Теория вероятностей и математическая статистика. Закон распределения случайной величины. Математическое ожидание 28 Дисперсия случайной величины 32
 Скачать 361.49 Kb. Скачать 361.49 Kb.
|

Проверка статистических гипотезСтатистическая гипотеза – это любое предположение о виде или о значениях параметров вероятностного распределения. При проверке статистических гипотез ту гипотезу, которую проверяют, принято называть нулевой гипотезой и обозначать Hо. Одновременно рассматривают альтернативную (конкурирующую) гипотезу Н1. Гипотезы Hо и Н1должны быть противоположны друг другу. Принцип проверки статистических гипотез заключается в следующем. На основе выборки данных рассчитывают некий показатель , который называют статистикой критерия. Этот показатель является случайной величиной (поскольку он рассчитывается по выборке), но его выбирают таким образом, что его вероятностное распределение известно (возможно, приближенно). Кроме того, значение должно быть связано с тем, выполняется или нет проверяемая гипотеза. Все возможные значения разбивают на две непересекающиеся области – область принятия гипотезы и критическую область (в которой гипотеза отклоняется). Например, выбирают критическое значение статистики критерия кр такое, что если гипотеза верна, то вероятность α превысить это значение α = Р( > кр) очень мала (α = Р( > кр)). Тогда при ≤ кр гипотеза принимается, а при всех остальных значениях отклоняется Hо. Правило проверки статистической гипотезы называют статистическим критерием. Однако, с вероятностью α может быть все же допущена ошибка (т.е. гипотеза Hо будет отвергнута, хотя на самом деле она верна). Это может произойти потому, что значение статистики попало в критическую область случайно. Такую ошибку называют ошибкой первого рода, а соответствующую вероятность называют уровнем значимости критерия. Она должна быть небольшой. Кроме того, может быть допущена также ошибка второго рода : она заключается в том, что гипотеза Hо принимается, хотя на самом деле она является неверной (а верна альтернативная гипотеза H1). Отметим, что при проверке одной и той же гипотезы по выборке одного и того же объема невозможно одновременно уменьшить вероятность ошибок первого и второго рода. Это связано с тем, что с ростом критической области одновременно растут и α, и . Ведь чем больше критическая область, тем больше вероятность отклонить гипотезу и меньше вероятность ее принять (соответственно, больше вероятность отклонить верную или принять неверную). Вероятность НЕ допустить ошибку второго рода называется мощностью критерия (она равна 1 – ). Одновременно увеличить мощность критерия и уменьшить уровень значимости можно только за счет увеличения объема выборки, потому что только при этом условии выборочные значения показателей будут более точно отражать истинные характеристики распределения, а вероятность случайных отклонений уменьшится. Например, на склад поступила партия изделий. Из нее отбирают часть изделий для проверки на брак. По результатам проверки будет принята или отвергнута нулевая гипотеза, которая состоит в следующем: доля бракованных изделий в партии невелика, и партию можно принять. Предположим вначале, что в выбранных изделиях доля бракованных была велика, и по результатам выборочного контроля всю партию забраковали. Однако, есть вероятность, что проверяющему случайно попались именно плохие изделия, и на самом деле партию надо было принять, потому что остальные изделия не содержат брака. В этом случае была допущена ошибка первого рода, т.е. отклонили верную нулевую гипотезу (отвергли хорошие изделия). Теперь предположим, что в выбранных изделиях доля бракованных была невелика, и по результатам выборочного контроля партию приняли. Однако, есть вероятность, что проверяющему случайно попались именно хорошие изделия, и на самом деле партию надо было забраковать. В этом случае была допущена ошибка второго рода, т.е. принята неверная нулевая гипотеза. Из приведенных примеров видно, что чем больше изделий будет выбрано для проверки, тем меньше риск совершить и ту, и другую ошибку. При равном объеме выборки чем строже критерии проверки (больше критическая область), тем больше вероятность допустить ошибку первого рода и меньше – второго (и наоборот). В юриспуденции под нулевой гипотезой обычно имеется в виду гипотеза о том, что подсудимый невиновен. Соответственно, ошибка первого рода – это обвинение невиновного, а ошибка второго рода – это оправдание виновного. Задание низкого уровня значимости означает, что вероятность ошибки первого рода должна быть маленькой, т.е. риск принять неверное, «обвинить невиновного» должен быть маленьким. В зависимости от вида критической области все статистические критерии принято делить на три основных класса. Рассмотрим их на примере, в котором статистика имеет стандартное нормальное распределение (т.е. = N(0; 1)) и задан пятипроцентный уровень значимости (α = 0,05): 1) правосторонняя критическая область задается неравенством > кр Если α = 0,05, то площадь под графиком плотности стандартного нормального распределения справа от прямой х = кр должна составлять 0,05. Вся площадь под этим графиком справа от вертикальной оси составляет 0,5. Чтобы найти значение кр, воспользуемся функцией Лапласа, которая должна здесь принять значение 0,5 – 0,05 = 0,45. Такое значение соответствует кр = 1,64. Рисунок 20 – Правосторонняя критическая область На рисунке 20 площадь заштрихованной фигуры составляет 0,05, т.е. 5% от единицы (от общей площади графика под функцией плотности вероятности). Это означает, что Р( > кр) = α = 0,05. С такой вероятностью проверяемая гипотеза будет все-таки отвергнута, даже если она на самом деле верна. Если фактическое значение статистики критерия ≤ кр, гипотеза принимается. 2) левосторонняя критическая область задается неравенством < кр Такое значение соответствует кр = -1,64. На рисунке 21 площадь заштрихованной фигуры также составляет 0,05, т.е. Р( < кр) = α = 0,05. Если фактическое значение статистики критерия ≥ кр, гипотеза принимается. Рисунок 21 – Левосторонняя критическая область 3) двусторонняя критическая область задается неравенствами 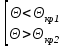 Поскольку площадь под графиком плотности распределения в критической области должна составлять 0,05, площадь каждого из двух заштрихованных участков на рисунке 22 должна составлять 0,025 (т.е. α/2). Тогда функция Лапласа при х = кр2 должна принять значение 0,5 – 0,025 = 0,475. Такое значение соответствует кр2 = 1,96. Соответственно, кр1 = -1,96. Итак, при использовании двустороннего критерия Р( < кр1) = = Р( > кр2) = α/2. Если кр1 ≤ ≤ кр2, гипотеза принимается. Рисунок 22 – Двусторонняя критическая область Рассмотрим следующий пример. Машина для расфасовки специй при поставке была отрегулирована так, чтобы средняя масса специй в пакетике в пробной партии из 50 штук составляла 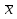 0 = 90 (г) при СКО х = 10 (г). Из расфасованной через месяц партии было отобрано 60 пакетиков, и средняя масса специй в пакетике составила 0 = 90 (г) при СКО х = 10 (г). Из расфасованной через месяц партии было отобрано 60 пакетиков, и средняя масса специй в пакетике составила 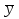 0 = 86 (г) при СКО y = 8,5 (г). Необходимо выяснить, является ли это случайным совпадением, или регулировка машины нарушена. 0 = 86 (г) при СКО y = 8,5 (г). Необходимо выяснить, является ли это случайным совпадением, или регулировка машины нарушена.Сформулируем нулевую гипотезу: регулировка не нарушена. Это означает, что на самом деле средние величины при поставке и в настоящий момент равны, т.е. М( - ) = М() – М() = 0. Будем считать, что случайная величина - имеет нормальное распределение с математическим ожиданием 0.Найдем СКО этой случайной величины. Какова дисперсия случайной величины ? D() = D((xi)/n)) = = (D(xi))/n2 = (D(xi))/n2 = 2х*n/n2 = 2х/n, где n = 50, т.е. D( ) = 100/50 = 2.Аналогично D( ) = 2y/n, где n = 60, т.е. D(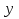 ) = 8,52/60 = 72,25/60 1,2. ) = 8,52/60 = 72,25/60 1,2.Тогда D( - ) = D() + D() = 3,2, а СКО 1,79.Итак, ( - ) = N(0; 1,79).Тогда статистика = ( - )/1,79 будет иметь стандартное нормальное распределение, т.е. = N(0, 1). Взяв в качестве оценок генеральных средних выборочные оценки 0 и 0, рассчитаем фактическое значение статистики критерия: = (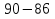 )/1,79 2,23. )/1,79 2,23.Зададимся уровнем значимости 5%. Построим двустороннюю критическую область: если фактический критерий попадает в нее, то это означает, что разница между средними слишком существенно отличается от нуля в ту или другую сторону; и тогда гипотезу о равенстве средних надо отвергнуть. По таблице функции Лапласа найдем границы этой области: Ф(кр2) = 0,5 – 0,05/2 = 0,475, тогда кр2 = 1,96; кр1 = -1,96. Так как 2,23 > 1,96, гипотеза Н0 отвергается, т.е. регулировка машины нарушена. Однако, существует пятипроцентная вероятность, что этот вывод сделан случайно (т.е на самом деле с машиной все в порядке, просто были сделаны неудачные выборки). Зададимся уровнем значимости 2%. Тогда границы критической области найдем по таблице функции Лапласа для значения этой функции Ф(кр2) = 0,5 – 0,02/2 = 0,49, тогда тогда кр2 = 2,34; кр1 = -2,34. Так как 2,23 > 2,34, на двухпроцентном уровне значимости можно принять нулевую гипотезу. Т.е. считать, что регулировка машины не нарушена. |