ОСНОВЫ ПРОГРАММИРОВАНИЯ_2014. Учебное пособие для 1го курса оглавление Оглавление 2 основы программирования 2 Введение 2
 Скачать 4.81 Mb. Скачать 4.81 Mb.
|

4. МЕТОДЫ ПОСТРОЕНИЯ АЛГОРИТМОВ4.1. Основные понятия структурного программированияНа первых ЭВМ с «тесной» памятью и небольшим быстродействием основным показателем качества программы была ее экономичность по занимаемой памяти и времени счета. Чем программа получалась короче, тем класс программиста считался выше. Такое сокращение программы часто давалось большими усилиями. Иногда программа получалась настолько «хитрой», что могла «перехитрить» самого автора. Возвращаясь через некоторое время к собственной программе, желая что-то изменить, программист мог запутаться в ней, забыв свою «гениальную идею». Так как вероятность выхода из строя сложного технического устройства больше, чем простого, очень сложный алгоритм всегда увеличивает вероятность ошибки в программе. В процессе изготовления программного продукта программист должен пройти определенные этапы.  На стадии проектирования строится алгоритм будущей программы, например, в виде блок-схемы. Кодирование — это составление текста программы на языке программирования. Отладка осуществляется с помощью тестов, т. е. программа выполняется с некоторым заранее продуманным набором исходных данных, для которого известен результат. Чем сложнее программа, тем большее число тестов требуется для ее проверки. Очень «хитрую» программу трудно протестировать исчерпывающим образом. Всегда есть шанс, что какой-то «подводный камень» остался незамеченным. С ростом памяти и быстродействия ЭВМ, с совершенствованием языков программирования и трансляторов с этих языков проблема экономичности программы становится менее острой. Все более важной качественной характеристикой программ становится их простота, наглядность, надежность. С появлением машин третьего поколения эти качества стали основными. В конце 60-х — начале 70-х гг. XX столетия вырабатывается дисциплина, которая получила название структурного программирования. Ее появление и развитие связаны с именами Э. В. Дейкстры, Х.Д.Милса, Д. Е. Кнута и других ученых. Структурное программирование до настоящего времени остается основой технологии программирования. Соблюдение его принципов позволяет программисту быстро научиться писать ясные, безошибочные, надежные программы. В основе структурного программирования лежит теорема, которая была строго доказана в теории программирования. Суть ее в том, что алгоритм для решения любой логической задачи можно составить только из структур «следование, ветвление, цикл». Их называют базовыми алгоритмическими структурами. Из предыдущих разделов учебника вы уже знакомы с этими структурами. По сути дела, мы и раньше во всех рассматриваемых примерах программ придерживались принципов структурного программирования. Следование — это линейная последовательность действий:  Каждый блок может содержать в себе как простую команду, так и сложную структуру, но обязательно должен иметь один вход и один выход. Ветвление — алгоритмическая альтернатива. Управление передается одному из двух блоков в зависимости от истинности или ложности условия. Затем происходит выход на общее продолжение: 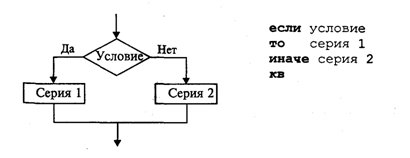 Неполная форма ветвления имеет место, когда на ветви «нет» пусто: 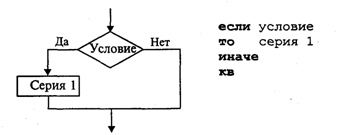 Цикл — повторение некоторой группы действий по условию. Различаются два типа цикла. Первый — цикл с предусловием (цикл-пока): 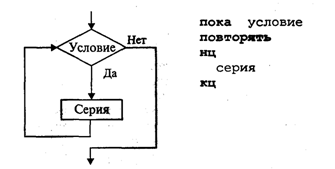 Пока условие истинно, выполняется серия, образующая тело цикла. Второй тип циклической структуры — цикл с постусловием (цикл-до): 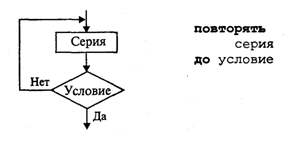 Здесь тело цикла предшествует условию цикла. Тело цикла повторяет свое выполнение, если условие ложно. Повторение кончается, когда условие станет истинным. Теоретически необходимым и достаточным является лишь первый тип цикла — цикл с предусловием. Любой циклический алгоритм можно построить с его помощью. Это более общий вариант цикла, чем цикл-до. В самом деле, тело цикла-до хотя бы один раз обязательно выполнится, так как проверка условия происходит после завершения его выполнения. А для цикла-пока возможен такой вариант, когда тело цикла не выполнится ни разу. Поэтому в любом языке программирования можно было бы ограничиться только циклом-пока Однако в ряде случаев применение цикла-до оказывается более удобным, и поэтому он используется. Иногда в литературе структурное программирование называют программированием без goto. Действительно, при таком подходе нет места безусловному переходу. Неоправданное использование в программах оператора goto лишает ее структурности, а значит, всех связанных с этим положительных свойств: прозрачности и надежности алгоритма. Хотя во всех процедурных языках программирования этот оператор присутствует, однако, придерживаясь структурного подхода, его употребления следует избегать. Сложный алгоритм состоит из соединенных между собой базовых структур. Соединяться эти структуры могут двумя способами: последовательным и вложенным. Если блок, составляющий тело цикла, сам является циклической структурой, то, значит, имеют место вложенные циклы. В свою очередь, внутренний цикл может иметь внутри себя еще один цикл и т.д. В связи с этим вводится представление о глубине вложенности циклов. Точно так же и ветвления могут быть вложенными друг в друга. Структурный подход требует соблюдения стандарта в изображении блок-схем алгоритмов. Чертить их нужно так, как это делалось во всех приведенных примерах. Каждая базовая структура должна иметь один вход и один выход. Нестандартно изображенная блок-схема плохо читается, теряется наглядность алгоритма. Вот несколько примеров структурных блок-схем алгоритмов (рис. 47). 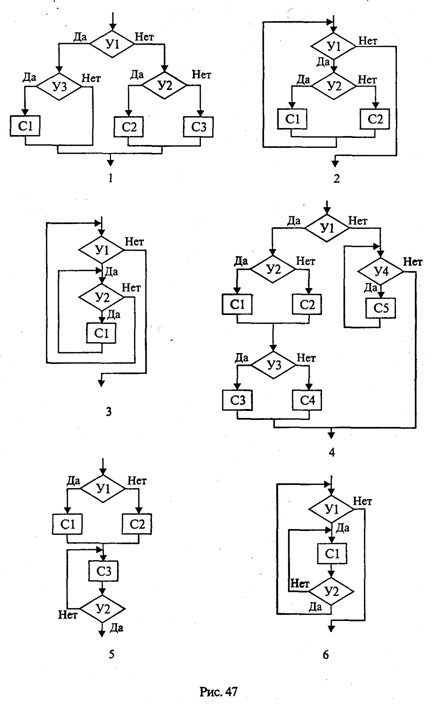 Такие блок-схемы легко читаются. Их структура хорошо воспринимается зрительно. Структуре каждого алгоритма можно дать название. У приведенных на рис. 47 блок-схем следующие названия: 1. Вложенные ветвления. Глубина вложенности равна единице. 2. Цикл с вложенным ветвлением. 3. Вложенные циклы-пока. Глубина вложенности — единица. 4. Ветвление с вложенной последовательностью ветвлений на положительной ветви и с вложенным циклом-пока на отрицательной ветви. 5. Следование ветвления и цикла-до. 6. Вложенные циклы. Внешний — цикл-пока, внутренний — цикл-до. Языки программирования Паскаль и Си называют языками структурного программирования. В них есть все необходимые управляющие конструкции для структурного построения программы. Наглядность такому построению придает структуризация внешнего вида текста программы. Основной используемый для этого прием — сдвиги строк, которые должны подчиняться следующим правилам: • конструкции одного уровня вложенности записываются на одном вертикальном уровне (начинаются с одной позиции в строке); • вложенная конструкция записывается смещенной по строке на несколько позиций вправо относительно внешней для нее конструкции. Для приведенных выше блок-схем структура текста программы на Паскале должна быть следующей: 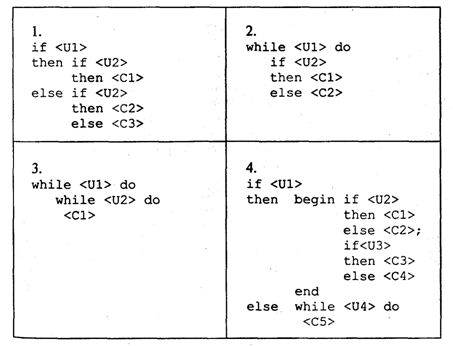 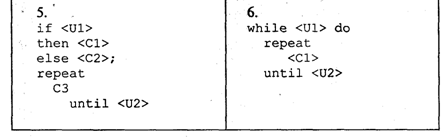 Структурная методика алгоритмизации — это не только форма описания алгоритма, но это еще и способ мышления программиста. Создавая алгоритм, нужно стремиться составлять его из стандартных структур. Если использовать строительную аналогию, можно сказать, что структурная методика построения алгоритма подобна сборке здания из стандартных секций в отличие от складывания по кирпичику. Еще одним важнейшим технологическим приемом структурного программирования является декомпозиция решаемой задачи на подзадачи — более простые с точки зрения программирования части исходной задачи. Алгоритмы решения таких подзадач называются вспомогательными алгоритмами. В связи с этим возможны два пути в построении алгоритма: • «сверху вниз»: сначала строится основной алгоритм, затем вспомогательные алгоритмы; • «снизу вверх»: сначала составляются вспомогательные алгоритмы, затем основной. Первый подход еще называют методом последовательной детализации, второй — сборочным методом. Сборочный метод предполагает накопление и использование библиотек вспомогательных алгоритмов, реализованных в языках программирования в виде подпрограмм, процедур, функций. При последовательной детализации сначала строится основной алгоритм, а затем в него вносятся обращения к вспомогательным алгоритмам первого уровня. После этого составляются вспомогательные алгоритмы первого уровня, в которых могут присутствовать обращения к вспомогательным алгоритмам второго уровня, и т.д. Вспомогательные алгоритмы самого нижнего уровня состоят только из простых команд. Метод последовательной детализации применяется в любом конструировании сложных объектов. Это естественная логическая последовательность мышления конструктора: постепенное углубление в детали. В нашем случае речь идет тоже о конструировании, но только не технических устройств, а алгоритмов. Достаточно сложный алгоритм другим способом построить практически невозможно. Методика последовательной детализации позволяет организовать работу коллектива программистов над сложным проектом. Например, руководитель группы строит основной алгоритм, а разработку вспомогательных алгоритмов и написание соответствующих подпрограмм поручает своим сотрудникам. Участники группы должны лишь договориться об интерфейсе (т. е. взаимосвязи) между разрабатываемыми программными модулями, а внутренняя организация программы — личное дело программиста. Пример разработки программы методом последовательной детализации будет рассмотрен в следующем разделе. 4.2. Метод последовательной детализацииСуть метода была описана выше. Сначала анализируется исходная задача. В ней выделяются подзадачи. Строится иерархия таких подзадач (рис. 48). 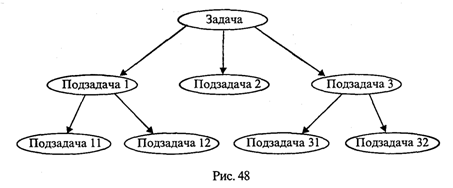 Затем составляются алгоритмы (или программы), начиная с основного алгоритма (основной программы), далее — вспомогательные алгоритмы (подпрограммы) с последовательным углублением уровня, пока не получим алгоритмы, состоящие из простых команд. Вернемся к задаче «Интерпретатор», которая рассматривалась в разд. 3.16. Напомним условие: дана исходная символьная строка, имеющая следующий вид: а b= На месте а и b стоят десятичные цифры; значком обозначен один из знаков операций: +, -, *. Нужно, чтобы машина вычислила это выражение и после знака = вывела результат. Операция деления не рассматривается для того, чтобы иметь дело только с целыми числами. Сформулируем требования к программе Interpretator, которые сделают ее более универсальной, чем вариант, рассмотренный в разд. 3.16: 1. Операнды а и b могут быть многозначными целыми положительными числами в пределах MaxInt. 2. Между элементами строки, а также в начале и в конце могут стоять пробелы. 3. Программа осуществляет синтаксический контроль текста. Ограничимся простейшим вариантом контроля: строка должна состоять только из цифр, знаков операций, знака = и пробелов. 4. Проводится семантический контроль: строка должна быть построена по схеме а b =. Ошибка, если какой-то элемент отсутствует или нарушен их порядок. 5. Осуществляется контроль диапазона значений операндов и результата (не должны выходить за пределы MaxInt). Уже из перечня требований становится ясно, что программа будет непростой. Составлять ее мы будем, используя метод последовательной детализации. Начнем с того, что представим в самом общем виде алгоритм как линейную последовательность этапов решения задачи: 1. Ввод строки. 2. Синтаксический контроль (нет ли недопустимых символов?). 3. Семантический контроль (правильно ли построено выражение?). 4. Выделение операндов. Проверка операндов на допустимый диапазон значений. Перевод в целые числа. 5. Выполнение операции. Проверка результата на допустимый диапазон. 6. Вывод результата. Этапы 2, 3, 4, 5 будем рассматривать как подзадачи первого уровня, назвав их (и будущие подпрограммы) соответственно Sintax, Semantika, Operand, Calc В свою очередь, для их реализации потребуется решение следующих подзадач: пропуск лишних пробелов (Propusk), преобразование символьной цифры в целое число (Cifra). Кроме того, при выделении операндов понадобится распознавать операнд, превышающий максимально допустимое значение (Error). Обобщая все сказанное в схематической форме, получаем некоторую структуру подзадач. Этой структуре будет соответствовать аналогичная структура программных модулей (рис. 49). 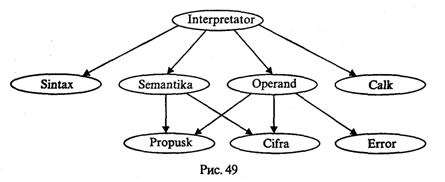 Первый шаг детализации. Сначала наметим все необходимые подпрограммы, указав лишь их заголовки (спецификации). На месте тела подпрограмм запишем поясняющие комментарии (такой вид подпрограммы называется «заглушкой»). Напишем основную часть программы. А потом вернемся к детальному программированию процедур и функций. На первом этапе программирования вместо тела подпрограммы опишем ее назначение в форме комментария. Окончательно объединив тексты подпрограмм с основной программой, получаем рабочий вариант программы Interpretator. Теперь ее можно вводить в компьютер. Отладка и тестирование программы. Никогда нельзя быть уверенным, что одним махом написанная программа будет верной (хотя такое и возможно, но с усложнением программы становится все менее вероятным). До окончательного рабочего состояния программа доводится в процессе отладки. Ошибки могут быть «языковые», могут быть алгоритмические. Первый тип ошибок, как правило, помогает обнаружить компилятор с Паскаля. Это ошибки, связанные с нарушением правил языка программирования. Их еще называют ошибками времени компиляции, ибо обнаруживаются они именно во время компиляции. Алгоритмические ошибки приводят к различным последствиям. Во-первых, могут возникнуть невыполнимые действия. Например, деление на нуль, корень квадратный из отрицательного числа, выход индекса за границы строки и т.п. Это ошибки времени исполнения. Они приводят к прерыванию выполнения программы. Как правило, имеются системные программные средства, помогающие в поиске таких ошибок. Другая ситуация, когда алгоритмические ошибки не приводят к прерыванию выполнения программы. Программа выполняется до конца, получаются какие-то результаты, но они не являются верными. Для окончательной отладки алгоритма и анализа его правильности производится тестирование. Тест — это такой вариант решения задачи, для которого заранее известны результаты. Как правило, один тестовый вариант не доказывает правильность программы. Программист должен придумать систему тестов, построить план тестирования для исчерпывающего испытания всей программы. Мы уже говорили о том, что качественная программа ни в каком варианте не должна завершаться аварийно. Успешное прохождение всех тестов есть необходимое условие правильности программы. Заметим, что при этом оно необязательно является достаточным. Чем сложнее программа, тем труднее построить исчерпывающий план тестирования. Опыт показывает, что даже в «фирменных» программах в процессе эксплуатации обнаруживаются ошибки. Поэтому проблема тестирования программы — очень важная и одновременно очень сложная проблема. 4.3. Рекурсивные методыСуть рекурсивных методов — сведение задачи к самой себе. Вы уже знаете, что в Паскале существует возможность рекурсивного определения функций и процедур. Эта возможность представляет собой способ программной реализации рекурсивных алгоритмов. Однако увидеть рекурсивный путь решения задачи (рекурсивный алгоритм) часто очень непросто. Рассмотрим классическую задачу, известную в литературе под названием «Ханойская башня» (рис. 50). 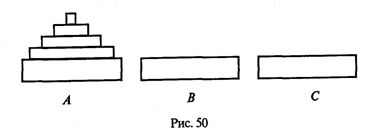 На площадке (назовем ее А) находится пирамида, составленная из дисков уменьшающегося от основания к вершине размера. Эту пирамиду в том же виде требуется переместить на площадку В. При выполнении этой работы необходимо соблюдать следующие ограничения: • перекладывать можно только по одному диску, взятому сверху пирамиды; • класть диск можно либо только на основание площадки, либо на диск большего размера; • в качестве вспомогательной можно использовать площадку С. Название «Ханойская башня» связано с легендой, согласно которой в давние времена монахи одного ханойского храма взялись переместить по этим правилам башню, состоящую из 64 дисков. С завершением их работы наступит конец света. Монахи все еще работают и, надеемся, еще долго будут работать! Нетрудно решить эту задачу для двух дисков. Обозначая перемещения диска, например, с площадки А на В так: А → В, напишем алгоритм для этого случая А→С; А→В; С→В. Всего 3 хода! Для трех дисков алгоритм длиннее: А→В; А→С; В→С; А→В; С→А; С→В; А→В. В этом случае уже требуются 7 ходов. Подсчитать количество ходов (N) для k дисков можно по следующей рекуррентной формуле: N(1) = 1; N(k) = 2х N(k - 1) + 1. Например, N(10) = 1023, N(20) = 104857. А вот сколько перемещений нужно сделать ханойским монахам: N(64) = 18446744073709551615. Попробуйте прочитать это число. Теперь составим программу, по которой машина рассчитает алгоритм работы монахов и выведет его для любого значения п (количества дисков). Пусть на площадке А находятся п дисков. Алгоритм решения задачи будет следующим: 1. Если п = 0, то ничего не делать. 2. Если п > 0, то переместить п — 1 диск на С через В; переместить диск с А на В (А → В) переместить п — 1 диск с С на В через А. При выполнении пункта 2 последовательно будем иметь три состояния (рис. 51). 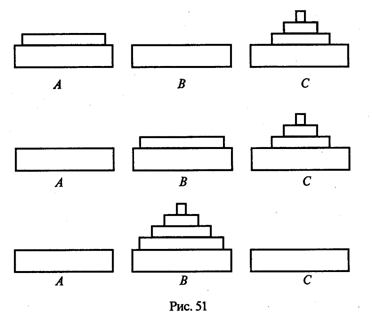 Описание алгоритма имеет явно рекурсивный характер Перемещение n дисков описывается через перемещение п — 1 диска. А где же выход из этой последовательности рекурсивных ссылок алгоритма самого на себя? Он в пункте 1, каким бы ни показалось странным его тривиальное содержание. А теперь построим программу на Паскале. В ней имеется рекурсивная процедура Напоу, выполнение которой заканчивается только при п = 0. При обращении к процедуре используются фактические имена площадок, заданные их номерами: 1, 2, 3. Поэтому на выходе цепочка перемещений будет описываться в таком виде: 1→2 1→3 2→3 и т.д.  Это одна из самых удивительных программ! Попробуйте воcпроизвести ее на машине. Проследите, как изменяется число ходов с ростом п. Для этой цели можете сами добавить в программу счетчик ходов и в конце вывести его значение или печатать ходы с порядковыми номерами. 4.4. Методы перебора в задачах поискаВ данном разделе мы рассмотрим некоторые задачи, связанные с проблемой поиска информации. Это огромный класс задач, достаточно подробно описанный в классической литературе по программированию (см., например, книги Н.Вирта, Д. Кнута и другие). Общий смысл задач поиска сводится к следующему: из данной информации, хранящейся в памяти ЭВМ, выбрать нужные сведения, удовлетворяющие определенным условиям (критериям). Подобные задачи мы уже рассматривали. Например, поиск максимального числа в числовом массиве, поиск нужной записи в файле данных и т. п. Такой поиск осуществляется перебором всех элементов структуры данных и их проверкой на удовлетворение условию поиска. Перебор, при котором просматриваются все элементы структуры, называется полным перебором. Полный перебор является «лобовым» способом поиска и, очевидно, не всегда самым лучшим. Рассмотрим пример. В одномерном массиве X заданы координаты п точек, лежащих на вещественной числовой оси. Точки пронумерованы. Их номера соответствуют последовательности в массиве X. Определить номер первой точки, наиболее удаленной от начала координат. Легко понять, что это знакомая нам задача определения номера наибольшего по модулю элемента массива X. Она решается путем полного перебора следующим образом:  Полный перебор элементов одномерного массива производится с помощью одной циклической структуры. А теперь такая задача: исходные данные — те же, что и в предыдущей; требуется определить пару точек, расстояние между которыми наибольшее. Применяя метод перебора, эту задачу можно решать так: перебрать все пары точек из Ладанных и определить номера тех, расстояние между которыми наибольшее (наибольший модуль разности координат). Такой полный перебор реализуется через два вложенных цикла:  Очевидно, что такое решение задачи нерационально. Здесь каждая пара точек будет просматриваться дважды, например при i = 1, j = 2 и i = 2, j= 1. Для случая п = 100 циклы повторят выполнение 100 х 100 = 10000 раз. Выполнение программы ускорится, если исключить повторения. Исключить также следует и случай совпадения значений i и j. Тогда число повторений цикла будет равно . При n = 100 получается 4950. Для исключения повторений нужно в предыдущей программе изменить начало внутреннего цикла с 1 на i +1. Программа примет вид:  Рассмотренный вариант алгоритма назовем перебором без повторений. Замечание. Конечно, эту задачу можно было решить и другим способом, но в данном случае нас интересовал именно алгоритм, связанный с перебором. В случае точек, расположенных не на прямой, а на плоскости или в пространстве, поиск альтернативы такому алгоритму становится весьма проблематичным. В следующей задаче требуется выбрать все тройки чисел без повторений, сумма которых равна десяти, из массива X. В этом случае алгоритм будет строиться из трех вложенных циклов. Внутренние циклы имеют переменную длину. For I:=l To N Do For J:=I+1 To N Do For K:=J+1 To N Do If X[I]+X[J]+X[K]=10 Then WriteLn(X[I],X[J],X[K]); А теперь представьте, что из массива Х требуется выбрать все группы чисел, сумма которых равна десяти. В группах может быть от 1 до п чисел. В этом случае количество вариантов перебора резко возрастает, а сам алгоритм становится нетривиальным. Казалось бы, ну и что? Машина работает быстро! И все же посчитаем. Число различных групп из п объектов (включая пустую) составляет 2n. При п = 100 это будет 2100 ≈ 1030. Компьютер, работающий со скоростью миллиард операций в секунду, будет осуществлять такой перебор приблизительно 10 лет. Даже исключение перестановочных повторений не сделает такой переборный алгоритм практически осуществимым. Путь практической разрешимости подобных задач состоит в нахождении способов исключения из перебора бесперспективных с точки зрения условия задачи вариантов. Для некоторых задач это удается сделать с помощью алгоритма, описанного в следующем разделе. Перебор с возвратом. Рассмотрим алгоритм перебора с возвратом на примере задачи о прохождении лабиринта (рис. 52). 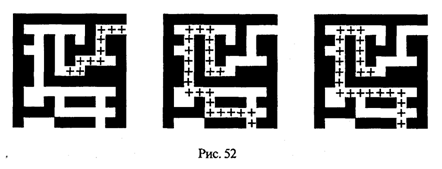 Дан лабиринт, оказавшись внутри которого нужно найти выход наружу. Перемещаться можно только в горизонтальном и вертикальном направлениях. На рисунке показаны все варианты путей выхода из центральной точки лабиринта. Для получения программы решения этой задачи нужно решить две проблемы: • как организовать данные; • как построить алгоритм. Информацию о форме лабиринта будем хранить в квадратной матрице LAB символьного типа размером N x N, где N — нечетное число (чтобы была центральная точка). На профиль лабиринта накладывается сетка так, что в каждой ее ячейке находится либо стена, либо проход. Матрица отражает заполнение сетки: элементы, соответствующие проходу, равны пробелу, а стене — какому-нибудь символу (например, букве М) Путь движения по лабиринту будет отмечаться символами +. Например, приведенный выше рисунок (в середине) соответствует следующему заполнению матрицы LAB:  Исходные данные — профиль лабиринта (исходная матрица LAB без крестиков); результат — все возможные траектории выхода из центральной точки лабиринта (для каждого пути выводится матрица LAB с траекторией, отмеченной крестиками). Алгоритм перебора с возвратом еще называют методом проб. Суть его в следующем: 1. Из каждой очередной точки траектории просматриваются возможные направления движения в одной и той же последовательности; договоримся, что просмотр будет происходить каждый раз против часовой стрелки — справа-сверху-слева-снизу; шаг производится в первую же обнаруженную свободную соседнюю клетку; клетка, в которую сделан шаг, отмечается крестиком. 2. Если из очередной клетки дальше пути нет (тупик), то следует возврат на один шаг назад и просматриваются еще не испробованные пути движения из этой точки; при возвращении назад покинутая клетка отмечается пробелом. 3. Если очередная клетка, в которую сделан шаг, оказалась на краю лабиринта (на выходе), то на печать выводится найденный путь. Программу будем строить методом последовательной детализации. Первый этап детализации:  Процедура GO пытается сделать шаг в клетку с координатами х, у. Если эта клетка оказывается на выходе из лабиринта, то пройденный путь выводится на печать. Если нет, то в соответствии с установленной выше последовательностью делается шаг в соседнюю клетку. Если клетка тупиковая, то выполняется шаг назад. Из сказанного выше следует, что процедура носит рекурсивный характер. Запишем сначала общую схему процедуры без детализации:  Для вывода найденных траекторий составляется процедура PRINTLAB. В окончательном виде программа будет выглядеть так:   Еще один пример красивой программы с использованием рекурсивного определения процедуры (вспомните ханойскую башню!). Схема алгоритма данной программы типична для метода перебора с возвратом. По аналогичным алгоритмам решаются, например, популярные задачи об обходе шахматной доски фигурами или о расстановке фигур на доске так, чтобы они «не били» друг друга; множество задач оптимального выбора (задачи о коммивояжере, об оптимальном строительстве дорог и т.п.). Замечание. Из-за использования массива LAB в качестве параметра-значения в процедуре GO могут возникнуть проблемы с памятью при реализации программы на ЭВМ. В таком случае можно перейти к глобальной передаче массива. 4.5. Эвристические методыПод эвристическими понимаются такие методы, правильность которых строго не доказывается. Они выглядят правдоподобными; кажется, что в большинстве случаев они должны давать верные решения. На уровне экспертной оценки алгоритма часто не удается придумать контрпример, доказывающий ошибочность или неуниверсальность метода. Это, разумеется, не является строгим обоснованием правильности метода. Тем не менее практика использования эвристических методов дает положительные результаты. Эвристические методы разнообразны, поэтому нельзя описать какую-то общую схему их разработки. Чаще всего они применяются совместно с методами перебора для сокращения числа проверяемых вариантов. Некоторые варианты согласно выбранной эвристике считаются заведомо бесперспективными и не проверяются. Такой подход ускоряет работу алгоритма по сравнению с полным перебором. Платой за это является отсутствие гарантии того, что выбрано правильное или наилучшее из всех возможных решение. 4.6. Сложность алгоритмовТрадиционно принято оценивать степень сложности алгоритма по объему используемых им основных ресурсов компьютера: процессорного времени и оперативной памяти. В связи с этим вводятся такие понятия, как временная сложность алгоритма и объемная сложность алгоритма. Параметр временной сложности становится особенно важным для задач, предусматривающих интерактивный режим работы программы, или для задач управления в режиме реального времени. Часто программисту, составляющему программу управления каким-нибудь техническим устройством, приходится искать компромисс между точностью вычислений и временем работы программы. Как правило, повышение точности ведет к увеличению времени. Объемная сложность программы становится критической, когда объем обрабатываемых данных оказывается на пределе объема оперативной памяти ЭВМ. На современных компьютерах острота этой проблемы снижается благодаря как росту объема ОЗУ, так и эффективному использованию многоуровневой системы запоминающих устройств. Программе оказывается доступной очень большая, практически неограниченная область памяти (виртуальная память). Недостаток основной памяти приводит лишь к некоторому замедлению работы из-за обменов с диском. Используются приемы, позволяющие минимизировать потери времени при таком обмене. Это использование кэш-памяти и аппаратного просмотра команд программы на требуемое число ходов вперед, что позволяет заблаговременно переносить с диска в основную память нужные значения. Исходя из сказанного можно заключить, что минимизация емкостной сложности не является первоочередной задачей. Поэтому в дальнейшем мы будем интересоваться в основном временной сложностью алгоритмов. Время выполнения программы пропорционально числу исполняемых операций. Разумеется, в размерных единицах времени (секундах) оно зависит еще и от скорости работы процессора (тактовой частоты). Для того чтобы показатель временной сложности алгоритма был инвариантен относительно технических характеристик компьютера, его измеряют в относительных единицах. Обычно временная сложность оценивается числом выполняемых операций. Как правило, временная сложность алгоритма зависит от исходных данных. Это может быть зависимость как от величины исходных данных, так и от их объема. Если обозначить значение параметра временной сложности алгоритма α символом Tα, а буквой V обозначить некоторый числовой параметр, характеризующий исходные данные, то временную сложность можно представить как функцию Tα(V). Выбор параметра V зависит от решаемой задачи или от вида используемого алгоритма для решения данной задачи. Пример 1. Оценим временную сложность алгоритма вычисления факториала целого положительного числа. Function Factorial(x:Integer): Integer; Var m,i: Integer; Begin m:=l; For i:=2 To x Do m:=ro*i; Factorial:=m End; Подсчитаем общее число операций, выполняемых программой при данном значении x. Один раз выполняется оператор m:=1; тело цикла (в котором две операции: умножение и присваивание) выполняется х — 1 раз; один раз выполняется присваивание Factorial:=m. Если каждую из операций принять за единицу сложности, то временная сложность всего алгоритма будет 1 + 2 (x — 1) + 1 = 2х Отсюда понятно, что в качестве параметра следует принять значение х. Функция временной сложности получилась следующей: Tα(V)=2V. В этом случае можно сказать, что временная сложность зависит линейно от параметра данных — величины аргумента функции факториал. Пример 2. Вычисление скалярного произведения двух векторов А = (a1, a2, …, ak), В = (b1, b2, …, bk). АВ:=0; For i:=l To k Do AB:=AB+A[i]*B[i]; В этой задаче объем входных данных п = 2k. Количество выполняемых операций 1 + 3k = 1 + 3(n/2). Здесь можно взять V= k= п/2. Зависимости сложности алгоритма от значений элементов векторов А и В нет. Как и в предыдущем примере, здесь можно говорить о линейной зависимости временной сложности от параметра данных. С параметром временной сложности алгоритма обычно связывают две теоретические проблемы. Первая состоит в поиске ответа на вопрос: до какого предела значения временной сложности можно дойти, совершенствуя алгоритм решения задачи? Этот предел зависит от самой задачи и, следовательно, является ее собственной характеристикой. Вторая проблема связана с классификацией алгоритмов по временной сложности. Функция Tα(V) обычно растет с ростом V. Как быстро она растет? Существуют алгоритмы с линейной зависимостью Тα от V (как это было в рассмотренных нами примерах), с квадратичной зависимостью и с зависимостью более высоких степеней. Такие алгоритмы называются полиномиальными. А существуют алгоритмы, сложность которых растет быстрее любого полинома. Проблема, которую часто решают теоретики — исследователи алгоритмов, заключается в следующем вопросе: возможен ли для данной задачи полиномиальный алгоритм? 4.7. Методы сортировки данныхСуществует традиционное деление алгоритмов на численные и нечисленные. Численные алгоритмы предназначены для математических расчетов: вычисления по формулам, решения уравнений, статистической обработки данных и т.п. В таких алгоритмах основным видом обрабатываемых данных являются числа. Нечиcленные алгоритмы имеют дело с самыми разнообразными видами данных: символьной, графической, мультимедийной информацией. К этой категории относятся многие алгоритмы системного программирования (трансляторы, операционные системы), систем управления базами данных, сетевого программного обеспечения и т.д. Для программных продуктов второй категории наиболее часто используемыми являются алгоритмы сортировки данных — упорядочения информации по некоторому признаку. От эффективности, прежде всего скорости, их выполнения во многом зависит эффективность работы всей программы. Различают алгоритмы внутренней сортировки — во внутренней памяти и алгоритмы внешней сортировки — сортировки файлов. Далее мы будем рассматривать только внутреннюю сортировку. Как правило, сортируемые данные располагаются в массивах. В простейшем случае это числовые массивы. Однако для нечисленных алгоритмов более характерна ситуация, когда сортируется массив записей (в терминологии Паскаля) или массив структур (в терминологии Си). Поле, по значению которого производится сортировка, называется ключом сортировки. Обычно оно имеет числовой тип. Например, массив сортируемых записей содержит два поля: наименование товара и количество товара на складе. В программе на Паскале он описан так:  Сортировка производится либо по возрастанию, либо по убыванию значения ключа A[i].key. Во всех дальнейших примерах программ предполагается, что приведенные выше описания в программе присутствуют глобально и область их действия распространяется на процедуры сортировки. Хотя все примеры приводятся на Паскале, но по тому же принципу можно разработать функции сортировки на Си/Си++. Алгоритм сортировки «методом пузырька» рассматривался в разделе 3.17. Здесь мы обсудим два алгоритма: сортировку простым включением и быструю сортировку. Сортировка простым включением. Предположим, что на некотором этапе работы алгоритма левая часть массива с 1-го по (i — 1)-й элемент включительно является отсортированной, а правая часть с i-го по n-й элемент остается такой, какой она была в первоначальном, неотсортированном массиве. Очередной шаг алгоритма заключается в расширении левой части на один элемент и, соответственно, сокращении правой части. Для этого берется первый элемент правой части (с индексом i) и вставляется на подходящее ему место в левую часть так, чтобы упорядоченность левой части сохранилась. Процесс начинается с левой части, состоящей из одного элемента А[1], а заканчивается, когда правая часть становится пустой.  Теперь оценим сложность алгоритма сортировки простым включением. Очевидно, что временная сложность зависит как от размера сортируемого массива, так и от его исходного состояния в смысле упорядоченности элементов. Временная сложность будет минимальной, если исходный массив уже отсортирован в нужном порядке значений ключа (в данном случае — по возрастанию). Максимальное значение сложности будет соответствовать противоположной упорядоченности исходного массива, т.е. упорядоченности исходного массива по убыванию значений ключа. Обычно для алгоритмов сортировки временная сложность оценивается количеством пересылок элементов. Оценим величину минимальной временной сложности алгоритма. Если массив уже отсортирован, то тело цикла while не будет выполняться ни разу. Выполнение процедуры сведется к работе следующего цикла:  Поскольку тело цикла for исполняется n — 1 раз, то число пересылок элементов массива Мmin = 2(п - 1), а число сравнений ключей равно Сmin = n - 1. Сложность алгоритма будет максимальной, если исходный массив упорядочен по убыванию. Тогда каждый элемент А[i] будет «прогоняться» к началу массива, т.е. устанавливаться в первую позицию. Цикл while выполнится 1 раз при i = 2, 2 раза при i = 3 и т. д., п — 1 раз при i = п. Таким образом, общее число пересылок записей равно: Более подходящей для реальной ситуации является средняя оценка сложности. Для ее вычисления надо предположить, что все элементы исходного массива — случайные числа и их значения никак не связаны с их номерами. В таком случае результат очередной проверки условия x. key Разумно допустить, что среднее число выполнений цикла While для каждого конкретного значения i равно i/2, т. е. в среднем каждый раз приходится просматривать половину последовательности до тех пор, пока не найдется подходящее место для очередного элемента Тогда формула для среднего числа пересылок (средняя оценка сложности) будет следующей: Как максимальная, так и средняя оценка сложности алгоритма квадратична (является полиномом второй степени) по параметру п — размеру сортируемого массива. Алгоритм быстрой сортировки. Этот алгоритм был разработан Э. Хоаром. В алгоритме быстрой сортировки используются три идеи: • разделение сортируемого массива на 2 части, левую и правую; • взаимное упорядочение двух частей (подмассивов) так, чтобы все элементы левой части не превосходили элементов правой части; • рекурсия, при которой подмассив упорядочивается точно таким же способом, как и весь массив. Для разделения массива на две части нужно выбрать некоторое «барьерное» значение ключа. Это значение должно удовлетворять единственному условию: лежать в диапазоне значений для данного массива (т.е. между минимальной и максимальной величиной). За «барьер» можно выбрать значение ключа любого элемента массива, например первого, или последнего, или находящегося в середине. Далее нужно сделать так, чтобы в левом подмассиве оказались все элементы с ключом, меньшим барьера, а в правом — с большим: Затем, просматривая массив слева направо, необходимо найти позицию первого элемента с ключом, большим барьера, а просматривая справа налево — найти первый элемент с ключом, меньшим барьера. Следует поменять эти значения, затем продолжить встречное движение до следующей пары элементов, предназначенных для обмена. Необходимо повторять эту процедуру, пока индексы левого и правого просмотров не совпадут. Место совпадения станет границей между двумя взаимно упорядоченными подмассивами. Далее алгоритм рекурсивно применяется к каждому из подмассивов (левому и правому). В конечном счете приходим к совокупности из п взаимно упорядоченных одноэлементных массивов, которые делить дальше невозможно. Эта совокупность образует один полностью упорядоченный массив. Сортировка завершена!  Сложность алгоритма быстрой сортировки. Исследование временной сложности алгоритма быстрой сортировки является очень трудоемкой задачей, и поэтому мы здесь приводить его не будем. Рассмотрим лишь окончательный результат этого анализа. Временная сложность T как функция от п — размера массива — по порядку величины выражается следующей формулой: Т(п) = 0 (n 1n (n)). Здесь использовано принятое в математике обозначение: O(х) обозначает величину порядка х. Следовательно, временная сложность алгоритма быстрой сортировки есть величина порядка п 1n(n). Эта величина для целых положительных п меньше, чем п2 (вспомним, что алгоритм сортировки простым включением имеет сложность порядка n2). И чем больше значение п, тем эта разница существеннее. Например: Приложение 1. Турбо Паскаль. Модуль CRTТаблица П1.1. Константы режимов работы  Таблица П1.2. Константы цветов 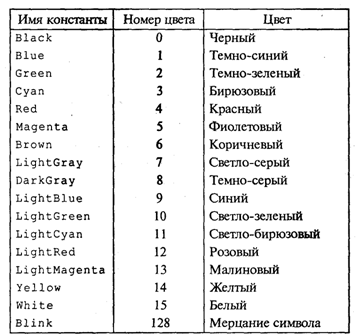 Таблица П1.3. Процедуры и функции 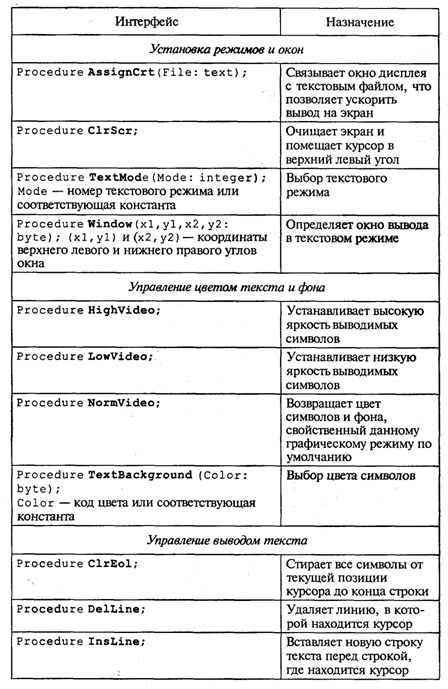 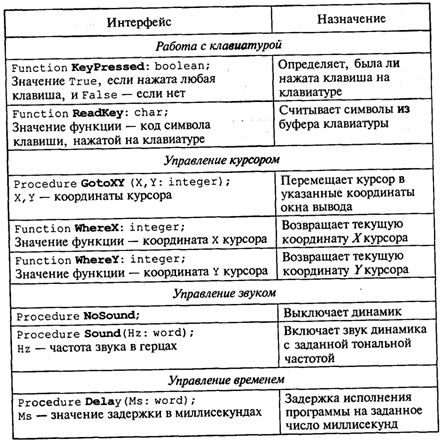 Приложение 2. Турбо Паскаль. Модуль GRAPHТаблица П2.1. Коды драйверов графических устройств  Таблица П2.2. Константы графических режимов 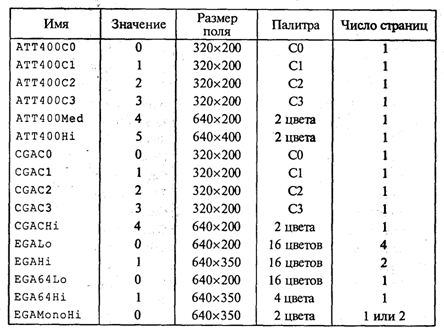 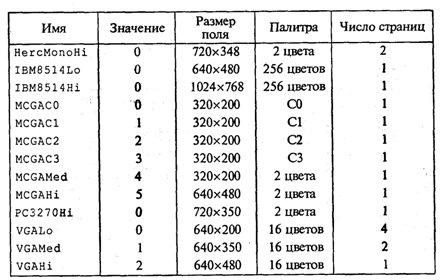 Примечание. Палитра С0 включает в себя следующие цвета: светло-зеленый, розовый и желтый; палитра С1 — светло-голубой, светло-фиолетовый и белый; палитра С2 — зеленый, красный и коричневый; палитра С3 — голубой, фиолетовый и светло-серый. Таблица П2.3. Коды цветов 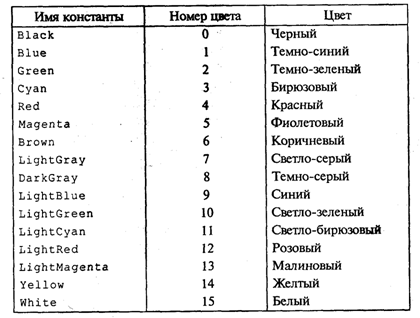 Таблица П2.4. Коды линий  Таблица П2.5. Константы орнамента заполнения (для процедуры SetFillStyle) 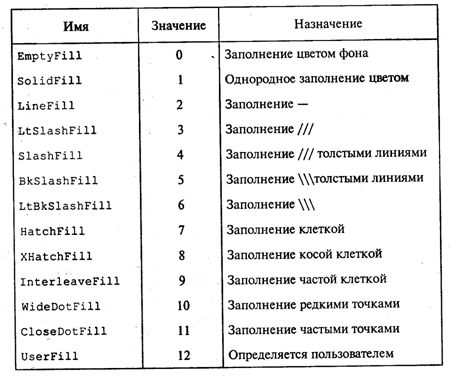 Таблица П2.6. Процедуры и функции 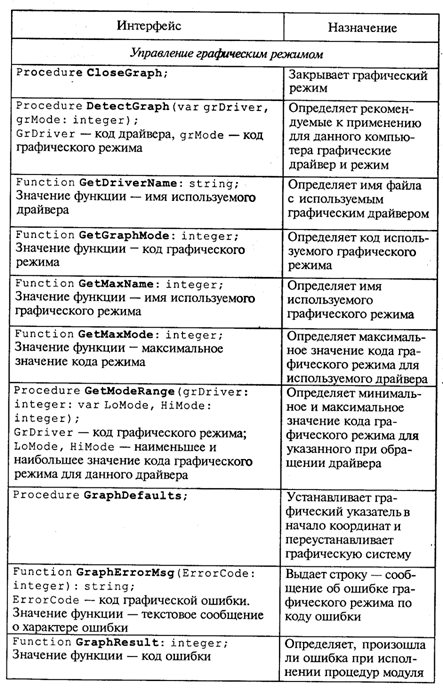 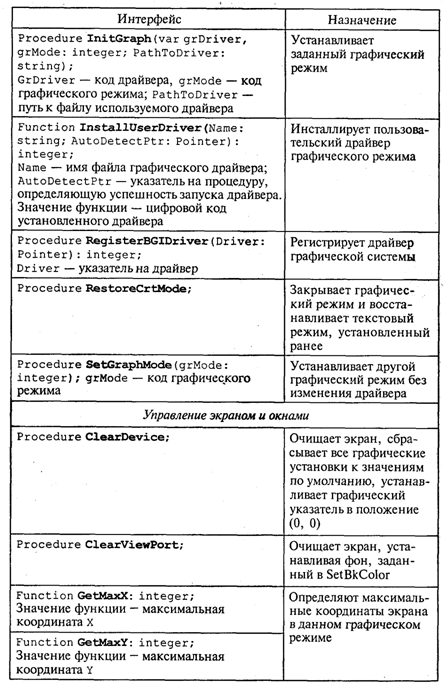 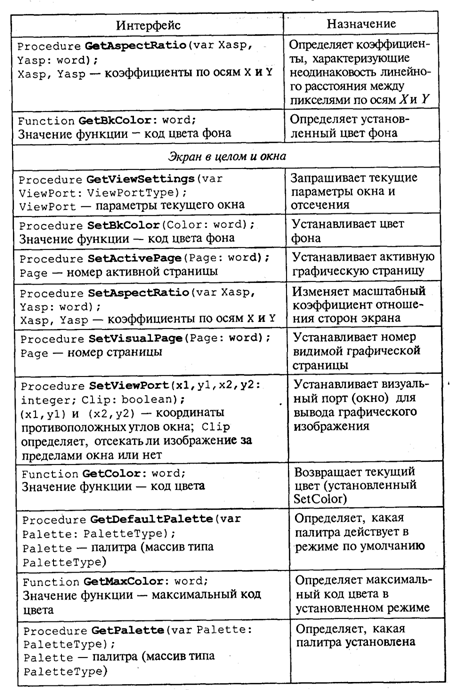 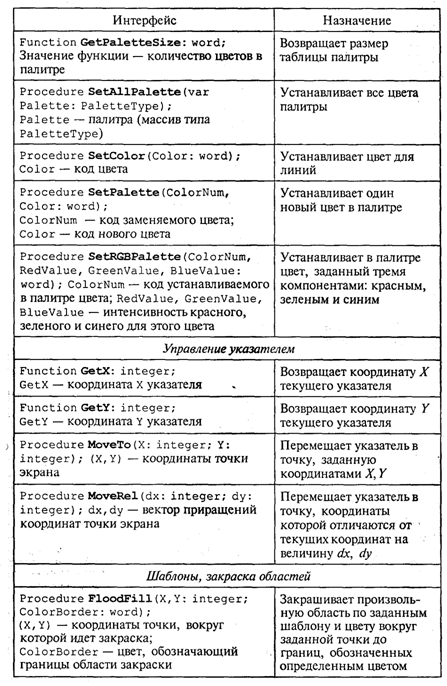 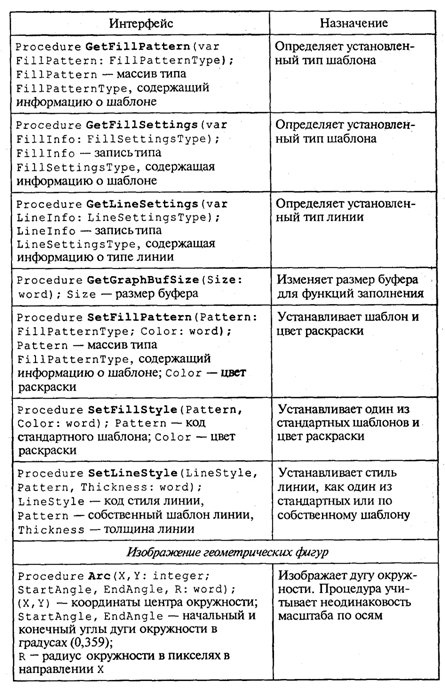 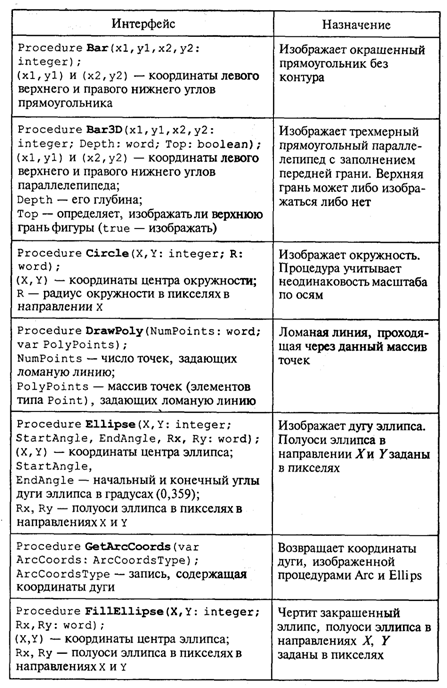 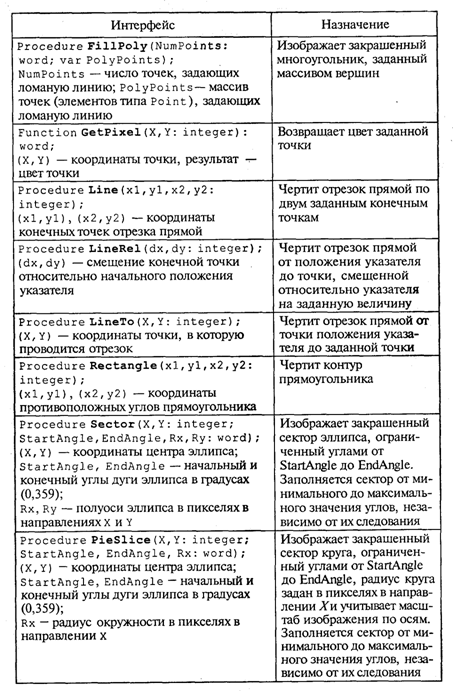 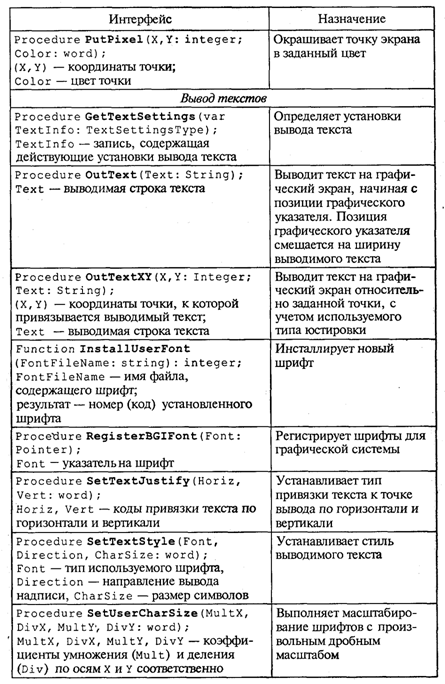 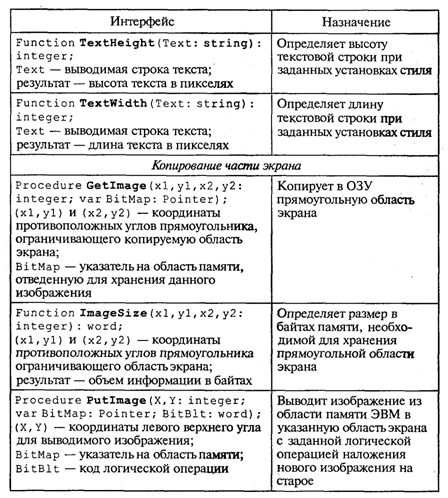 СПИСОК ЛИТЕРАТУРЫ
|