Сергеев - Метрология. В. Г. Фирстов Кандидат физикоматематических наук
 Скачать 4.38 Mb. Скачать 4.38 Mb.
|

Глава 8. ОБРАБОТКА РЕЗУЛЬТАТОВИЗМЕРЕНИЙ8.1. Прямые многократные измерения8.1,1. Равноточные измеренияПрямые многократные измерения делятся на равно- и неравноточные. Теоретические основы и методика объединения результатов неравноточных измерений подробно рассмотрены в [3]. Равно точными называются измерения, которые проводятся средствами измерений одинаковой точности по одной и той лее методике при неизменных внешних условиях. При равноточных измерениях СКО результатов всех рядов измерений равны между собой. Перед проведением обработки результатов измерений необходимо удостовериться в том, что данные из обрабатываемой выборки статистически подконтрольны, группируются вокруг одного и того же центра и имеют одинаковую дисперсию. Устойчивость изменений часто оценивают интуитивно на основе длительных наблюдений. Однако существуют математические методы решения поставленной задачи — так называемые методы проверки однородности [3]. Применительно к измерениям рассматривается однородность групп наблюдений, необходимые признаки которой состоят в оценке несмещенности средних арифметических и дисперсий относительно друг друга. Проверка допустимости различия между оценками дисперсий нормально распределенных результатов измерений выполняется с помощью критерия Р.Фишера при наличии двух групп наблюдений и критерия М.Бартлетта, если групп больше. Критерий Фишера рассмотрен в гл. 5. Задача обработки результатов многократных измерений заключается в нахождении оценки измеряемой величины и доверительного интервала, в котором находится ее истинное значение. Обработка должна проводится в соответствии с ГОСТ 8.207—76 "ГСИ. Прямые измерения с многократными наблюдениями. Методы обработки результатов наблюдений. Общие положения". Исходной информацией для обработки является ряд из n (n > 4) результатов измерений x1, х2, х.г,..., хn, из которых исключены известные систематические погрешности, — выборка. Число n зависит как от требований к точности получаемого результата, так и от реальной возможности выполнять повторные измерения. Последовательность обработки результатов прямых многократных измерений состоит из ряда этапов. Определение точечных оценок закона распределения результатов измерений. На этом этапе определяются: • среднее арифметическое значение х измеряемой величины по формуле (6.8); • СКО результата измерения Sx по формуле (6.11) или (6.12); • СКО среднего арифметического значения Sx̅ по формуле (6.10). В соответствии с критериями, рассмотренными в гл. 7, грубые погрешности и промахи исключаются, после чего проводится повторный расчет оценок среднего арифметического значения и его СКО. В ряде случаев для более надежной идентификации закона распределения результатов измерений могут определяться другие точечные оценки: коэффициент асимметрии, эксцесс и контрэксцесс, энтропийный коэффициент. Определение закона распределения результатов измерений или случайных погрешностей измерений. В последнем случае от выборки результатов измерений х1, х2, х3,-.., хn переходят к выборке отклонений от среднего арифметического х1, х2, х3,..., хn, где xi = xi - х̅. Первым шагом при идентификации закона распределения является построение по исправленным результатам измерений xi, где I = 1, 2,..., n, вариационного ряда (упорядоченной выборки), а также уi, где уi = min(xi) и уn = mах(хi). В вариационном ряду результаты измерений (или их отклонения от среднего арифметического) располагают в порядке возрастания. Далее этот ряд разбивается на оптимальное число m, как правило, одинаковых интервалов группирования длиной h = (y1 + yn) / m . Задача определения оптимального числа m интервалов группирования рассматривалась в ряде работ, обзор которых дан в [4]. Оптимальным является такое число интервалов m, при котором возможное максимальное сглаживание случайных флуктуации данных сопровождается с минимальным искажением от сглаживания самой кривой искомого распределения. Для практического применения целесообразно использовать предложенные в [4] выражения mmin = 0,55n0,4 и mmax =1,25n0,4, которые получены для наиболее часто встречающихся на практике распределений с эксцессом, находящимся в пределах от 1,8 до 6, т.е. от равномерного до распределения Лапласа. Искомое значение m должно находится в пределах от mmjn до mmax, быть нечетным, так как при четном m в островершинном или двухмодальном симметричном распределении в центре гистограммы оказываются два равных по высоте столбца и середина кривой распределения искусственно уплощается. В случае, если гистограмма распределения явно двухмодальная, число столбцов может быть увеличено в 1,5-2 раза, чтобы на каждый из двух максимумов приходилось примерно по m интервалов. Полученное значение длины интервала группирования h всегда округляют в большую сторону, иначе последняя точка окажется за пределами крайнего интервала. Далее определяют интервалы группирования экспериментальных данных в виде 1 = (у1, y1 + h); 2= (y1 +h, y1 + 2h);....; m = (yn - h; уn), и подсчитывают число попаданий nk (частоты) результатов измерений в каждый интервал группирования. Сумма этих чисел должна равняться числу измерений. По полученным значениям рассчитывают вероятности попадания результатов измерений (частости) в каждый из интервалов группирования по формуле pk= nk/n, где k=l, 2,..., m. Проведенные расчеты позволяют построить гистограмму, полигон и кумулятивную кривую. Для построения гистограммы по оси результатов наблюдений х (рис. 8.1,а) откладываются интервалы k в порядке возрастания номеров и на каждом интервале строится прямоугольник высотой pk. Площадь, заключенная под графиком, пропорц/иональна числу наблюдений n. Иногда высоту прямоугольника откладывают разной эмпирическoй плотности вероятности pk = Pk /k = nk/(nk), которая является оценкой средней плотности в интервале k. В этом случае площадь под гистограммой равна единице. При увеличении числа интервалов и соответственно уменьшении их длины гистограмма все более приближается к гладкой кривой — графику плотности распределения вероятности. Следует отметить, что в ряде слуяаев производят расчетное симметрирование гистограммы, методика которого приведена в [4 ] Полигон представляет собой ломаную кривую, соединяющую середины верхних оснований каждого столбца гистограммы (см. рис. 8.1,а). Он более наглядно, чем гистограмма, отражает форму кривой распределения. За пределами гистограммы справа и слева остаются пустые интервалы, в которых точки, соответствующие их серединам, лежат на оси абсцисс. 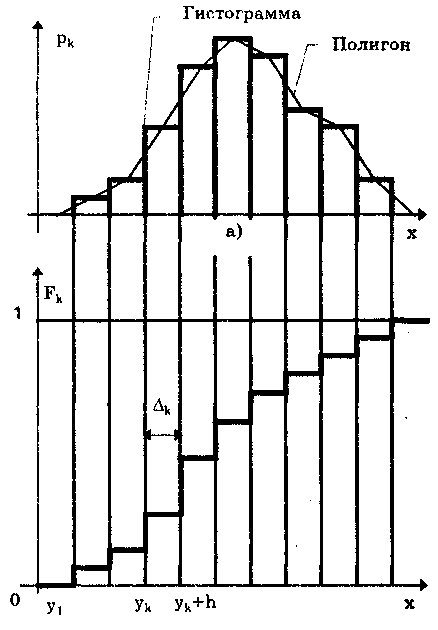 Рис. 8.1. Гистонрамма, полигон (а) и кумулятивная кривая (б) Эти точки при построении полигона соединяют между собой отрезками прямых линий. В результате совместно с осью х образуется замкнутая фигура, площадь которой в соответствии с правилом нормирования должна быть равна единице (или числу наблюдений при использовании частостей). Кумулятивная кривая — это график статистической функции распределения. Для ее построения по оси результатов наблюдений х (рис. 8.1,6) откладывают интервалы k в порядке возрастания номеров и на каждом интервале строят прямоугольник высотой  Значение Fk называется кумулятивной частостью, а сумма nk— кумулятивной частотой. По виду построенных зависимостей может быть оценен закон распределения результатов измерений. Оценка закона распределения по статистическим критериям. При числе наблюдений n > 50 для идентификации закона распределения используется критерий Пирсона (хи-квадрат, см. 8.1.2) или критерий Мизеса—Смирнова (2). При 50 > n > 15 для проверки нормальности закона распределения применяется составной критерий (d-критерий), приведенный в ГОСТ 8.207-76. При n < 15 принадлежность экспериментального распределения к нормальному не проверяется. Определение доверительных границ случайной погрешности. Если удалось идентифицировать закон распределения результатов измерений, то с его использованием находят квантильный множитель zp при заданном значении доверительной вероятности Р. В этом случае доверительные границы случайной погрешности А = ±zpS -. Определение границ неисключенной систематической погрешности результата измерений. Под этими границами понимают найденные нестатистическими методами границы интервала, внутри которого находится неисключенная систематическая погрешность. Она образуется из ряда составляющих: как правило, погрешностей метода и средств измерений, а также субъективной погрешности. Границы неисключенной систематической погрешности принимаются равными пределам допускаемых основных и дополнительных погрешностей средств измерений, если их случайные составляющие пренебрежимо малы. Они суммируются по правилам, рассмотренным в разд. 9.2. Доверительная вероятность при определении границ 6 принимается равной доверительной вероятности, используемой при нахождении границ случайной погрешности. Определение доверительных границ погрешности результата измерения р. Данная операция осуществляется путем суммирования СКО случайной составляющей Sx̅ и границ неисключенной систематической составляющей в зависимости от соотношения / Sx̅ по правилам, изложенным в разд. 9.4. Запись результата измерения. Результат измерения записывается в виде х = х̅ ± p при доверительной вероятности Р = Р . При отсутствии данных о виде функции распределения составляющих погрешности результаты измерений представляют в виде х, S-, п, 8 при доверительной вероятности Р = Рд. 8.1.2. Идентификация формы распределениярезультатов измеренийВ качестве способа оценки близости распределения выборки экспериментальных данных к принятой аналитической модели закона распределения используются критерии согласия. Известен целый ряд критериев согласия, предложенных разными авторами. Наибольшее распространение в практике получил критерий Пирсона. Идея этого метода состоит в контроле отклонений гистограммы экспериментальных данных от гистограммы с таким же числом интервалов, построенной на основе распределения, совпадение с которым определяется. Использование критерия Пирсона [3, 48] возможно при большом числе измерений (п > 50) и заключается в вычислении величины 2 (хи-квадрат):  (8.1) (8.1)где ni, Ni — экспериментальные и теоретические значения частот в i-м интервале разбиения; m — число интервалов разбиения; Pi — значения вероятностей в том же интервале разбиения, соответствующие выбранной модели распределения; При n случайная величина 2 имеет распределение Пирсона с числом степеней свободы v = m - 1- r, где г — число определяемых по статистике параметров, необходимых для совмещения модели и гистограммы. Для нормального закона распределения г = 2, так как закон однозначно характеризуется указанием двух его параметров — математического ожидания и СКО. Если бы выбранная модель в центрах всех m столбцов совпадала с экспериментальными данными, то все m разностей (ni –Ni) были бы равны нулю, а следовательно, и значение критерия 2 также было бы равно нулю. Таким образом, 2 естьмера суммарного отклонения между моделью и экспериментальным распределением. Критерий 2 не инвариантен к числу столбцов и существенно возрастает с увеличением их числа. Поэтому для использования его при разном числе столбцов составлены таблицы квантилей распределения 2, входом в которые служит так называемое число степеней свободы v = (m – 1 - r). Чтобы совместить модель, соответствующую нормальному закону, с гистограммой, необходимо совместить координату центра, а для того, чтобы ширина модели соответствовала ширине гистограммы, ее нужно задать как г = 2 и v = m-3. Часть квантилей распределения 2q приведена в табл. 8.1. Таблица 8.1 Значения 2 при различном уровне значимости
Если вычисленная по опытным данным мера расхождения 2 меньше определенного из таблицы значения q2 , то гипотеза о совпадении экспериментального и выбранного теоретического распределений принимается. Это не значит, что гипотеза верна. Можно лишь утверждать, что она правдоподобна, т.е. она не противоречит опытным данным. Если же c2выходит за границы доверительного интервала, то гипотеза отвергается как противоречащая опытным данным. Методика определения соответствия экспериментального и принятого законов распределения заключается в следующем: • определяют оценки среднего арифметического значения х и СКО Sx по формулам (6.9) и (6.11); • группируют результаты многократных наблюдений по интервалам длиной h, число которых определяют "так же, как и при построении гистограммы; • для каждого интервала разбиения определяют его центр xio и подсчитывают число наблюдений П|, попавших в каждый интервал; • вычисляют число наблюдений для каждого из интервалов, теоретически соответствующее выбранной аналитической модели распределения. Для этого сначала от реальных середин интервалов хi0 производят переход к нормированным серединам zi = (хi0 - x̅)/Sx. Затем для каждого значения ziспомощью аналитической модели находят значение функции плотности вероятностей f(zi). Например, для нормального закона По найденному значению f(zi) определяют ту часть Ni имеющихся наблюдений, которая теоретически должна быть в каждом из интервалов Ni = nhf(zi)/Sх, где n — общее число наблюдений; • если в какой-либо интервал теоретически попадает меньше пяти наблюдений, то в обеих гистограммах его соединяют с соседним интервалом. После этого определяют число степеней свободы v = m-1-r, где m — общее число интервалов. Если было произведено укрупнение, то m — число интервалов после укрупнения; • по формуле (8.1) определяют показатель разности частот 2; • выбирают уровень значимости критерия q. Он должен быть небольшим, чтобы была мала вероятность совершить ошибку первого рода. По уровню значимости и числу степеней свободы v по табл. 8.1 находят границу критической области cq2, такую, что P{c2 > cq2} = q. Вероятность того, что полученное значение c2 превышает cq2, равна q и мала. Поэтому, если оказывается, что c2 > cq2, то гипотеза о совпадении экспериментального и теоретического законов распределения отвергается. Если же c2 < cq2, то гипотеза принимается. Чем меньше q, тем больше значение cq2 (при том же числе степеней свободы v), тем легче выполняется условие c2 < cq2и принимается проверяемая гипотеза. Но при этом увеличивается вероятность ошибки второго рода. В связи с этим нецелесообразно принимать 0,02 < q < 0,01. Иногда вместо проверки с односторонней критической областью применяют проверки с двусторонними критическими областями. При этом оценивается вероятность P{cqн2 < c2 < cqв2}.Уровень значимости критерия q делится на две части: q = q1 + q2. Как правило, принимают q1 = q2. По табл. 8.1 для P{c2 > cq2} = q находят c12 при уровне значимости q, и числе степеней свободы v и c22 уровня значимости 1 — q2 и том же n. Гипотеза о совпадении распределений принимается, если | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||