|
|
лекции по эконометрике. Основные понятия и определения эконометрики
Рассмотрим модели: 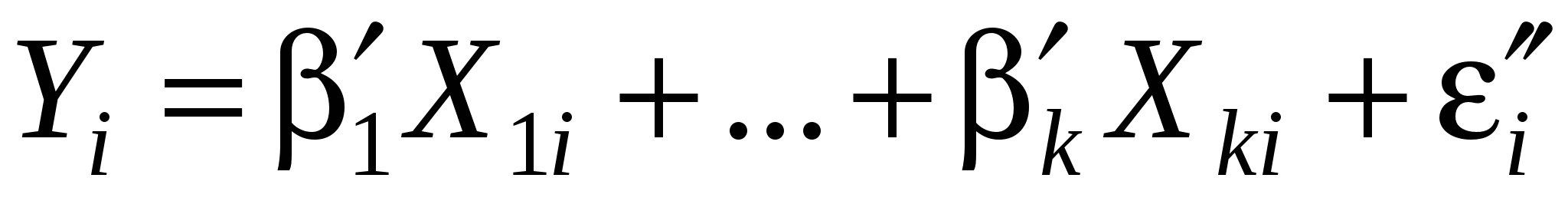 , i=1,…,N (1); , i=1,…,N (1);  , i=N+1,…,N+M (2). , i=N+1,…,N+M (2).
В первой выборке N наблюдений, во второй – М наблюдений. Пример: Y – заработная плата, объясняющие переменные – возраст, стаж, уровень образования. Следует ли из имеющихся данных, что модель зависимости заработной платы от объясняющих переменных, стоящих в правой части одинакова для мужчин и женщин?
Н0: 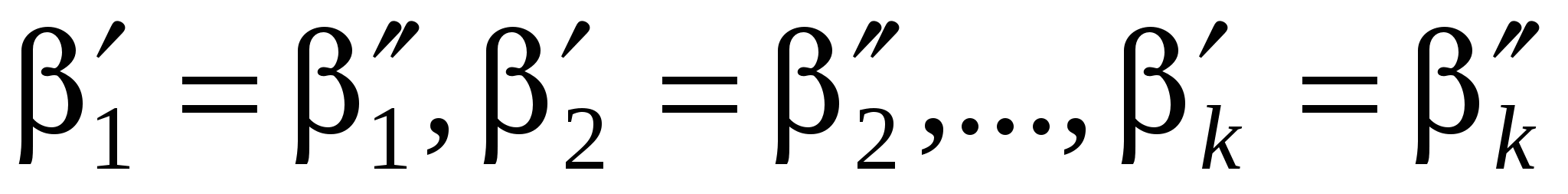
Для проверки этой гипотезы можно воспользоваться общей схемой проверки гипотез при помощи сравнения регрессии с ограничениями и регрессии без ограничений. Регрессией без ограничений здесь является объединение регрессий (1) и (2), т. е. ESSUR = ESS1 + ESS2, число степеней свободы – N + M - 2k. Регрессией с ограничениями (т. е. регрессией в предположении, что выполнена нулевая гипотеза) будет являться регрессия  для всего имеющегося набора наблюдений: для всего имеющегося набора наблюдений:
, i = 1,…, N+M (3).
Оценивая (3), получаем ESSR. Для проверки нулевой гипотезы используем следующую статистику:
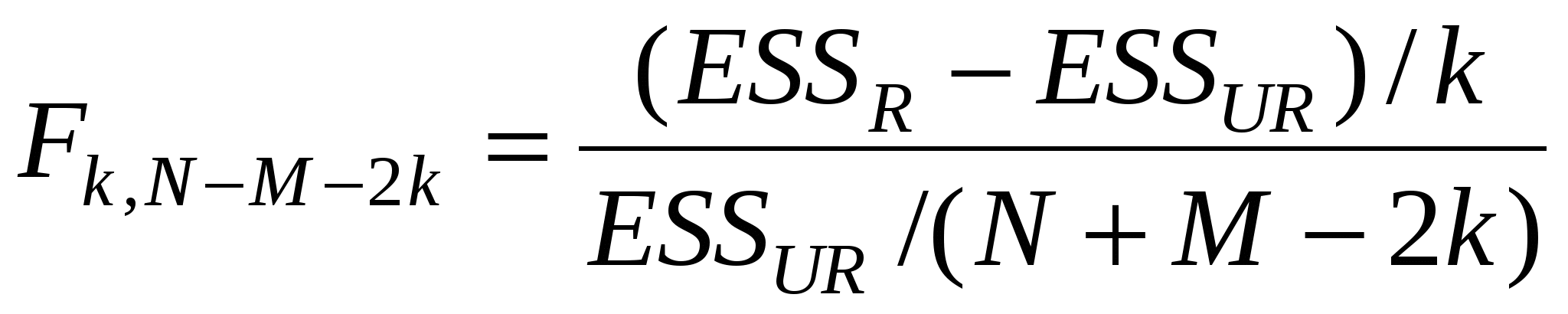 , которая в случае справедливости нулевой гипотезы имеет распределение Фишера с числом степеней свободы числителя k и знаменателя N+ M- 2k. , которая в случае справедливости нулевой гипотезы имеет распределение Фишера с числом степеней свободы числителя k и знаменателя N+ M- 2k.
Если нулевая гипотеза справедлива, мы можем объединить имеющиеся выборки в одну и оценивать модель для N+M наблюдений. Если же нулевую гипотезу отвергаем, то мы не можем слить две выборки в одну, и нам придется оценивать эти две модели по отдельности.
Изучение общей линейной модели, рассмотренной нами ранее, весьма существенно, как мы видели, опирается на статистический аппарат. Однако, как и во всех приложениях мат. статистики, сила метода зависит от предположений, лежащих в его основе и необходимых для его применения. Некоторое время мы будем рассматривать ситуации, когда одна или более гипотез, лежащих в основе линейной модели, нарушается. Мы рассмотрим альтернативные методы оценивания в этих случаях. Мы увидим, что роль одних гипотез более существенна по сравнению с ролью других. Нам надо посмотреть, к каким последствиям может привести нарушения тех или иных условий (предположений), уметь проверить, удовлетворяются они или нет и знать, какие статистические методы можно и целесообразно применять, когда не подходит классический метод наименьших квадратов.
Связь между переменными линейная и выражается уравнением 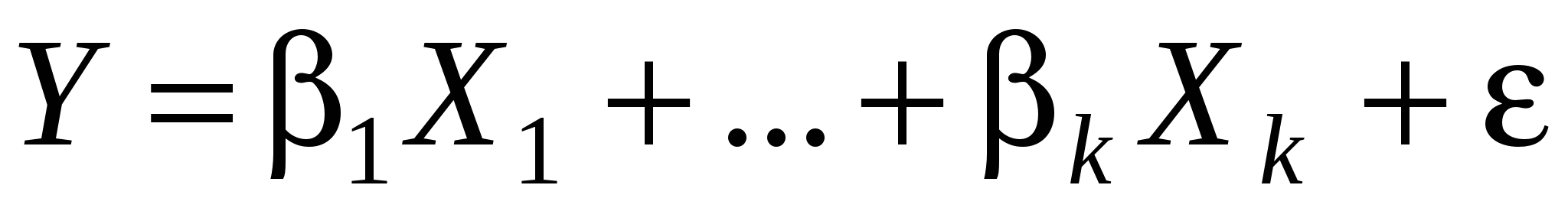 - ошибки спецификации модели (невключение в уравнение существенных объясняющих переменных, включение в уравнение лишних переменных, неправильный выбор формы зависимости между переменными); - ошибки спецификации модели (невключение в уравнение существенных объясняющих переменных, включение в уравнение лишних переменных, неправильный выбор формы зависимости между переменными);
X1,…,Xk – детерминированные переменные – стохастические регрессоры, линейно независимые – полная мультиколлинеарность;
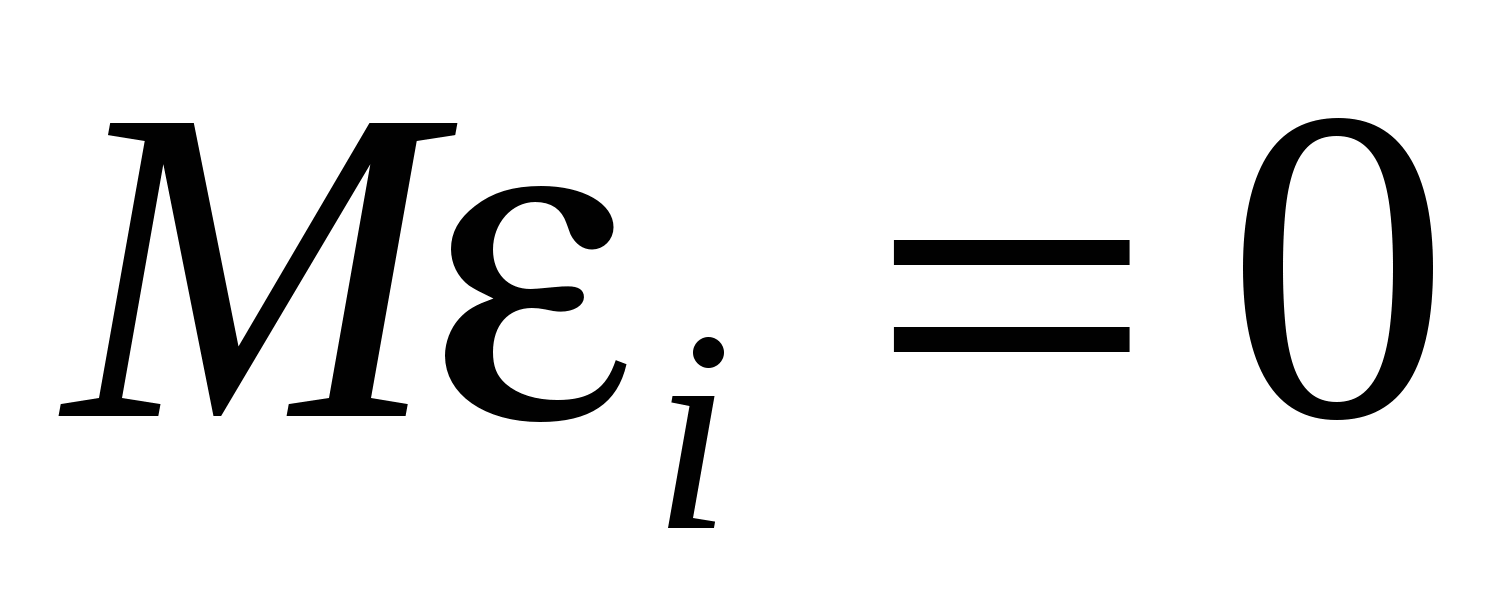 ; ;
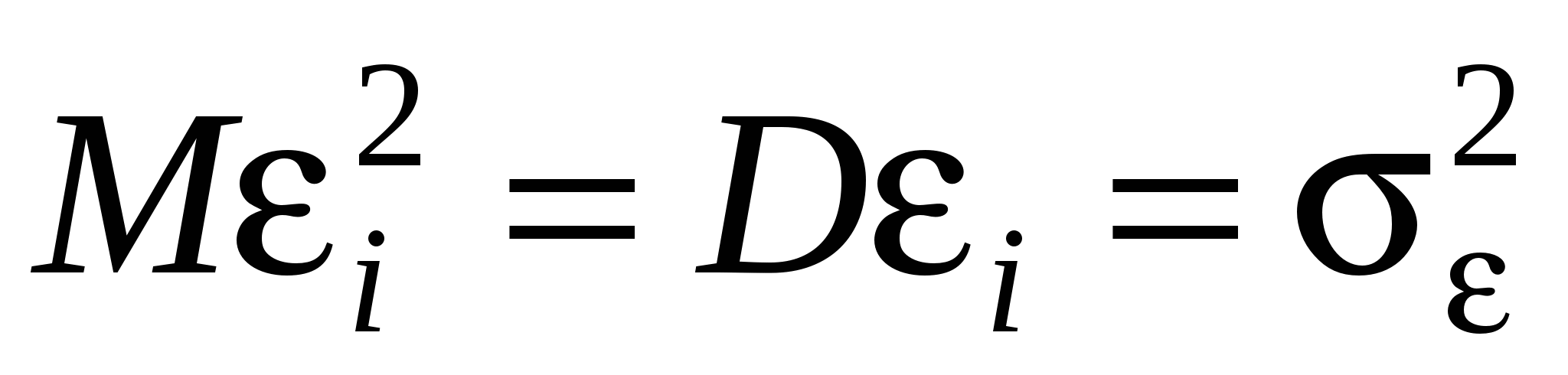 - гетероскедастичность; - гетероскедастичность;
5. 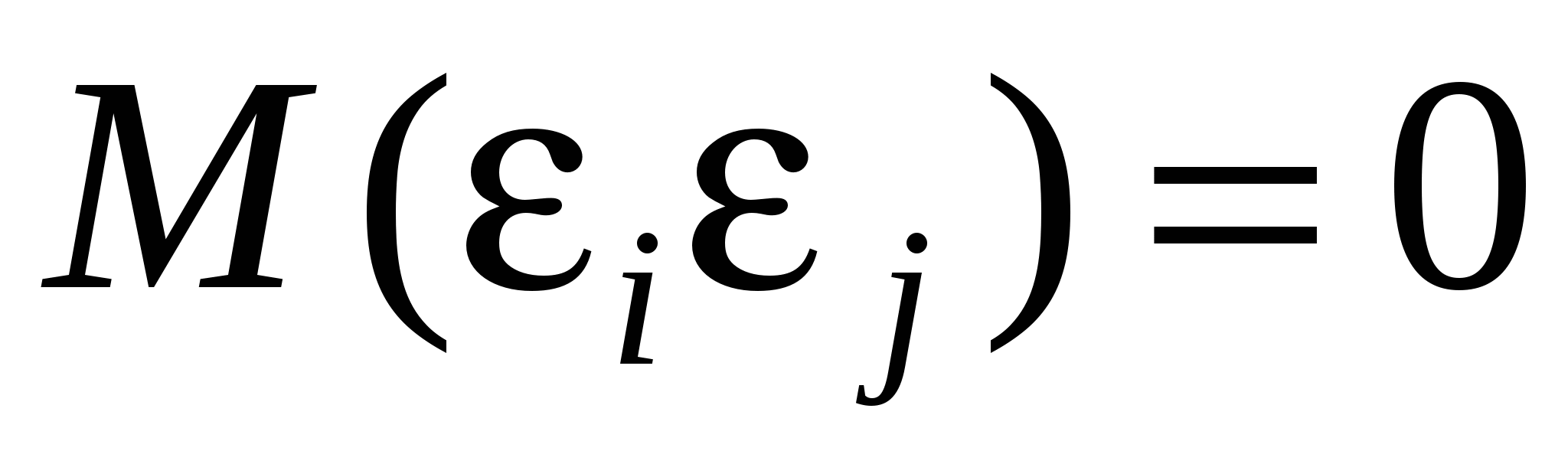 при i k – автокорреляция ошибок при i k – автокорреляция ошибок
Прежде чем приступать к разговору, рассмотрим следующие понятия: парный коэффициент корреляции и частный коэффициент корреляции.
Предположим, что мы исследуем влияние одной переменной на другую переменную (Y и X). Для того чтобы понять, насколько эти переменные связаны между собой, мы вычисляем парный коэффициент корреляции по следующей формуле:
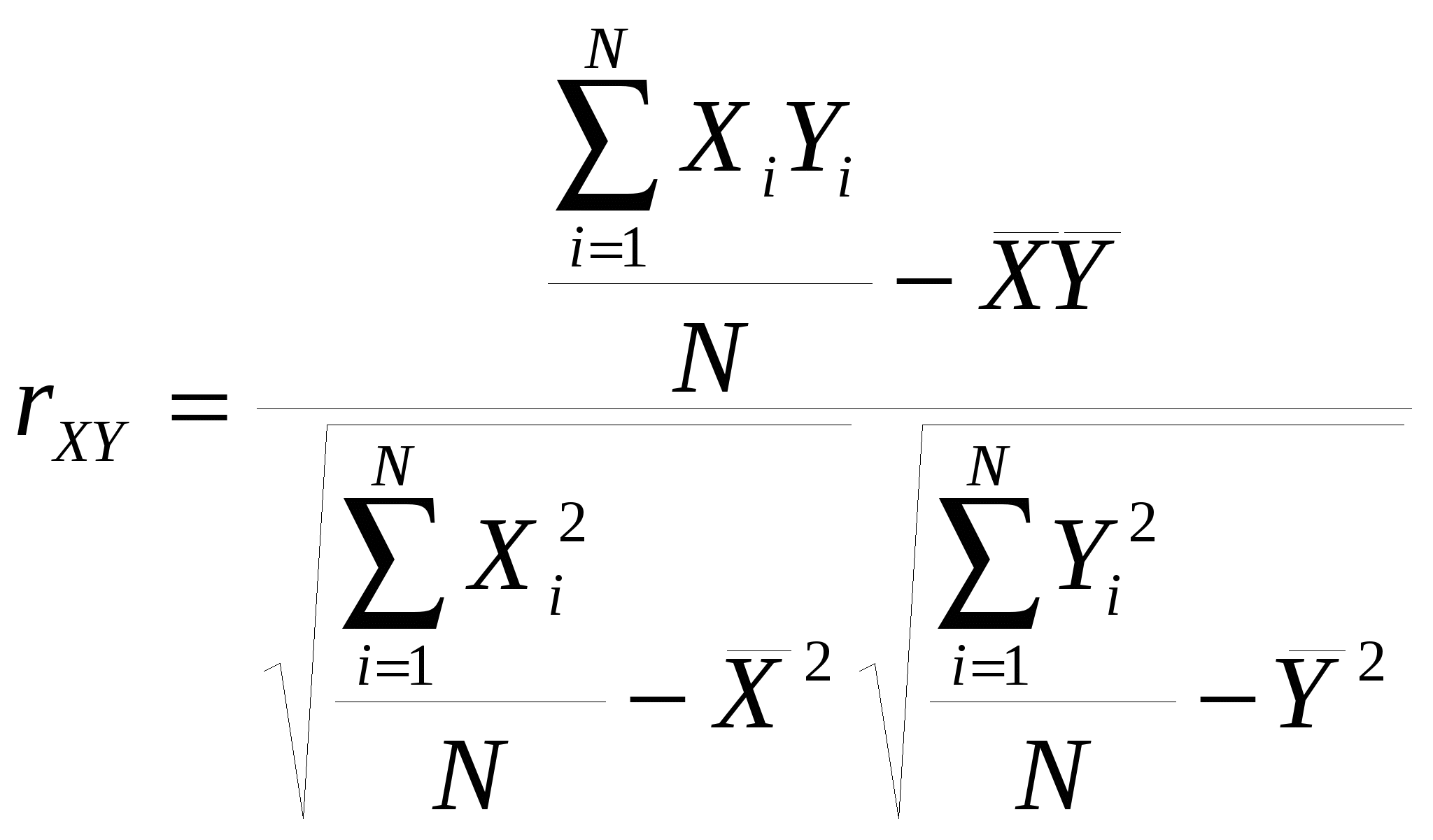
Если мы получили значение коэффициента корреляции близкое к 1, мы делаем вывод о том, что переменные достаточно сильно связаны между собой.
Однако, если коэффициент корреляции между двумя исследуемыми переменными близок к 1, на самом деле они могут и не быть зависимыми. Пример с душевнобольными и радиоприемниками – пример так называемой «ложной корреляции». Высокое значение коэффициента корреляции может быть обусловлено и существованием третьей переменной, которая оказывает сильное влияние на первые две переменные, что и служит причиной их высокой коррелируемости. Поэтому возникает задача расчета «чистой» корреляции между переменными X и Y, т. е. корреляции, в которой исключено влияние (линейное) других переменных. Для этого и вводят понятие коэффициента частной корреляции.
Итак, мы хотим определить коэффициент частной корреляции между переменными X и Y, исключив линейное влияние переменной Z. Для его определения используется следующая процедура:
Оцениваем регрессию 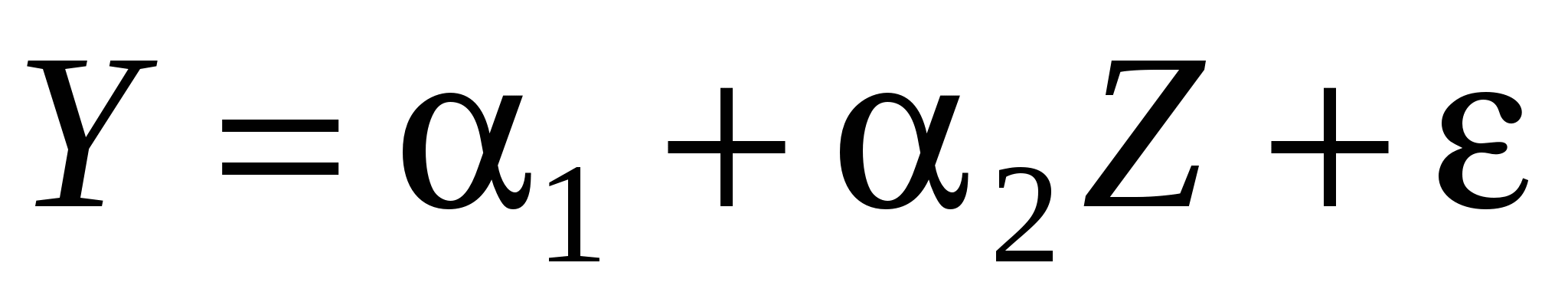 , ,
Получаем остатки 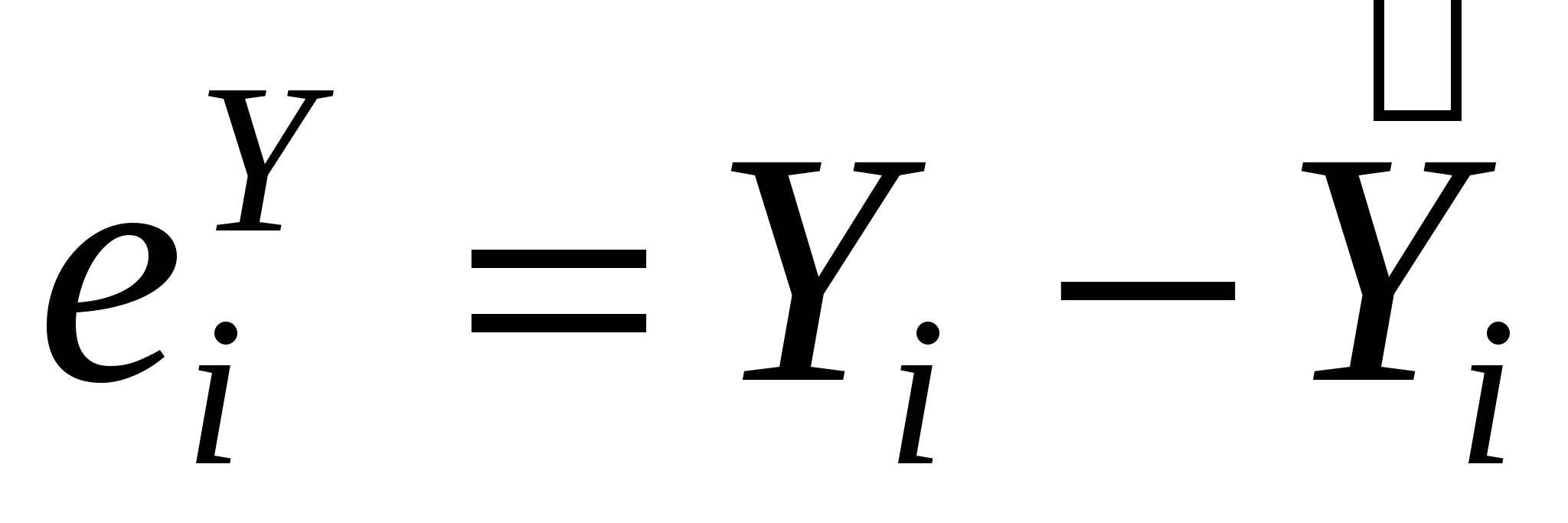 , ,
Оцениваем регрессию 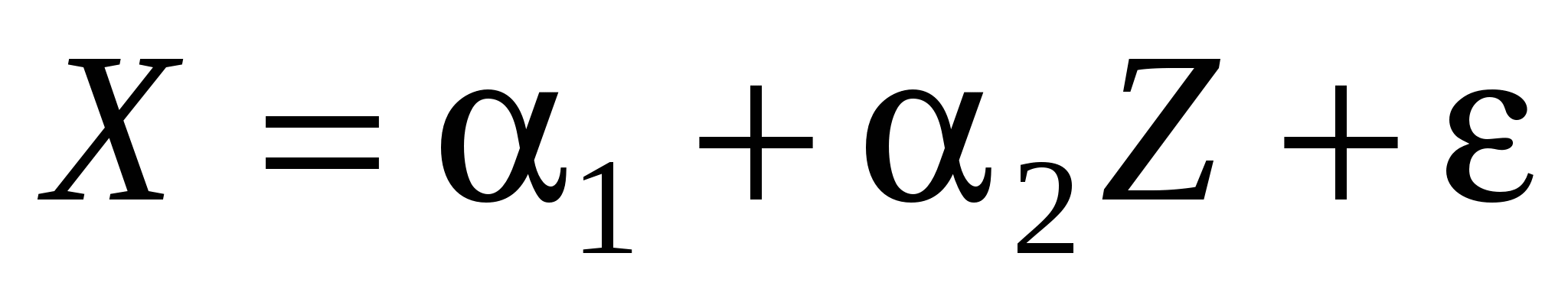 , ,
Получаем остатки 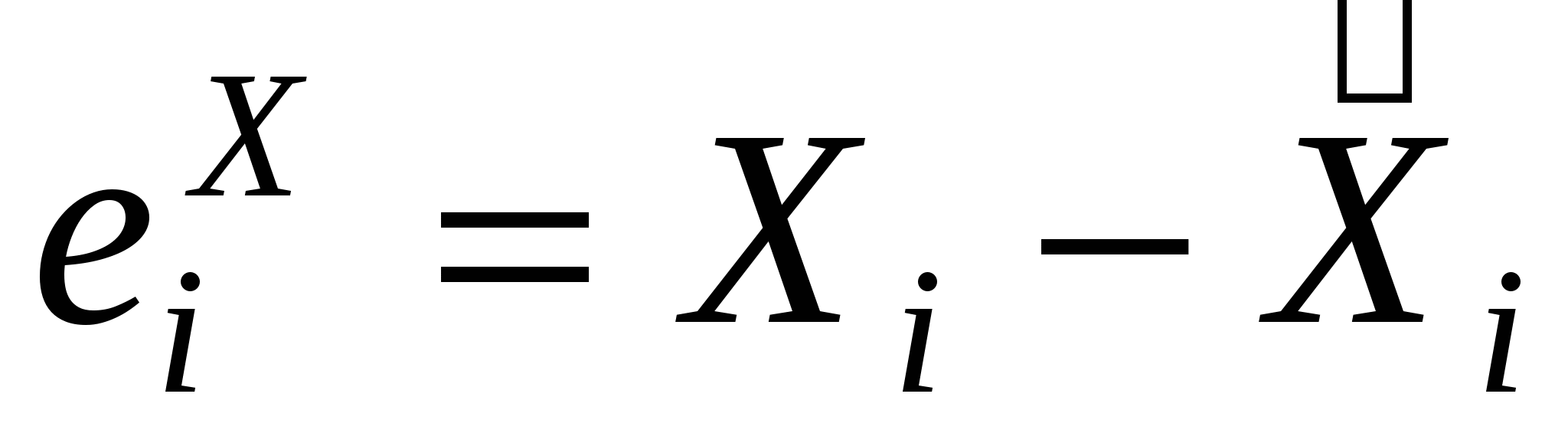 , ,
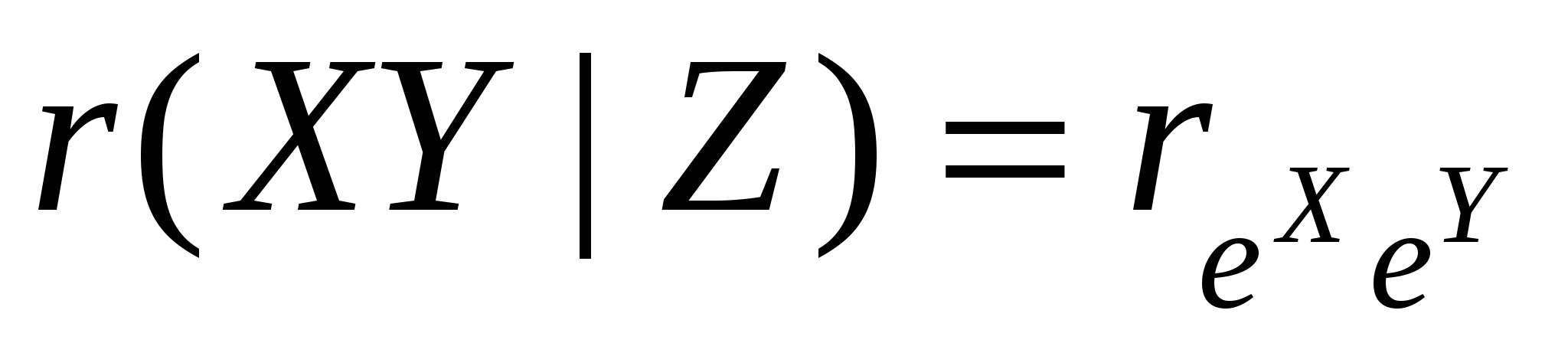 - выборочный коэффициент частной корреляции, измеряет степень связи между переменными X и Y, очищенную от влияния переменной Z. - выборочный коэффициент частной корреляции, измеряет степень связи между переменными X и Y, очищенную от влияния переменной Z.
Прямые вычисления:
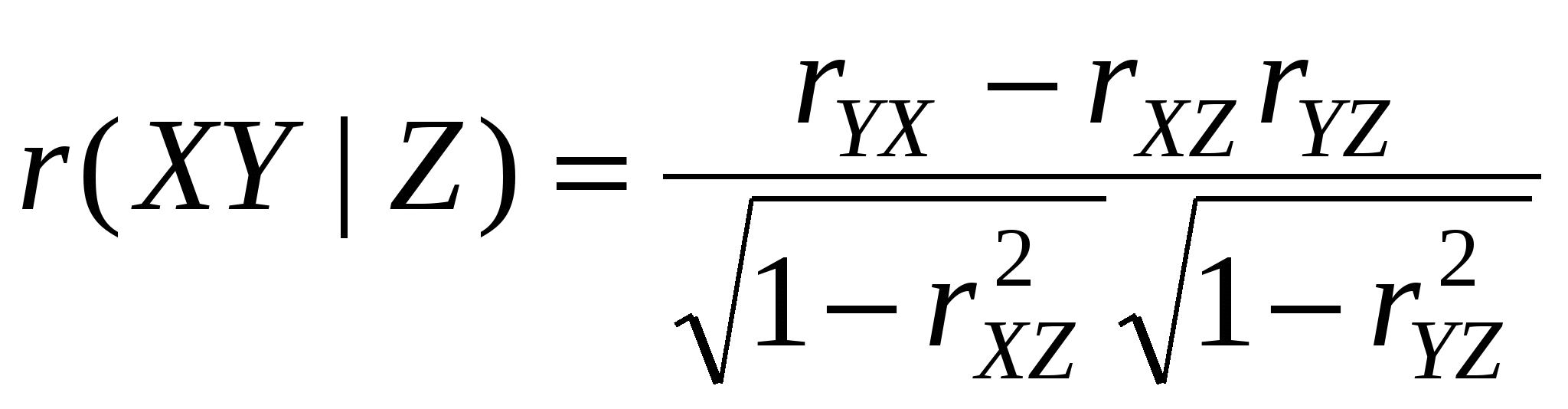
Свойство: 
Процедура построения коэффициента частной корреляции обобщается на случай, если мы хотим избавиться от влияния двух и более переменных.
6. МУЛЬТИКОЛЛИНЕАРНОСТЬ.
Совершенная мультиколлинеарность.
Одно из требований Гаусса-Маркова говорит нам о том, чтобы объясняющие переменные не были связаны никаким точным соотношением. Если такое соотношение между переменными существует, мы говорим о том, что в модели присутствует совершенная мультиколлинеарность. Пример. Рассмотрим модель со средней оценкой на экзамене, состоящую из трех объясняющих переменных: I доход родителей, D среднее число часов, затраченных на обучение в день, W среднее число часов, затраченных на обучение в неделю. Очевидно, что W=7D. И это соотношение будет выполняться для каждого студента, который попадет в нашу выборку. Случай полной мультиколлинеарности отследить легко, поскольку в этом случае невозможно построить оценки по методу наименьших квадратов.
Частичная мультиколлинеарность или просто мультиколлинеарность.
Гораздо чаще встречается ситуация, когда между объясняющими переменными точной линейной зависимости не существует, но между ними существует тесная корреляционная зависимость – этот случай носит название реальной или частичной мультиколлинеарности (просто мультиколлинеарность) – существование тесных статистических связей между переменными. Надо сказать, что вопрос мультиколлинеарности – это вопрос скорее степени выраженности явления, а не его вида. Оценка любой регрессии будет страдать от нее в том или ином виде, если только все независимые переменные не окажутся абсолютно некоррелированными. Рассмотрение данной проблемы начинается только тогда, когда это начинает серьезно влиять на результаты оценки регрессии (наличие статистических связей между регрессорами вовсе не обязательно дает неудовлетворительные оценки). Итак, мультиколлинеарность – это проблема, когда тесная корреляционная зависимость между регрессорами ведет к получению ненадежных оценок регрессии.
Последствия мультиколлинеарности:
Формально, поскольку (X'X) – невырожденная, то мы можем построить МНК-оценки коэффициентов регрессии. Однако вспомним, как выражаются теоретические дисперсии оценок коэффициентов регрессии: 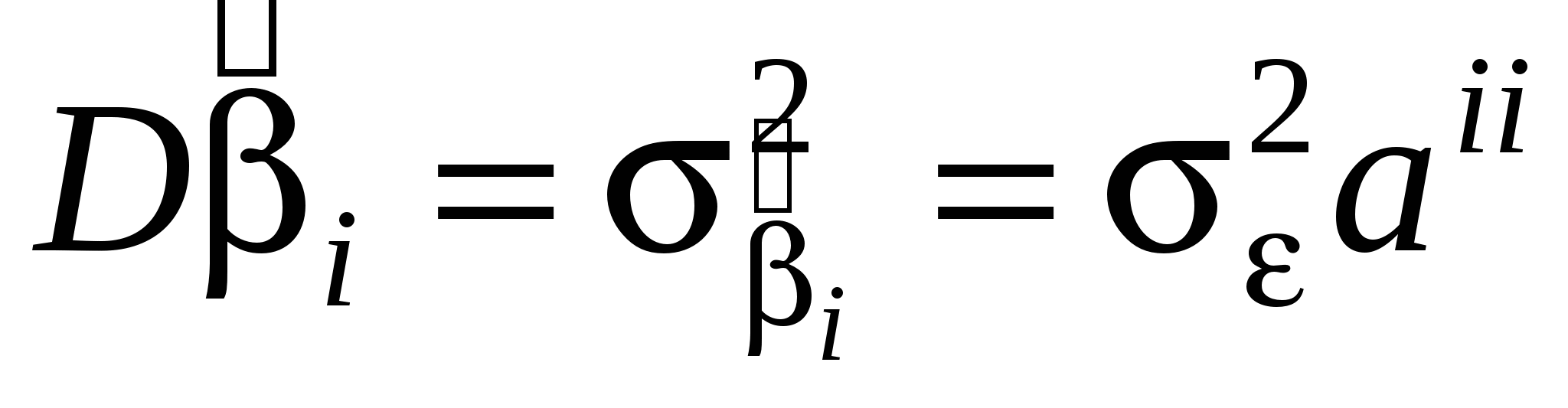 , где aii - i-й диагональный элемент матрицы , где aii - i-й диагональный элемент матрицы 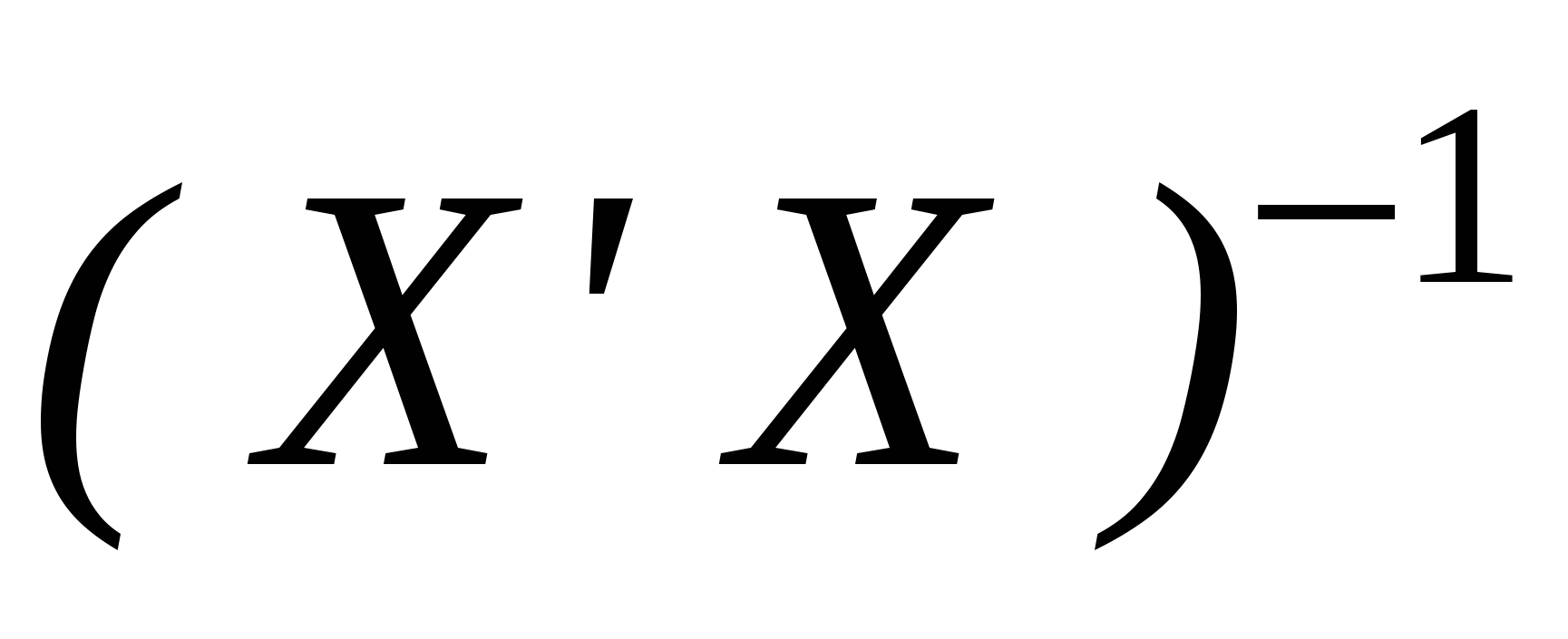 . Поскольку матрица (X'X) близка к вырожденной и det(X'X) 0, то . Поскольку матрица (X'X) близка к вырожденной и det(X'X) 0, то
1) на главной диагонали обратной матрицы стоят очень большие числа, поскольку элементы обратной матрицы обратно пропорциональны det(X'X). Следовательно, теоретическая дисперсия i-го коэффициента достаточно большая и оценка дисперсии 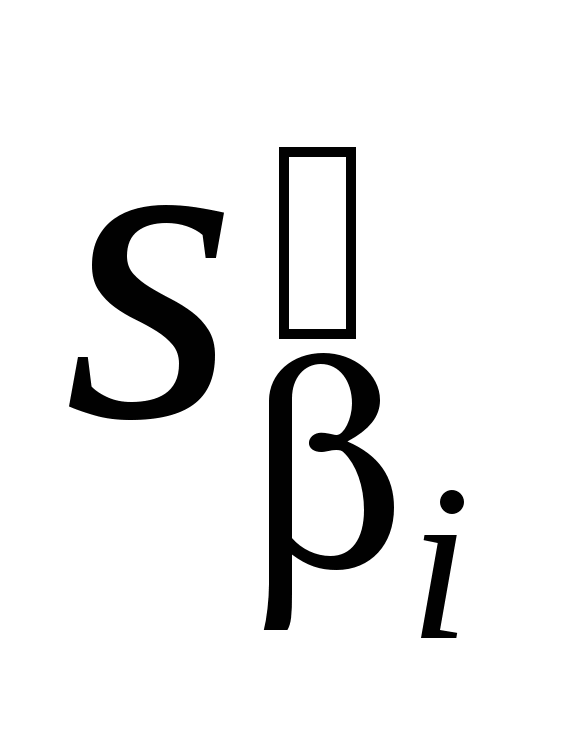 так же большая, следовательно, t- статистики небольшие, что может привести к статистической незначимости i-го коэффициента. Т. е. переменная оказывает значимое влияние на объясняемую переменную, а мы делаем вывод о ее незначимости. так же большая, следовательно, t- статистики небольшие, что может привести к статистической незначимости i-го коэффициента. Т. е. переменная оказывает значимое влияние на объясняемую переменную, а мы делаем вывод о ее незначимости.
2) Поскольку оценки 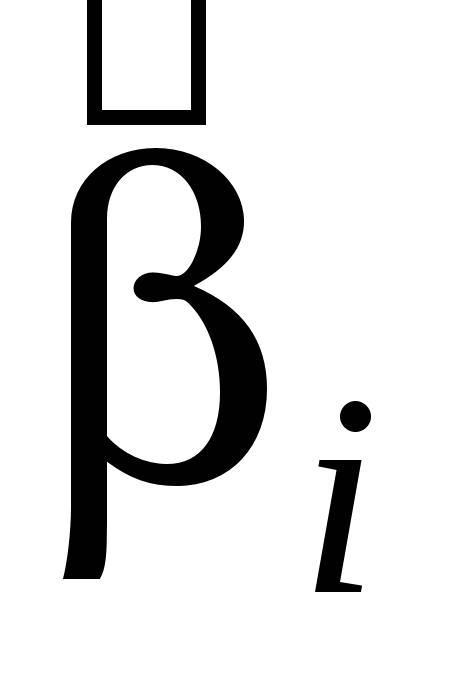 и зависят от (X'X)-1, элементы которой обратно пропорциональны det(X'X), то если мы добавим или уберем одно-два наблюдения, добавив или убрав, таким образом, одну-две строки к матрице X'X, то значения и могут измениться существенным образом, вплоть до смены знака – неустойчивость результатов оценивания. и зависят от (X'X)-1, элементы которой обратно пропорциональны det(X'X), то если мы добавим или уберем одно-два наблюдения, добавив или убрав, таким образом, одну-две строки к матрице X'X, то значения и могут измениться существенным образом, вплоть до смены знака – неустойчивость результатов оценивания.
3) Трудность интерпретации уравнения регрессии. Допустим, у нас в уравнении есть две переменные, которые связаны между собой между собой: X1 и X2. Коэффициент регрессии при X1 интерпретируется как мера изменения Y за счет изменения X1 при прочих равных условиях, т.е. значения всех других переменных остаются прежними. Однако, поскольку переменные Х1 и Х2 связаны, то изменения в переменной Х1 повлекут за собой предсказуемые изменения в переменной Х2 и значение Х2 не останется прежним.
Пример:  , где Х1 – общая площадь, Х2 – жилая площадь. Мы говорим: "Если жилая площадь увеличиться на 1 кв. м., то при прочих равных условиях цена квартиры увеличиться на , где Х1 – общая площадь, Х2 – жилая площадь. Мы говорим: "Если жилая площадь увеличиться на 1 кв. м., то при прочих равных условиях цена квартиры увеличиться на 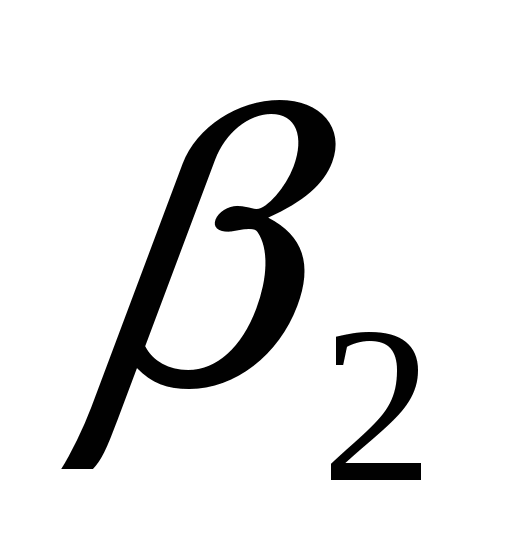 долл". Однако в этом случае и жилая площадь увеличится на 1 кв. м. и прирост цены будет долл". Однако в этом случае и жилая площадь увеличится на 1 кв. м. и прирост цены будет 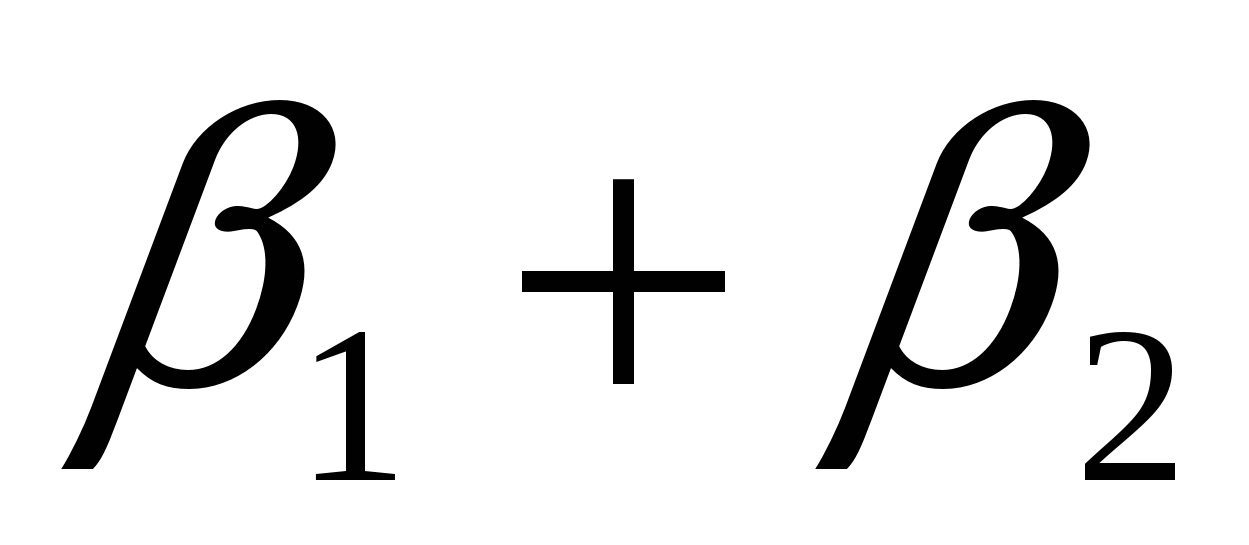 . Разграничить влияние на переменную Y каждой переменной в отдельности уже не представляется возможным. Выход в данной ситуации с ценой на квартиру -–включить в модель не общую площадь, а так называемую "добавочную" или "дополнительную" площадь. . Разграничить влияние на переменную Y каждой переменной в отдельности уже не представляется возможным. Выход в данной ситуации с ценой на квартиру -–включить в модель не общую площадь, а так называемую "добавочную" или "дополнительную" площадь.
Признаки мультиколлинеарности.
Точных критериев для определения наличия (отсутствия) мультиколлинеарности не существует. Однако есть эвристические рекомендации по ее выявлению:
Анализируют матрицу парных коэффициентов корреляции между регрессорами и если значение коэффициента корреляции близко к 1, то это считается признаком мультиколлинеарности.
Анализ матрицы корреляции – лишь поверхностное суждение о наличии (отсутствии) мультиколлинеарности. Более внимательное изучение этого вопроса достигается при помощи расчета коэффициентов частной корреляции или расчетов коэффициентов детерминации каждой из объясняющих переменных по всем другим объясняющим переменным в регрессии 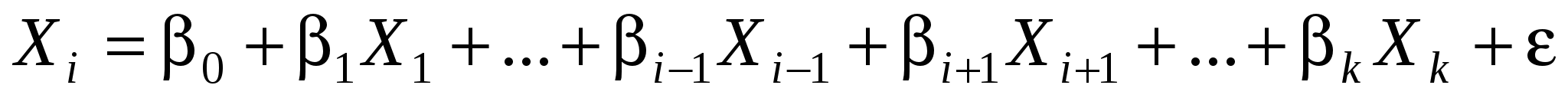 . .
Можно посчитать определитель матрицы (Х’X) и если он близок к нулю, то это тоже свидетельствует о наличии мультиколлинеарности.
(Х’X) – симметричная положительно определенная матрица, следовательно, все ее собственные числа неотрицательны. Если определитель матрицы (Х’X) равен нулю, то минимальное собственное число так же ноль и непрерывность сохраняется. Следовательно, по значению манимального собственного числа  можно судить и о близости к нулю определителя матрицы (Х’X). Кроме этого свойства минимальное собственное число важно еще и потому, что стандартная ошибка коэффициента обратно пропорциональна . можно судить и о близости к нулю определителя матрицы (Х’X). Кроме этого свойства минимальное собственное число важно еще и потому, что стандартная ошибка коэффициента обратно пропорциональна .
О наличии мультиколлинеарности можно судить по внешним признакам, являющимся следствиями мультиколлинеарности:
некоторые из оценок имеют неправильные с точки зрения экономической теории знаки или неоправданно большие значения;
небольшое изменение исходных экономических данных приводит к существенному изменению оценок коэффициентов модели;
большинство t-статистик коэффициентов незначимо отличаются от нуля, в то же время модель в целом является значимой, о чем говорит высокое значение F-статистики.
Как избавится от мультиколлинеарности, как ее устранить:
Использование факторного анализа. Переход от исходного набора регрессоров, среди которых есть статистически зависимые, к новым регрессорам Z1,…,Zm при помощи метода главных компонент – вместо исходных переменных вместо исходных переменных рассматриваем некоторые их линейные комбинации, корреляция между которыми мала или отсутствует вообще. Задача здесь – дать содержательную интерпретацию новым переменным Z. Если не удалось – возвращаемся к исходным переменным, используя обратные преобразования. Полученные оценки будут, правда, смещенными, но будут иметь меньшую дисперсию.
Среди всех имеющихся переменных отобрать наиболее существенно влияющих на объясняемую переменную факторов. Процедуры отбора будут рассмотрены ниже.
Переход к смещенным методам оценивания.
Когда мы сталкиваемся с проблемой мультиколлинеарности, то у неискушенного исследователя поначалу возникает желание просто исключить лишние регрессоры, которые, возможно, служат ее причиной. Однако не всегда ясно, какие именно переменные являются лишними в указанном смысле. Кроме того, как будет показано ниже, отбрасывание так называемых существенно влияющих переменных приводит к смещенности МНК-оценок.
7. ОШИБКИ СПЕЦИФИКАЦИИ
Построение экономической модели включает в себя спецификацию ее соотношений, выбор переменных, входящих в соотношение, определение математической функции, входящей в каждое соотношение. В данном пункте мы рассмотрим второй элемент.
Если точно известно, какая переменная должна быть включена в уравнение, то наша задача состоит в определении коэффициентов, построении доверительных интервалов, проверке различных гипотез. На практике мы никогда не можем быть уверены, что уравнение специфицировано правильно. Что случится, если мы включим в уравнение переменные, которых там быть не должно, и что случится, если мы не включим в уравнение переменные, которые там должны присутствовать. Свойства оценок коэффициентов в значительной степени зависят от правильности спецификации модели.
Ошибки спецификации бывают двух видов:
невключение в уравнение существенной объясняющей переменной;
включение в уравнение переменной, которая не должна там присутствовать.
3) неправильный выбор формы зависимости между переменными, мы предположили, что модель линейная, а она может быть более сложной.
1. Влияние отсутствия в уравнении переменной, которая должна быть включена.
Рассмотрим ситуацию для случая двух переменных.
Истинная модель выглядит следующим образом: 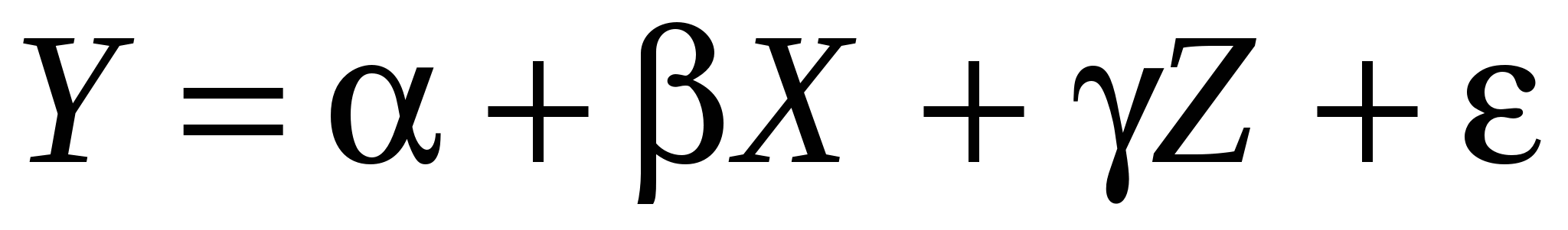 . Но мы не уверены в значимости Z, поэтому оцениваем «короткую» модель: . Но мы не уверены в значимости Z, поэтому оцениваем «короткую» модель: 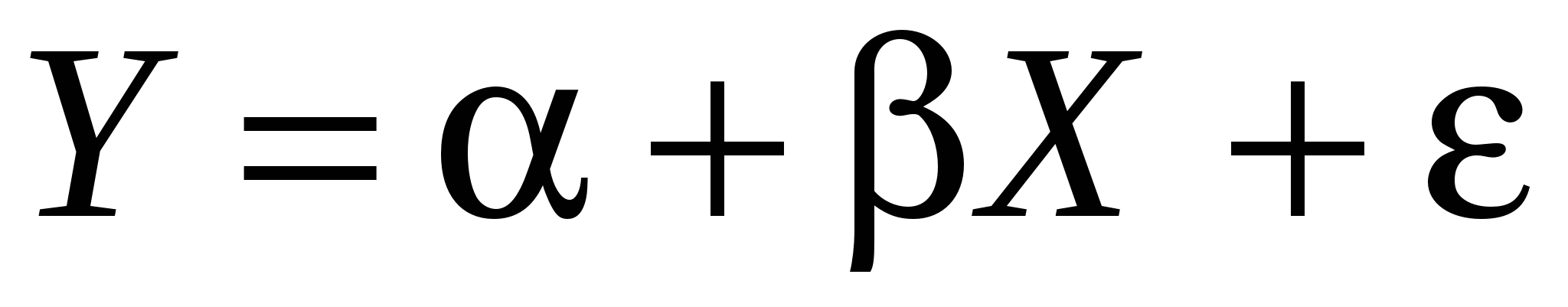 . По методу наименьших квадратов вычисляем . По методу наименьших квадратов вычисляем  : :
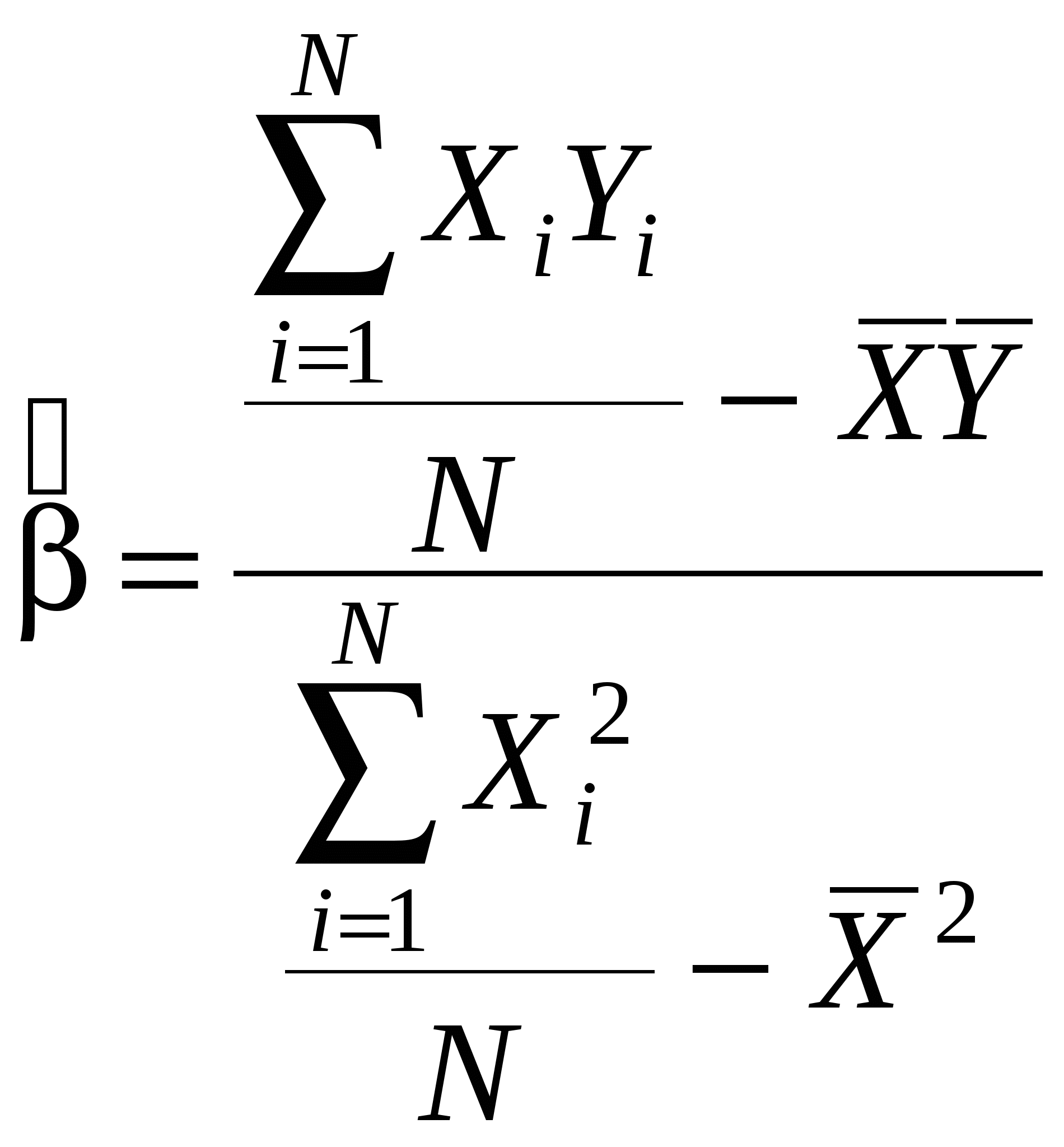
- несмещенная оценка , если M = . Посчитаем, чему равно M:
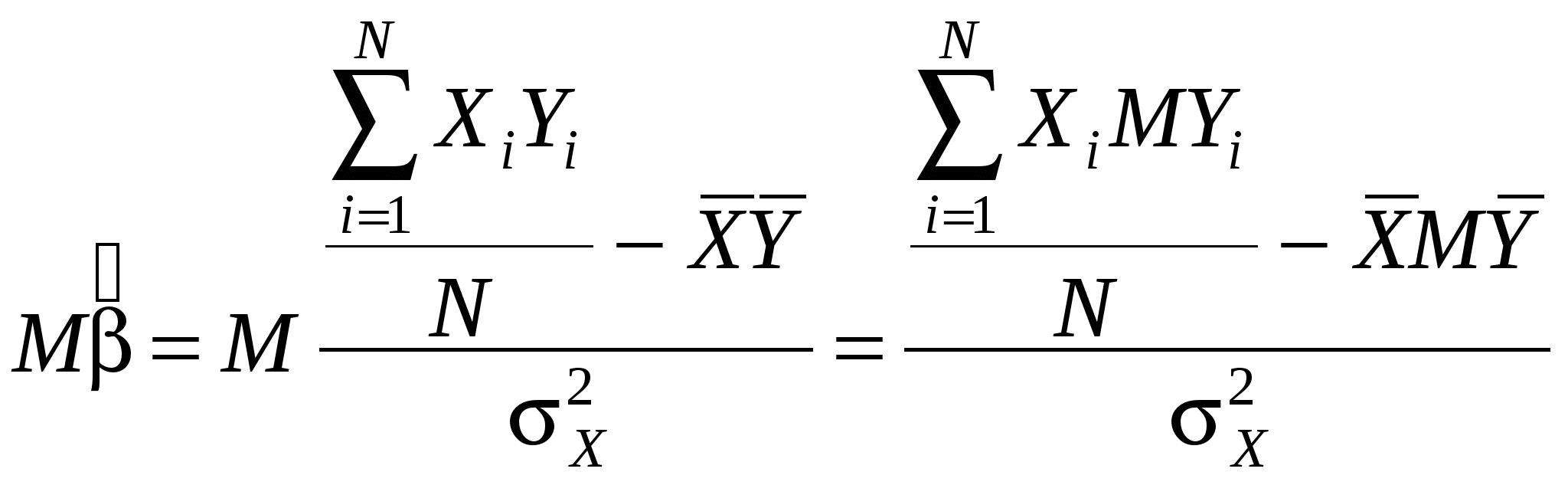
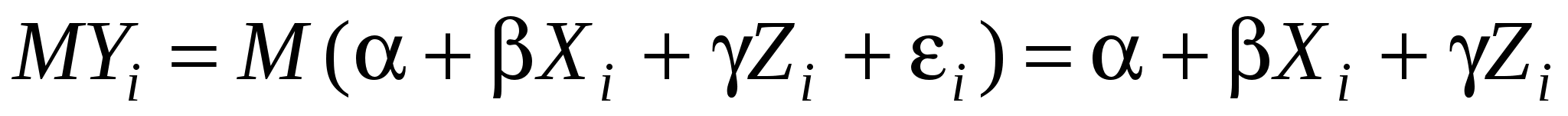
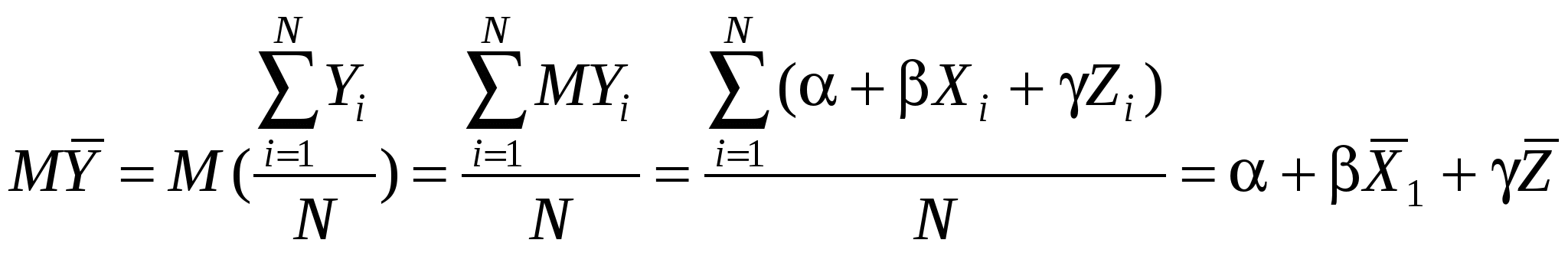
Таким образом, получаем в числителе:
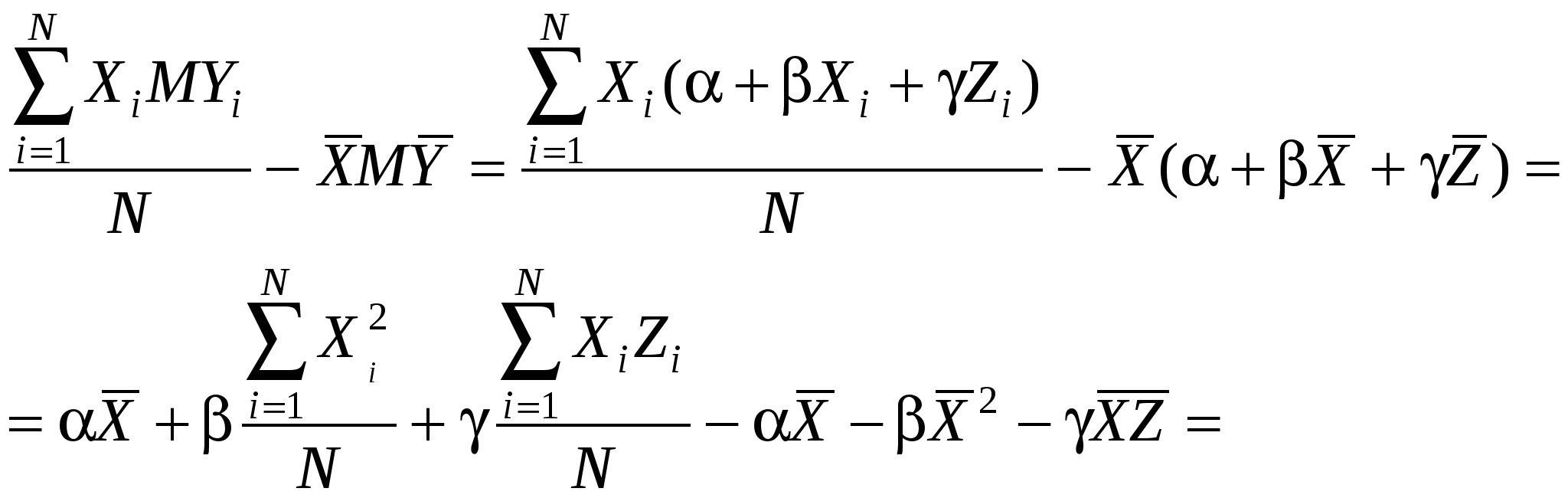
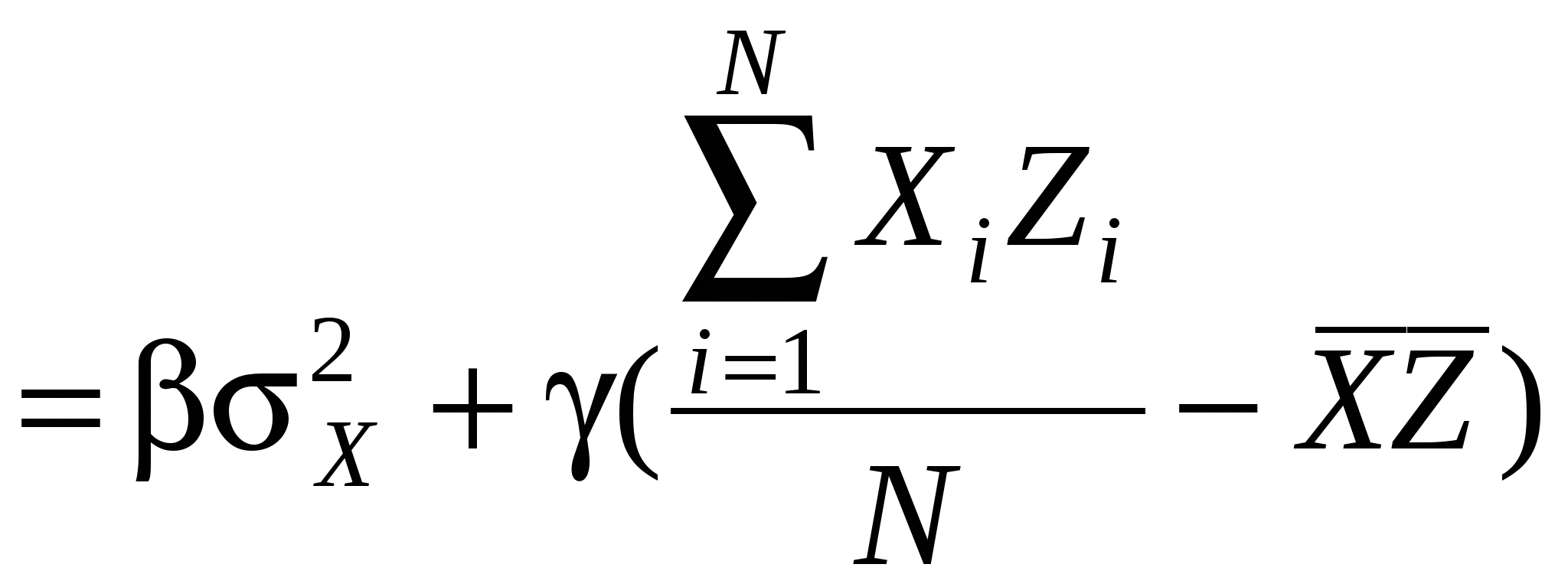
Итак, 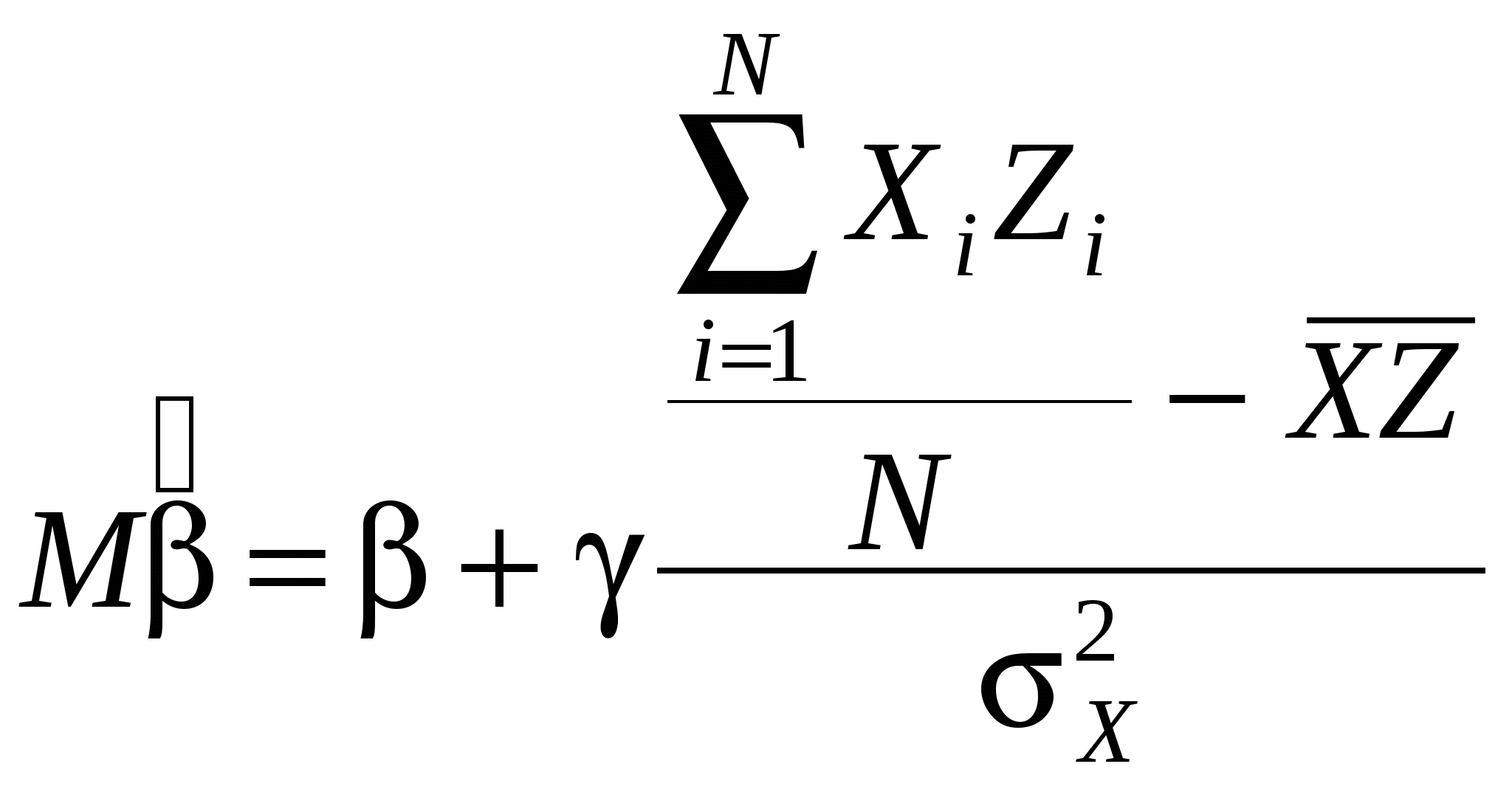 . .
Таким образом, мы получили смещенную оценку. Оценка будет несмещенной в двух случаях:
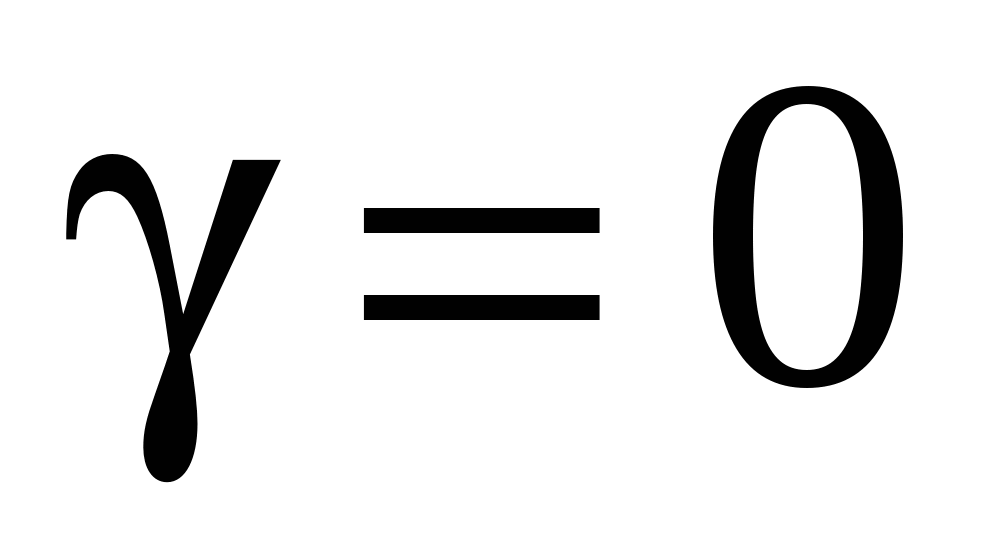 ; ;
X и Z статистически независимы.
Наша оценка будет завышать или занижать истинное значение коэффициента в зависимости от знака смещения.
Интуитивное объяснение.
Предположим, что и положительны, а X и Z положительно коррелированны, тогда с увеличением X
Y будет иметь тенденцию к росту, поскольку положителен;
Z будет иметь тенденцию к увеличению, поскольку X и Z положительно коррелированны;
Y получит дополнительное ускорение из-за увеличения Z, поскольку положительно.
Другими словами, изменение Y будет преувеличивать влияние текущих значений X, т. к. отчасти они будут связаны с изменениями Z. Т.е. часть изменения Y за счет изменения Z будет приписано X.
Однако смещение оценок коэффициентов здесь – не единственная неприятность. Что будет с оценками дисперсий?
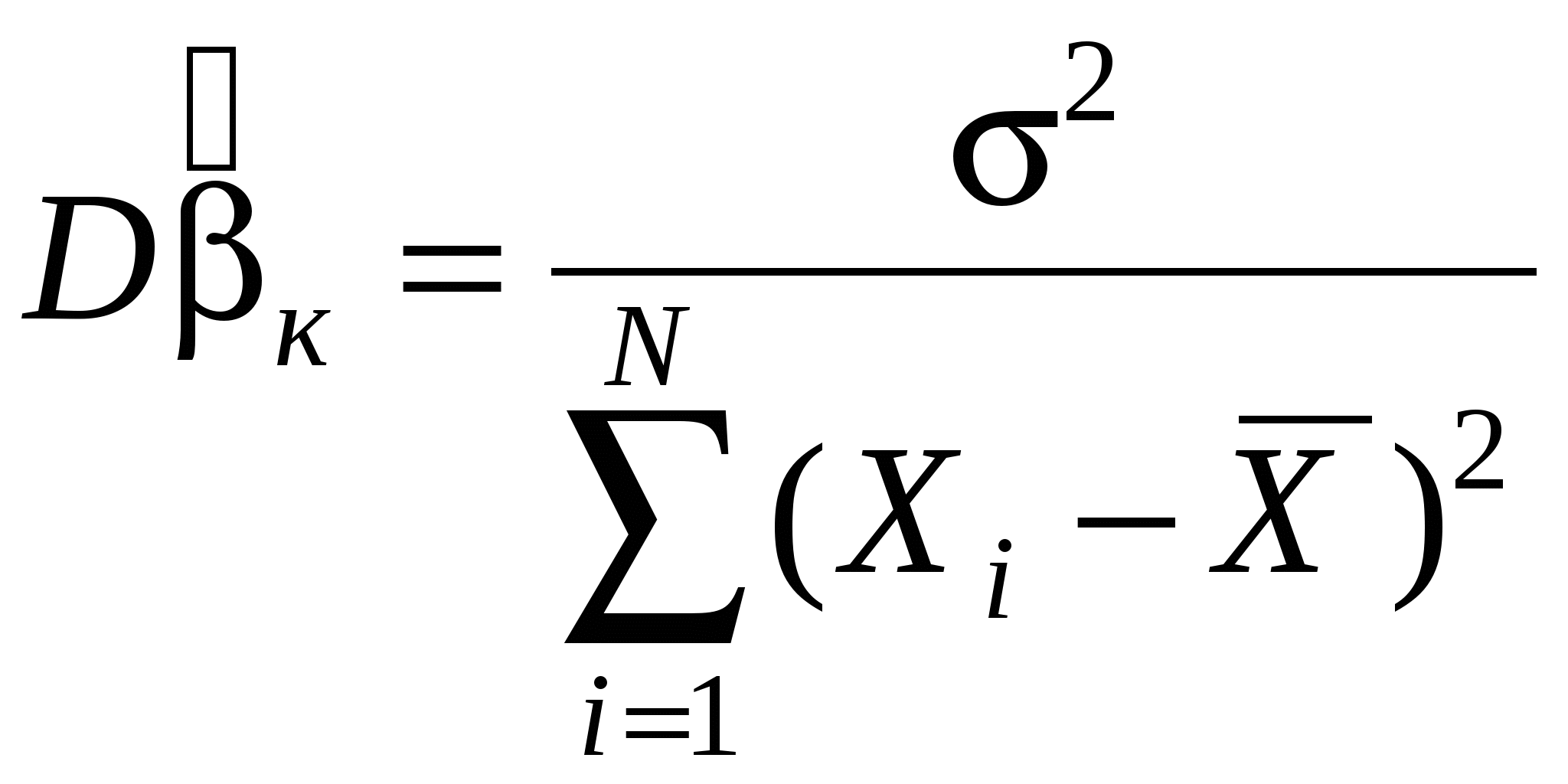 - в короткой регрессии (без доказательства). - в короткой регрессии (без доказательства).
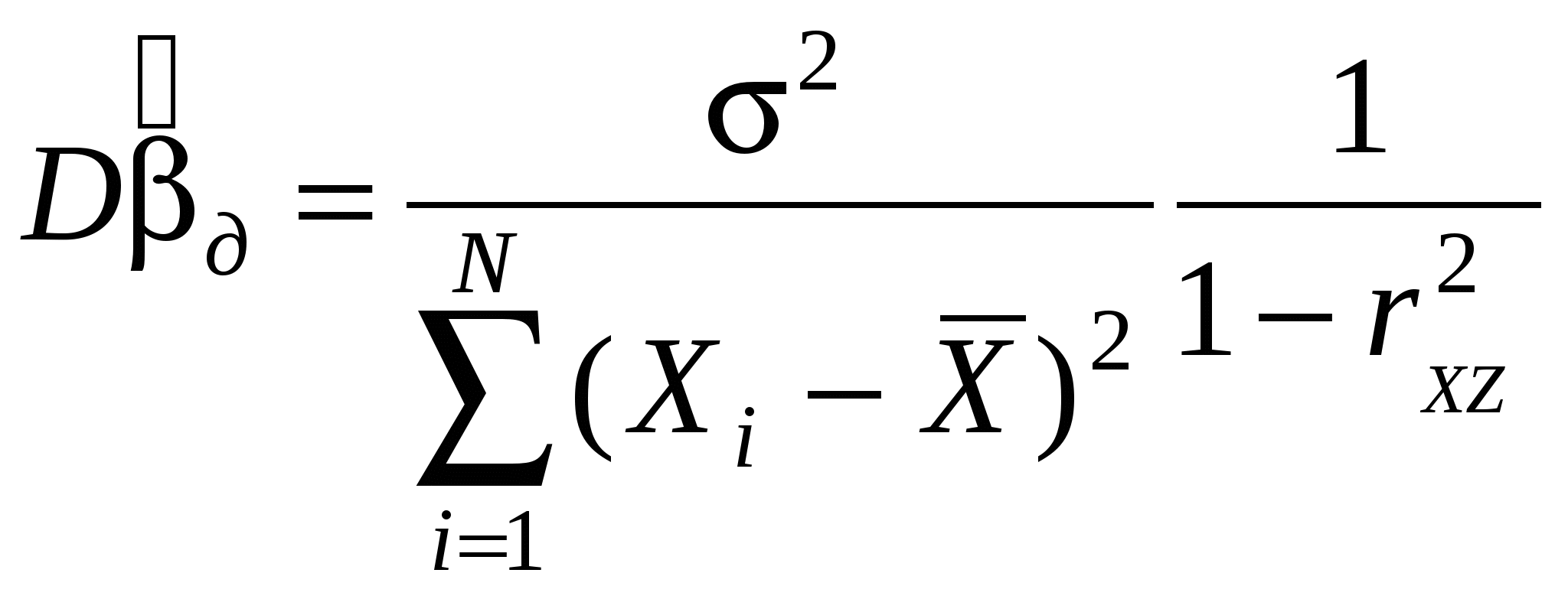 - в длинной регрессии (без доказательства). - в длинной регрессии (без доказательства).
Таким образом, 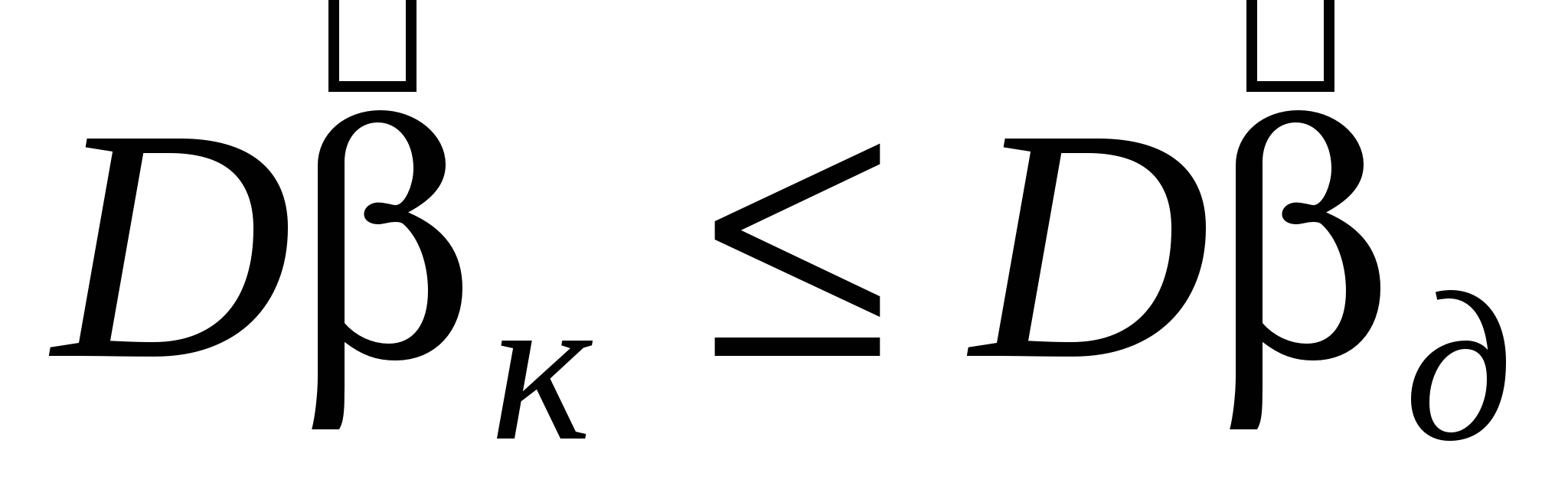 , т. е. - смещенная оценка, но обладает меньшей дисперсией. , т. е. - смещенная оценка, но обладает меньшей дисперсией.
Что будет с оценкой 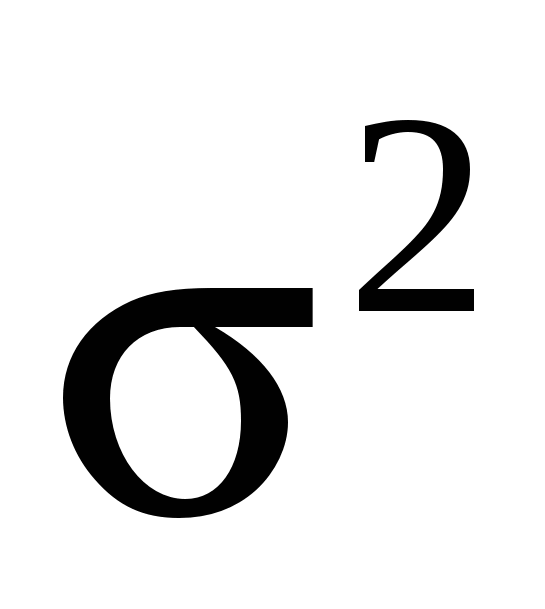 - - 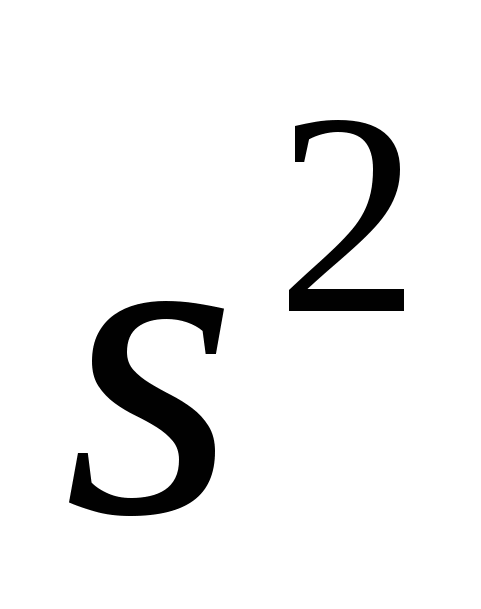 ? Оказывается, что в случае, если мы не включаем в регрессию существенную переменную, эта оценка будет смещенной. Поскольку участвует во многих статистических тестах, то используя их для проверки гипотез, мы можем получить ложные выводы. ? Оказывается, что в случае, если мы не включаем в регрессию существенную переменную, эта оценка будет смещенной. Поскольку участвует во многих статистических тестах, то используя их для проверки гипотез, мы можем получить ложные выводы.
Итак, в случае невключения объясняющих переменных, МНК-оценка короткой регрессии смещена, и обладает меньшей дисперсией, чем у оценки в длинной регрессии. Оценка дисперсии ошибки имеет неотрицательное смещение.
2. Включение несущественных переменных.
Теперь у нас ситуация противоположная предыдущей. Истинная модель выглядит следующим образом: , а мы оцениваем «длинную» регрессию . Таким образом, включая в уравнение несущественную переменную, мы не учитываем информацию о том, что коэффициент при Z равен нулю. Следует всегда ожидать, что неучитывание всей информации о модели потере эффективности оценок. Т. е. в нашем случае дисперсия оценки в «длинной» регрессии будет больше, чем дисперсия оценки коэффициента при Х в истинной модели, поскольку мы вынуждены по тем же самым наблюдениям оценивать два параметра вместо одного. Тем не менее, оценки «длинной» регрессии останутся несмещенными.
Потеря эффективности не случится, если переменные Х и Z некоррелированны. Потеря эффективности приводит к тому, что мы с большей трудностью отвергаем гипотезу о незначимости коэффициента, тем не менее оценка дисперсии останется несмещенной.
Выводы здесь мы приводить не будем. и - несмещенные оценки, но ее дисперсия больше, чем в правильной модели, т. е. точность оценки ухудшается.
Рисунок с графиками плотностей распределения.
3. Неправильный выбор функциональной зависимости.
Еще одна ошибка спецификации происходит, когда исследователь решает оценить линейную модель, в то время как истинная регрессионная модель нелинейная. Пример: 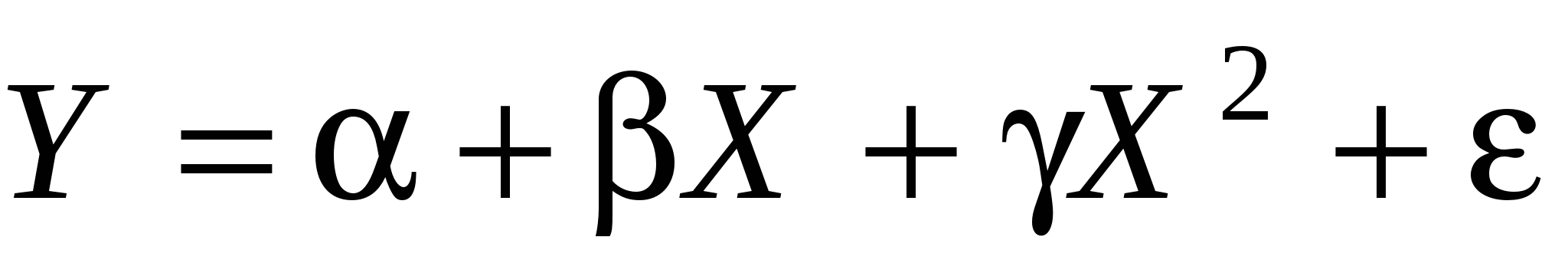 , а оцениваем мы модель . Приведенная выше ситуация является частным случаем ситуации с пропущенными переменными. Выбор линейной модели, в то время как истинная модель нелинейная может привести к смещенности и несостоятельности оценок регрессии. Поэтому исследователи часто используют полиномиальную регрессию как тест на нелинейность в объясняющих переменных. , а оцениваем мы модель . Приведенная выше ситуация является частным случаем ситуации с пропущенными переменными. Выбор линейной модели, в то время как истинная модель нелинейная может привести к смещенности и несостоятельности оценок регрессии. Поэтому исследователи часто используют полиномиальную регрессию как тест на нелинейность в объясняющих переменных.
Итак, мы с вами рассмотрели теоретические аспекты включения лишних или невключения нужных переменных в уравнение. Что же делать на практике, когда мы никогда точно не знаем, какие переменные входят в модель, а какие нет. В таких ситуациях используют различные эвристические процедуры отбора регрессоров.
8. ПРОЦЕДУРЫ ОТБОРА РЕГРЕССОРОВ
(отбор наиболее существенных объясняющих переменных).
В самом начале нашего курса мы разбирали вопрос, откуда возникает ошибка в i-м наблюдении. Мы тогда говорим про невключение в уравнение переменных в силу различных обстоятельств – про возможность перехода от исходного числа p анализируемых объясняющих переменных к существенно меньшему числу объясняющих переменных, наиболее6 информативных в некотором смысле. Некоторые объясняющие переменные оказывают несущественное влияние на объясняющую переменную и им можно пренебречь. Если же у нас есть сильно зависимые признаки, то информация, поставляемая ими, дублирует друг друга, так, что дополнительным влиянием одной из переменных можно пренебречь. Поэтому стремление исследователя отобрать из имеющегося у него набора объясняющих переменных лишь самые существенные (с точки зрения влияния на Y), представляется вполне естественным. В предположении, что объясняющие переменные неслучайны, возможны две точки зрения на оценку уравнения регрессии, получаемого после отбора наиболее существенных предсказывающих переменных:
Модель регрессии является истинной, тогда при помощи метода наименьших квадратов получается несмещенная и эффективная оценка коэффициентов регрессии (в условиях мультиколлинеарности эта оценка может быть неудовлетворительной, но, тем не менее, останется несмещенной). Тогда принудительное приравнивание части коэффициентов к нулю, что и происходит при отборе регрессоров, приводит, как мы убедились, к смещенным оценкам коэффициентов при оставшихся переменных, т. е. мы переходим к классу смещенных оценок, о чем говорилось выше.
Процесс отбора существенных переменных можно рассматривать как процесс выбора истинной модели из множества возможных линейных моделей, которые могут быть построены с помощью набора объясняющих переменных, и тогда полученные после отбора оценки коэффициентов можно рассматривать как несмещенные. этой точки зрения мы и будем придерживаться в дальнейшем.
Для случая, когда объясняющие переменные – случайные величины, вопрос о правильности (истинности) модели не стоит. Все, что мы ищем в этом случае – модель, сохраняющую ошибку предсказания на разумном уровне при ограниченном количестве переменных.
Существует несколько подходов к решению задачи отбора наиболее существенных объясняющих переменных. Мы остановимся на двух процедурах, реализующих идею «от простого к сложному» – последовательного наращивания числа объясняющих переменных.
Пусть у нас всего р переменных, претендующих на участие в правой части.
«Все возможные регрессии».
Проведем р парных регрессий Y на X1,…Xp и выберем ту переменную, для которой коэффициент детерминации наибольший - 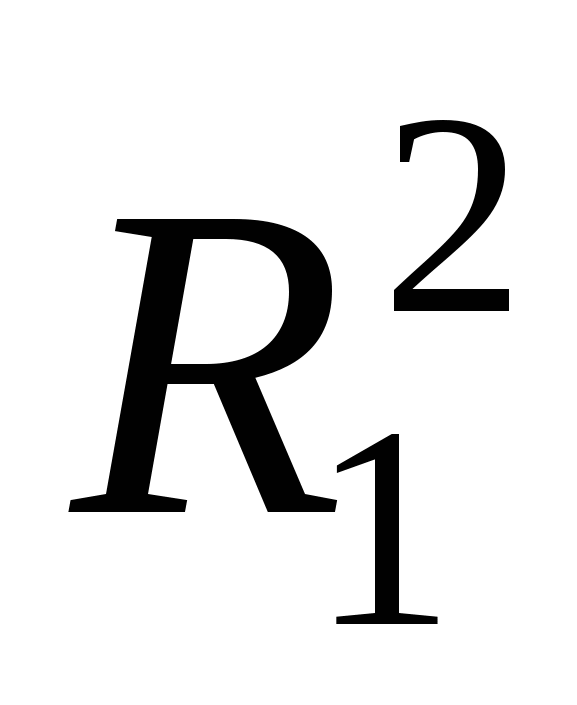 . на этом шаге мы найдем одну объясняющую переменную, которую можно назвать наиболее информативной объясняющей переменной при условии, что в регрессионную модель мы можем включить только одну из имеющегося набора объясняющих переменных. . на этом шаге мы найдем одну объясняющую переменную, которую можно назвать наиболее информативной объясняющей переменной при условии, что в регрессионную модель мы можем включить только одну из имеющегося набора объясняющих переменных.
проведем р*(р-1) регрессий, каждый раз включая две из р переменных и выберем ту, которая дает наибольшее значение 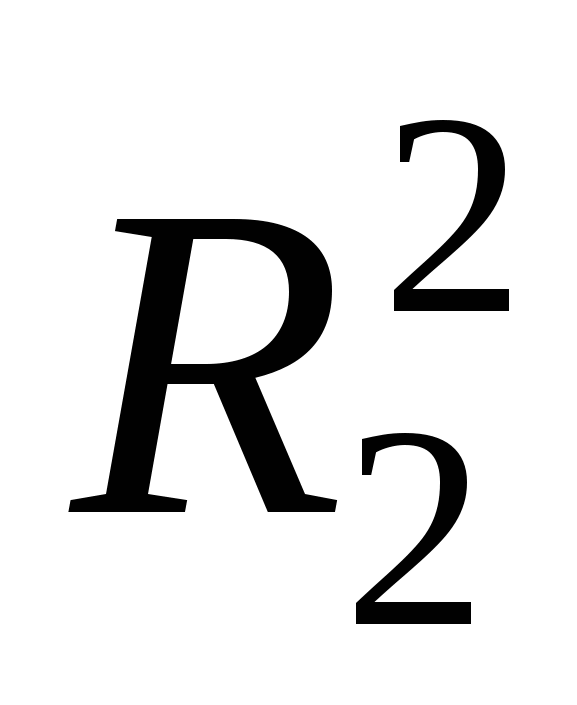 – пара (X(1), X(2)) – наиболее информативная пара переменных: эта пара будет иметь наиболее тесную статистическую связь с результирующим показателем Y. В состав этой пары переменная из первого шага может и не войти. – пара (X(1), X(2)) – наиболее информативная пара переменных: эта пара будет иметь наиболее тесную статистическую связь с результирующим показателем Y. В состав этой пары переменная из первого шага может и не войти.
находим три наиболее информативных объясняющих переменных, проведя р*(р-1)*(р-2) - 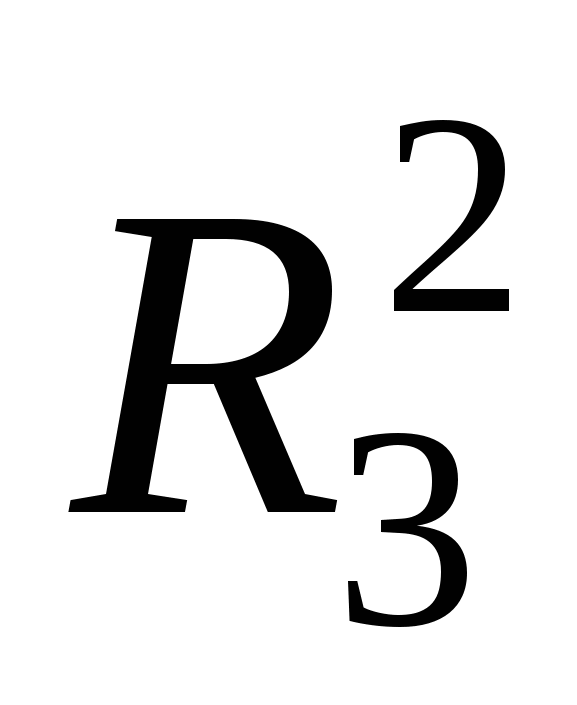
…
Вопрос – когда остановиться. Строгих правил нет, только рекомендации. Изобразим на графике зависимость скорректированного коэффициента детерминации наиболее информативной совокупности переменных от числа этих переменных. Одновременно будем откладывать следующую величину:
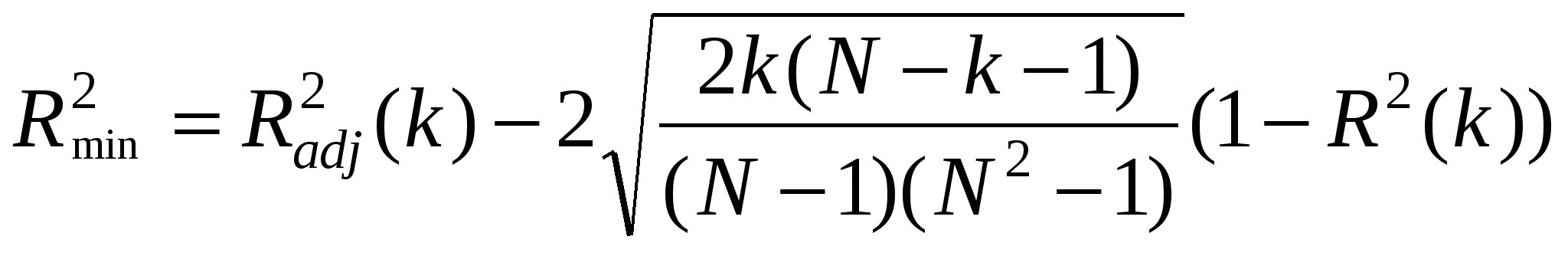 . .
Получим следующую картинку:
Рисунок
Предлагается выбрать в качестве оптимального числа объясняющих переменных то число, для которого 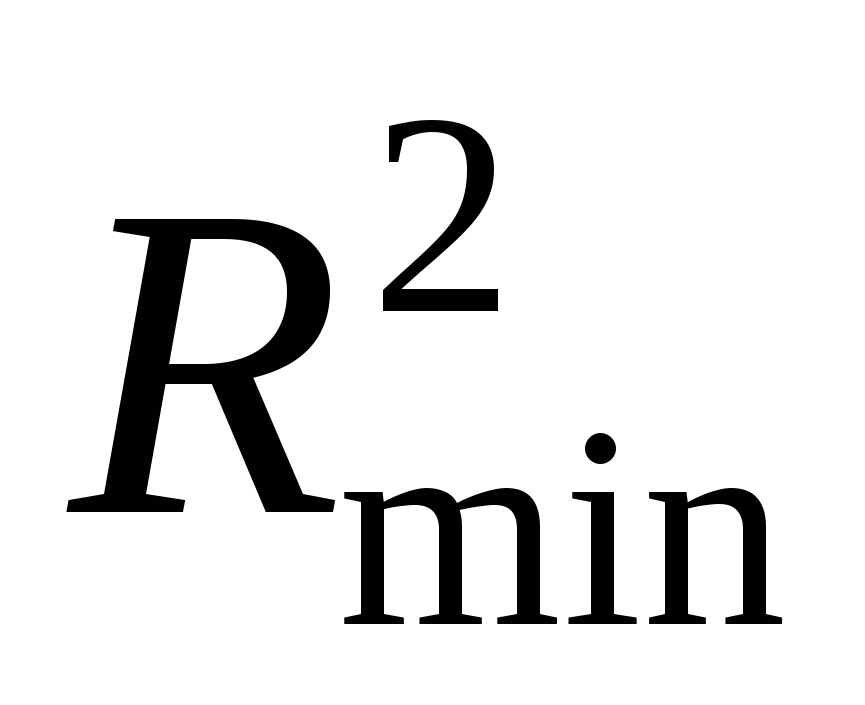 достигает своего максимума. Теоретическое обоснование этому мы здесь не приводим. достигает своего максимума. Теоретическое обоснование этому мы здесь не приводим.
Однако реализация метода всех возможных регрессий требует значительных вычислительных трудностей, поскольку число регрессий, которые необходимо оценить, большое (равное 2р-1, для p = 20 число возможных переборов будет больше миллиона (вспомнить байку про шахматы)). Есть несколько выходов из этой ситуации. Мы рассмотрим
II. Пошаговая процедура отбора переменных (в двух реализациях).
Здесь мы на каждом шаге учитываем результаты предыдущего шага, и в этом состоит отличие этого метода от предыдущего.
Первый шаг такой же, как и в предыдущем случае:
Среди имеющихся р переменных выбираем ту, для которой коэффициент корреляции с объясняемой переменной наибольший.
а) Теперь мы перебираем не все возможные пары переменных, а лишь те, в которых участвует переменная, полученная на первом шаге. Число переборов в этом случае существенно уменьшится
б) среди оставшихся переменных выбираем ту, которая имеет с объясняемой переменной наибольший коэффициент частной корреляции, очищенный от влияния переменной, полученной на первом шаге.
3)…
Число переборов для а) - 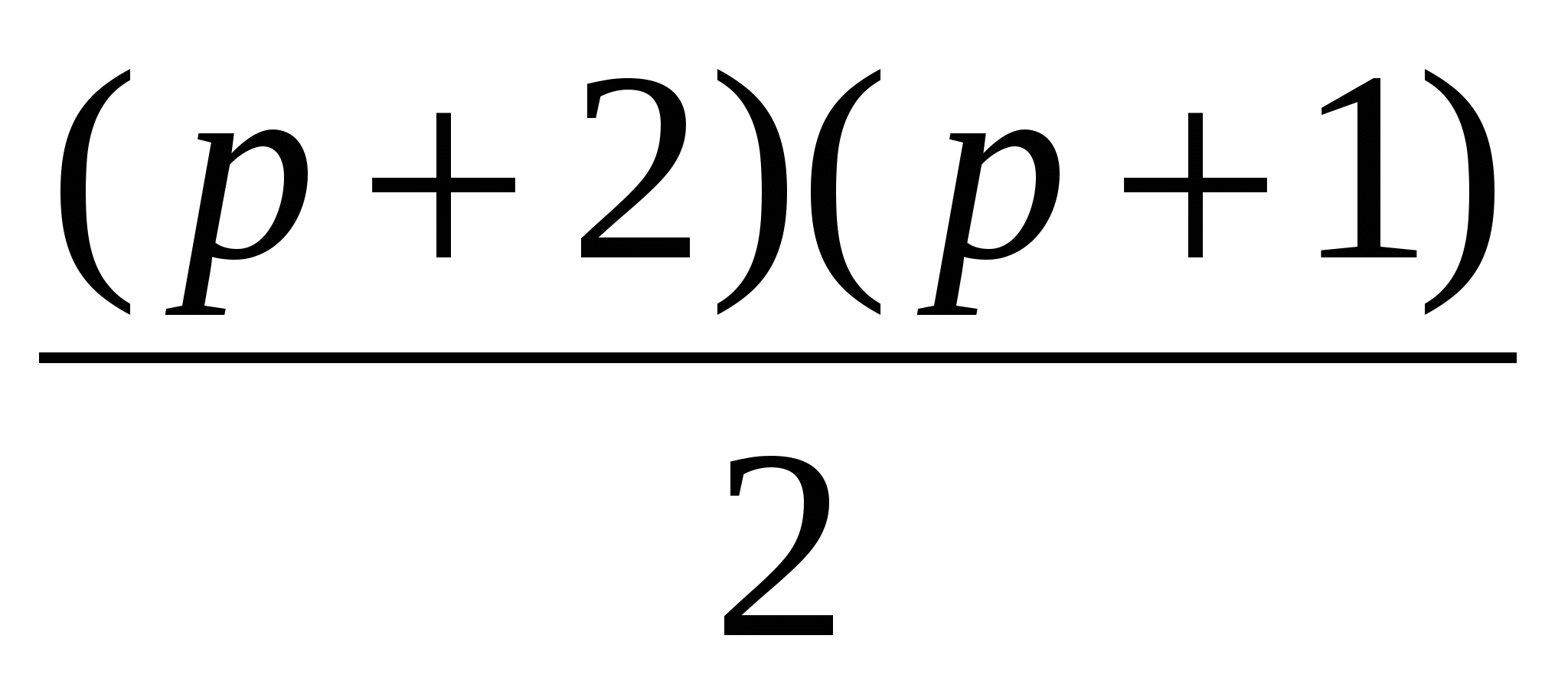 , т. е. для р = 20 число переборов будет 209. , т. е. для р = 20 число переборов будет 209.
Опять остается вопрос – когда же остановится. Ответ может быть такой, например, когда новый коэффициент частной корреляции будет уде незначимо отличаться от нуля и др. Здесь так же можно сконструировать величину и остановится тогда, когда она достигнет максимума.
Вообще говоря, пошаговые процедуры не гарантируют получения оптимального с точки зрения «всех пошаговых регрессий» набора, но в большинстве ситуаций, наборы переменных, получаемых методами пошагового отбора, будут близки к ним.
Кроме описанных, существуют различные методы пошаговые: другой метод пошагового присоединения, метод присоединения-удаления, метод удаления и др.
|
|
|
 Скачать 0.78 Mb.
Скачать 0.78 Mb.