теория информации. ТИ (Best). Лекции по предмету "Теория информации" Красноярск 2002
 Скачать 1.06 Mb. Скачать 1.06 Mb.
|

Код ХафманаОтносят к группе неравномерных кодов. С помощью кодов Хафмана получают сообщения, в которых содержатся наименьшее среднее число символов на букву, т.е. это оптимизирующие коды. Методика построения кодов следующая: Пусть есть алфавит А, содержащий буквы а1, а2, …, аn, вероятности появления которых р1, р2,…, рn. Буквы алфавита располагаем в порядке убывания их вероятностей а1, а2, …, аn-2 b p1, р2,…, рn-2 pn-1 + pn Алфавит А1 называют сжатым, полученным из алфавита А путем однократного сжатия. Буквы алфавита А1 располагаем в порядке убывания их вероятностей. Затем проводим процедуру сжатия, получаем алфавит А2. Продолжаем процедуру сжатия до тех пор, пока у нас не останется 2 буквы.
Процедура кодирования Две буквы последнего алфавита кодируем 1 и 0. Затем кодируется предыдущий алфавит. Процесс кодирования закончен. Чтобы определить эффективность, надо посчитать среднее число символов на алфавит. 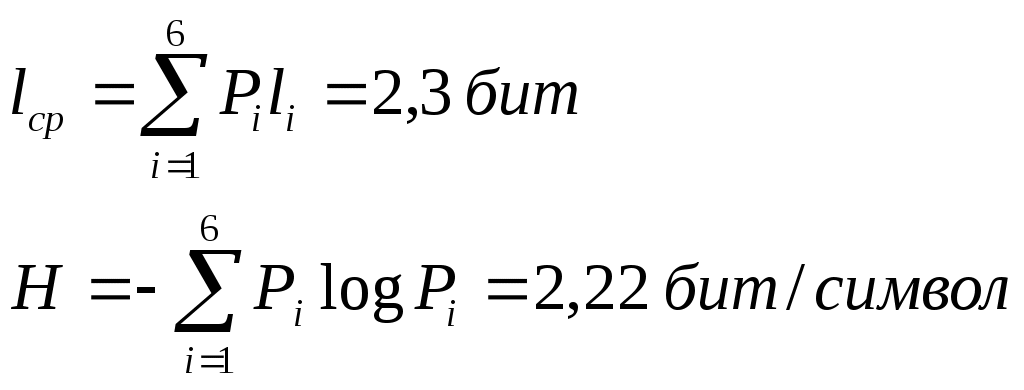 Кодирование алфавита по методу Хафмана не является однозначно определенной процедурой. Можно получать разные коды Хафмана. Чтобы посмотреть изменение кода Хафмана, рассмотрим пример другой кодировки:
Если посчитать Процедура декодирования кодов Хафмана является однозначной. Используя методику Хафмана, можно строить оптимальные коды, если для кодирования используется m элементарных сигналов. При построении таких кодов используется процедура сжатия, при которой сливаются каждый раз m букв алфавита. Последовательность сжатия приводит к алфавиту из m букв. Число букв исходного алфавита n должно быть представляемо n = m + k *(m -1), k – целое число. Этого условия всегда можно достичь, если ввести в исходный алфавит фиктивные буквы, вероятность которых равна нулю. Дан алфавит из 6 букв с вероятностями. Построить троичный код Хафмана 0, 1, 2. Требуемое число букв: n = 3 + k * (3 - 1), k = 1 n = 5 k = 2 n = 7 не хватает одной буквы а7 с вероятностью равной нулю
Подсчитаем энтропию 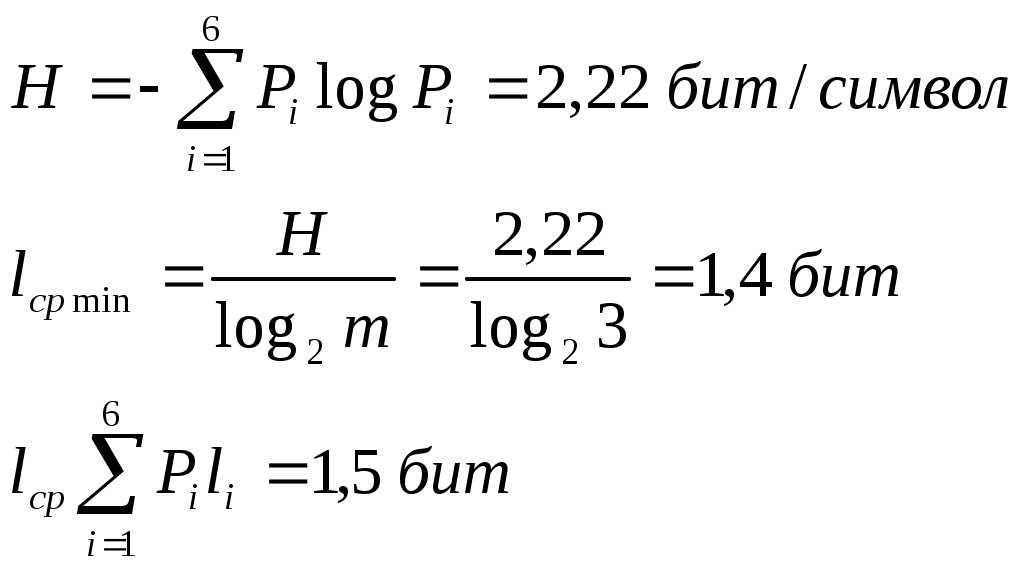 m – количество символов m – количество символовСуществует еще одна методика С 1 0 1 (7) хема получения кода Хафмана с помощью кодового дерева   Д 1 0 ан алфавит. Располагаем буквы в порядке убывания вероятностей 1 0 (5) 0,5 (6) а 0,28  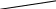 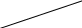 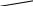 1 0,5 1 0,5 0  0,22 0,08 0,05 (4) 01 а2 0,15 011 а3 0,12 1 0 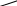 (2) 10 а4 0,1 0 0 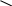 0,13 0011 а5 0,04 1 0 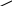 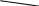 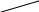 (3) 0010 а6 0,04 0 0  (1) 0001 а7 0,03 1 00000 а8 0,02 0 Находят 2 буквы с вероятностями (а7 и а8) и проводят от них линию к точке, в которой вероятность равна их сумме Теперь меньшими вероятностями обладают буквы а5 и а6. Соединяют их линиями в одной точке с вероятностью 0.08 Соединяем 0,08 и 0,05, получает 0,13 Соединяем буквы а3 и а4 Соединяем 0,15 и 0,13 И так далее… Кодируем ветки Обозначим цифрой один верхнюю линию узла, нижнюю ноль. Коды представляют собой последовательность 0 и 1, которые встречаются по пути от точки с вероятностью единица, до кодируемой буквы. Передача информации по дискретным каналам связи Для анализа информационных возможностей канала связи используется обобщённая информационная модель каналов связи.  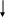 Z X Y И         ЛС ИИ – источник информации П1, П2 – преобразователи ЛС – линия связи ИП – источник помех ПИ – приёмник информации Источник информации создаёт cигналы z, которые кодируются в преобразователе П1, превращаются в сигналы x и поступают в линию связи (ЛС). В результате действия помех, сигнал Y на приёмном конце, отличается от X. Помехи создаются воображаемым источником помех (ИП) и поступают в линии связи в виде мешающего сигнала Определение максимально возможной скорости передачи информации по каналу; Разработка кодов, позволяющих увеличить скорость передачи информации; Согласование канала с источником. Важнейшей характеристикой канала является пропускная способность (обозначается символом С). - Наибольшая возможная скорость передачи информации по каналу. Пропускная способность определяют следующим образом: Взаимная информация При отсутствии помех H(x / y) = 0 и Пропускная способность канала Основная теорема Шеннона о кодировании для дискретного канала без помех 1). Дискретный канал без помех: Основная теорема Шеннона утверждает: если источник информации имеет энтропию H(z), а канал связи обладает пропускной способностью, то: 1. Сообщения, вырабатываемое источником всегда можно закодировать так, чтобы скорость их передачи vz была сколь угодно близка к vz max . 2. Не существует способа кодирования, позволяющего сделать эту скорость больше, чем vz max. Величина Теорема Шеннона (другая). Если источник информации имеет энтропию Н(z), то сообщение всегда можно закодировать так, чтобы средняя длина кода lср была близка к величине Доказательство: В качестве доказательства будем использовать методику Шеннона-Фана. Предположим, что при последовательном делении совокупности кодируемых букв по методу Шеннона-Фана на меньшие группы, каждый раз удается добиться равенства вероятностей двух получаемых групп. 1. После первого деления, получается группа с вероятностью ½; 2. После второго деления, получается группа с вероятностью ¼; и т. д. …. После Если после При выполнении этого условия длина кодового обозначения li будет связана с вероятностью pi соотношением pi=½li или, преобразуя это выражение, получим li = log В общем случае величина log pi целым числом не будет, поэтому в качестве Величина 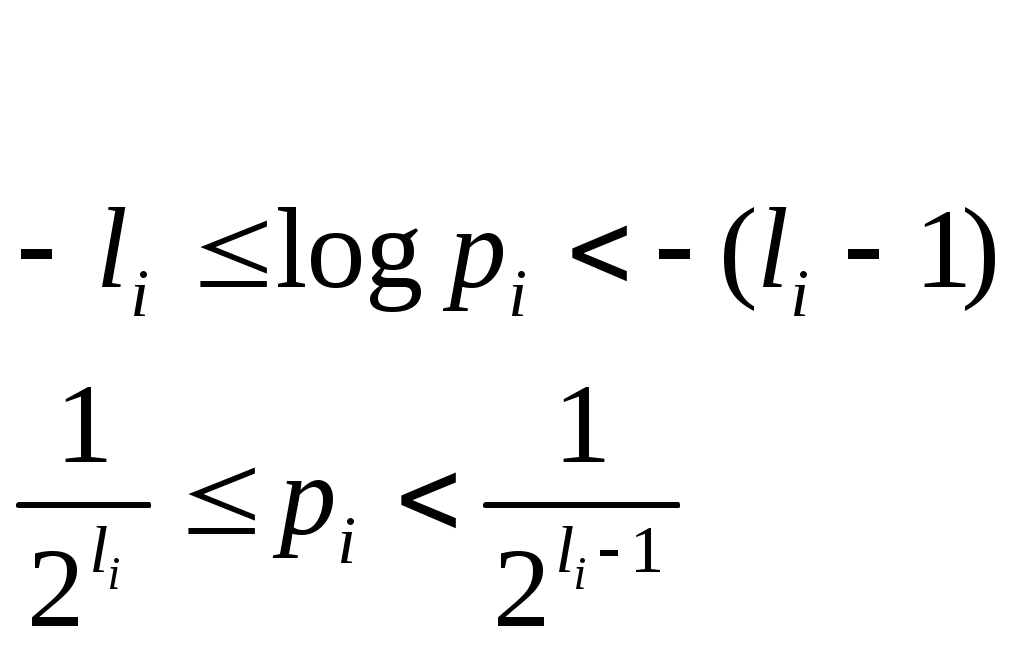 Далее Шеннон утверждал, что существует такой метод кодирования, при котором длина В качестве доказательства рассмотрим процедуру кодирования: Пусть имеется алфавит с буквами и заданы вероятности их появления. Расположим буквы алфавита в порядке убывания их вероятностей. к  оды оды z1 Q1 - числа Qi будем определять следующим образом; Q1 = 0 z2 Q2 Q2=p(z1) … … Q3=p(z1) + p(z2) zn Qn … Qn = p(z1) + p(z2) + … + p(zn-1) Все Qi≠0, кроме первого, следовательно, совпадения с первым не будет, все Qi – разные и меньше единицы. Шеннон предлагает перевести каждое Qi число в двоичную дробь. В целом Эти числа можно определить из соотношения: qi – либо 1, либо 0. Пример: Разложение каждого числа ограничивается до тех пор, пока не будет выполняться равенство: Пример: Дан алфавит состоит из восьми букв и их вероятности. Рассмотрим процедуру кодирования
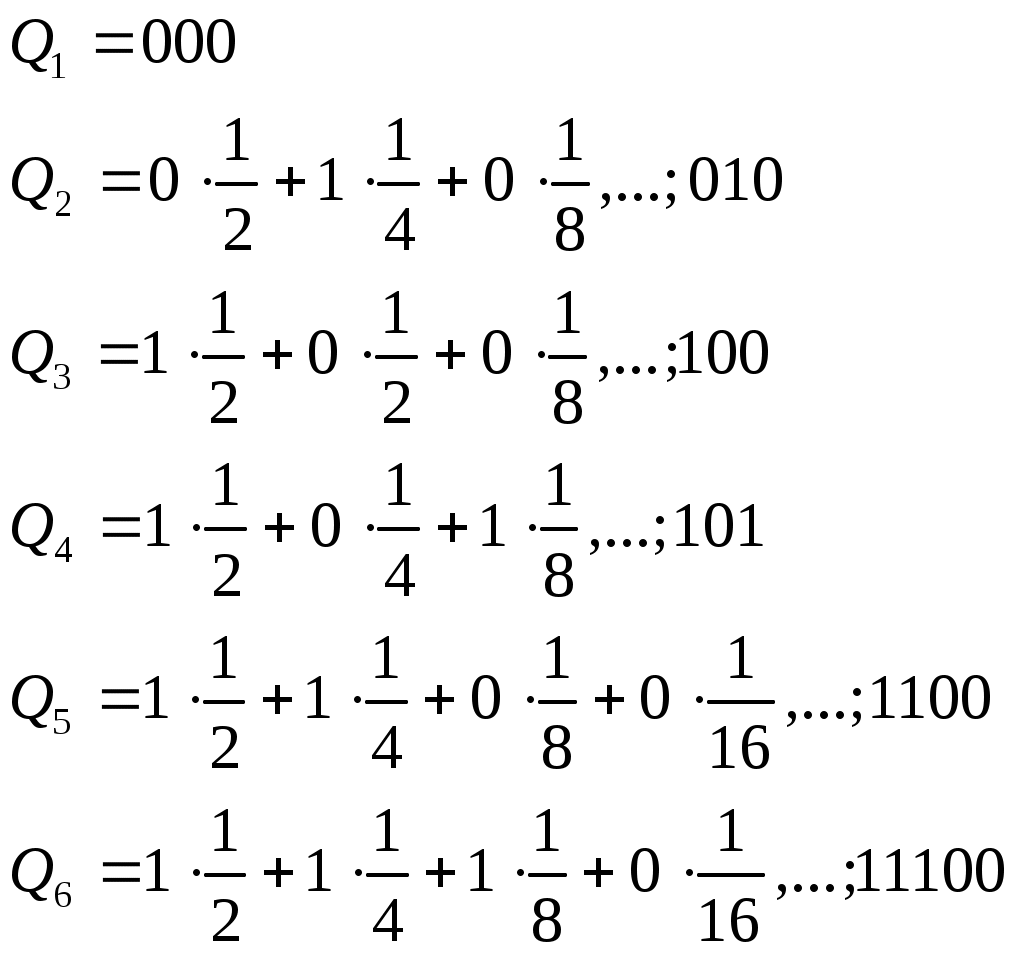 Средняя длина кодового сообщения 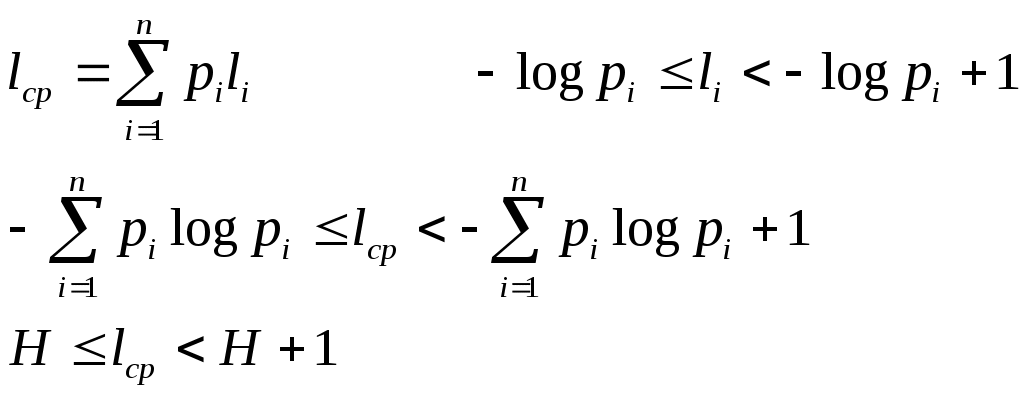 Теорема доказана В случае кодирования буквенных блоков по N букв, получаем новый алфавит z’. 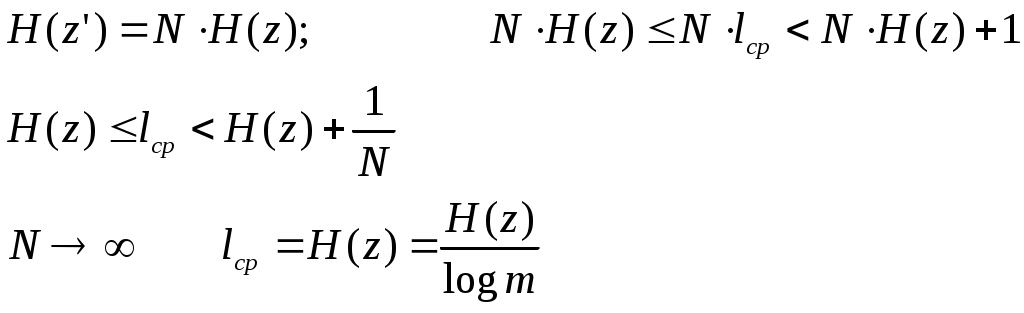 m – количество символов во вторичном алфавите, в двоичном - m = 2. Скорость передачи Максимальная скорость | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||