Ауе. Основное 4 МУ АД Лаб 4 сем (1). Методические указания к проведению лабораторных занятий по нормативной учебной дисциплине естественнонаучного цикла Анализ данных
 Скачать 6.5 Mb. Скачать 6.5 Mb.
|

|
ЧАСТЬ 2 ЛАБОРАТОРНАЯ РАБОТА №1. Классификация с помощью деревьев решений Цель: изучить методы классификации с помощью деревьев решений Задание Ознакомиться с возможностями аналитического пакета Deductor, выполнив приведенные ниже задания. В конце работы сохранить проект. Деревья решений. Деревья решений применяются для решения задачи классификации. Дерево представляет собой иерархический набор условий (правил), согласно которым данные относятся к тому или иному классу. В построенном дереве присутствует информация о достоверности того или иного правила. Рассчитывается значимость каждого входного поля. Пусть аналитик имеет данные по тому, как голосуют депутаты конгресса США по различным законопроектам. Также известна партийная принадлежность каждого депутата – республиканец или демократ. Перед аналитиком поставлена задача: классифицировать депутатов на демократов и республиканцев в зависимости от того, как они голосуют. Данные по голосованию находятся в файле «Голосование конгресса.txt». Таблица содержит следующие поле «Класс» – класс голосующего (демократ или республиканец) и поля, информирующие о том, как голосовали депутаты за принятие различных законопроектов («да», «нет», «воздержался»). Для решения задачи нужно импортировать файл Голосование конгресса.txt (все типы полей указать как строковые), и запустить Мастер обработки. Выбрать в качестве обработки дерево решений. В Мастере построения на 2 шаге сделать поле «Класс» выходным, а остальные поля входными. Далее предлагается настроить способ разбиения исходного множества данных на обучающее и тестовое. Зададим случайный способ разбиения, когда данные для тестового и обучающего множества берутся из исходного набора случайным образом. На следующем шаге Мастера предлагается настроить параметры процесса обучения, а именно минимальное количество примеров, при котором будет создан новый узел (пусть узел создается, если в него попали два и более примеров), а также предлагается возможность строить дерево с более достоверными правилами. На следующем шаге Мастера запускается сам процесс построения де- рева. Также можно увидеть информацию о количестве распознанных примеров (рис. 1.1). После построения дерева можно увидеть, что почти все примеры и на обучающей и на тестовой выборке распознаны. Перейти на следующий шаг Мастера для выбора способа визуализации. Основной целью аналитика является отнесение депутата к той или иной партии. Механизм отнесения должен быть таким, чтобы депутат указал, как он будет голосовать за различные законопроекты, а дерево решений ответит на вопрос, кто он – демократ или республиканец. Такой механизм предлагает визуализатор «Что-если». 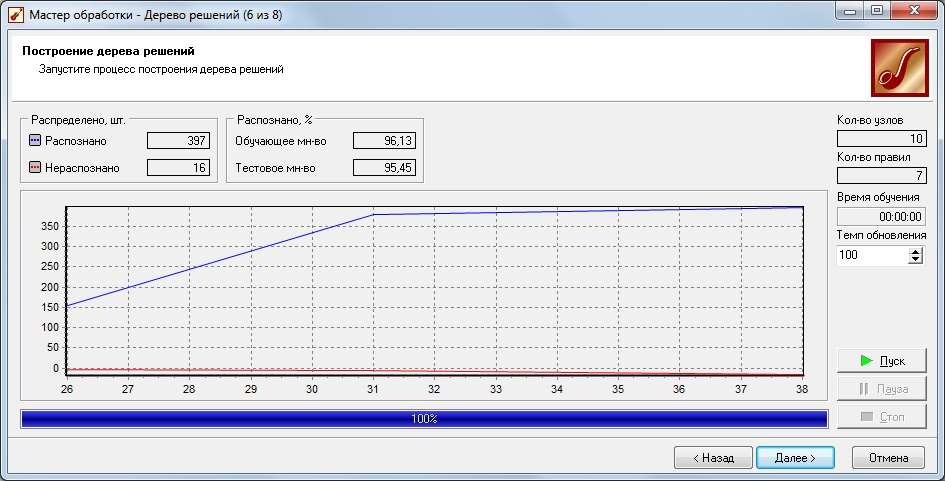 Рис. 1.1 Не менее важным является и просмотр самого дерева решений, на ко- тором можно определить, какие факторы являются более важными (верх- ние узлы дерева), какие второстепенными, а какие вообще не оказывают влияния (входные факторы, вообще не присутствующие в дереве решений). Поэтому выберем также и визуализатор «Дерево решений». Формализованные правила классификации, выраженные в форме «Ес- ли <Условие>, тогда <Класс>», можно увидеть, выбрав визуализатор «Пра- вила (дерево решений)». Часто аналитику бывает полезно узнать, сколько примеров было рас- познано неверно, какие именно примеры были отнесены к какому классу ошибочно. На этот вопрос дает ответ визуализатор «Таблица сопряженности». Важную информацию предоставляет визуализатор «Значимость атрибутов». С помощью него можно определить, насколько сильно выходное поле зависит от каждого из входных факторов. Чем больше значимость атрибута, тем больший вклад он вносит при классификации. Проведем анализ полученных данных. Для начала посмотрим на «Таблицу сопряженности» (рис. 1.2).  Рис. 1.2 По диагонали таблицы расположены примеры, которые были пра- вильно распознаны, в остальных ячейках – те, которые были отнесены к другому классу. В данном случае дерево правильно классифицировало практически все примеры. Перейдем к визуализатору «Дерево решений» (рис. 1.3). Как видно, де- рево решений получилось не очень громоздкое, большая часть факторов (законопроектов) была отсечена, т.е. влияние их на принадлежность к пар- тии минимальна или его вообще нет (по-видимому, по этим вопросам у партий нет принципиального противостояния). 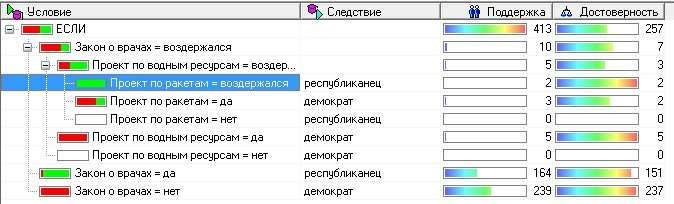 Рис. 1.3 Самым значимым фактором оказалась позиция, занимаемая депутата- ми по пакету законов, касающихся врачей. Это же подтверждает и визуали- затор «Значимость атрибутов». На визуализаторе «Правила» представлен список всех правил, соглас- но которым можно отнести депутата к той или иной партии. Правила мож- но сортировать по поддержке, достоверности, фильтровать по выходному классу (к примеру, показать только те правила, согласно которым депутат является демократом с сортировкой по поддержке). Данные представлены в виде таблицы. Полями этой таблицы являются: - номер правила, - условие, которое однозначно определяет принадлежность к партии, - решение – то, кем является депутат, голосовавший согласно этому условию, - поддержка – количество и процент примеров из исходной выборки, которые отвечают этому условию, - достоверность – процентное отношение количества верно распознан- ных примеров, отвечающих данному условию, к общему количеству при- меров, отвечающих данному условию. Исходя из данных этой таблицы, аналитик может сказать, что именно влияет на то, что депутат является демократом или республиканцем, какова цена этого влияния (поддержка) и какова достоверность правила. Задание для самостоятельного выполнения Вариант 1 (номер зачетной книжки заканчивается на 0, 1, 2, 3) На основе исходных данных файла «Credit.txt» определить правила выдачи кредитов. Вариант 2 (номер зачетной книжки заканчивается на 4, 5, 6) На основе исходных данных файла «Грибы.txt» найти алгоритм определения съедобных и не ядовитых грибов. Вариант 3 (номер зачетной книжки заканчивается на 7, 8, 9) На основе исходных данных файла «Ирисы.txt» найти алгоритм определения класса цветов. ЛАБОРАТОРНАЯ РАБОТА № 2. Кластеризация Цель: изучить методы кластеризации Задание Ознакомиться с возможностями аналитического пакета Deductor https://basegroup.ru/deductor/download , выполнив приведенные ниже задания. В конце работы сохранить проект. Кластеризация с помощью с помощью алгоритма k-means Рассмотрим механизм кластеризации, реализованный на алгоритме k-means, основываясь на данных роста численности населения по регионам РФ. Исходная таблица находится в файле «Регионы.txt». Задача состоит в распределении регионов на функциональные группы по демографической картине в них и выявлении скрытых закономерностей. Вначале необходимо осуществить импорт рассматриваемых данных из файла. После этого запустить Мастер обработки «Кластеризация». При за- пуске Мастера необходимо настроить назначения столбцов, т.е. выбрать свойства, по которым будет происходить группировка объектов. Укажите столбцам «Численность населения» и «Регион» назначение «информационное», а остальным полям – «входное». На следующем шаге Мастера необходимо настроить способ разделе- ния исходного множества данных на тестовое и обучающее, а также коли- чество примеров в том и другом множестве. Укажите, что данные обоих множеств берутся случайным образом, и определите все множество как обучающее. Следующий шаг предлагает настроить параметры кластеризации, определить на какое количество кластеров будет распределяться исходное множество. По мнению экспертов в стране наблюдается четыре тенденции развития регионов, поэтому выберем фиксированное количество кластеров равное четырем. Для отображения полученных групп кластеров выбрать из списка ви- зуализаторов способы отображения данных: «Профили кластеров», «Куб» «Матрица сравнений», «Связи кластеров». Для настройки визуализатора «Куб» необходимо выбрать рассматри- ваемые показатели как факты, а номер кластера и регионы как измерение. На 9 шаге задать отображение фактов как среднее по рассматриваемое группе. Общую структуру сформированных алгоритмом кластеров можно просмотреть в визуализаторе «Профили кластеров» (рис. 2.1). В нем пред- ставлены все рассматриваемые свойства вместе с характером влияния их на состав кластера. Основным фактором, определяющим состав кластера, яв- ляется значимость свойств, выраженная в процентах. Алгоритм автоматически разбил регионы на четыре кластера с разной поддержкой и разными процентами значимости свойств. 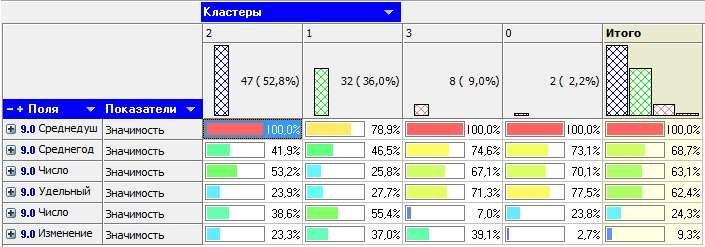 Рис. 2.1 Третий кластер является показателем демографической обстановки страны, так как собрал в себя максимальное количество регионов – 47 из 89. Малозначимым и почти не влияющим свойством на распределение яв- ляется изменение численности населения по сравнению с предыдущим го- дом, при необходимости данным свойством можно пренебречь. С помощью кнопки переименование кластеров можно им присвоить им рабочие названия (рис. 2.2). 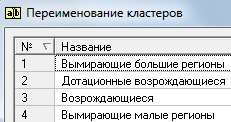 Рис. 2.2 Наиболее ярко выраженными кластерами по заданным свойствам яв- ляются нулевой и первый кластер: они максимально отличаются от осталь- ных рассматриваемых групп значениями свойств, и минимальной под- держкой. Подтвердим предположение, используя визуализатор «Матрица сравнений». Наименьшая степень сходства между первым и нулевым кла- стером 12,76% (рис. 2.3). 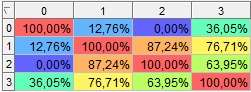 Рис. 2.3 Так же оценить похожесть кластеров можно с помощью визуализатора «Связи кластеров». Наиболее похожим на нулевой кластер является второй, он имеет наибольшую степень связи, отображаемую на диаграмме красным цветом (рис. 2.4). При необходимости данные кластеры как наиболее похожие можно объединить. 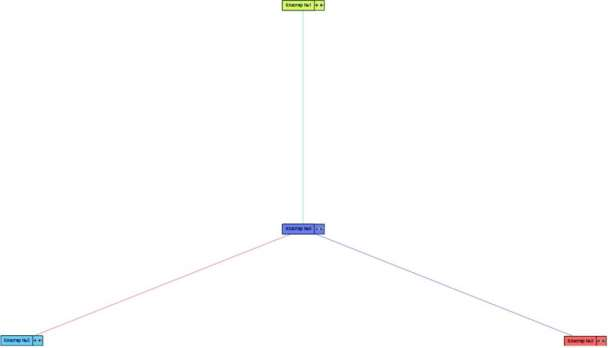 Рис. 2.4 Результаты по сформированным кластерам наиболее удобно рассмат- риваются с помощью визуализатора «Куб», в который встроена кросс- диаграмма, изображающая полученные кластеры в графическом виде, что существенно упрощает анализ (рис. 2.5). 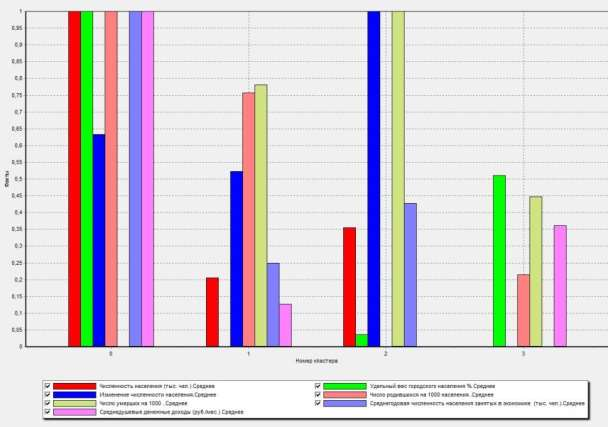 Рис. 2.5 Определить какой регион максимально похож на выбранный можно с помощью «Диаграммы связи». Определим семь похожих на Санкт-Петербург регионов по демографической обстановке. Зададим количество связей равным - 7, а Санкт-Петербург поместим в центр. Челябинская область максимально схожа с Санкт-Петербургом, степень сходства – 91,6%. В правой стороне окна можно проанализировать демографические коэффициенты для этих двух регионов (рис. 2.6). 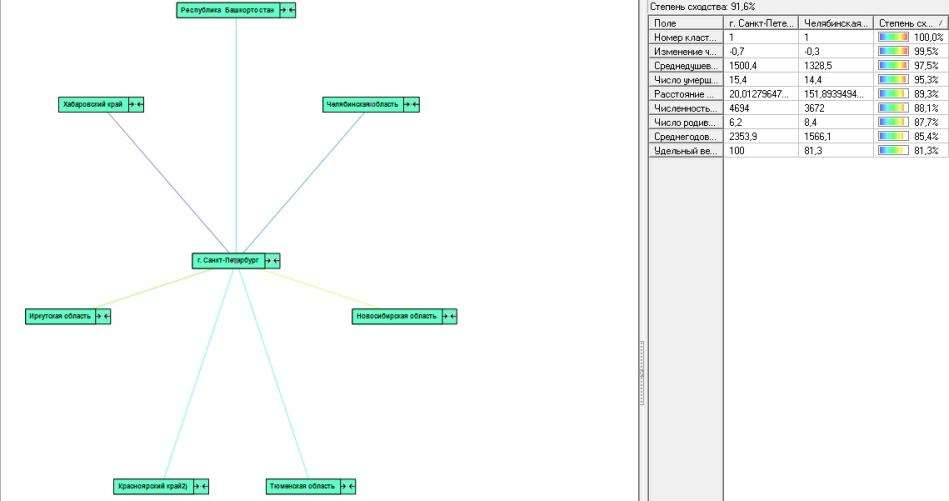 Рис. 2.6 Кластеризация с помощью самоорганизующейся карты Кохонена Самоорганизующаяся карта Кохонена является разновидностью нейронной сети. Она применяется, когда необходимо решить задачу кла- стеризации, т.е. распределить данные по нескольким кластерам. Алгоритм определяет расположение кластеров в многомерном пространстве факто- ров. Исходные данные будут относиться к какому-либо кластеру в зависи- мости от расстояния до него. Многомерное пространство трудно для пред- ставления в графическом виде. Механизм же построения карты Кохонена позволяет отобразить многомерное пространство в двумерном, которое бо- лее удобно и для визуализации и для интерпретации результатов аналити- ком. Рассмотрим механизм кластеризации путем построения самооргани- зующейся карты, основываясь на тех же исходных данных о регионах. Запустите Мастер обработки и выберите метод обработки «Карта Ко- хонена». Все поля кроме Региона (информационное поле) сделать входны- ми. На 3 шаге Мастера необходимо настроить способ разделения исходно- го множества данных на тестовое и обучающее, а также количество приме- ров в том и другом множестве. Укажите, что данные обоих множеств бе- рутся случайным образом. Следующий шаг предлагает настроить параметры карты. Значения по умолчанию вполне подходят. На 5 шаге Мастера также оставим параметры по умолчанию. На 6 шаге настраиваются остальные параметры обучения. Укажем фиксированное количество кластеров – 4. На 7 шаге предлагается запустить сам процесс обучения. Во время обучения можно посмотреть количество распознанных примеров и теку- щие значения ошибок. Нажмите кнопку «Пуск» и дождитесь завершения процесса обработки. После этого требуется в списке визуализаторов выбрать появившуюся теперь Карту Кохонена для просмотра результатов кластеризации и Про- фили кластеров. Далее в Мастере настройки отображения карты Кохонена указать все входные столбцы. В итоге получаем Карту Кохонена (рис. 2.7), позволившую предста- вить многомерное (четырехмерное) пространство входных факторов в дву- мерном виде, который удобнее анализировать. 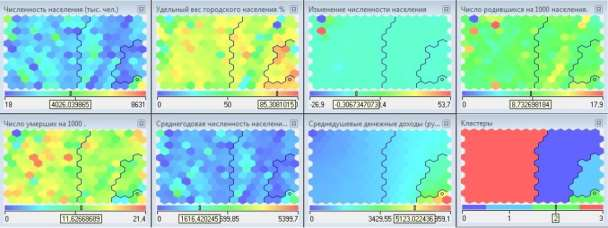 Рис. 2.7 Как и в случае кластеризации методом k-means, видно, что изменение численности населения не влияет на разбиение регионов. Наиболее эффек- тивным кластером является кластер 2, объединяющий в себе возрождаю- щиеся регионы с самыми высокими среднедушевыми доходами и относи- тельно низкой смертностью. Аналогичную информацию предоставляют нам и визуализатор «Профили кластеров». Задание для самостоятельного выполнения 1. Импортировать сценарий «Абоненты.txt», с целью сегментирования абонентов телекоммуникационной компании, предоставляющей на рынке услуги мобильной связи. 2. Используя Карту Кохонена, сегментировать клиентов по семи кластерам. 2.1. На 2 шаге в «Настройках нормализации» для всех полей кроме Возраст и Среднемесячный доход (100%) установить значимость равную 30% + № варианта. 2.2. Тестовое множество не использовать. 2.3. Увеличить размер карты в 1,5 раза. При размере 24х18 она будет иметь количество ячеек 432, в среднем на одну ячейку будет приходиться 10 примеров. 3. Визуализировать данные в виде Связей кластеров, Профилей кластеров и Карты Кохенена и проанализировать результат. 4. Переименовать кластеры задав им следующие названия: Бизнес-люди, Тусовщики, Работающие люди неактивные, Молодежь неактивная, Активная группа зрелого и пенсионного возраста, Группа предпенсионного возраста, неактивная, Группа пенсионного возраста, неактивная. ЛАБОРАТОРНАЯ РАБОТА №3. Поиск ассоциативных правил Цель: изучить алгоритмы поиска ассоциативных правил Методические указания Поиск ассоциативных правил Ассоциативные правила позволяют находить закономерности между связанными событиями. Примером такого правила служит утверждение, что покупатель, приобретающий хлеб, приобретет и молоко. Пусть имеется база данных, состоящая из покупательских транзакций. Каждая транзакция – это набор товаров, купленных покупателем за один визит. Такую транзакцию еще называют рыночной корзиной. Целью анализа является установление следующих зависимостей: если в транзакции встретился некоторый набор элементов X, то на основании этого можно сделать вывод о том, что другой набор элементов Y также должен появиться в этой транзакции. Установление таких зависимостей дает нам возможность находить очень простые и интуитивно понятные правила. Рассмотрим механизм поиска ассоциативных правил на примере данных о продажах товаров в некоторой торговой точке. Данные находятся в файле «Supermarket.txt». В таблице представлена информация по покупкам продуктов нескольких групп. Она имеет всего два поля «Номер чека» и «Товар». Необходимо решить задачу анализа потребительской корзины с целью последующего применения результатов для стимулирования продаж. При импорте сценария указать, что поле «Номер чека» должно быть дискретным. Для поиска ассоциативных правил запустить Мастер обработки и вы- брать тип обработки «Ассоциативные правила». Далее указать, что поле «Номер чека» является идентификатором транзакции, а «Товар» элементом транзакции. Следующий шаг позволяет настроить параметры построения ассоциа- тивных правил: минимальную и максимальную поддержку, минимальную и максимальную достоверность, а также максимальную мощность множе- ства. Исходя из характера имеющихся данных, следует указать границы поддержки – 13% и 80% и достоверности 60% и 90%. После завершения процесса поиска, полученные результаты можно посмотреть, используя появившиеся специальные визуализаторы «Попу- лярные наборы», «Правила», «Дерево правил», «Что-если». Популярные наборы – это множества, состоящие из одного и более элементов, которые наиболее часто встречаются в транзакциях одновре- менно. Насколько часто встречается множество в исходном наборе тран- закций, можно судить по поддержке. Данный визуализатор отображает множества в виде списка (рис. 3.1). Получившиеся наборы товаров наиболее часто покупают в данной торговой точке, следовательно, можно принимать решения о поставках то- варов, их размещении и т.д. 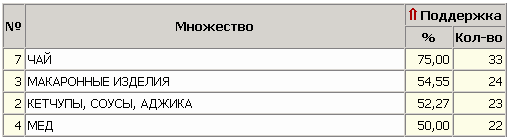 Рис. 3.1 Визуализатор «Правила» отображает ассоциативные правила в виде списка правил (рис. 3.2). Таким образом, эксперту предоставляется набор правил, которые описывают поведение покупателей. 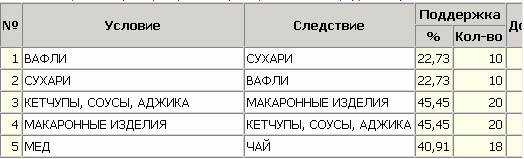 Рис. 3.2 Визуализатор «Дерево правил» – это всегда двухуровневое дерево. Оно может быть построено либо по условию, либо по следствию. При построе- нии дерева правил по условию на первом (верхнем) уровне находятся узлы с условиями, а на втором уровне – узлы со следствием. Второй вариант де- рева правил – дерево, построенное по следствию. Здесь на первом уровне располагаются узлы со следствием. Справа от дерева находится список правил, построенный по выбран- ному узлу дерева. Для каждого правила отображаются поддержка и достоверность. Если дерево построено по условию, то вверху списка отображается условие правила, а список состоит из его следствий. Тогда правила отвечают на вопрос, что будет при таком условии. Если же дерево построено по следствию, то вверху списка отображается следствие правила, а список состоит из его условий. Эти правила отвечают на вопрос, что нужно, чтобы было заданное следствие. В данном случае правила отображены по условию (рис. 3.3). Отображаемый результат можно интерпретировать как 2 правила. 1. Если покупатель приобрел вафли, то он с вероятностью 71% также приобретет сухари. 2. Если покупатель приобрел вафли, то он с вероятностью 64% также приобретет сухари и чай. 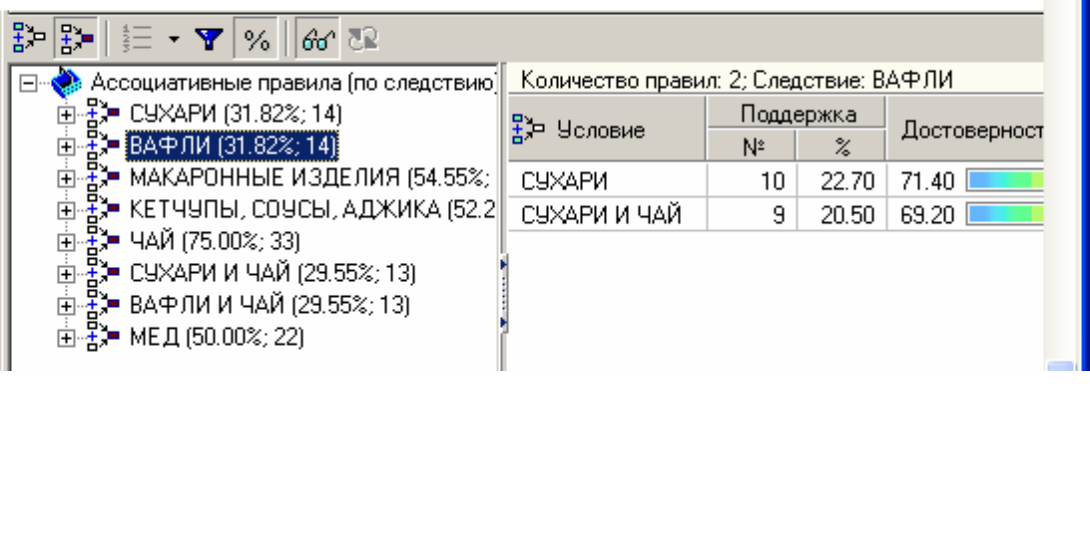 Рис. 3.3 Анализ «Что-если» позволяет ответить на вопрос, что получим в качестве следствия, если выберем данные условия? Например, какие товары приобретаются совместно с выбранными товарами. В окне слева располо- жен список всех элементов транзакций. Справа от каждого элемента указа- на поддержка: сколько раз данный элемент встречается в транзакциях. В правом верхнем углу расположен список элементов, входящих в условие. Это, например, список товаров, которые приобрел покупатель. Для них нужно найти следствие. Например, товары, приобретаемые сов- местно с ними. Чтобы предложить человеку то, что он, возможно, забыл купить. В правом нижнем углу расположен список следствий. Справа от эле- ментов списка отображается поддержка и достоверность. Пусть необходимо проанализировать, что, возможно, забыл покупа- тель приобрести, если он уже взял вафли и мед. Для этого следует добавить в список условий эти товары (например, с помощью двойного щелчка мыши) и затем нажать на кнопку «Вычислить правила» (Ctrl+Enter). При этом в списке следствий появятся товары, совместно приобретаемые с данными. В данном случае появятся «сухари», «чай», «сухари и чай», т. е., может быть, покупатель забыл приобрести сухари, чай или и то и другое (рис.3.4). Таким образом, в данном примере найденные правила можно исполь- зовать для сегментации клиентов на два сегмента: клиенты, покупающие макаронные изделия и соусы к ним, и клиенты, покупающие все к чаю. В разрезе анализа предпочтений можно узнать, что наибольшей популярно- стью в данном магазине пользуются чай, мед, макаронные изделия, кетчу- пы, соусы и аджика. В разрезе размещения товаров в супермаркете можно применить результаты предыдущих двух анализов, т. е. располагать чай рядом с медом, а кетчупы, соусы и аджику рядом с макаронными изделиями и т.д. 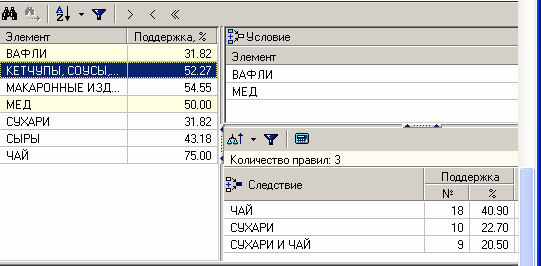 Рис. 3.4 |