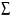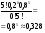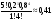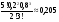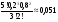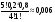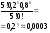Теория вероятностей и математическая статистика. Закон распределения случайной величины. Математическое ожидание 28 Дисперсия случайной величины 32
 Скачать 361.49 Kb. Скачать 361.49 Kb.
|

Дискретные случайные величиныБудем в дальнейшем рассматривать только такие эксперименты, результаты которых имеют численное значение. Это значение будем называть случайной величиной. Случайная величина может быть дискретной (принимать конечное или бесконечное число отдельных значений) или непрерывной (принимать любые значения на некотором промежутке числовой оси). Разумеется, число возможных значений непрерывной случайной величины всегда бесконечно. Например, выбор наугад любого числа из множества чисел {1; 2; 5}, или из {0; 0,5; 1; 10,5}, или из множества натуральных чисел, или любого целого числа от 5 до 10 представляет собой дискретную случайную величину. Выбор наугад любого числа из промежутка [1; 5], или любого положительного числа представляет собой пример непрерывной случайной величины. Закон распределения случайной величины. Математическое ожиданиеШрифт: полужирный, Отступ: Первая строка: 0 см, По центру, интервал Перед: 30 пт, После: 30 пт, Не отрывать от следующего, Уровень 2, Стиль: Связанный, Скрыть до использования, Экспресс-стиль, Основан на стиле: Обычный, Следующий стиль: Обычный Среднее значение дискретной случайной величины, полученное при неограниченно большом числе опытов, называют ее математическим ожиданием. Пусть проведено n экспериментов, в которых определялось значение случайной величины х. В этих экспериментах она принимала значения х1, х2,. . . , хm соответственно h(x1), h(x2), . . ., h(xm) число раз ( 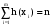 ). Величины h(xi) называют частотами. ). Величины h(xi) называют частотами.Например, рассмотрим балл, полученный студентом на экзамене, как дискретную случайную величину. Пусть из 100 студентов в потоке один человек получил два балла, 10 человек получили три балла, 40 человек получили четыре балла и 49 человек получили пять баллов. Т.е. m = 4, х1 = 2, h(x1) = 1; х2 = 3, h(x2) = 10; х3 = 4, h(x3) = 40; х4 = 5, h(x5) = 49. Рассчитаем средний балл. Для этого просуммируем общее количество баллов, набранное всеми студентами потока, как  = 1*2 + 10*3 + 40*4 + 49*5 = 437. Теперь разделим эту сумму на всех студентов 437/100 = 4,37. Итак, средний балл = 1*2 + 10*3 + 40*4 + 49*5 = 437. Теперь разделим эту сумму на всех студентов 437/100 = 4,37. Итак, средний балл 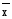 = 4,37. = 4,37.Общая формула для расчета среднего значения имеет следующий вид: 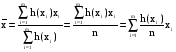 При достаточно большом n число 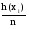 (относительную частоту) можно рассматривать, как эмпирическую оценку вероятности того, что случайная величина примет значение хi, т.е. Р(х = хi) = (относительную частоту) можно рассматривать, как эмпирическую оценку вероятности того, что случайная величина примет значение хi, т.е. Р(х = хi) = М(х) = 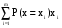 . .Если дискретная случайная величина может принимать бесконечное число значений, сумма в правой части будет представлять собой ряд. Если этот ряд не сходится абсолютно, то говорят, что математическое ожидание данной случайной величины не существует. Правило, позволяющее поставить в соответствие случайной величине некоторую вероятностную меру, будем называть законом распределения случайной величины, или ее вероятностным распределением. Для дискретной случайной величины с конечным числом значений это набор вероятностей, соответствующий каждому из ее значений. При этом сумма этих вероятностей по всем возможным значениям случайной величины должна быть равна 1: 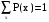 . .Это может быть, например, таблица или формула. Рассмотрим пример. Пусть вероятность того, что игрок выиграет 1000 руб., равна 0,1. Вероятность выигрыша 500 руб. равна 0,2. В случае проигрыша ему придется уплатить 300 руб. Представить вероятностное распределение выигрыша в виде таблицы и определить ожидаемый выигрыш. Случайная величина х – выигрыш – может принимать значения из множества {1000; 500; -300}. Вероятность первых двух значений задана, а вероятность проигрыша можно подсчитать как 1-(0,1 + 0,2) = 0,7. Вероятностное распределение х можно представить в виде табл.1: Таблица 1
Отсюда математическое ожидание выигрыша М(х) = 1000*0,1 + + 500*0,2 + (-300)*0,7 = -10. Это означает, что ожидаемый выигрыш представляет собой проигрыш. При многократном повторении эксперимента (игры) игрок потеряет в среднем 10 руб. за игру (хотя в отдельной игре он может и выиграть). Две случайные величины называют независимыми, если закон распределения одной из них не зависит от того, какое значение приняла другая величина. Приведем без доказательства некоторые свойства математического ожидания: 1) Математическое ожидание константы равно самой константе: с – const  M(c) = c M(c) = cНапример, если работник получает постоянную зарплату х = 30 (тыс. руб.), то ее математическое ожидание, т.е. ожидаемая зарплата будет равна 30 тыс.руб. 2) Постоянный сомножитель можно вынести за знак математического ожидания: с – const M(cx) = cM(x)Например, если один работник получает в среднем 20 тыс. руб. (х – его заработная плата, М(х) = 20), а другой работник всегда получает на 20% больше, чем первый, то заработная плата второго работника равна 1,2*х, а ее математическое ожидание равно М(1,2*х) = 1,2*М(х) = 1,2*20 =24 (тыс.руб.). 3) Математическое ожидание суммы случайных величин равно сумме математических ожиданий: M(x + y) = M(x) + M(y) Например, если в отделе работают два человека, и ожидаемая заработная плата одного из них равна 20 тыс. руб. (х – его заработная плата, М(х) = 20), а другого – 30 тыс. руб. (y – его заработная плата, М(y) = 30), то ожидаемая оплата труда в этом отделе равна М(х + y) = М(х) + М(y) = 20 + + 30 =50 (тыс.руб.). 4) Для независимых случайных величин математическое ожидание их произведения равно произведению математических ожиданий: M(xy) = M(x)M(y) (для независимых х и y) Например, пусть один работник получает в среднем 20 тыс. руб. (х – его заработная плата, М(х) = 20). Для заработной платы другого работника действует повышающий коэффициент по сравнению с первым работником, и этот коэффициент представляет собой случайную величину y. В среднем он получает на 20% больше, чем первый, т.е. М(y) = 1,2. Величина коэффициента не зависит от зарплаты первого работника. Тогда ожидаемая заработная плата второго работника равна М(хy) = M(x)M(y) = 1,2*20 =24 (тыс.руб.). Однако, если повышающий коэффициент зависит от зарплаты (например, при зарплате до 18 тыс.руб. от равен 1,21, от 18 до 20 тыс.руб. – 1,2, больше 20 тыс.руб. – 1,18), то тогда воспользоваться формулой нельзя. Свойства (3) и (4) будут верными не только для двух, но для любого конечного числа случайных величин. 5) При увеличении (уменьшении) всех значений случайной величины на константу, ее математическое ожидание увеличится (уменьшится) на эту же константу: с – const M(x - с) = M(x) – сНапример, если ожидаемая зарплата за месяц составляет 30 тыс. руб. (х – заработная плата, М(х) = 30), и из нее каждый месяц вычитают 800 руб. на оплату проездного билета, то математическое ожидание зарплаты за вычетом оплаты проездного составит М(х – 0,8) = М(х) – 0,8 = 29,2 (тыс.руб.). 6) Математическое ожидание отклонения случайной величины от своего математического ожидания равно нулю: M(x – М(х)) = 0 Например, если ожидаемая зарплата за месяц составляет 30 тыс. руб. (х – заработная плата, М(х) = 30), то ее ожидаемое отклонение от 30 тыс. руб. составляет ноль. Дисперсия случайной величиныДисперсией случайной величины называют математическое ожидание квадрата отклонения случайной величины от своего математического ожидания (если последнее существует): D(x) = M((x-M(x))2). Для дискретной случайной величины: 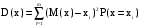 Если дискретная случайная величина может принимать бесконечное число значений, сумма в правой части будет представлять собой ряд. Для чего подсчитывают дисперсию? Математическое ожидание само по себе не дает нам верного представления о характере исследуемого явления, о том, как может изменяться случайная величина. Мы узнаем только ее среднее значение при большом числе экспериментов, но не можем судить о том, каков в среднем разброс ее значений вокруг этого числа. Судить об этом позволяет дисперсия. Отклонения при ее вычислении берутся в квадрате, так как в противном случае отклонения в разные стороны (значения больше и меньше среднего) компенсировали бы друг друга. Выбор для избавления от знака именно возведения в квадрат, а не какого-либо другого действия (например, взятия по модулю) объясняется тем, что на этом факте основывается доказательство некоторых важных свойств дисперсии, изучаемых математической статистикой. Приведенное выше выражение для дисперсии является неудобным при проведении практических вычислений, поэтому выведем другое. 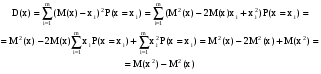 Итак,  Приведем без доказательства некоторые свойства дисперсии: 1) Дисперсия неотрицательна (по определению): D(x) 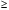 0 02) Дисперсия постоянной равна нулю: с – const D(c) = 0Например, если работник получает постоянную зарплату х = 30 (тыс. руб.), то ее дисперсия будет равна нулю (в самом деле, характеристика рассеяния нулевая). 3) Постоянный множитель можно выносить за знак дисперсии, возводя его в квадрат: с – const D(cx) = c2D(x)Например, пусть дисперсия заработной платы работника равна 4 (х –заработная плата, D(х) = 4). Другой работник всегда получает на 20% больше, чем первый, т.е. заработная плата второго работника равна 1,2*х. Тогда дисперсия заработной платы второго работника равна D(1,2*х) = = 1,22*D(х) = 1,44*4 = 5,76. 4) Для независимых случайных величин дисперсия их суммы равна сумме дисперсий: D(x + y) = D(x) + D(y) (для независимых х и y) Например, пусть дисперсия заработной платы одного работника равна 4 (х – его заработная плата, D(х) = 4), а другого – 5 (y – его заработная плата, D(y) = 5). Тогда дисперсия суммарной заработной платы составит D(x + + y) = D(x) + D(y) = 4 + 5 = 9. Однако, выполнить расчет таким образом можно лишь в случае, когда заработные платы этих работников не зависят друг от друга. Если они зависимы, воспользоваться формулой нельзя. Следует отметить, что дисперсия разности двух случайных величин будет равна тоже сумме дисперсий (а не разности). Это следует из свойств (3) и (4), поскольку при возведении в квадрат сомножителя (-1) получают 1. Свойство (4) будет верным не только для двух, но для любого конечного числа случайных величин. 5) При увеличении (уменьшении) всех значений случайной величины на константу, ее дисперсия не изменится (это следует из свойств (2) и (4): с – const D(x - с) = D(x)Например, если дисперсия среднемесячной зарплаты равна 4, и из зарплаты каждый месяц вычитают 800 руб. на оплату проездного билета, то дисперсия зарплаты за вычетом оплаты проездного будет все равно равна 4. Например, рассмотрим случайную величину х – количество проданных в день автомобилей. Эта величина измерялась в течение 100 дней, и за это время принимала значения {0; 1; 2; 3; 4} соответственно 18, 15, 28, 15 и 24 число раз. Необходимо определить дисперсию вероятностного распределения х. Будем считать, что число экспериментов – 100 - достаточно велико, чтобы можно было рассматривать относительную частоту в качестве эмпирической оценки вероятности. Поэтому чтобы определить вероятности, разделим каждую из частот на 100. Представим вероятностное распределение в виде табл.2, приписав к ней две строки для вспомогательных вычислений. Таблица 2
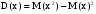 = 6,46-2,122 = 6,46-2,122 1,97. 1,97.Использовать полученную оценку все же представляется затруднительным. Ее нельзя сравнить с математическим ожиданием, так как ее единицы измерения не имеют экономического смысла (“автомобили в квадрате”). Поэтому, чтобы определить, действительно ли разброс количества продаж вокруг величины 2,12 так велик, извлечем корень из дисперсии 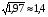 . Полученный результат имеет те же единицы измерения, что и рассматриваемая случайная величина (в данном случае он измеряется в количестве автомобилей, т.е. в штуках). . Полученный результат имеет те же единицы измерения, что и рассматриваемая случайная величина (в данном случае он измеряется в количестве автомобилей, т.е. в штуках).Эту величину называют средним квадратическим отклонением (СКО) и обозначают  . .СКО = 1,4 (шт.) – много это или мало? Вероятно, если бы объем продаж составлял в среднем, например, 10 машин в день, то такая величина характеризовала бы небольшой разброс. В рассматриваемом случае М = 2,12 (шт.). Чтобы оценить полученный результат, необходимо подсчитать относительный показатель, который позволит сравнить СКО с математическим ожиданием. Отношение СКО к математическому ожиданию случайной величины называют коэффициентом вариации: 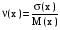 . Он представляет собой безразмерную величину (можно перевести его в проценты, умножив на 100%). . Он представляет собой безразмерную величину (можно перевести его в проценты, умножив на 100%).Для рассмотренного примера коэффициент вариации равен 1,4/2,12 = = 0,66 или 66%. Рассмотренные выше математическое ожидание, дисперсия, СКО и коэффициент вариации представляют собой числовые характеристики случайной величины. Кроме них, существуют и другие числовые характеристики, которые пока рассматривать не будем. Биномиальное распределениеРассмотрим следующую ситуацию. Игральную кость бросают четыре раза, причем в качестве исхода каждого из этих опытов них рассматривают события А – выпало 6 очков, или В – выпало не 6 очков. В каждом из опытов Р(А)=1/6; Р(В)=5/6. В качестве случайной величины х рассмотрим число выпадений 6 за эти 4 опыта; х  {0; 1; 2; 3; 4}. Определим, например, Р(х = 2). Этому значению случайной величины соответствуют следующие последовательности событий: ААВВ; АВАВ; АВВА; ВААВ; ВАВА; ВВАА. Вероятность каждого из них равна (1/6)2*(5/6)2. Вероятность суммы этих шести равновероятных событий равна 6*(1/6)2*(5/6)2 = 25/216 = Р(х = 2). {0; 1; 2; 3; 4}. Определим, например, Р(х = 2). Этому значению случайной величины соответствуют следующие последовательности событий: ААВВ; АВАВ; АВВА; ВААВ; ВАВА; ВВАА. Вероятность каждого из них равна (1/6)2*(5/6)2. Вероятность суммы этих шести равновероятных событий равна 6*(1/6)2*(5/6)2 = 25/216 = Р(х = 2). Почему событий оказалось именно 6? Это число представляет собой число сочетаний из 4 по 2 (шестерка могла выпасть в любых двух опытах из четырех): С24 = 4!/(2!*2!) = 6. Рассмотрим более общую ситуацию. Каждый из n независимых опытов имеет два исхода. Вероятность одного из них равна p, а другого (1- p) (в каждом опыте). Случайная величина х представляет собой число опытов, в которых имел место первый из этих исходов. Тогда ее вероятность можно вычислить по формуле: Р(х) = Cxnpx(1 - p)n - x = px(1 - p)n - x n!/(x!(n - x)!) При этом говорят, что величина х имеет биномиальное вероятностное распределение (n N, x = 0,n, 0 < p < 1). Формула, которая выведена выше, представляет собой биномиальный закон распределения дискретной случайной величины.Например, 5 станков работают независимо друг от друга. Вероятность поломки в течение дня для каждого из них равна 0,2. Найти вероятностное распределение числа станков, сломавшихся в течение дня. Дискретная случайная величина х – число станков, сломавшихся в течение дня: х {0; 1; 2; 3; 4; 5}. Имеет место 5 независимых опытов, в каждом из которых возможен один из двух исходов – станок сломался (с вероятностью р = 0,2) или не сломался (с вероятностью 1 - 0,2 = 0,8). Поэтому величина х распределена биномиально, т.е. ее распределение определяется формулой: Р(х) = Cx50,2x0,85 - x = 0,2x(0,8)5 - x 5!/(x!(5 - x)!).Представим его в виде таблицы 3. Таблица 3
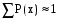 . .Определим математическое ожидание и дисперсию биномиального распределения. Используем свойства математического ожидания. Присвоим результатам проводимых n экспериментов числовые значения – первому исходу (с вероятностью р) - 1, а второму – 0. Это n случайных величин. Математическое ожидание каждой из них равно 1*р + 0*(р – 1) = р. Случайная величина х представляет собой сумму n таких величин, следовательно, их математические ожидания необходимо сложить: М(х) = np. Проведем аналогичные рассуждения для дисперсии. Отметим при этом, что n случайных величин являются независимыми. Математическое ожидание квадрата каждой из них равно р, а квадрат математического ожидания – р2. Отсюда дисперсия каждой из них равна р - р2 = р(1 - р). Тогда дисперсия х является суммой этих дисперсий: D(x) = np(1 - p). Подсчитаем эти величины для примера со станками: М(х) = np = = 5*0,2 = 1; D(x) = np(1 - p) = 5*0,2*0,8 = 0,8; 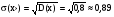 ; ;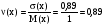 . . |