теория информации. ТИ (Best). Лекции по предмету "Теория информации" Красноярск 2002
 Скачать 1.06 Mb. Скачать 1.06 Mb.
|

|
Пример: Сообщения передаются в двоичном коде. Время передачи от нуля до одной секунды, r0 = 1 сек, 1) Символы равновероятны и независимы. 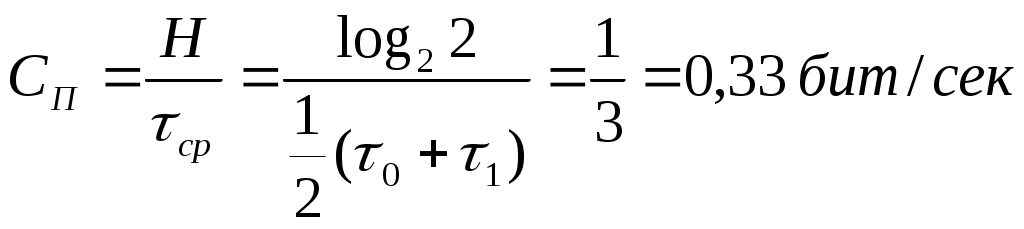 2) Символы неравновероятны 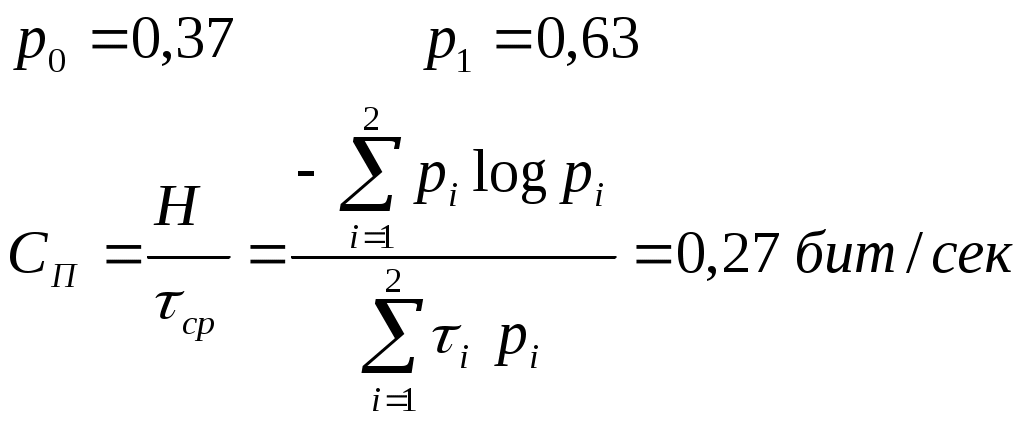 Дискретный канал с помехами Характеризуется канальной матрицей 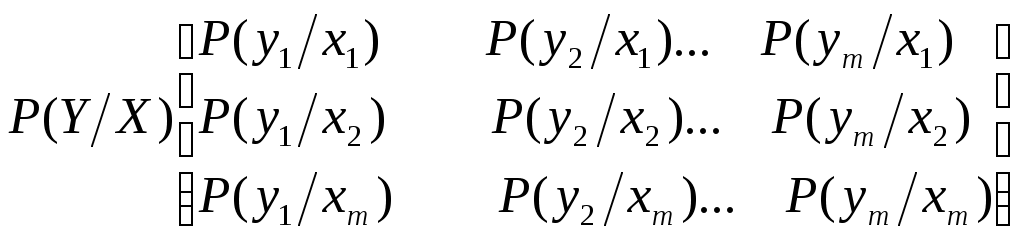 … Взаимная информация 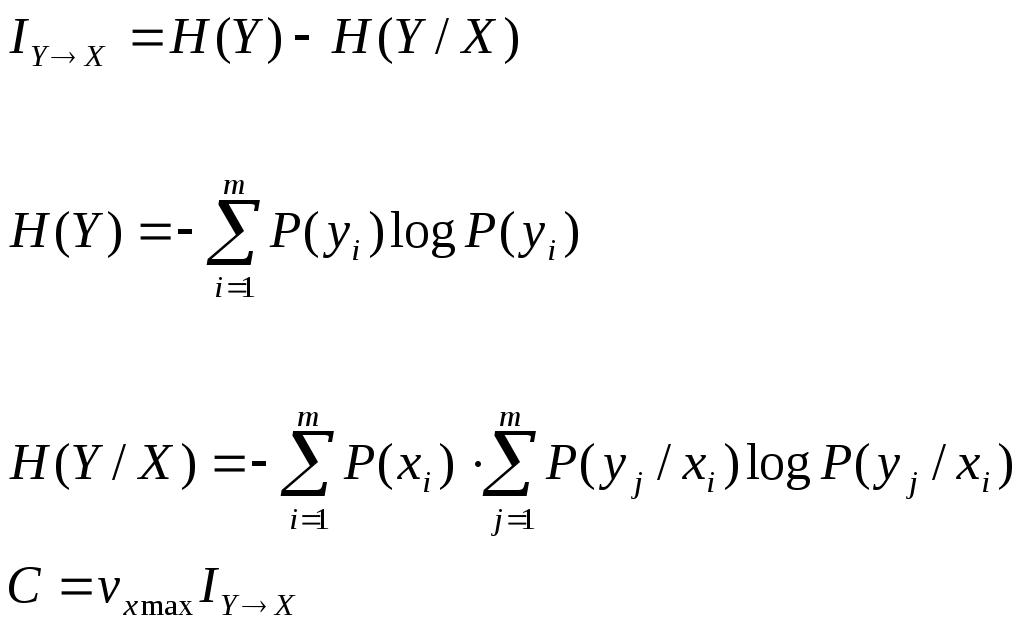 Энтропия на выходе приёмника Средняя условная энтропия - это максимальное значение определить сложно. … … Определим пропускную способность канала связи, по которому передаются двоичные сигналы со скоростью vx, если вероятность искажения сигнала равна p. Имеет источник информации Разложение выполним в виде диаграммы 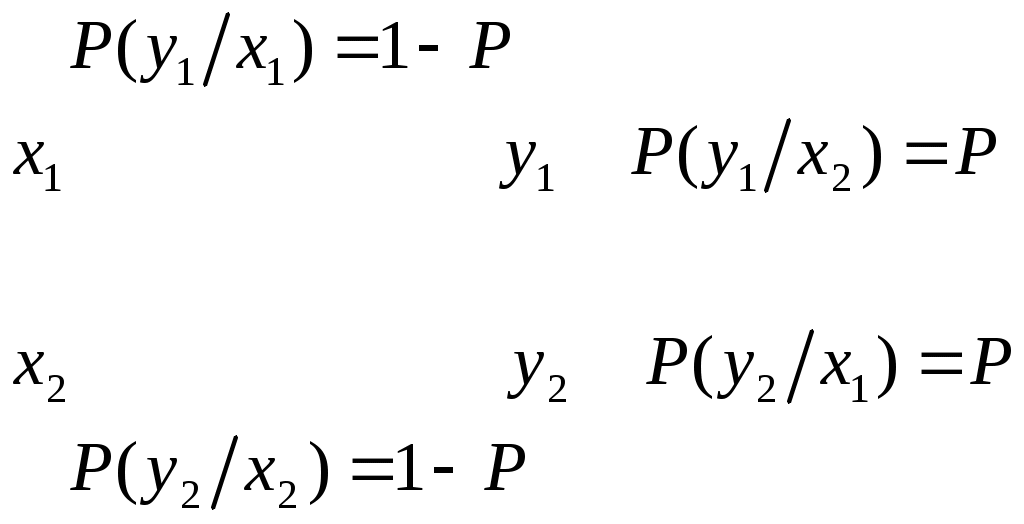    Правильный приём   Канал такого типа называют симметричным бинарным, (т.к. два числа) Искажение Определим среднюю условную энтропию 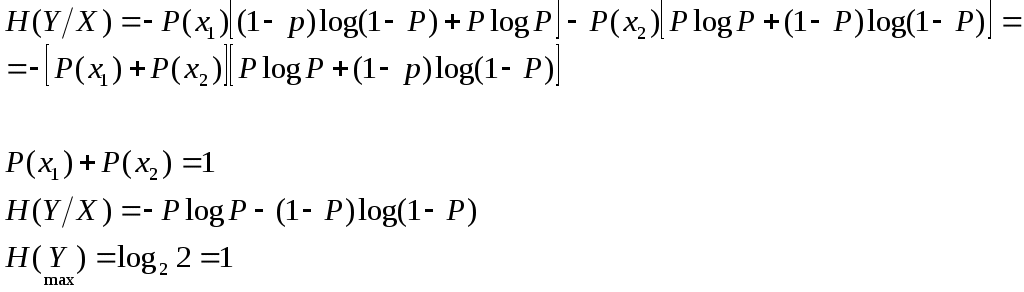 Учитывая, что , получим, что объединили - , т.е потери не будут зависеть от характерис-тики источника Поэтому 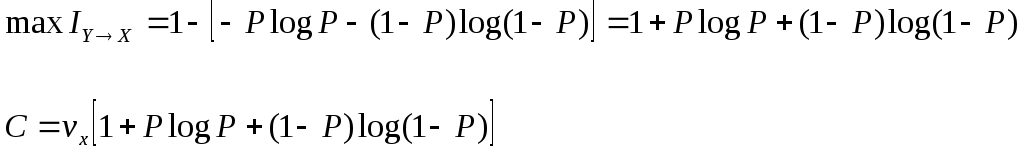 Пропускная способность канала Рассмотрим два крайних условия: 1. Вероятность искажения (Р=0), следовательно, помех нет, следовательно, С = vx и она имеет свое максимальное значение 2. Р=1/2. Значение С = 0 – это минимальное значение пропускной способности Пример: Определить пропускную способность канала связи, способного передавать 100 симв./сек . Каждый символ искажается с вероятностью 0,01. Теорема о кодировании Шеннона для дискретного канала с помехами Если источник информации имеет энтропию H(z), а канал обладает пропускной способностью С, то: 1. Сообщение, вырабатываемое источником, всегда можно закодировать так, чтобы скорость передачи vz была близка величине vz max. И чтобы при этом вероятность ошибки в определении переданного символа была меньше заданного числа. 2. Не существует метода кодирования, позволяющего вести передачу со скоростью выше vz max и с малой вероятностью ошибки. То есть, если H’(z) ≤ C, то может быть подобран специальный код, позволяющий вести передачу с малой вероятностью ошибки. Если H’(z) > C то такого кода не существует. Очевидно, что при уменьшении скорости передачи, можно повысить достоверность, например, методом многократного повторения. Для обеспечения нулевой ошибки, кажется, что скорость передачи должна стремиться к нулю. Теорема же утверждает, что всегда можно обеспечить скорость передачи равной Vz max путем выбора подходящего ввода. Корректирующие коды Это коды, которые позволяют обнаруживать и исправлять ошибки. n – значность кода (из скольки символов состоит данная кодовая комбинация) N0 = 2n, n – число возможных кодовых комбинаций. Идея возможности обнаружения ошибок заключается в том, что для передачи используются не все комбинации, а только их часть N. И это значение N Используемые комбинации N называются разрешенные, а остальные N0–N – это запрещенные комбинации. Если в результате действия помех разрешенная комбинация превращается в запрещенную, то это обнаруживает наличие ошибки. Если совокупность ошибок превращает одну разрешенную комбинацию в другую разрешенную комбинацию, то такие ошибки обнаружены не будут. Примером кода, обнаружившего одиночную ошибку, является коды с контролем по четности. Сущность таких кодов состоит в следующем: К исходной кодовой комбинации добавляют 1 или 0, таким образом, чтобы количество (сумма) единиц всегда была четной. Сбой любого одного символа обнаружит ошибку.   информационный информационный
Чтобы принять сигнал правильно, надо повторить передачу. Количество символов, на которое одна кодовая комбинация отличающаяся от другой кодовой комбинации, называется кодовым расстоянием и обозначается буквой d. d0 – минимальное кодовое расстояние – минимальное количество символов, на которое кодовая комбинация отличается друг от друга. Для того, чтобы определить кодовое расстояние достаточно просуммировать кодовые комбинации по правилам двоичного поля и подсчитать число единиц в полученном результате. Пример: Для кода 1 А1 = 00 0 0 = 0 Правила: А2 = 01 1 0 = 1 четн. – 0 А3 = 10 0 1 = 1 нечетн. – 1 А4 = 11 1 1 = 0 Определим кодовую комбинацию А1А2 01 01 Для кода 2 А1=000 А2А4 011 А3А2 101 А2=011 110 d = 2 011 d = 2 А3=101 101 110 А4=110 Ошибку можно не только обнаружить, но и исправить, если принятая кодовая комбинация ближе к исходной, чем к любой другой разрешённой комбинации. Пример: Построим код: К коду 2 добавим два символа, повторив первых два символа получим код 3: Код 2 А1=000 А2=011 А3=101 А4=110 Код 3
информационные разряды контрольные разряды Определим кодовое расстояние между комбинациями Строим матрицу кодовых расстояний
Пусть передаётся комбинация А3, и она содержит ошибку матрица кодовых расстояний
vx ближе всего к А3, следовательно посылалась А3 и мы ошибку исправили. Корректирующая способность кода зависит от минимального кодового расстояния d0. Если d0 = 3, то он может исправлять ошибку, то есть корректирующую способность кода можно повышать, если увеличивать минимальное кодовое расстояние. Для построения кодов, которые обнаруживают и исправляют одиночную ошибку d0 = 3, должно выполняться неравенство: nи – количество информационных разрядов n – значность кода nк – количество контрольных разрядов n = nи + nк Поэтому результаты сведем в таблицу:
Предположим, что строим код на тридцать два сообщения nи = 5, выделяем столбец nк = 4 n = 9 Расчеты можно вести по формуле. Для кода, который обнаруживает двойную ошибку, а исправляет одиночную: Обозначим буквой: r – кратность обнаруживающих ошибок; s – кратность исправляемых ошибок; Тогда для кодов обнаруживающих и исправляющих ошибки: d0 = r + s + 1, для кодов, которые только обнаруживают ошибки d0 = n + 1, для кодов, которые только исправляют ошибки d0 = 2s + 1 (когда r > s). Если d0 r s 1  0 0 отличие комбинации 0 0 отличие комбинации 2 1 0 обнаружение одиночной ошибки3 1 1 обнаружение одиночной ошибки и исправление одиночной ошибки3 2 0 обнаруживающий 2-ую ошибкуКоличество контрольных разрядов и значность кода для разных минимальных кодовых расстояний, связано соотношением: Для кодов, обнаруживающих все трехкратные ошибки.  количество обнаруженных ошибок Для кодов, исправляющих двойные ошибки 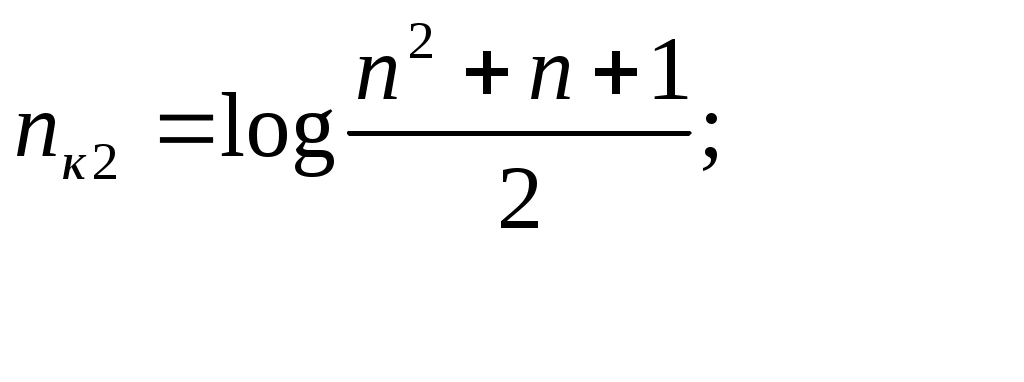 Для кодов, исправляющих тройные ошибки: Для кодов, исправляющих S ошибок: Пример: Требуется передавать, обнаруживающим трёхкратные ошибки, все комбинации пятизначного двоичного кода. Чему равна общая длина кода ? r – кратность обнаруживающих ошибок. s – кратность исправляемых ошибок. nи = 5; nк = 1 + log[6 + log6] = 5 n = nи + nк = 10 Пример: Определить количество информационных разрядов кода длиной в пятнадцать символов, если код исправляет две ошибки. n=15 nи = n - nк = 15 – 7 = 8 Исправление ошибок с помощью полной кодовой таблицы Процесс исправления ошибок поясняется с помощью диаграммы. Ak – разрешённые комбинации Bj – запрещённые комбинации А 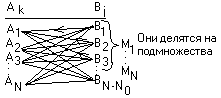 1 может искажена и может превратиться в B1 или B2 и т.д. в любую из запрещённых комбинаций. Запрещённые комбинации делятся на подмножества Hk. Способ приема состоит в том, что если принимается комбинация Bj, которая попадает в подмножество Мк, то считается, что принята комбинация Ак (M1 соответствует тому, что передавалась комбинация A1). Исправляющая способность кода будет зависеть от выбора разбиения или от стратегии. Пример: Рассмотрим пример построения КУ. Пусть li – вектор ошибки, он имеет те же размерность, что и кодовая комбинация. 1 – искажения есть, 0 - искажений нет. Пусть кодируется набор из 4-х комбинаций. А1=0001 А2=0101 А3=1110 А4=1111 Bj=Ак+li
Разбиение Разбиение запрещенных кодовых комбинаций на множества зависит от статистики ошибок и выбранной стратегии. Если ошибки в каждом символе независимы, то вероятность ошибок убывает с повышением ее кратности. Для уменьшения средней вероятности ошибки следует в начале исправлять ошибки меньшей кратности. На практике действуют следующим образом: оставляют комбинации в сроках с низшей кратностью и вычеркивают одинаковые комбинации в строках с высшей кратностью. Действуя, таким образом получают таблицу комбинаций:
Т.е. Исправили десять одинарных и две двойные ошибки. Если статистика ошибок такова, что большую вероятность имеют ошибки высшей кратности, то разбиение изменяют: оставляют комбинации в строках с высшей кратностью и вычеркивают в строках с низшей. “-“ значит действие помехи переходит в разрешенную комбинацию и мы ее обнаруживаем.
Если статистика ошибок такова, что какая-нибудь комбинация искажается больше, чем другие, например, комбинация А1, то стратегия разбиения будет другая: оставляем все кодовые комбинации соответствующие А1, т.е. М1, а остальные вычеркиваем: комбинации, которые не совпадают, остаются
Систематические коды Это коды, в которых контрольные и информационные разряды размещаются по определенной системе. Закономерности, заложенные в структуре этих кодов, позволяют проводить декодирование более простым способом, чем методом полной кодовой таблийы. Кодовый вектор – последовательность 0-й и 1-й кодовой комбинации. Вес кодового вектора – число единиц в кодовой комбинации. Нулевой вектор – кодовая комбинация, состоящая из одних нулей. n – значность кода (из скольки символов состоит кодовая комбинация); nu – число информационных разрядов; nk – число контрольных разрядов; Пример: Для систематических кодов применяют обозначение: Код(n, nu) Код (5,3) Построение систематических кодов производится следующим образом: в качестве первого берется нулевой вектор, затем составляется производящая матрица. Она имеет nи – строк, n – столбцов. В качестве строк производящей матрицы берутся любые линейно независимые n-значные векторы, отстоящие друг от друга не менее, чем на заданное кодовое расстояние. Строки матрицы G – являются кодовыми векторами. Первый вектор - нулевой. Линейно независимыми называются векторы, для которых выполняется условие: v1, v2,...,vк v1 + v2 + ...+ vк ≠ 0 Остальные кодовые векторы определяются количеством: 1 –нулевой вектор. Остальные кодовые векторы получаются в результате суммирования строк производящей матрицы G в различных сочетаниях. Для обнаружения ошибок составляется множество проверочных векторов, ортогональных векторам кода. Т.е. если кодовый вектор v образован символами а1, а2,…, аn, а ортогональный вектор u образован символами – b1, b2,..., bn, то Из векторов u составляется проверочная матрица Н. Она имеет nк – строк, n-столбцов. Строками матрицы Н являются любые линейно-независимые векторы u. Пример: Пусть строится код (5,3) с минимальным кодовым расстоянием d0=2. Он позволяет обнаруживать все одиночные ошибки. Составим производящую матрицу G: Три строки, т.к. nu = 3, n = 5 – столбцы Комбинации Результат комбинации 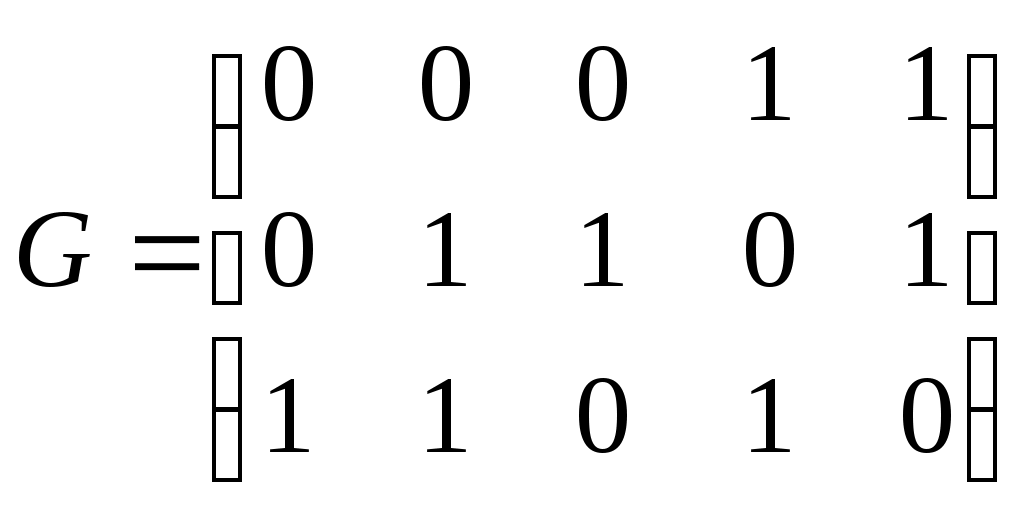 Нулевой вектор Строки матрицы G 1 + 2 2 + 3 1 + 3 1 + 2 + 3    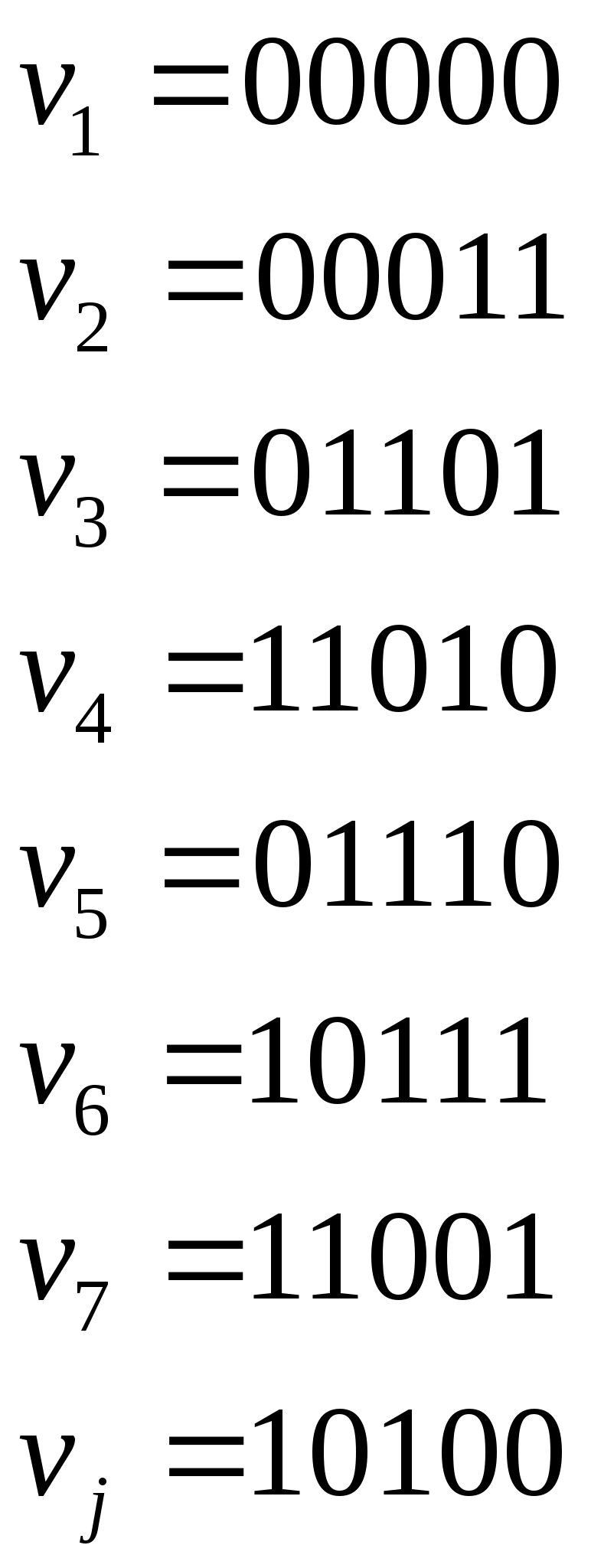 Можно было бы построить G из любой другой тройки векторов, кроме сочетаний v2v3v5, v2v4,v1 и т.д. (семь штук), т.к. эти сочетания линейно зависимы, т.е. v2 + v4 + v7 ≠0. Построим ортогональные векторы u (проверочные). Составим v2 0 b1 + 0 b2 + 0 b3 + 1 b4 + 1 b5 = 0 b4 + b5 = 0 v3 b2 + b3 + b5 = 0 v8 b1 + b3 = 0 Для любого вектора u должно выполняться 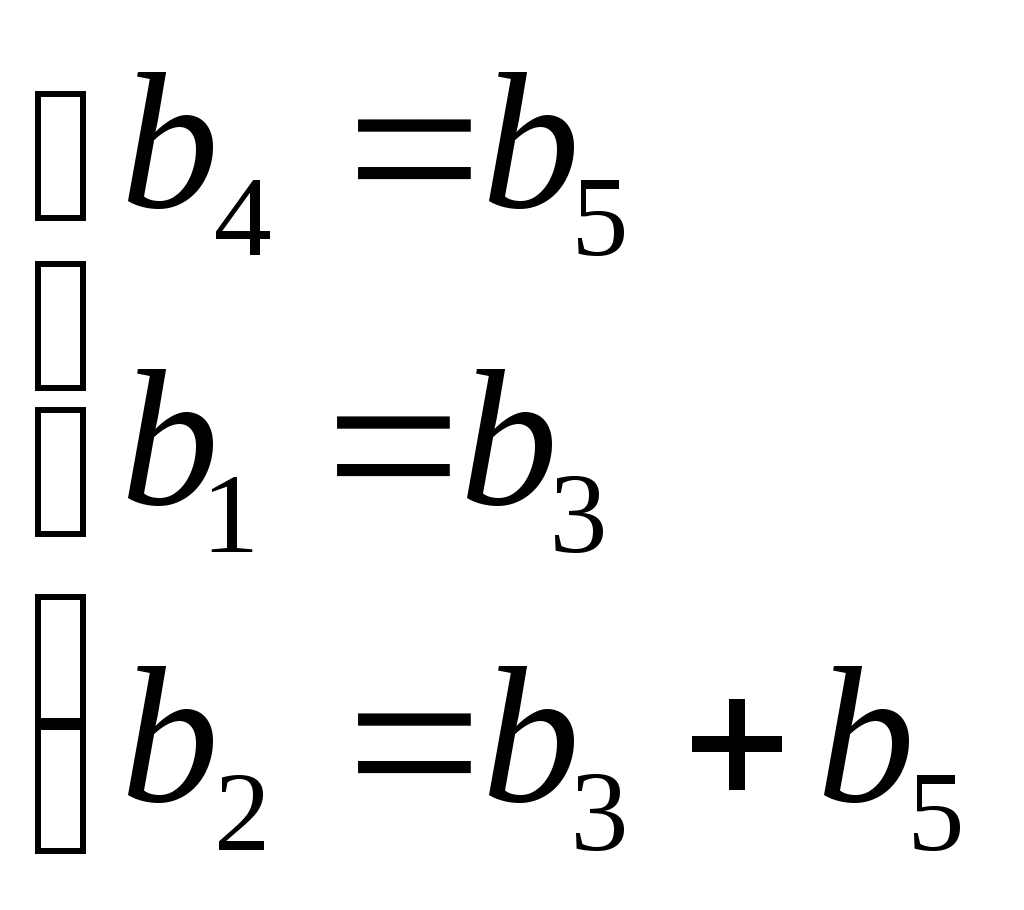 Перебирая все удовлетворяющие этим условия сочетания, получили: u1 = 00000 u2 = 01011 u3 = 10111 u4 = 11100 Из этих векторов необходимо составить проверочную матрицу Н Декодирование систематических кодов 1. Декодирование с помощью полной кодовой таблицы. Рассчитаем параметры этой таблицы N = 25 = 32 – код пяти значений N0 = 23 = 8 – разрешённая комбинаяция N - N0=32-8=24 – запрещённая коибинация ( кодовых исправлений 24 ошибки ) Строим полную кодовую таблицу. В качестве первой строки используем разрешенные комбинации v1 – v8
Общий метод декодирования состоит в следующем: Приняв некий вектор vx, содержащий ошибку, его отыскивают в полной кодовой таблице и соотносят с тем кодовым вектором, который стоит в верхней строке этого столбца. Пример: vx=00111, находим в таблице и соотносят с 01 строкой, т.е. v = 00011 Достоинство метода: его универсальность, возможность применять различные стратегии. Недостаток: громоздкость кода и только 3-и ошибки. 2. Декодирование с проверкой на четность. С помощью ортогональных векторов u из матрицы Н можно установить связь между составляющими векторов v. Используя условие ортогональности: Составляющие 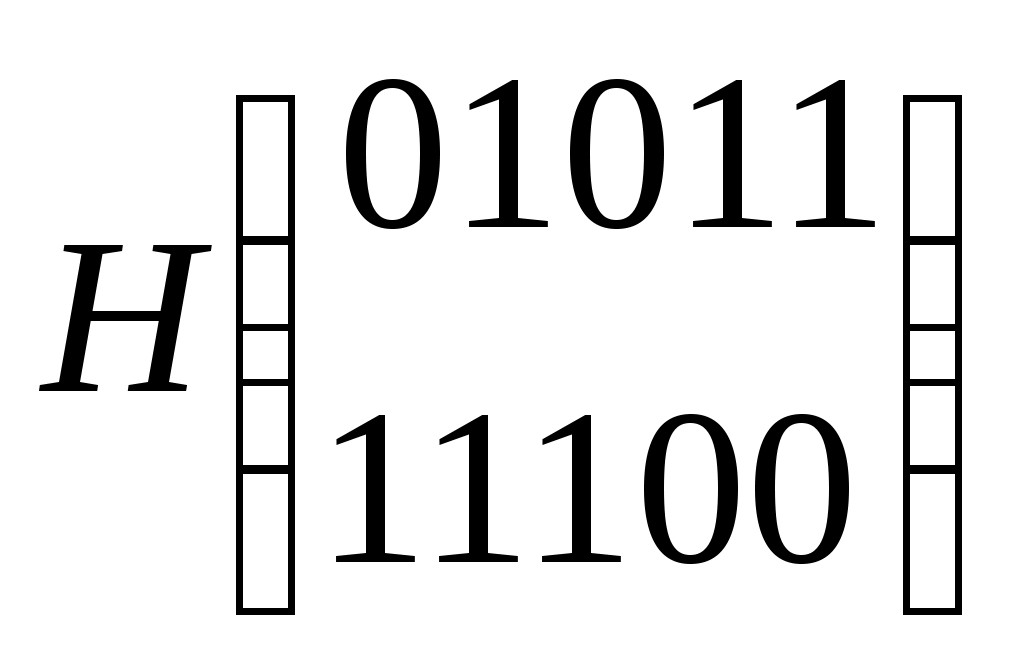  схема проверок: схема проверок:На основании векторов u можно записать схему проверок   Пример: , пусть принят вектор vx = 00110. Он имеет координаты а1 а2 а3 а4 а5. Составим схему проверок.  Если бы ошибок не было бы, то здесь были бы нули. Возможность кода к исправлению ошибки можно объяснить схемой
Следовательно, данный код может исправить во втором бите, обнаружить ошибку четвёртом или пятом бите, обнаружить ошибку в первом и третьем бите. Для исправления всех ошибок надо, чтобы каждый бит появлялся в оригинальной комбинации строк в таблице проверки, и так будет, когда d0=3 и добавиться ещё одна проверка. Декодирование с помощью корректирующего вектора Составляется корректирующий вектор, принятая кодовая комбинация умножается на корректирующий вектор, если принятая комбинация без ошибок, то корректирующий вектор равен нулю (т.е. результат умножается).Если есть ошибка, то результат ненулевой, каждой ошибке ставится в соответствие свой ненулевой результат умножения. Составляющие вектора С c1,c2,..,ci представляют собой скалярное произведение принятого вектора vx на строки исправляющей матрицы Рассмотрим i-ую строку полной кодовой таблицы Умножим эту строку на вектор uj, то получим 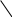  =0 =0 =0 Метод декодирования состоит из следующих операций: По полной кодовой таблице и матрицы Н вычисляют корректирующий вектор С; Принятый вектор vx умножают на векторы матрицы Н и вычисляют корректирующий вектор. Сравнивают полученные значения корректирующего вектора с имеющимся шаблоном и определяют ошибку Пример: Нужно выбрать систему кодирования. Возьмём ту же систему кодов и H. 1. Определение шаблонов корректирующего вектора Векторы ошибок 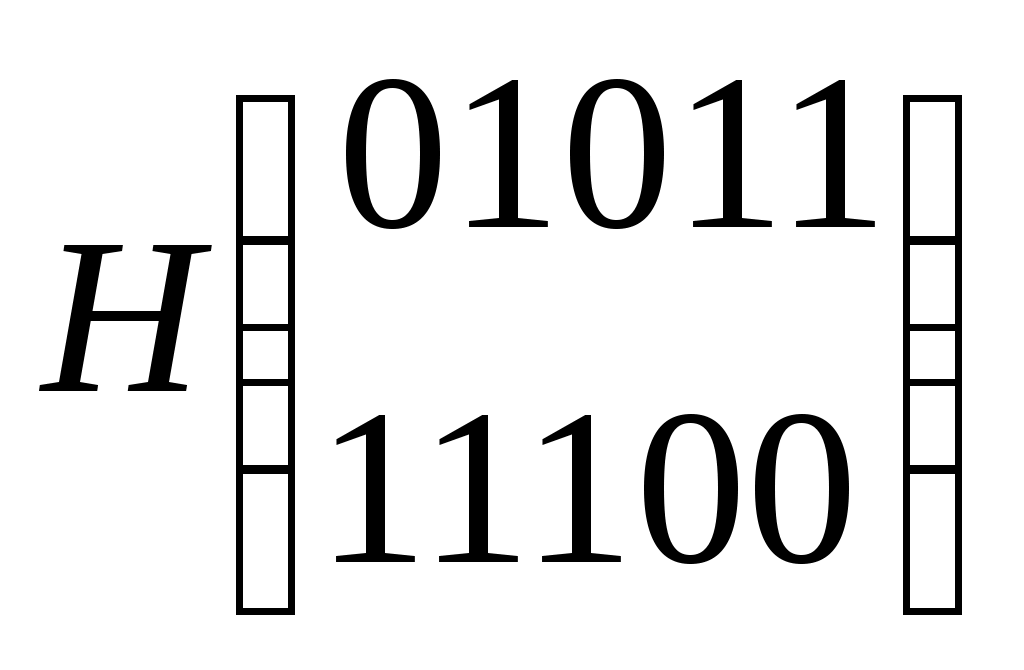 шаблоны 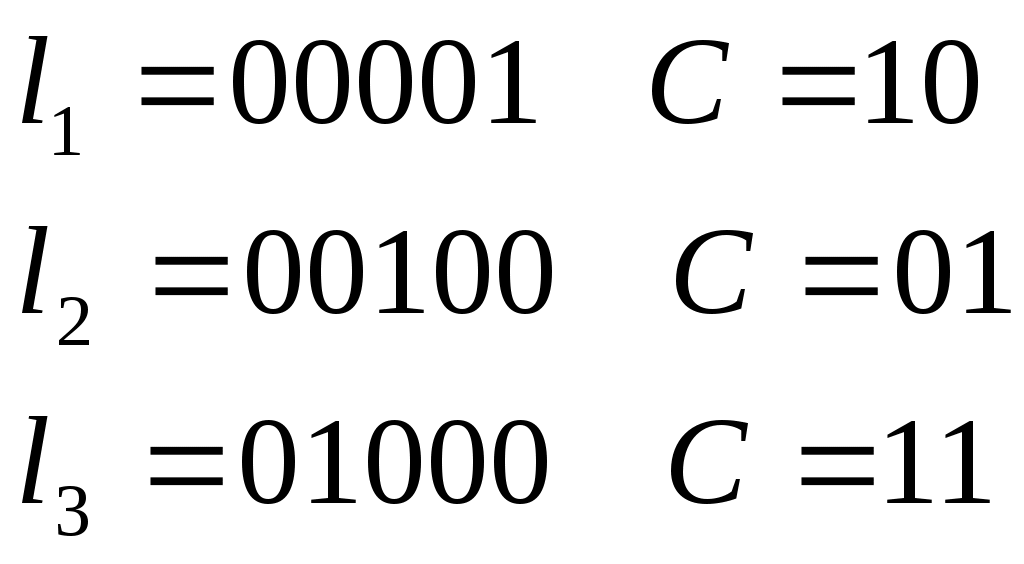 Для вектора e1 построение шаблона. e1: e1u1 = 0000101011 = 1 C1 = 1 e1u2 = 0000111100 = 0 C2 = 0 Следовательно, вектору e1 ставится в соответствие вектор С = (10) Для e2: e2u1 = 0010001011 = 0 C1 = 0 e2u2 = 0010011100 = 1 C2 = 1 Для e3: e3u1 = 0100001011 = 1 C1 = 1 e3u2 = 0100011100 = 1 C2 = 1 Шаблоны известны на приёмной стороне ещё до посылки комбинации 2. Определение корректирующего вектора Пусть принят вектор vx = 01001   Сравниваем полученный вектор ошибки с нашим шаблоном и определяем, что это e2. 3) Исправляем ошибку 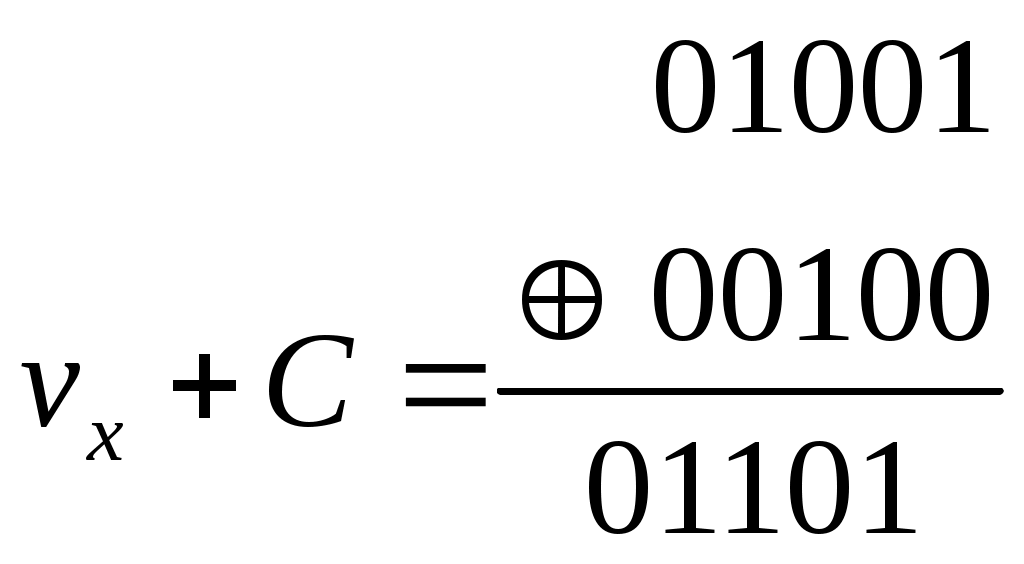 , что соответствует комбинации v3. , что соответствует комбинации v3.Можно строить образующую матрицу достаточно простым способом, например, единичной матрицей nu ni. 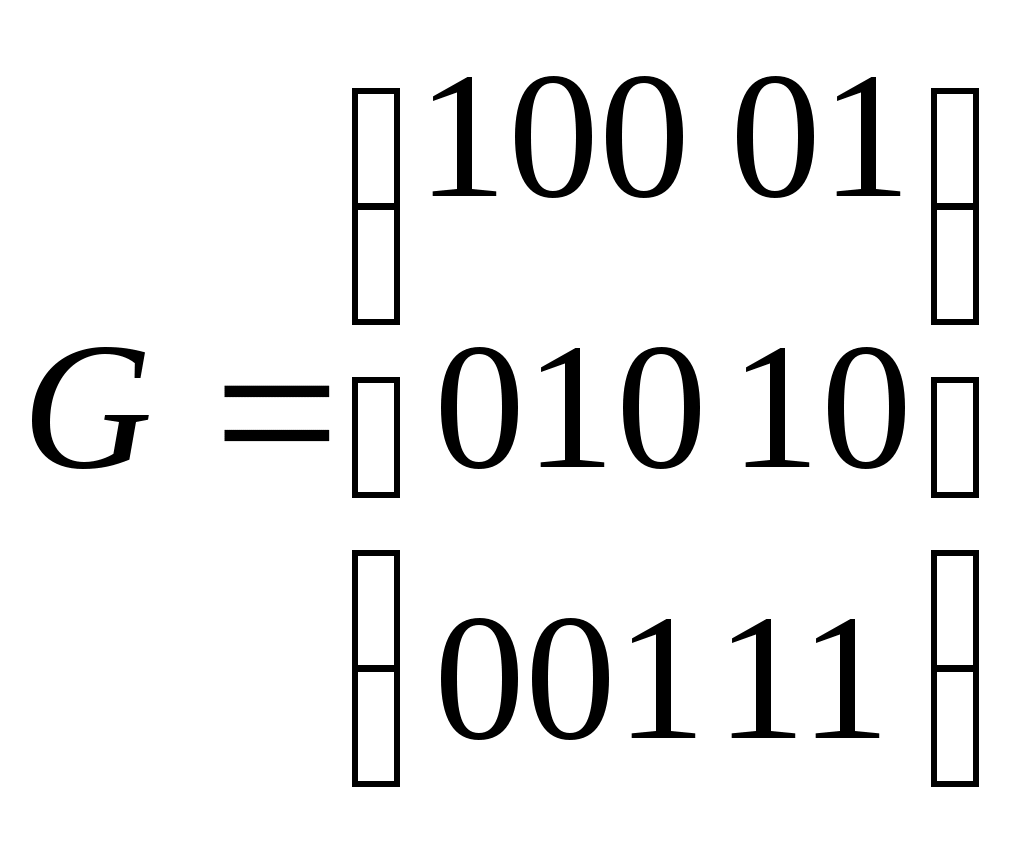 Эта матрица порождает восемь кодов, которые также позволяют обнаружить одиночную ошибку. Эта матрица порождает восемь кодов, которые также позволяют обнаружить одиночную ошибку.Преимущество кода состоит в том, что его можно легко составить, в исправляющих способностях выйгрыша нет. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||