отчет. Н. Ф. Гусарова, Н. В
 Скачать 2.27 Mb. Скачать 2.27 Mb.
|

ЦЕЛЬ РАБОТЫРеализовать алгоритм по отбору признаков на выбранном наборе данных. ЗАДАНИЕ НА ПРАКТИЧЕСКУЮ РАБОТУ И ПОРЯДОК ВЫПОЛНЕНИЯВыбрать предметную область и набор данных, согласовать выбор с пре- подавателем. Можно использовать репозиторий ресурса http://archive.ics.uci.edu/ml/. Выбрать алгоритм отбора признаков, согласовать выбор с преподавате- лем. Реализовать алгоритм по отбору признаков на выбранном наборе дан- ных. Выбор способа реализации алгоритма предоставляется студенту. Проверить качество реализованного отбора признаков с помощью од- ного из критериев. ПРИМЕР ВЫПОЛНЕНИЯ РАБОТЫДля выполнения лабораторной работы был выбран датасет, содержа- щий показатели исследуемых пациентов, у которых был диагностирован рак молочной железы. Датасет взят из архива UCI: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Coimbra#. Описание отобранного датасета: Существует 10 предикторов, все количественные, и бинарная зави- симая переменная, указывающая на наличие или отсутствие рака молочной железы. Предикторами являются антропометрические данные и параметры, которые могут быть собраны при анализе крови. Атрибуты: Age (years) – возраст. BMI (kg/m2) – индекс массы тела. Glucose (mg/dL) – уровень сахара в крови. Insulin (µU/mL) – содержание инсулина в организме. HOMA – индекс инсулинорезистентности. Leptin (ng/mL) – содержание лептина в организме. Adiponectin (µg/mL) – гормон адипонектин. Resistin (ng/mL) – гормон резистин. 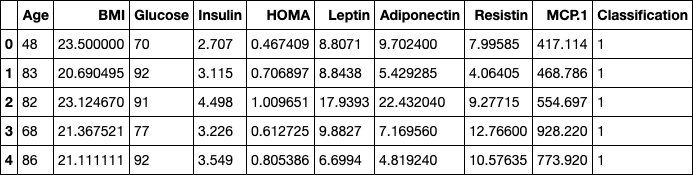 MCP-1(pg/dL) – содержание компонента MCP-1. MCP-1(pg/dL) – содержание компонента MCP-1.Рис. 2.1. Пример данных из датасета Импортируем необходимые модули и библиотеки:  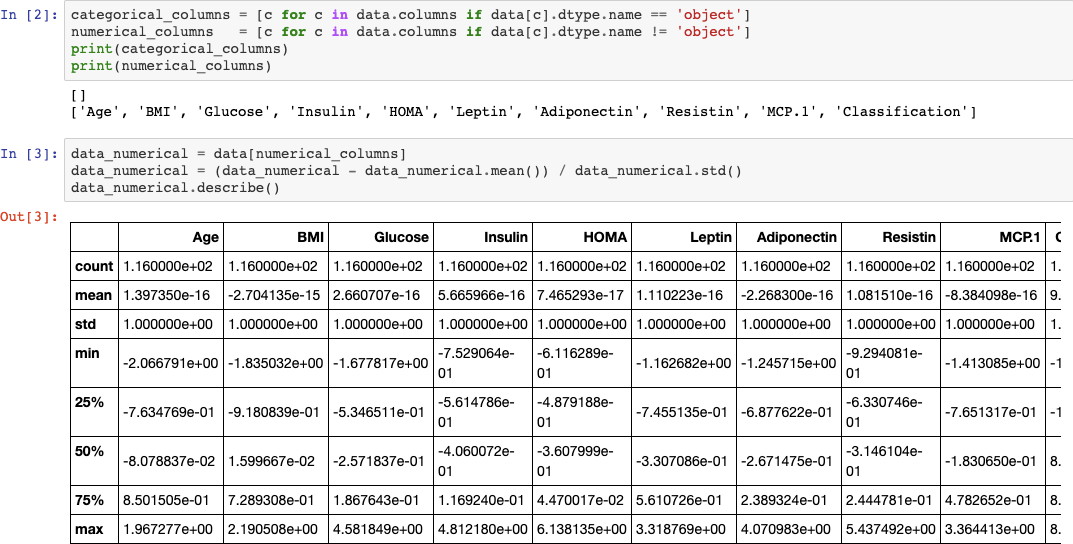 Для работы с данными осуществим необходимые преобразования: Для работы с данными осуществим необходимые преобразования:Отбор признаков будем осуществлять на основе их важности. Пер- вым методом выберем линейную регрессию. Используем функцию Line- arRegression. Для оценки точности алгоритма линейной регрессии будем ис- пользовать RMSE. 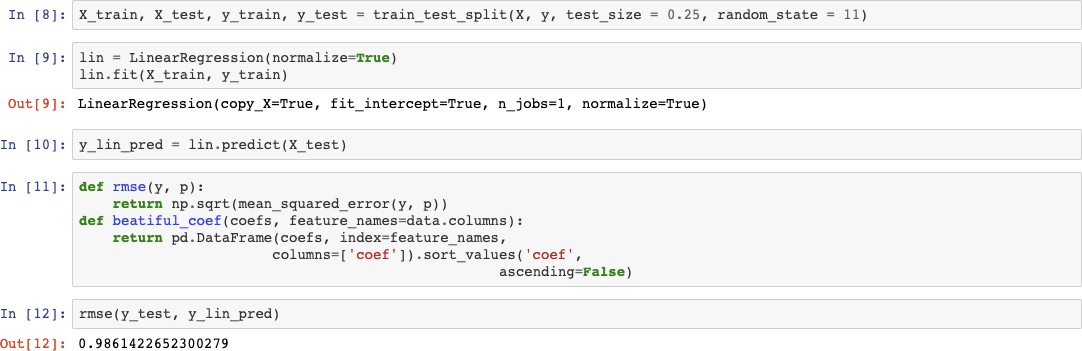 Полученный коэффициент точности равен 0,98614. В результате проделанной работе получили следующий результат: 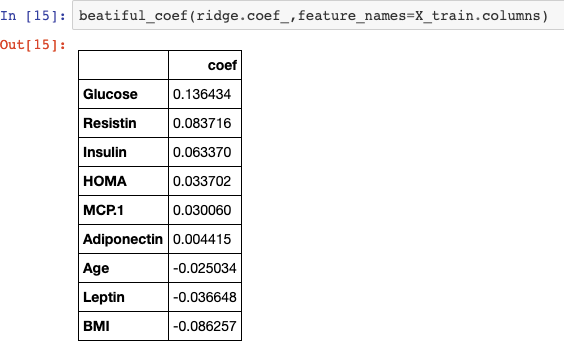 Самыми показательными параметрами получились содержание са- хара в крови и гормон резистин.В качестве второго метода для отбора при- знаков выберем метод случайного леса. Ансамблевые алгоритмы на основе деревьев решений, такие как слу- чайный лес (random forest), позволяют оценить важность признаков. 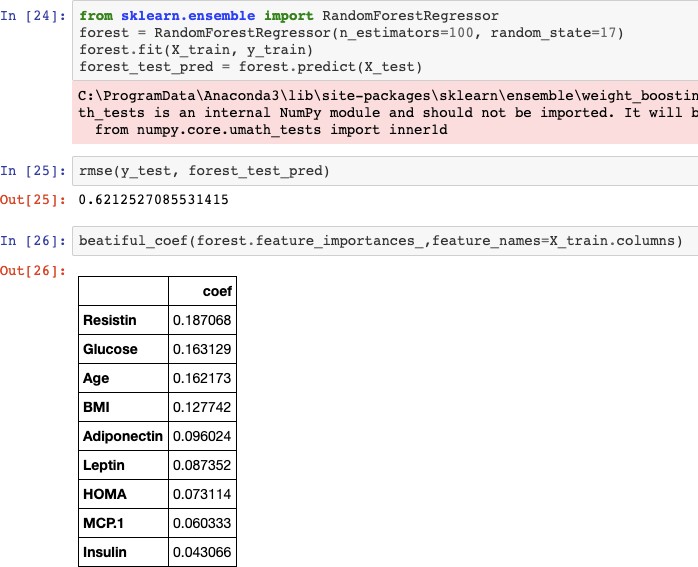 В результате выявили два важных признака: резистин и содержание сахара в крови. Получили результат RMSE равный 0.6213, что намного меньше в сравнении с оценкой алгоритма линейной регрессии. Значит, ме- тод случайного леса является более точным для отбора признаков. |