Ауе. Основное 4 МУ АД Лаб 4 сем (1). Методические указания к проведению лабораторных занятий по нормативной учебной дисциплине естественнонаучного цикла Анализ данных
 Скачать 6.5 Mb. Скачать 6.5 Mb.
|

|
Цель: научиться работать с OLAP-кубом. Исходные данные Имеется компания, занимающаяся продажей продуктов питания. Для хранения и последующего анализа выбираются данные, описывающие бизнес-процесс продажи товаров. Объектами предметной области являются продавцы и продукты. Задание 1. В MS Excel создать новую книгу “OLAP”. 2. В ту же папку сохранить с сайта www.fem-sut.spb.ru файл nwdata_cube.cub. 3. Через пункт меню «Вставка-Сводная» таблица запустить Мастер, выбрать пункт 'использовать внешний источник данных', нажать кнопку 'выбрать подключение' и указать в качестве источника файл nwdata_cube.cub. 4. В открывшемся справа окне изучить структуру OLAP куба. 5. Используя операцию Сечения, построить сводную таблицу с изме- рениями Страна (по столбцам) и Год продажи (по строкам). В качестве фактов взять количество проданных товаров. Агрегировать данные по странам и по годам. 6. Используя операцию Транспонирования, поменять местами изме- рения Страна и Год продажи. 7. Используя операцию Сечения, добавить в качестве измерения Кате- горию продукта. 8. Используя операцию Детализации, отобразить в таблице названия компаний и названия продуктов. 9. Используя операцию Свертки, скрыть названия продуктов по всей таблице. 10. Добавить агрегированное значение по сумме продаж по странам Аргентина и Австрия. Названную группу назвать «Страны на А». Устано- вить показ промежуточных итогов в нижней части группы. 11. Сравнить полученный результат с рис. 3.1. Убедиться в невозмож- ности изменять заданную в кубе иерархию уровней. 12. Скопировать полученную сводную таблицу на новые листы и по- строить на них диаграммы, позволяющие получить ответы на следующие вопросы (предварительно при необходимости внести изменения в структуру скопированных таблиц): а) Доли пяти самых крупных стран продавцов по итоговым продажам (рис. 3.2.). б) Объемы продаж самых продаваемых товаров из каждой товарной категории по годам (рис. 3.3.). с) Динамика продаж морепродуктов в США по месяцам (рис. 3.4.). 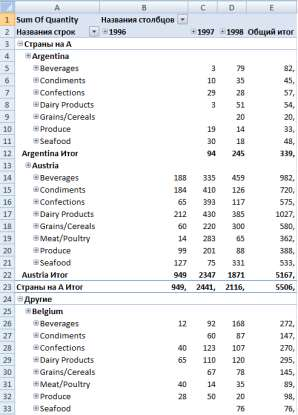 Рис. 3.1 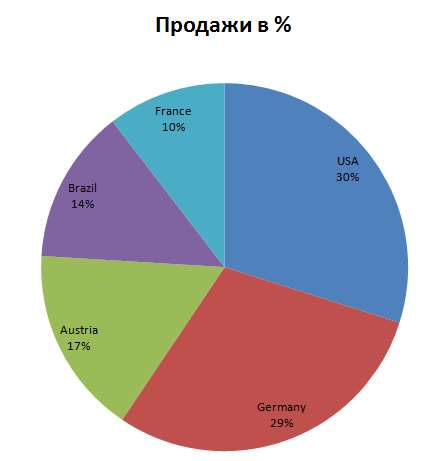 Рис. 3.2 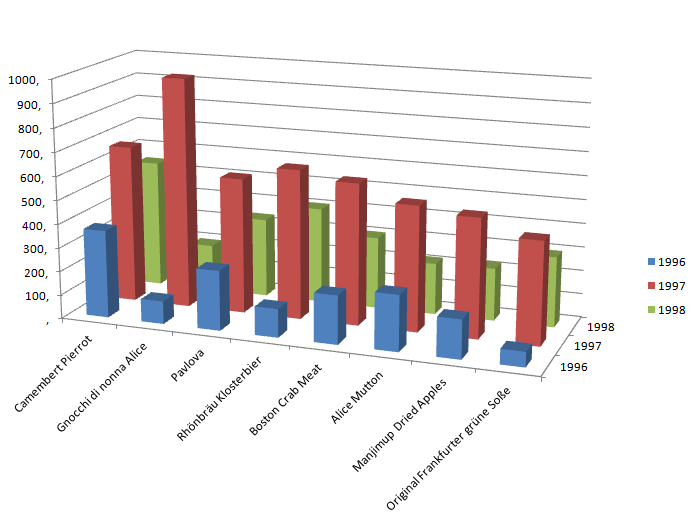 Рис. 3.3 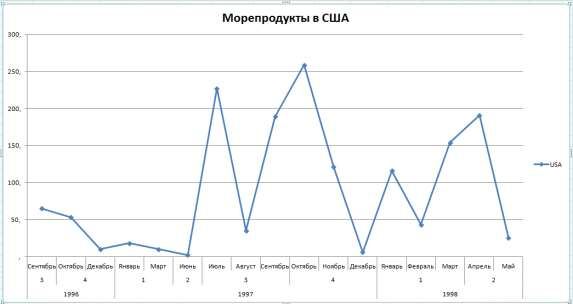 Рис. 3.4 ЛАБОРАТОРНАЯ РАБОТА №4. Описательные статистики. Выявление резко выделяющихся наблюдений. Цель: научиться сглаживать данные для анализа Краткая характеристика пакета Deductor Deductor Studio – программа, являющаяся составной частью платформы Deductor. Она содержит механизмы импорта, обработки, визуализации и экспорта данных для быстрого и эффективного анализа и прогнозирования. В Deductor Studio для аналитика основополагающим понятием является сценарий. Сценарий представляет собой последовательность операций с данными, представленную в виде иерархического дерева. В дереве каждая операция образует узел, заголовок которого содержит: имя источника данных, наименование применяемого метода обработки, используемые при этом поля и т.д. Кроме этого, слева от наименования узла стоит значок, со- ответствующий типу операции. Если узел имеет подчиненные узлы, то слева от его названия будет расположен значок «+», щелчок по которому позволит развернуть узел, т.е. сделать видимыми все его подчиненные узлы, при этом значок «+» поменяется на «–». Щелчок по значку «–», наоборот, сворачивает все подчиненные узлы. Задание Ознакомиться с возможностями аналитического пакета Deductor, выполнив приведенные ниже задания. В конце работы сохранить проект. Импорт данных Сценарий состоит из ветвей. Deductor не имеет собственных средств для ввода данных, поэтому сценарий всегда начинается с узла импорта из какого-либо источника. Любой вновь создаваемый узел импорта будет находиться на верхнем уровне Импорт данных из текстового файла с разделителями осуществляется путем вызова мастера импорта на панели «Сценарии» (рис. 4.1).  Рис.4.1 После запуска мастера импорта указать тип импорта “Текстовый файл (Direct)” и перейти к настройке импорта. Все файлы примеров необходимо сохранить с сайта или взять с сетевого диска T:\Analiz. Указать имя файла Trade.txt (), из которого необходимо получить дан- ные. В данном файле содержатся данные о продажах за некоторый период времени. В окне просмотра выбранного файла можно увидеть его содержа- ние. Перейти к настройке параметров импорта (шаг 2–4). На шаге 3 указать в качестве разделителя целой и дробной части числа точку. Все остальные параметры по умолчанию оставить без изменения. Теперь перейдем к настройке свойств полей. На этом шаге мастера предоставляется возможность настроить имя, название (метку), размер, тип данных, вид данных и назначение. Некоторые свойства (например, тип данных) можно задавать для выделенного набора столбцов. Вид данных определяет – конечный ли это набор (дискретные) или бесконечный (не- прерывные). В нашем случае год и месяц продажи товара – это текстовые (строковые) дискретные значения, а количество проданного товара веще- ственные непрерывные. Указав параметры столбцов, запустить процесс импорта, нажав на кнопку «Пуск». После импорта данных на следующем шаге Мастера необходимо выбрать способ отображения данных. В данном случае самым информативным является диаграмма, поэтому выберем ее (рис. 4.2). Очистка данных 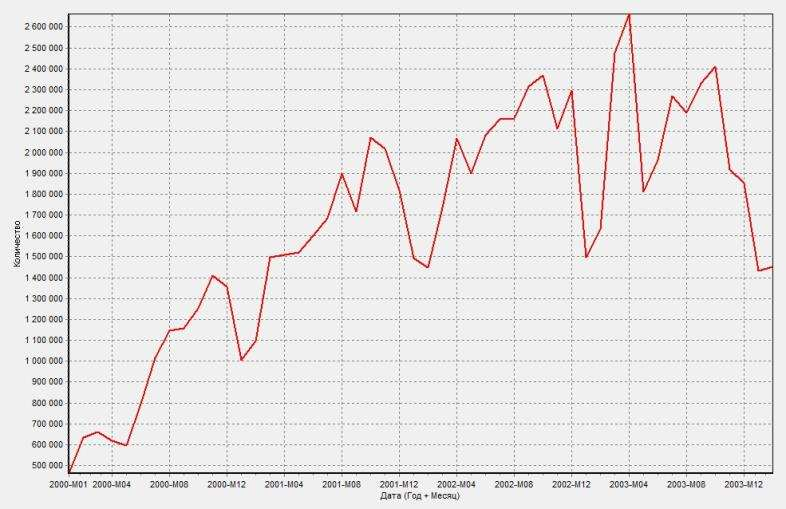 Рис. 4.2 Часто исходные данные для анализа не годятся, а качество данных влияет на качество результатов. Обычно «сырые» данные содержат в себе различные «шумы», за которыми трудно увидеть общую картину, а также аномалии – влияние случайных, либо редко происходивших событий. Оче- видно, что влияние этих факторов на общую модель необходимо минимизировать, т.к. модель, учитывающая их, получится неадекватной. Минимизировать влияние шумов, аномалий и прочее можно, используя устойчивые к их воздействию алгоритмы анализа и применяя специализированные механизмы очистки. Парциальная предобработка Парциальная предобработка служит для восстановления пропущенных данных, редактирования аномальных значений (выбросов) и спектральной обработке данных (например, сглаживания данных). Именно этот шаг часто проводится в первую очередь. Как видно из диаграммы (рис. 4.2) выбросы ухудшают статистическую картину распределения. Воспользуемся мастером обработки (рис. 4.3) и выберем Редактирование выбросов.  Рис. 4.3 В мастере на 2 шаге поставить флажок «Обрабатывать как упорядо- ченный набор данных». На 3 шаге для поля «Количество» указать боль- шую степень подавления. После выполнения процесса обработки на диаграмме (рис. 4.4) видно, что выбросы уменьшились, стала проясняться реальная картина продаж. Переключение между двумя диаграммами можно сделать через меню «Ок- но». Спектральная обработка 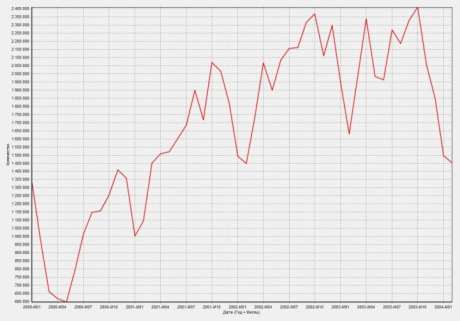 Рис. 4.4 Сглаживание данных применяется для удаления шумов из исходного набора, а также для выделения тенденции, трудно обнаруживаемой в исходном наборе. Deductor Studio предлагает несколько видов спектральной обработки. Продолжим работу с данными файла «Trade.txt». Сгладим данные при помощи спектральной обработки. В Мастере поле «Количество» указать как используемое и выбрать «Вычитание шума» После выполнения процесса обработки выбрать в качестве визуализации диаграмму. Как видно из рис. 4.5 данные стали более сглаженными и могут служить для дальнейшей обработки. Взглянув на данные легко понять общую тенденцию. 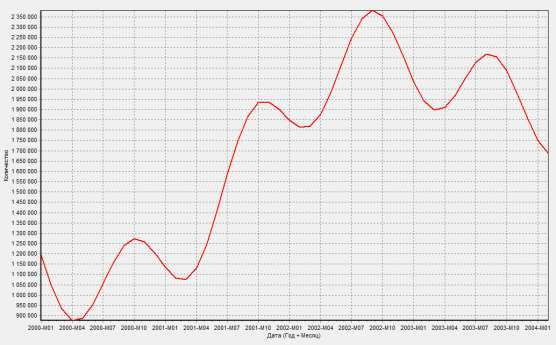 Рис. 4.5 Задание для самостоятельного выполнения 1. Импортировать сценарий «Dynamics_website.txt», содержащий данные о посещаемости веб-сайта. 2. Визуализировать данные в виде диаграммы. 3. Провести оценку качества данных по полу Посещения, используя соответствующий метод обработки. 4. Провести спектральную обработку по полю Посещения на основе Вейвлет-преобразования. 5. Визуализировать данные в виде диаграммы. 6. Провести сравнительный анализ диаграмм до и после обработки. ЛАБОРАТОРНАЯ РАБОТА №5. Корреляционный анализ Цель: изучить методику корреляционного анализа Задание Ознакомиться с возможностями аналитического пакета Deductor, выполнив приведенные ниже задания. В конце работы сохранить проект. Корреляционный анализ Корреляционный анализ применяется для оценки зависимости выходных полей данных от входных факторов и устранения незначащих факторов. Принцип корреляционного анализа состоит в поиске таких значений, которые в наименьшей степени коррелированны (взаимосвязаны) с выход- ным результатом. Такие факторы могут быть исключены из результирую- щего набора данных практически без потери полезной информации. Крите- рием принятия решения об исключении является порог значимости. Если корреляция между входным и выходным факторами меньше порога значи- мости, то соответствующий фактор отбрасывается как незначащий. Рассмотрим применение обработки на примере данных из файла «Anketa1.txt». Он содержит таблицу с информацией о кредитах граждан. В данном примере определим степень влияния входных факторов на один из выходов и оставим только значимые. Импортировать файл «Anketa1.txt» и выбрать вариант отображения таблица.  Рис. 5.1 В Мастере обработки выбрать корреляционный анализ, и задать входные поля «Личный доход в месяц после налогообложения», «Сумма кредита», «Стаж работы», «Количество лет проживания в регионе», «Рыночная стоимость автомобиля», «Рыночная стоимость недвижимо- сти» и выходное поле «Возврат кредита». Остальные поля отметить как неиспользуемые (рис. 5.1). В качестве метода выбрать коэффициент корреляции Пирсона. На следующем шаге запустить процесс корреляционного анализа. После завершения процесса выбрать все факторы. По полученной матрице корреляции (рис. 5.2) видно, какие факторы влияют сильнее, чем другие, и какие можно не учитывать при построении всевозможных моделей. Дубликаты и противоречия 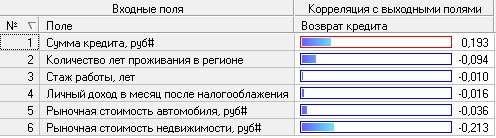 Рис. 5.2 Одна из серьезных проблем, часто встречающаяся на практике, – наличие в данных дубликатов и противоречий. Противоречивыми являются группы записей, в которых содержатся строки с одинаковыми входными факторами, но разными выходными. В такой ситуации непонятно, какое результирующее значение верное. Если противоречивые данные использовать для построения модели, то она ока- жется неадекватной. Поэтому противоречивые данные чаще всего лучше вообще исключить из исходной выборки. Также в данных могут встречаться записи с одинаковыми входными факторами и одинаковыми выходными, т.е. дубликаты. Таким образом, данные несут избыточность. В большинстве случаев дубликаты в данных являются следствием ошибок при подготовке данных. В Deductor Studio для автоматизации этого процесса есть соответству- ющий инструмент – обработка «Дубликаты и противоречия». Суть обработки состоит в том, что определяются входные (факторы) и выходные (результаты) поля. Алгоритм ищет во всем наборе записи, для которых одинаковым входным полям соответствуют одинаковые (дублика- ты) или разные (противоречия) выходные поля. На основании этой инфор- мации создаются два дополнительных логических поля – «Дубликат» и «Противоречие», принимающие значения «истина» или «ложь». В допол- нительные числовые поля "Группа дубликатов" и "Группа противоречий" записываются номер группы дубликатов и группы противоречий, в кото- рые попадает данная запись. Если запись не является дубликатом или про- тиворечием, то соответствующее поле будет пустым. Рассмотрим механизм выявления дубликатов на примере данных фай- ла «Anketa.txt». В этом файле находится информация об анкетных данных граждан, участвующих в кредитовании. Попробуем вычислить присутствие дубликатов. Импортируем данные из текстового файла и посмотрим их в виде таб- лицы. Для выявления дубликатов запустить Мастер обработки. В нем вы- брать тип обработки «Дубликаты и противоречия». На 2 шаге Мастера необходимо настроить назначение полей. Поля «Фамилия», «Имя», «Отче- ство» определить как входные, «Код Анкеты» – как выходное, а «Сумма кредита» оставить информационным. После завершения выявления дубликатов просмотреть результат в ви- де таблицы дубликатов и противоречий. В первом случае видно, что существуют одинаковые строки, являю- щиеся дубликатами. Данный обработчик показывает дубликаты и их при- надлежность к группам дубликатов (рис. 5.3). 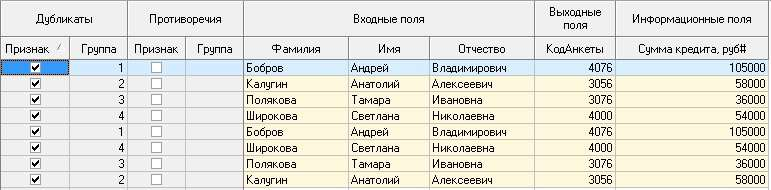 Рис. 5.3 Во втором случае видно, что при одинаковых «Фамилия», «Имя», «Отчество» оказываются различные «Коды Анкет» (рис. 5.4). 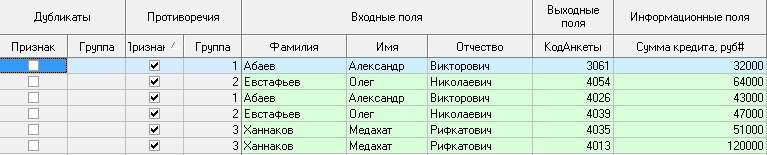 Рис. 5.4 Задание для самостоятельного выполнения 1. Импортировать сценарий «Region.txt», содержащий данные об экономическом состоянии регионов. 2. Провести корреляционный анализ зависимости объема Валового регионального продукта от всех остальных пригодных факторов. 3. Визуализировать данные в виде матрицы корреляции. 4. Сделать выводы по результатам анализа. ЛАБОРАТОРНАЯ РАБОТА №6. Прогнозирование с помощью линейной регрессии Цель: научиться прогнозировать динамику временного ряда Задание Ознакомиться с возможностями аналитического пакета Deductor, выполнив приведенные ниже задания. В конце работы сохранить проект. Преобразование данных к скользящему окну Линейная регрессия необходима тогда, когда предполагается, что зависимость между входными факторами и результатом линейная. Достоин- ством ее можно назвать быстроту обработки входных данных и простоту интерпретации полученных результатов. Рассмотрим применение линейной регрессии на примере данных по продажам, находящихся в файле «Trade.txt». Когда требуется прогнозировать временной ряд, тем более, если налицо его периодичность (сезонность), то лучшего результата можно добиться, учитывая значения факторов не только в данный момент времени, но и, например, за аналогичный период прошлого года. Такую возможность можно получить после трансформации данных к скользящему окну. То есть, например, при сезонности продаж с периодом 12 месяцев, для прогно- зирования количества продаж на месяц вперед можно в качестве входного фактора указать не только значение количества продаж за предыдущий ме- сяц, но и за 12 месяцев назад. Обработка создает новые столбцы путем сдвига данных исходного столбца вниз и вверх (глубина погружения и горизонт прогноза). У аналитика имеются данные о месячном количестве проданного товара за несколько лет. Ему необходимо, основываясь на этих данных, сказать, какое количество товара будет продано через неделю и через две. Выполните импорт данных из файла Trade.txt, запустите Мастер «Скользящее окно» (рис. 6.1). 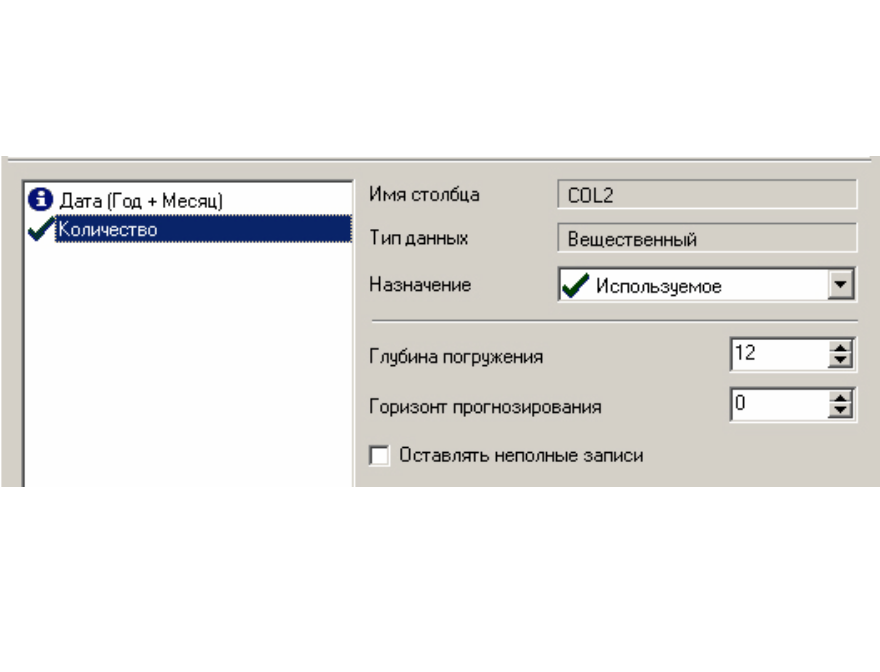 Рис. 6.1 В качестве результата прогноза будет указан столбец "Количество" (рис. 6.2).  Рис. 6.2 Прогнозирование с помощью линейной регрессии Теперь можно перейти непосредственно к прогнозированию. Будем строить прогноз с помощью линейной регрессии сразу после обработчика «Скользящее окно». Для построения линейной регрессии необходимо запустить Мастер обработки и выбрать в качестве обработки данных Линейную регрессию. На первом шаге задать назначение исходных столбцов. «Количество 1–12» сделать входными столбцами, а «Год и месяц» информационным по- лем. В качестве выходного поля указать столбец «Количество». На следующем шаге происходит настройка обучающего и тестового множеств, способ разложения исходного множества данных. Третий шаг установки позволяет осуществить ограничение диапазона входных значе- ний. Данные шаги оставим без изменений. При нажатии на кнопку «Далее» появляется окно запуска процесса обучения. В процессе выполнения видно, какая часть распознана на этапе обучения и теста. После выполнения процесса выбрать в качестве способа отображения диаграмму рассеяния и отображение результатов в виде диаграммы. Как видно из обеих диаграмм, обучение прошло с хорошей точностью (рис. 6.3). Теперь для построения прогноза запустить Мастера обработки, в кото- ром выбрать Прогнозирование. На первом шаге обработчика происходит настройка связи столбцов для прогнозирования. Указать связь между столбцами и горизонт прогноза равный 3 (рис. 8.4). На следующем шаге задаются параметры визуализации. Для данного примера выбрать отображение результатов в виде диаграммы прогноза (рис. 6.4). 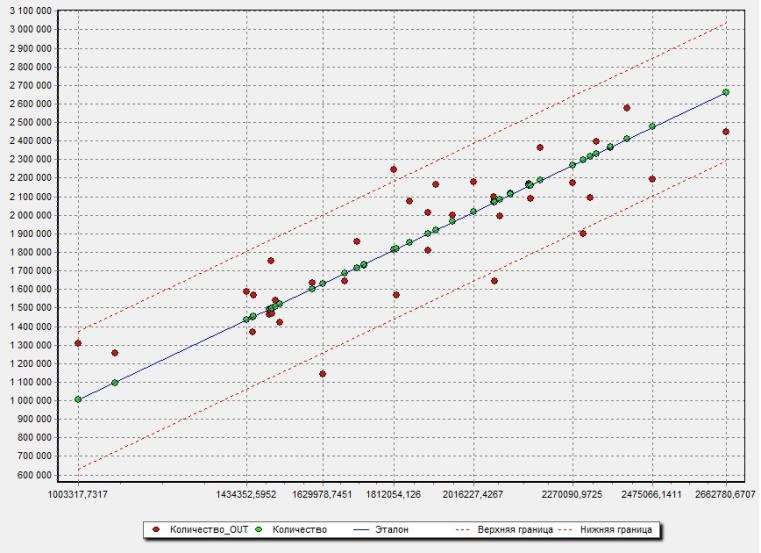 Рис. 6.3 Теперь аналитик может дать прогноз о продажах, основываясь на модели, построенной с помощью линейной регрессией. 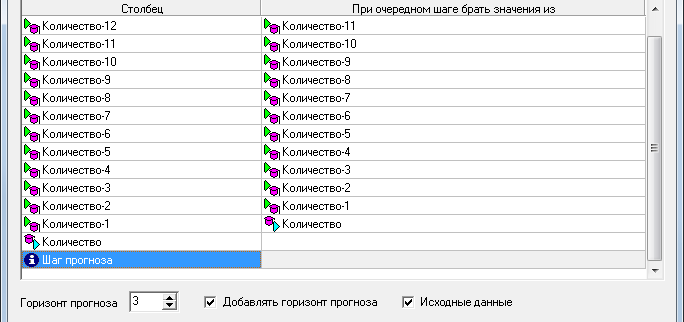 Рис. 6.4 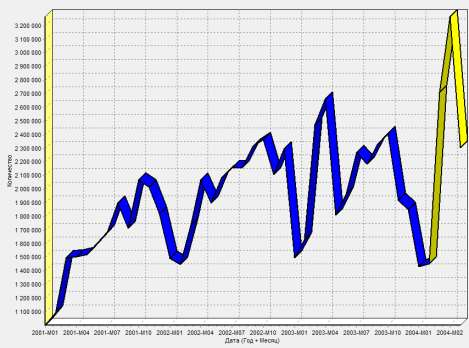 Рис. 6.5 |