являются общими для всех пересекаемых понятий. При форматирование массива ключевых слов выбор слов и словосочетаний, включаемых в основной словарный состав дескрипторного ИПЯ, целесообразно: -иметь минимально возможный объем основного словарного состава дескрипторного ИПЯ; -обеспечить максимально достижимую однозначность слов и выражений ИПЯ; -учитывать особенности терминов отрасли, для которой создается ИПЯ; -иметь возможность на основе дескрипторного ИПЯ строить понятия любых классов; -обеспечить удобное оперирование с лексическими единицами ИПЯ. 8.Классификация основных методов поиска
9.Классификация основных условий поиска
|