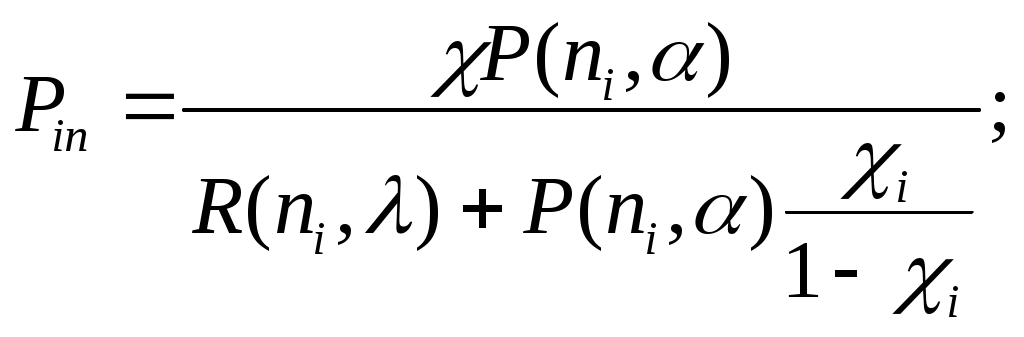Метод_указания к Лабораторным работам (1). Структурную и функциональную классификацию вс
 Скачать 2.03 Mb. Скачать 2.03 Mb.
|

|
Таблица 3 Значение функции –Plog2P
ЛАБОРАТОРНАЯ РАБОТА №4 Тема: «Моделирование информационных потоков» ЦЕЛЬ РАБОТЫ: изучение этапов обработки потоков первичных информационных документов и моделей обработки информации без накопления; без накопления с предварительным отбором документов; последовательной многофазовой обработки документов без накопления в каждой фазе. 1. Математические модели технологического процесса в автоматизированных банках данных. 1.1 Модель обработки информации без накопления. Рассмотрим технологический процесс обработки информации без ее накопления в место обработки. На вход такого технологического процесса подается поток информационных документов (первичных информационных документов, вторичных информационных документов, заявок, словарных терминов и т.п.). На входе этого процесса получают обработанные информационные документы (рис. 1 ). Плотность (интенсивность потока информационных документов на входе будет обозначаться λ(t), плотность потока обработанных информационных документов на выходе - λ0(t). Будем полагать, что в обработке информации принимает участие n статически одинаковых каналов (операторов или технических средств), каждый из которых имеет интенсивность обслуживания  В теории массового обслуживания такую систему обработки информации принято называть системой массового обслуживания с ожиданием и неограниченным числом мест в "очереди". Состояние такой системы будем связывать с числом информационных документов, поступивших на обработку, но еще не обработанных: X0 - в системе обработки информации нет информационных документов, X1 - в системе имеется один информационный документ и он обрабатывается в одном из каналов, "очереди " необработанных документов нет; Xk - в системе имеется k информационных документов (k Xn - в системе имеется n информационных документов и все они обрабатываются в n каналах,"очереди" необработанных документов нет; Xn+r- в системе имеется n+r информационных документов n, из них обрабатываются в n каналах, а r находится в "очереди" на обработку. Многочисленные расчеты показывают, что в отношении этих систем можно сделать допущение о том, что входящий поток информационных документов в канале является пуасоновским. Другими словами, процесс протекающий в такой системе является марковским с непрерывным временем и дискретными состояниями. Второе допущение состоит в том, что рассматривается только стационарный режим работы системы обработки информации. Другими словами, интенсивность потоков необработанных документов и интенсивность их обработки в каждом канале являются постоянными величинами λ=const,=const. Кроме того, временем переходного процесса в системе обработки информации пренебрегаем. Стационарный режим работ системы обработки информации может существовать только при условии: 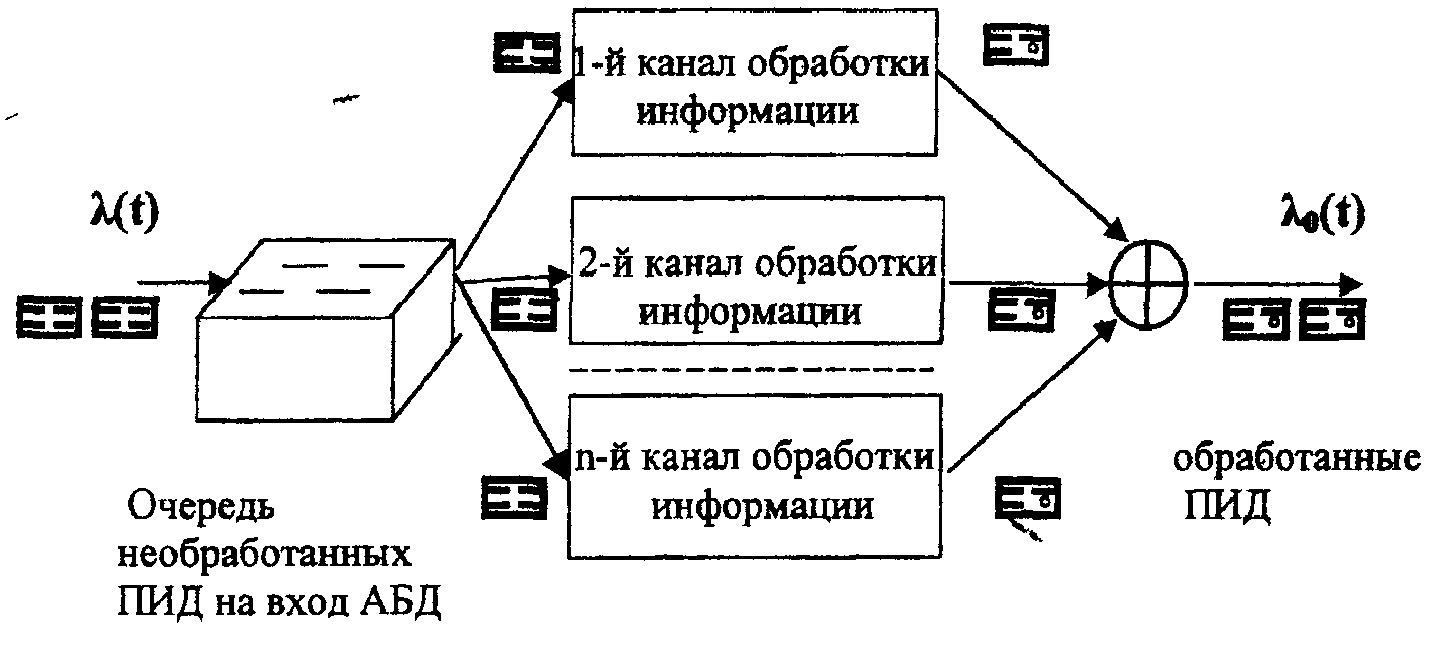 Рис. 2 откуда Формула (1.1) указывает на то очевидное условие, что суммарная производительность (интенсивность) всех каналов обработки информации должна быть больше интенсивности входного потока подлежащих обработке информационных документов. Вероятность того, что в системе обработки информации имеется k информационных документов, все они обрабатываются из "очереди", необработанных документов нет:  , (k=0,1,…,n), , (k=0,1,…,n),где Вероятность того, что в системе обработки информации имеется n+r информационных документов, n из них обрабатываются в n каналах и имеется очередь из r необработанных документов.  (r>=0); (r>=0);Для рассматриваемой системы обработки информации вероятность того, что документ будет обработан, равна единице. Следовательно, плотность потока обработанных документов в установившемся режиме будет равна плотности потока документов, на вход: Среднее число занятых каналов обработки информации (среднее число обрабатываемых документов) в данный момент времени t: Среднее число необработанных документов, находящихся в "очереди" на обработку: Среднее число документов, находящихся в системе обработки информации: Среднее время нахождения документа в "очереди" на обработку: Среднее время нахождения документа на обработке: Среднее время нахождения документа в системе обработки информации: Довольно часто имеет место случай, когда есть всего один канал обслуживания(n=1). В этом случае все формулы значительно упрощаются : 1.2. Модель обработки информации без накопления с предварительным отбором документов. Рассмотрим технологический процесс обработки информации без её накопления в месте обработки, но с предварительным отбором. Сущность отбора состоит в том, что каждый информационный документ поступающий в систему с вероятностью Ρ остается в ней на обработку и с вероятностью (1-Р) - изымается из обработки. При этом предполагается, что сам процесс отбора занимает малый промежуток времени по сравнению со временем ожидания документа в "очереди" и временем его обработки (рис.3). Все формулы модели 1.1 справедливы для модели 1.2 с тем лишь условием, что плотность потока документов подлежащих обработке в системе должна быть равна λp (а не величине λ).  1.3.Модель последовательной (многофазовой) обработки информации без ее накопления в каждой фазе. Рассмотрим технологический процесс, связанный с последовательной обработкой информации в m различных системах. На вход такой многофазовой системы обработки информации подается поток документов λ. Каждая i-я система обработки информации (i=1,2,...,m) характеризуется производительностью канала обработки информации μi и числом каналов ni. Общая схема такой системы показана на рис.4 . 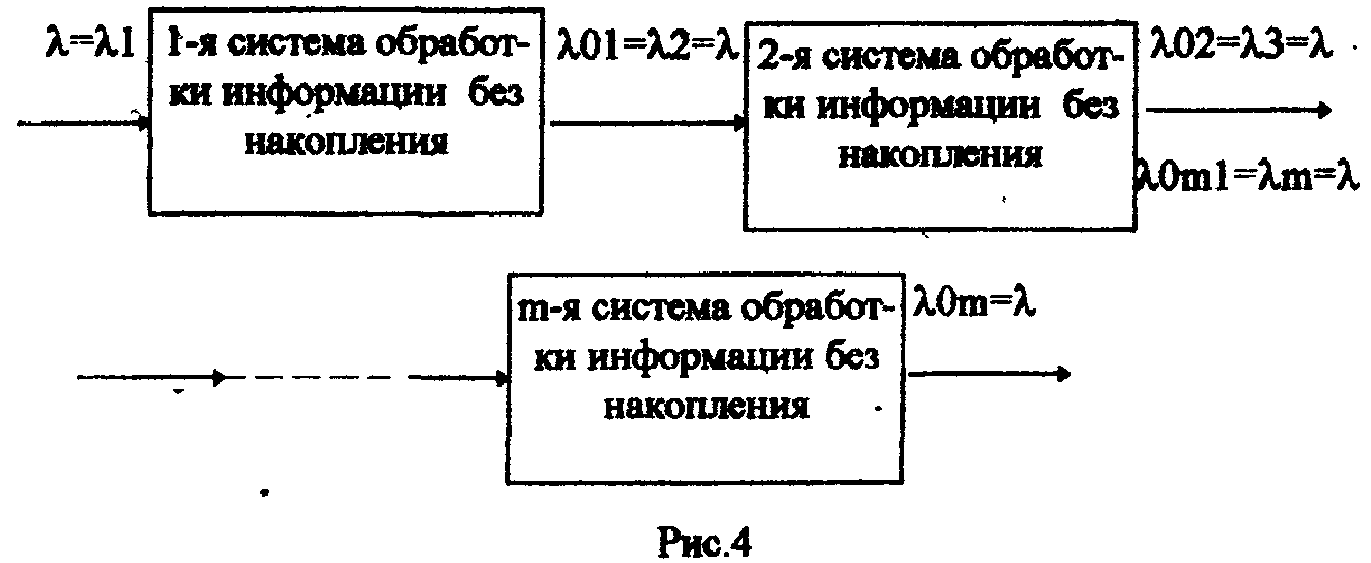 Стационарный режим работы такой многофазовой системы возможен лишь, если: Другими словами, стационарный режим работы возможен лишь, если суммарная производительность работы каждой системы больше интенсивности потока входных документов. Все характеристики i-й системы в стационарном режиме определяются по формулам модели 1.1 , входными параметрами являются величины: при условии выполнения Условие равенства плотности потока на входе и выходе любой системы: следует из того, что вся многофазовая система находится в стационарном режиме. Среднее число документов в такой многофазовой системе обработки будет определятся из выражения: где li - среднее число документов, находящихся в i-й системе обработки документов. Среднее время нахождения документов в многофазовой системе обработки: где ti - среднее время нахождения документа в i-й системе обработки информции. 2.Технология первичной аналитической обработки и индексирования информации 1 Задачей первичной аналитической обработки информации и ее индексирования является такое преобразование первичного информационного документа (ПИД) во вторичной информационный документ, в результате которого из ПИД выбираются заданные, которые должны храниться в базах данных ЭВМ. Если рассматривается АБД (автоматазированный банк данных) документального типа, кода выходной информацией, выдаваемой внешнему потребителю, является документ, то это преобразование сводится к составлению поискового образа первичного документа, т.е. выделение тех признаков, по которым его можно ввести и найти в базах данных, хранимых в ЭВМ. Если рассматривается АБД фактографического типа, когда входной информацией, выдаваемой внешнему потребителю является факт или совокупность нескольких фактов, то рассматриваемое преобразование сводится к составлению ВИД в котором выделены факты из ПИД. Эти факты записываются в ВИД в том виде, в котором они могут быть найдены в базах данных ЭВМ. В АБД смешанного типа вторичные информационные документы содержат как поисковые образы документов, так и описание фактов, а в качестве выходной информации внешнему потребителю могут выдаваться как сами документы, так и факты или совокупность фактов. Процесс индексирования представляет собой выделение наиболее важных компонентов ПИД в виде отдельных понятий и запись этих понятий во вторичном информационном документе с помощью элементов информационных языков. Рассмотрим подробнее процесс первичной аналитической обработки и индексирования на примере АБД научно-технической информации, где он требует значительных трудовых ресурсов. Это связанно в основном составление рефератов, что является очень трудоемкой операцией. Реферат представляет собой основное содержание ПИД изложенное в сжатой форме на естественном языке; в него входят в качестве ядра компоненты информационного набора. В этом состоит единство процессов реферирования и индексирования. На рис.5 показана общая схема первичной аналитической обработки и индексирования АБД научно-технической информации. В некоторых АБД для сокращения общих сроков первичной аналитической обработки ПИД библиографическое описание и реферирование проводят параллельно (рис.6). В этом случае для составления библиографического описания направляется лишь часть ПИД (первые несколько листов), а весь ПИД направляется на реферирование. Библиографическое описание и реферат вместе поступают на индексирование, после чего весь вторичный документ вводится в ЭВМ. Рассмотрим временные характеристики прохождения документов и их количества, накапливаемых на каждой операции, при рассмотрении параллельной технологии обработки информации по схеме, изображенной на рнс.6.   3. Группа учёта и распределения ПИД По формулам модели 1.1 находим: 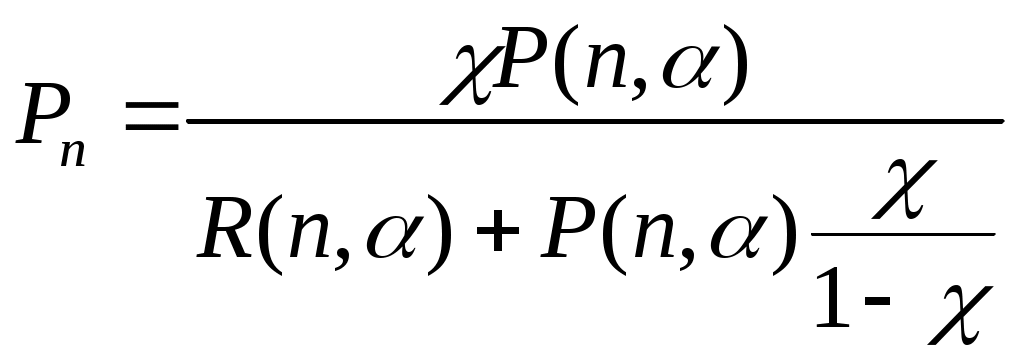 ; ;откуда:  , ,Среднее число ПИД находящихся в "очереди" на обработку в группе учета и распределения, будет: Среднее время ожидания в “очереди”: Среднее время нахождения ПИД в группе учета и распределения будет: тогда: среднее число ПИД находящихся в этой группе будет: 4. Группа библиографического описания Библиографическая работа состоит из двух последовательных операций: составление библиографического описания и его редактирование. Рассмотрим операцию составления библиографического описания (рис.8). Исходные данные: λ =100000 [ПИД/год] (число поступающих ПИД в год) μ = 6000 [ПИД/год] (число обрабатываемых ПИД одним библиографом в год) n = 16 (число библиографов) По формулам модели 1.1 находим: 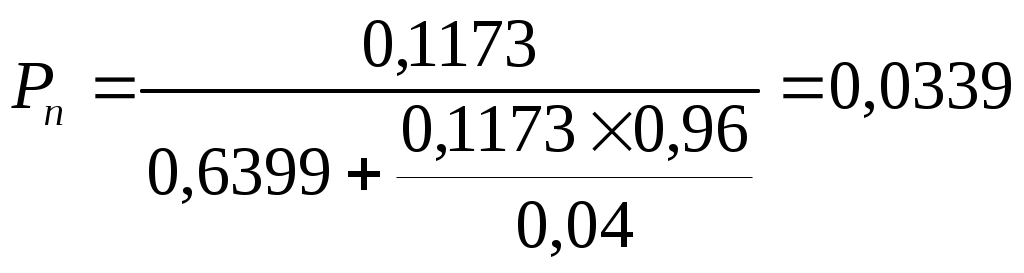 ; ;Таким образом, в группе составления библиографического описания каждый ПИД будет находится в среднем 42,6 мин. ( из них 24,4 мин. будет ожидать в "очереди" на обработку и 18,2 мин. будет обрабатываться) и всего в этой группе будет в среднем 35,6 ПИД из них 20,4 ожидают в "очереди" на обработку и 15,2 обрабатываются библиографами. Рассмотрим операцию редактирования библиографического описания. Исходные данные: λ=100000 [ПИД/год] (число поступающих ПИД в год) μ=22000 [ПИД/год] (число обрабатываемых ПИД одним редактором в год) n=5 (число редакторов библиографического описания). Исходные данные для группы редактирования библиографического описания такие же как и для группы учета и распределения, следовательно, в группе редактирования библиографического описания каждый ПИД будет находится в среднем 21,2 мин. ( из них в "очереди" 16,7 мин.).Всего в этой группе будет находится 17,5 ПИД ( из них в "очереди" -13,9 ПИД). В целом группе библиографического описания каждый ПИД будет находится в среднем 42,6+21,2=63,8 мин., т.е. около часа (из них в "очереди" 24,4+16,7=41,1 мин.), а всего в этой группе будет в среднем 35,6+17,5=53,1 ПИД (из них 20,4+13,9=34,3 в "очереди").   Рис.8 5. Группа реферирования 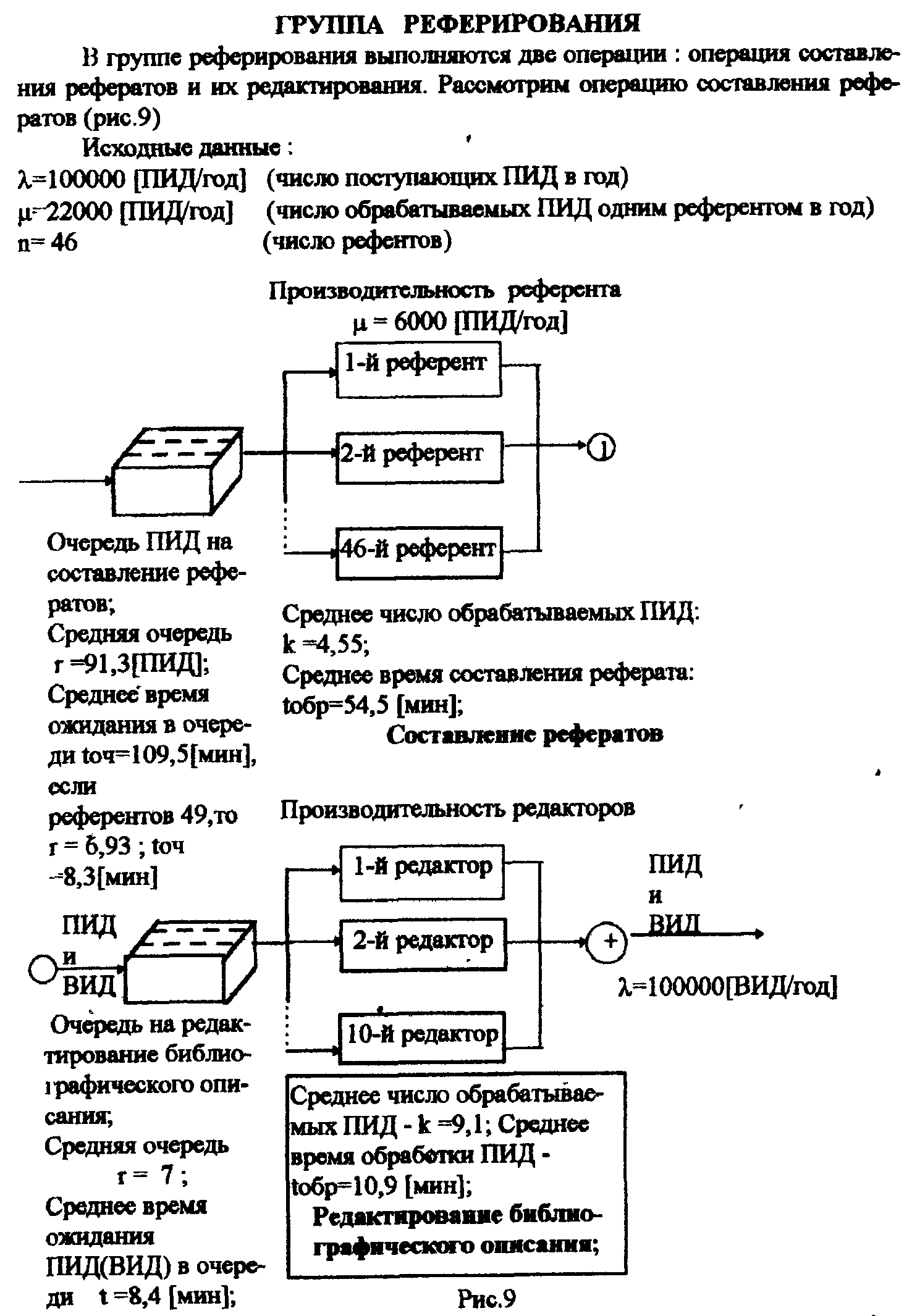 По формулам модели 1.1 находим: Т.к. n>20(>, то вероятность R(n, α) можно рассчитать по приближенной формуле: 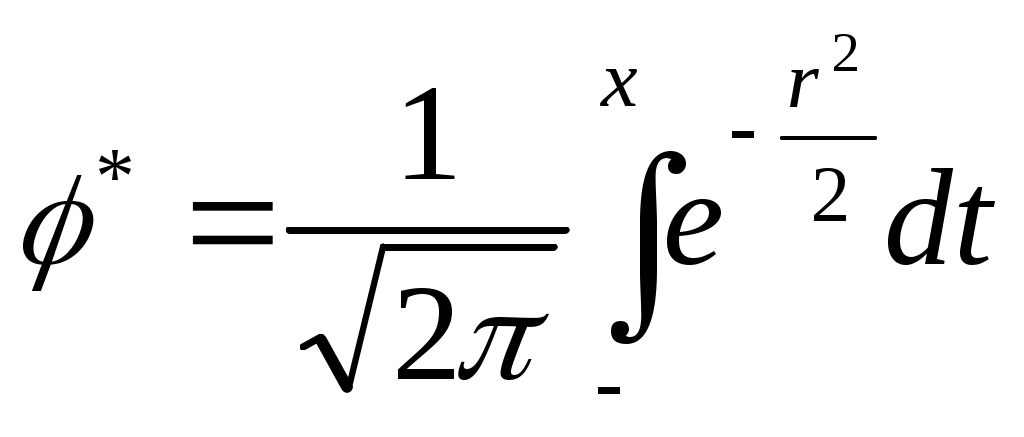 . .Следовательно:  ; ;Но этим данным можно утверждать, что на операции составления реферата, ПИД будет находиться в среднем 164 мин. (из них 109,5 мин. будет ожидать в "очереди" на обработку и 54,5мин. обрабатывается). По формулам модели 1.1 находим: Pn=0,0622; Таким образом, на операции редактирования рефератов ПИД ( и ВИД ) будет находиться в среднем 19,3 мин. (из них будет ожидать в "очереди" на обработку и 10,9 мин. обрабатывается). Всего на этой операции будет в среднем 16,1 ПИД ( из них ожидать обработки в среднем 7 ПИД и обрабатывается 9,1). Первичные и вторичные информационные документы, прошедшие операции составления библиографического описания и реферирования при параллельной обработке информации сливаются на операции индексирования (рис.2). Поэтому важно, чтобы обе эти операции в среднем занимали приблизительно одинаковое время. В нашем случае при наличии 49 рефератов в группе реферирования ПИД будет находиться в среднем 81,6 мин., а в группе библиографического описания - 64,7 мин. Такое расхождение вполне приемлемо. Если же в группе реферирования 46 рефератов, то ПИД будет находиться в этой группе в среднем 182,8 мин., т.е. почти в 3 раза больше, чем в группе библиографического описания, что приведет к нарушению ритмичной работы группы индексирования. Поэтому в группе реферирования нужно иметь 49 рефератов. 6. Группа индексирования Исходные данные · λ= 100000 [ПИД/год] (число поступающих ПИД в год); μ= 4400 [ПИД/год] (число обрабатываемых ПИД одним индексатором в год); n= 24 (число индексаторов). Мы взяли число индексаторов в группе не 23 ( минимально возможное число), а 24 т.к. при n=23 образуется в среднем очень длинная очередь. По формулам модели 1.1 рассчитаем: Таким образом в группе индексирования в среднем будет 38,8 ПИД (из них 16 в "очереди"), которые будут там находится 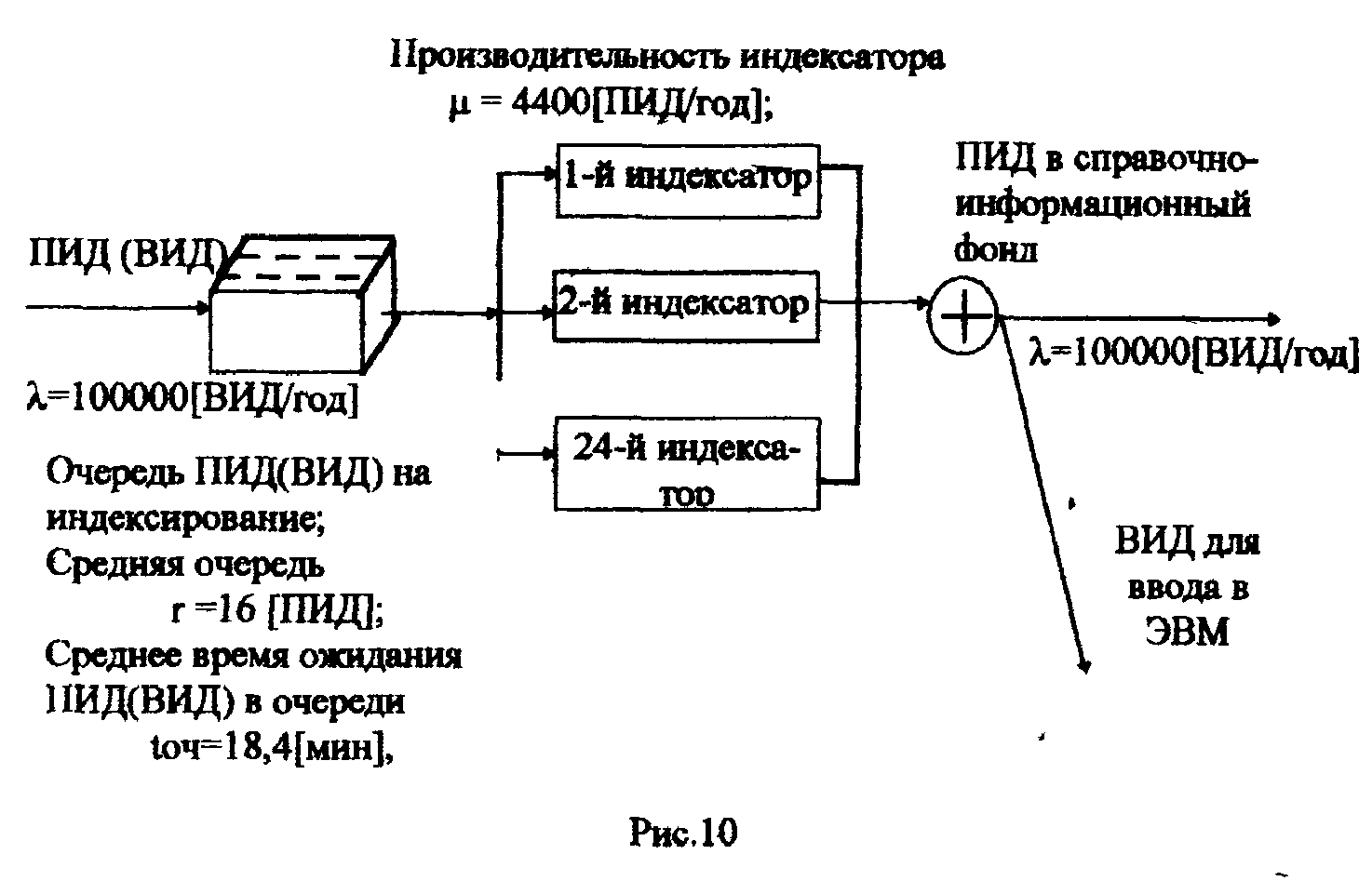 7. Основные формулы для математических моделей по обработке потоков документов для различных систем обслуживания.
Содержание лабораторной работы 1. Составить блок-схему и программу на алгоритмическом языке для решения поставленной задачи согласно варианту. 2. Получить результаты. 3. Провести анализ полученных результатов и сделать выводы. Содержание отчёта Отчет должен содержать: 1. Задание на лабораторную работу в полном объеме. 2. Постановку задачи. 3. Листинг программы. 4. Результаты работы программы. 5. Выводы по полученным результатам. Индивидуальные задания
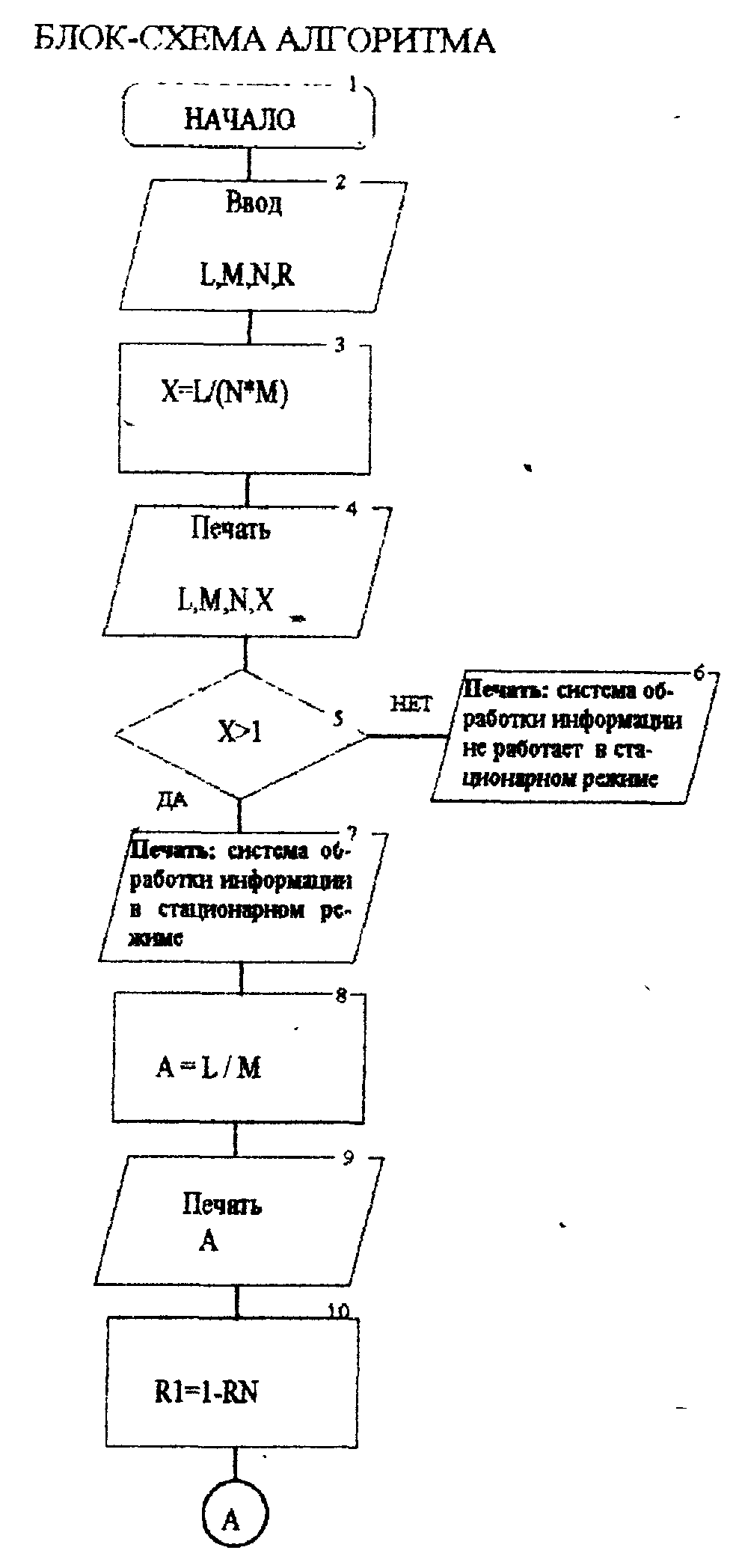 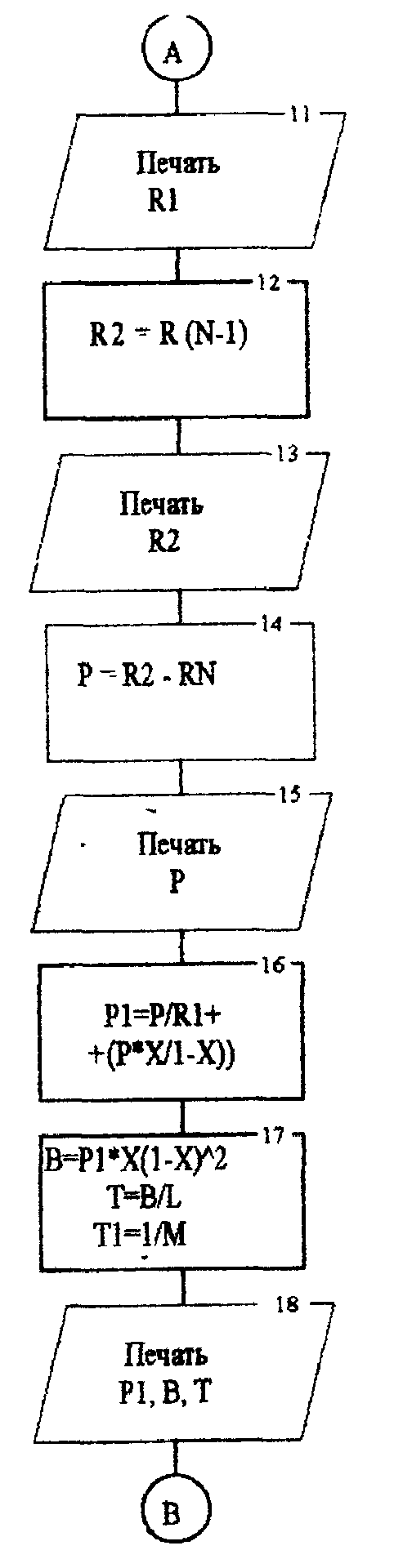 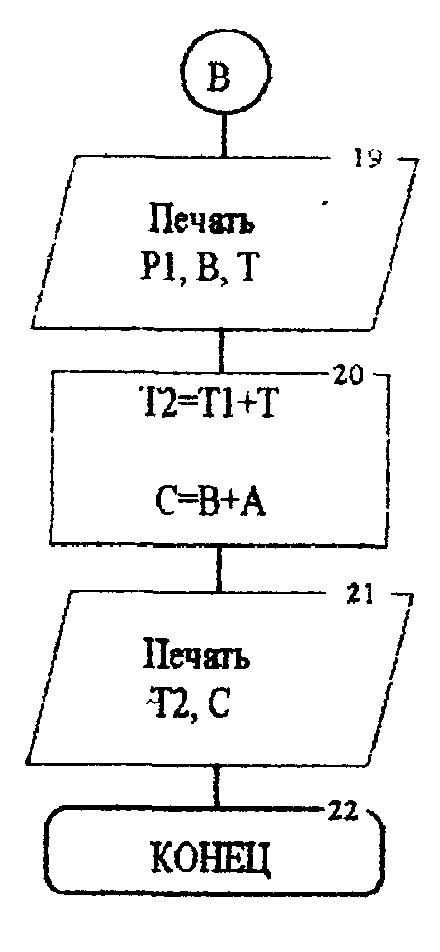 Текст программы program Sys; var l,n,m,rn,r,r1,r2,p:integer; x,x1,b,t,t1,t2,c,a,p1:real; begin read(l,m,n,r); x:=l/(n*m); writeln(l,m,n,x); if x<1 then writeln('Система обработки информации не работает в стационарном режиме') else writeln('Система обработки информации в стационарном режиме'); a:=l/m; writeln(a); r1:=1-r*n; writeln(r1); r2:=r*(n-1); writeln(r2); p:=r2-R*n; writeln(p); p1:=p/r1+(p*x/1-x); b:=p1*x/sqr((1-x)); t1:=1/m; writeln(p1,b,t); t2:=t1+t; c:=b+a; writeln(t2,c); end. ЛАБОРАТОРНАЯ РАБОТА №5 Тема: «Методы повышения достоверности переработки информации» ЦЕЛЬ РАБОТЫ: Изучить методы повышения достоверности переработки информации и один из них реализовать с конкретными данными на ПЭВМ. Основные теоретические положения. Проблема накопления данных является одним из наиболее важных аспектов в информационных системах (ИС) - это связано с объёмом файлов и степенью надёжности, которой эти системы должны обладать. Нужно не только собирать данные, но в первую очередь убедиться в достоверности собранных данных. Работы по проверке и установлению достоверности данных стали одним из главных факторов, определяющих затраты на функционирование ИС. При учёте имеющихся данных, в качестве первой задачи ставится предотвращение значительного дублирования данных на этапе сбора - здесь приходится выполнять большой объём работы по проверке достоверности данных. Эта работа распространяется на оригинальность данных (многие данные избыточны) и на качество данных (варианты 1,2). Нужно иметь возможность оценить достоверность собранной информации. Эта оценка распространяется на сами результаты, которые не должны противоречить ни друг другу, ни ранее введённой информации. Следует также оценивать источник, откуда поступают данные, обрабатываемые в банке данных. Они должны поступать из первичных источников информации, чтобы предотвратить возможные искажения. Система управления банками данных выполняет различные функции. Но одной из наиболее важных в системе управления банками данных является функция защиты. Необходимо обеспечить защиту от неисправностей в вычислительной технике: случайное разрушение файлов, повторный ввод ошибочных изменений (возвращение к первоначальному состоянию файлов) и т. д. Существует также возможность искажения исходной информации при вводе её в банк данных. Для предотвращения таких искажений разработаны различные программные методы защиты. Основой этих методов является способность ПЭВМ реализовать любые числовые и логические процедуры. Защита программ и данных при выполнении внутри машинных операций обычно обеспечивается операционными системами самих ПЭВМ, дополнительные меры защиты при необходимости разрабатываются в процессе проектирования систем. При выполнении этих работ принято выделять три области: ввод данных и запросов, работа с массивами и вывод информации. Программами, воспринимающими данные при их вводе в систему, являются контролирующая и редактирующая программы. Все данные, поступающие в систему, проходят через них. Основная цель программы контроля - обнаружение неправильных и «незаконных» запросов и ошибок. |

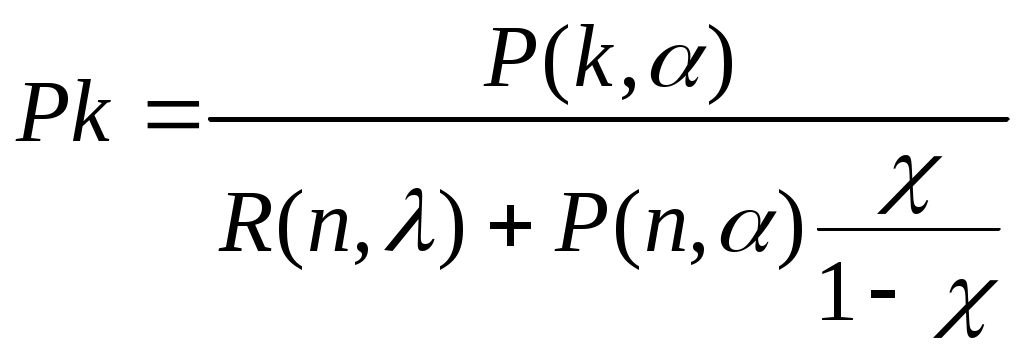 , (k=0,1,…,n),
, (k=0,1,…,n),