Учебник Под редакцией доктора экономических наук, профессора Л. А. Каргиной
 Скачать 4.86 Mb. Скачать 4.86 Mb.
|

Наука о данныхНаука о данных (англ. data science) — это многодис- циплинарная область, которая использует научные методы, процессы, алгоритмы и системы для извлечения знаний и идей из структурированных и неструктуриро- ванных данных. [18] Эта наука появилась в мире относи- тельно недавно и только начинает набирать популярность в России. Как и любая другая наука, она имеет множество определений. Довольно точно и полно науку о данных определил в своей книге голландский учёный Вил ван дер Аалст. [9] Наука о данных является междисциплинарной обла- стью, направленной на превращение данных в реальную ценность. Данные могут быть структурированными или неструктурированными, большими или малыми, статиче- скими или потоковыми. Ценность может быть обеспечена в виде прогнозов, автоматизированных решений, моделей, полученных из данных, или любого типа визуализации данных, предоставляющей информацию. Наука данных включает в себя извлечение данных, подготовку данных, исследование данных, преобразование, хранение данных, вычислительные инфраструктуры, различные виды май- нинга и обучения, представление объяснений и прогнозов, а также использование результатов с учетом этических, социальных, юридических и деловых аспектов. Приведенное выше определение подразумевает, что наука о данных шире прикладной статистики и интеллек- туального анализа данных. Люди, профессионально занимающиеся наукой о дан- ных, называются специалистами по анализу данных или дата сайнтистами (data scientist). Специалисты по ана- лизу данных помогают организациям превращать данные в ценную информацию, которая должна принести пользу компании. Эти специалисты могут ответить на множе- ство вопросов, ответы на которые основаны на данных. Эти вопросы можно сгруппировать в следующие четыре основные категории: (Отчётность) Что случилось? (Диагностика) Почему это произошло? (Предсказание) Что произойдет? (Рекомендация) Что может быть лучше всего? Наука о данных представляет собой объединение раз- личных частично перекрывающихся (под)дисциплин. На риc. 3.4 показаны основные составляющие науки о данных. Дисциплины пересекаются друг с другом и раз- личаются по объёму. Более того, границы не являются четкими и меняются со временем. Сами данные, которые изучаются и анализируются, также играют огромную роль. Большие данные (англ. big data) — это область, в которой рассматриваются способы анализа и систематического извлечения информации из наборов данных, которые слишком велики или сложны для обработки традиционными прикладными програм- мами обработки данных. Данные с большим количеством строк обеспечивают большую статистическую мощность, в то время как данные с большей сложностью (больше атрибутов или столбцов) могут в то же время привести к ошибкам и ложным выводам. Основные сложности в использовании больших данных — это захват данных, хранение данных, анализ данных, поиск, обмен, пере- дача, визуализация, запрос, обновление, конфиденциаль- ность информации и источник данных. Большие данные традиционно связаны с ключевыми характеристиками: объем, многообразие, скорость и достоверность [11]. 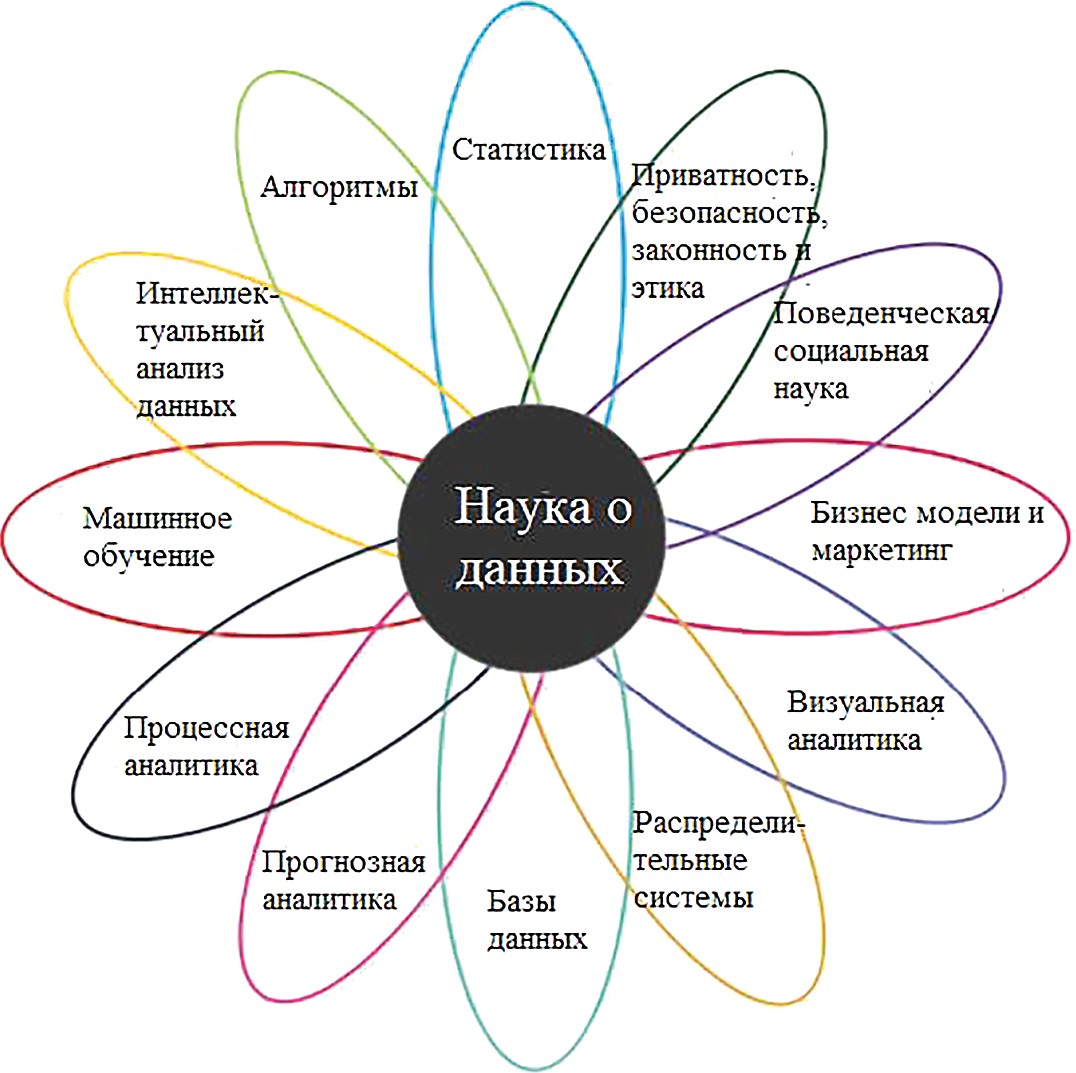 Риc.3.4.Составляющиенаукиоданных Большие данные можно описать следующими харак- теристиками [13]: Объем — количество генерируемых и хранимых данных. Размер данных определяет ценность и потен- циальное понимание, а также могут ли эти данные счи- таться большими или нет. Многообразие — тип и характер данных. Это помо- гает людям, которые анализируют данные, эффективно использовать информацию, которую они вывели из этих данных. Большие данные получают из текста, изображе- ний, аудио, видео. Скорость — в этом контексте, скорость, с которой данные генерируются и обрабатываются для удовлет- ворения потребностей и устранения проблем, которые лежат на пути роста и развития. Большие данные часто доступны в режиме реального времени. По сравнению с малыми данными, большие данные производятся с бо́льшим постоянством. Два вида скорости, связанные с большими данными — это частота генерации и частота обработки, записи и публикации. [13] Достоверность — это расширенное определение для больших данных, которое относится к качеству дан- ных и значению данных. Качество полученных данных может сильно варьироваться, влияя на точный анализ. Данные должны быть обработаны с помощью пере- довых инструментов (аналитики и алгоритмов), чтобы выявлять действительно значимую информацию. [17] Интеллектуальный анализ данных Интеллектуальный анализ данных можно охаракте- ризовать как процесс поиска особенностей и интересной структуры в данных. Структура может принимать множе- ство форм, включая набор правил, графики или сеть, одно или несколько уравнений и многое другое. Структура может быть частью сложной визуальной панели инстру- ментов или просто как список политических кандидатов и привязанный к ним номер, представляющий настрое- ния избирателей на основе записей в Twitter. В процессе интеллектуального анализа данных используется один или несколько алгоритмов для выяв- ления интересных тенденций и закономерностей в дан- ных. Знания, полученные в ходе этапа интеллектуального анализа данных, представляют собой обобщенную модель данных. Конечная цель — применить то, что было обна- ружено, к новым ситуациям. Существует несколько методов интеллектуального анализа данных. Однако все методы интеллектуального анализа данных используют индуктивное обучение. Индуктивное обучение — это процесс формирования общих определений понятий путем наблюдения конкрет- ных примеров изучаемых понятий. [16] Процесс интеллектуального анализа данных пред- ставляет собой конвейер, содержащий множество эта- пов — таких как очистка данных, извлечение функций и алгоритмическое проектирование. Рабочий процесс типичной процедуры интеллекту- ального анализа данных содержит следующие этапы [14]: Сбор данных. Сбор данных может потребовать использования: специального оборудования — такого как сенсор- ная сеть; ручного труда, такого как опросы пользователей; программных средств, таких как приложение для сбора веб-документов. После этапа сбора данные часто хранятся в базе дан- ных или в хранилище данных для обработки. Извлечение признаков и очистка данных. Когда происходит сбор данных, они часто не подходят для после- дующей обработки. Например, данные могут быть зако- дированы в нераспознанные форматы. Во многих случаях различные типы данных могут произвольно смешиваться в документе свободной формы. Чтобы сделать данные пригодными для обработки, необходимо преобразовать их в формат, дружественный алгоритмам интеллектуального анализа данных. Наиболее распространенным является многомерный формат, в котором различные поля данных соответствуют различным измеряемым свойствам, кото- рые называются признаками, атрибутами или измерени- ями. Крайне важно извлечь соответствующие характери- стики для процесса добычи. Этап извлечения признаков часто выполняется параллельно с очисткой данных, где недостающие и ошибочные части данных оцениваются или корректируются. Во многих случаях данные могут быть извлечены из различных источников и должны быть интегрированы в единый формат для обработки. Конеч- ным результатом этой процедуры является красиво струк- турированный набор данных, который может эффективно использоваться компьютерной программой. После фазы извлечения признаков данные могут снова храниться в базе данных для обработки. Аналитическая обработка и алгоритмы. Заключи- тельной частью процесса анализа данных является раз- работка эффективных аналитических методов, на основе обработанных данных. Общий процесс интеллектуального анализа данных показан на риc. 3.5. На первом этапе происходит сбор данных. Затем они обрабатываются путём извлечения важных признаков и очистки. Во время аналитического процесса данные преобразуются в готовые блоки, сфор- мированные в удобном виде для последующего анализа аналитиками. 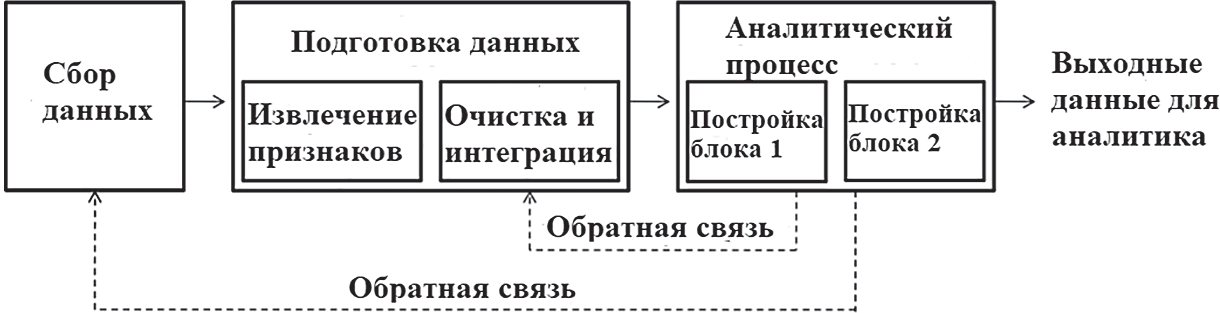 Риc.3.5.Процессинтеллектуальногоанализаданных Этап предварительной обработки или подготовки данных является, пожалуй, самым важным в процессе интеллектуального анализа данных. Этот этап начина- ется после сбора данных и состоит из следующих шагов: Извлечение признаков: аналитик может стол- кнуться с огромными объемами необработанных докумен- тов, системных журналов или коммерческих транзакций без каких-либо указаний о том, как эти необработанные данные должны быть преобразованы в значимые функ- ции базы данных для обработки. Эта фаза сильно зависит от аналитика, так как нужно понять, что именно будет влиять на результат анализа. Например, в приложении для обнаружения мошенничества с кредитными кар- тами сумма сбора, частота повторения и местоположение часто являются хорошими показателями мошенниче- ства. Однако многие другие признаки могут практически не являться показателями мошенничества. Очистка данных: извлеченные данные могут иметь ошибочные или отсутствующие записи. Поэтому некото- рые записи, возможно, потребуется удалить, или отсут- ствующие записи можно предположить или подставить на основе доступных похожих данных. Возможно, потре- буется устранить несоответствия. Выбор и преобразование признаков: когда данные очень многомерны, многие алгоритмы интеллектуального анализа данных не работают эффективно. Кроме того, многие признаки являются ошибочными по той или иной причине и могут добавлять ошибки в процесс интеллекту- ального анализа данных. Поэтому для удаления не отно- сящихся к делу объектов или преобразования текущего набора объектов в новое пространство данных, более при- годное для анализа, используются различные методы. Процесс очистки данных требует статистических мето- дов, которые обычно используются для оценки недостаю- щих данных. Кроме того, ошибочные записи данных часто удаляются для обеспечения более точных результатов интеллектуального анализа данных. Выбор и преобразо- вание признаков не следует рассматривать как часть пред- варительной обработки данных, поскольку этап выбора признаков часто сильно зависит от конкретной решаемой аналитической задачи. В некоторых случаях процесс выбора признака может быть даже тесно интегрирован с используе- мым конкретным алгоритмом или методологией. Машинное обучение Машинное обучение — это обширная дисциплина, которая также входит в науку о данных. В разрезе машин- ного обучения изучается то, как системы учатся на дан- ных. Системы могут быть обучены данными для принятия решений, и обучение является непрерывным процессом, в котором система постоянно поддерживает процесс обу- чения и улучшает свою способность принимать решения с большим количеством данных. Машинное обучение является разновидностью ис- кусственного интеллекта, который позволяет изучать и прогнозировать результаты без использования глубо- кого программирования. Термин «машинное обучение» часто используется вместо «искусственного интеллекта», потому что является его методом, который оказал наи- большее влияние на развитие этой сферы информацион- ных технологий. Крупные компании используют машинное обучение для принятия решений и автоматизации бизнес-процес- сов, изучая данные. Теперь простые в использовании инструменты, четко определенные алгоритмы и легко- доступные услуги представляют преимущества машин- ного обучения организациям любого размера. Компании, которые не используют машинное обучение для экономии на затратах, увеличения надежности и эффективности, вскоре будут вытеснены из конкурентной борьбы теми, кто внедряет эти технологии. Вместо того чтобы писать алгоритмы и правила, кото- рые принимают решения напрямую, или пытаться запро- граммировать компьютер, чтобы он выполнял постав- ленные задачи, используя наборы правил, исключений и фильтров, машинное обучение учит компьютерные системы принимать решения, изучая большие наборы данных. Машинное обучение может создавать модели, которые представляют и обобщают шаблоны в данных, которые используются для такого обучения, и исполь- зовать эти модели для интерпретации и анализа новой информации. В литературе существуют различные определения машинного обучения. Одно из них звучит так: «Область машинного обучения стремится ответить на вопрос “как мы можем построить компьютерные системы, которые автоматически улучшаются с опытом, и каковы фунда- ментальные законы, которые управляют всеми процес- сами обучения?» [17] Спам-фильтр — хороший пример машинного обуче- ния. По мере того, как ему передается больше данных, он продолжает подстраивать и адаптировать свои пра- вила принятия решений под новые данные, используя методы машинного обучения, тем самым предотвращая получение спама в дальнейшем. Распознавание и под- тверждение оплаты с помощью кредитных карт также основаны на нейронных сетях, еще одном популярном методе машинного обучения. Однако методы машинного обучения предпочитают данные суждениям, а наука о данных требует сбалансированного сочетания того и другого. Суждение необходимо для точной контекстуа- лизации параметров анализа и построения эффективных моделей. Например, профессор статистики Винни Бра- зис, использует машинное обучение для прогнозирова- ния доходов от кино. [14] Он утверждает, что простого машинного обучения будет недостаточно для получения точных предсказаний. Он дополняет машинное обуче- ние суждениями, полученными из интервью со сценари- стами, опросов и т. д., чтобы в результате получить более точный прогноз. Машинный интеллект возрождается как новое вопло- щение искусственного интеллекта (область, которая, как многие считают, не оправдала ожиданий). Машин- ное обучение обещает и дает ответы на многие вопросы, представляющие интерес. Хилари Мейсон, основатель FastForwardLabs, специалист по Data Science в Accel, предлагает четыре характеристики машинного интел- лекта, которые делают его интересным[9]: Машинное обучение обычно основано на теоретиче- ском прорыве и поэтому хорошо обосновано в науке. Оно изменяет существующую экономическую пара- дигму. Результатом машинного обучения является процесс перехода продукта из марочной категории в категорию рядовых продуктов за счет совершенствования производ- ственных технологий (например, Hadoop). Машинное обучение предоставляет новые данные, которые ведут к дальнейшему развитию науки о данных. Машинное обучение отличается и теперь определяется отдельно от традиционной статистики. Машинное обуче- ние больше касается обучения и сопоставления входных данных с выходными, в то время как в статистике всегда больше изучался анализ данных в рамках данной поста- новки проблемы или гипотезы. Машинное обучение, как правило, позволяет открывать что-то новое, в то время как эконометрика и статистический анализ, как пра- вило, основаны на теории с жесткими предположениями. Машинное обучение имеет тенденцию фокусироваться больше на прогнозировании, которое даёт более полный результат, чем прогноз (или корреляция). Домингос, ученый-практик, один из ведущих исследо- вателей в области машинного обучения, в своём исследо- вании [12] рассматривает машинное обучение как сумму трёх компонентов: представления, оценки и оптимиза- ции. Представление машинного обучения требует обозна- чения проблемы на формальном языке, который может обрабатываться с помощью компьютера. Эти представ- ления будут отличаться для различных методов машин- ного обучения. Например, в задаче классификации может быть выбор многих классификаторов, каждый из которых будет формально представлен. Затем, чтобы завершить этап оценки, указывается функция подсчета очков или функция потерь. Наконец, наилучшая оценка достигается за счет оптимизации модели. После того, как шаги были выполнены и наилучший алгоритм машинного обучения выбран из данных обуче- ния, мы можем проверить модель на данных из выборки или набора тестовых данных. Можно случайным образом отобрать часть выборки данных для проверки. Повторение этого процесса путем предоставления различных частей данных для тестирования, а также обучение по осталь- ным частям, является процессом, известным как пере- крестная проверка, и настоятельно рекомендуется, чтобы достичь точных и объективных результатов. Если окажется, что повторная перекрестная про- верка приводит к плохим результатам, даже несмотря на то, что тестирование в образце работает очень хорошо, то это может свидетельствовать о чрезмерной подгонке. Чрезмерная подгонка обычно происходит, когда модель чрезмерно параметризована в выборке и подходит очень хорошо для конкретно данной выборки, но тогда она ста- новится менее полезной для новых данных. Поэтому во многих случаях более простые и менее параметризован- ные модели, как правило, лучше работают при настройке параметров прогнозирования. Машинное обучение по способу обучения делится на два типа: обучение с учителем, которое обучает модель известными входными и выходными данными, чтобы она могла предсказывать будущие результаты, и обучение без учителя, которое находит скрытые шаблоны или внутрен- ние структуры во входных данных. Общая классификация методов машинного обучения показана на рисунке 3.6. Алгоритм обучения с учителем принимает известный набор входных данных и известных значений для этих данных (выход) и обучает модель генерировать разум- ные прогнозы (новые значения) для новых данных. Обу- чение с учителем используется, если известны данные для вывода, который необходимо предсказать. 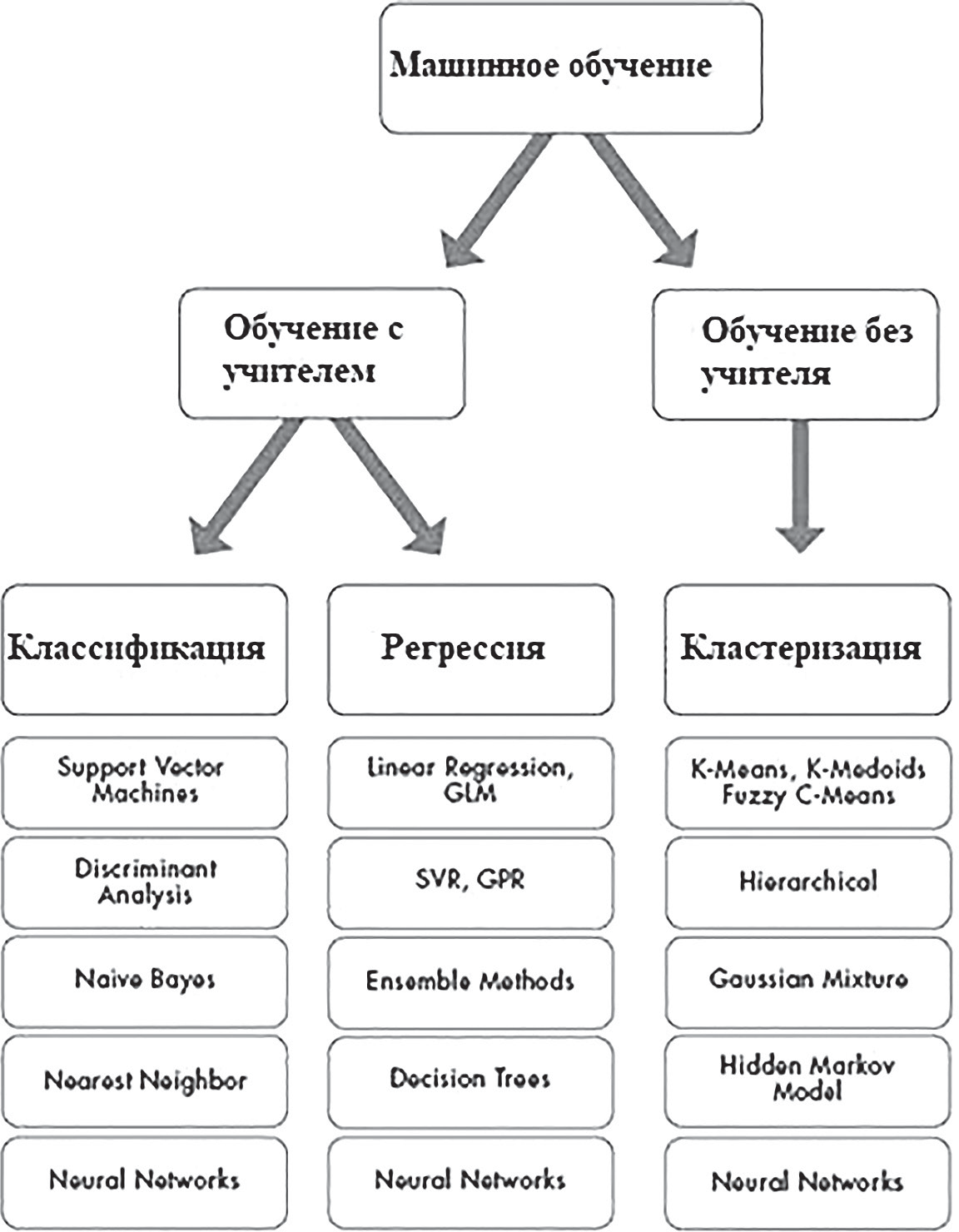 Риc.3.6.Классификацияметодовмашинногообучения Контролируемое обучение использует методы клас- сификации и регрессии для разработки прогностических моделей. Методы классификации предсказывают дискретные ответы — например, является ли электронное письмо подлинным или спамом, или опухоль раковой или добро- качественной. Модели классификации классифицируют входные данные по категориям. Общие алгоритмы для выполнения классификации включают в себя векторную машину поддержки, деревья решений, метод k-ближайших соседей, наивный байесов- ский классификатор, дискриминантный анализ, логисти- ческую регрессию и нейронные сети. Методы регрессии предсказывают непрерывные реак- ции — например, изменения температуры или колебания спроса на электроэнергию. Обычно применяются в про- гнозировании нагрузки электричества и алгоритмической торговле. Общие алгоритмы регрессии включают линейную модель, нелинейную модель, регуляризацию, ступенча- тую регрессию, деревья решений, нейронные сети и адап- тивную сеть на основе системы нечеткого вывода. Обучение без учителя находит скрытые шаблоны или внутренние структуры в данных. Машинное обучение используется для построения выводов из наборов данных, состоящих из неопределённых входных данных. Кластеризация является наиболее распространен- ным методом обучения без учителя. Она используется для исследовательского анализа данных для поиска скры- тых шаблонов или групп в данных. Общие алгоритмы для выполнения кластеризации включают метод k-средних, иерархическую кластери- зацию, Гауссову смесь распределений, скрытые модели Маркова, самоорганизующиеся карты, метод нечёткой кластеризации C-средних и вычитающую кластеризацию. Ансамбль моделей — это комбинации многих моделей машинного обучения. Существует много способов, с помо- щью которых модели могут быть объединены для созда- ния лучших моделей. Но различные модели не всегда необходимы в решении одной определённой задачи. Вместо этого можно откалибровать одну и ту же модель для разных подмножеств данных обучения, предоставляя несколько похожих, но разных моделей. Каждая из этих моделей затем используется для классификации вне выборки, и решение принимается путем отбора наиболее эффективных моделей. Этот метод известен как бэггинг. Одним из наиболее популярных примеров алгоритмов бэггинга является модель случайного леса. В другом методе — бустинге, оптимизируемая функ- ция потерь не взвешивает все примеры в наборе данных обучения одинаково. После одного прохода калибровки обучающие примеры взвешиваются таким образом, что случаи, когда алгоритм машинного обучения допустил ошибки (как в задаче классификации), получают более высокий вес в функции потерь. Подмечая эти наблю- дения, алгоритм учится предотвращать эти ошибки, поскольку они являются более значимыми. Другой подход к ансамблю методов называется ста-кинг, когда модели прикованы друг к другу, так что выход данных низкоуровневых моделей становится входом дру- гой модели более высокого уровня. Здесь модели инте- грированы вертикально в отличие от бэгинга, где модели интегрированы горизонтально. Наука о данных состоит из предсказаний и прогно- зов. Но между ними есть разница. Статистик-экономист Пол Саффо предположил, что предсказания направлены на определение одного результата, в то время как про- гнозы охватывают целый ряд результатов. Сказать, что «завтра будет дождь», — это сделать прогноз, но ска- зать, что «вероятность дождя составляет 40%» (подраз- умевает, что вероятность отсутствия дождя составляет 60%), — это значит сделать прогноз, поскольку он изла- гает диапазон возможных результатов с вероятностями. Делаются прогнозы погоды, а не предсказания. Предска- зания — это утверждения большой определенности, в то время как прогнозы иллюстрируют диапазон неопреде- ленности. Глубокое обучение Традиционные методы машинного обучения были ограничены в своей способности обрабатывать естествен- ные данные в их сырой, необработанной форме. В тече- ние десятилетий построение системы распознавания образов или машинного обучения требовало тщательного проектирования и значительного опыта в области разра- ботки экстрактора объектов, который преобразовывал необработанные данные (например, значения пикселей изображения) в подходящее внутреннее представление или вектор объектов, из которого подсистема обучения может обнаруживать или классифицировать шаблоны во входных данных. Обучение представлениям — это набор методов, в ко- торых на вход подаются необработанные данные и затем автоматически обнаруживаются представления, необхо- димые для распознавания или классификации. Методы глубокого обучения — это методы представления-обуче- ния с несколькими уровнями представления, получен- ные путем составления простых, но нелинейных моду- лей, каждый из которых преобразует представление на одном уровне (начиная с ввода сырых данных) в пред- ставление на более высоком, немного более абстрактном уровне. Благодаря такой структуре достаточно сложные функции могут быть извлечены. Для задач классифи- кации более высокие уровни представления усиливают аспекты входных данных, которые важны для распоз- навания и подавляют нерелевантные вариации. Изо- бражение, например, приходит в виде массива значений пикселей, и изученные объекты в первом слое представ- ления обычно представляют наличие или отсутствие граней в системе координат изображения. Второй слой обычно обнаруживает рисунки, выделяя определенные расположения граней, независимо от небольших изме- нений в их положениях. Третий слой может собирать рисунки в более крупные комбинации, которые соот- ветствуют частям знакомых объектов, а последующие слои будут обнаруживать объекты как комбинации этих частей. Ключевым аспектом глубокого обучения явля- ется то, что эти слои функций не разработаны инжене- рами-людьми: они извлекаются из данных с помощью процедуры обучения общего назначения. Для анализа данных в глубоком обучении использу- ются искусственные нейронные сети. Искусственная ней- ронная сеть (ИНС) — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологи- ческих нейронных сетей — сетей нервных клеток живого организма. [4] Это понятие возникло при изучении про- цессов, протекающих в мозге, и при попытке смоделиро- вать эти процессы. ИНС основаны на наборе связанных единиц или уз- лов, называемых искусственными нейронами, которые свободно моделируют нейроны в биологическом мозге. Каждое соединение, подобно нейронам в биологическом мозге, может передавать сигнал от одного искусствен- ного нейрона к другому. Искусственный нейрон, который получает сигнал, может обработать его, а затем сигнали- зировать дополнительным искусственным нейронам, свя- занным с ним. В практических разработках сигнал в ИНС при связи между искусственными нейронами является веществен- ным числом, а выход каждого искусственного нейрона вычисляется некоторой нелинейной функцией суммы его входов. Связи между искусственными нейронами называ- ются «гранями». Искусственные нейроны и края обычно имеют вес, который регулируется по мере обучения. Вес увеличивает или уменьшает силу сигнала при под- ключении. Искусственные нейроны могут иметь такой порог, что сигнал отправляется только в том случае, если совокупный сигнал пересекает этот порог. Как правило, искусственные нейроны объединяются в слои. Различные слои могут выполнять различные виды преобразований на своих входах. Сигналы перемещаются от первого слоя (входного слоя) к последнему слою (выходному слою), иногда после многократного обхода слоев. Первоначальная цель подхода ИНС состояла в том, чтобы решать проблемы так же, как это сделал бы чело- веческий мозг. Однако со временем внимание переклю- чилось на выполнение конкретных задач, что привело к отклонениям от биологии. Искусственные нейронные сети используются для решения различных задач, вклю- чая компьютерное зрение, распознавание речи, машин- ный перевод, фильтрацию социальных сетей, в настоль- ных и видеоиграх и в медицинской диагностике. Глубокое обучение делает большие успехи в решении проблем, с которыми не справлялись методы искусствен- ного интеллекта в течение многих лет. Оно оказалось очень хорошим инструментом для обнаружения сложных структур в многомерных данных и поэтому применимо ко многим областям науки, бизнеса и государства. В допол- нение к тому, чтобы побить рекорды в распознавании изображений [7] и распознавании речи [5], глубокое обу- чение превзошло другие методы машинного обучения во многих аспектах науки, например, при прогнозировании активности молекул в наркотиках, анализе данных уско- рителя частиц, реконструирующих схемы мозга, и пред- сказании влияния мутаций в некодирующей ДНК на экс- прессию генов и болезни. Глубокое обучение дало весьма многообещающие результаты для решения различных задач в понимании естественного языка, особенно клас- сификации конкретных тем, анализа настроений, ответов на вопросы и перевода на другой язык. [6] |