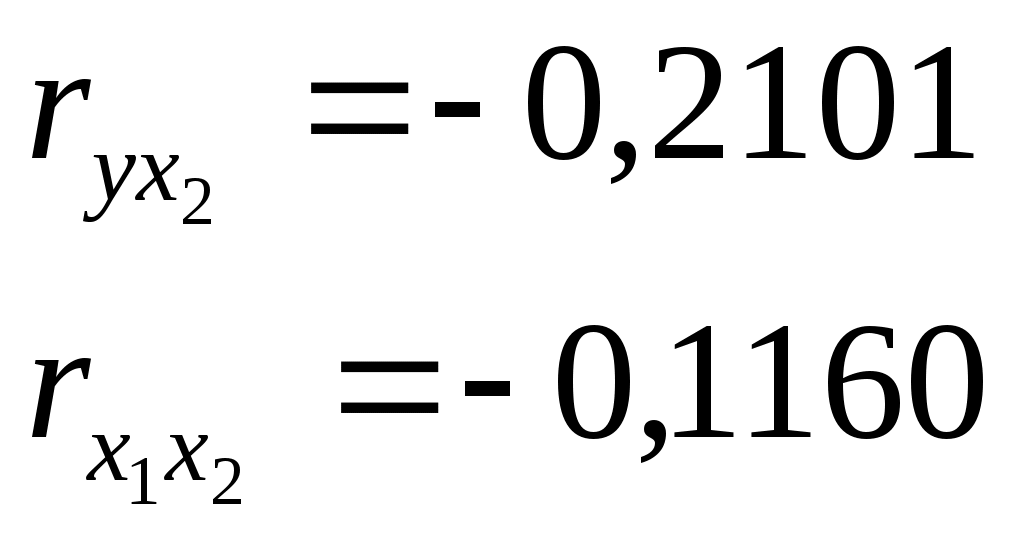Приложение 1_Эконометрика. Оценочные материалы текущего контроля успеваемости. Методические материалы по проведению процедур оценивания
 Скачать 4.57 Mb. Скачать 4.57 Mb.
|

|
Значения параметров регрессии 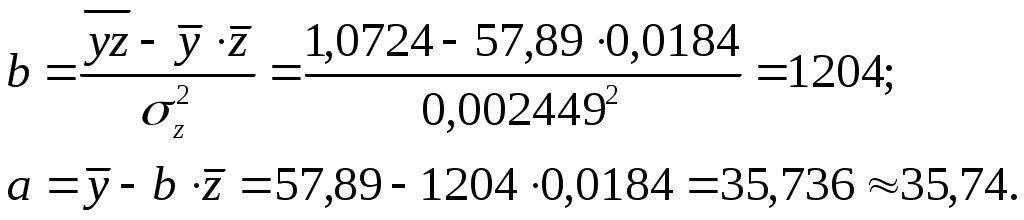 Тогда Индекс корреляции: 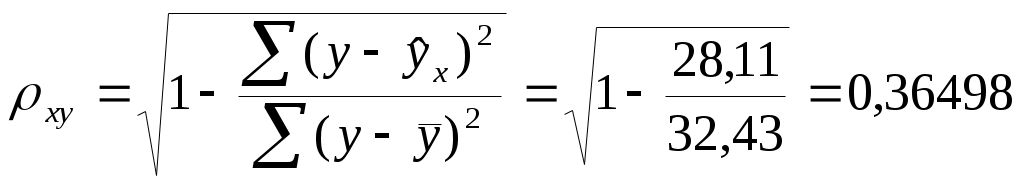 . . Следовательно, связь умеренная. Ошибка аппроксимации для всех функций повышенная: а) б) в) г) F-критерий Фишера: а) 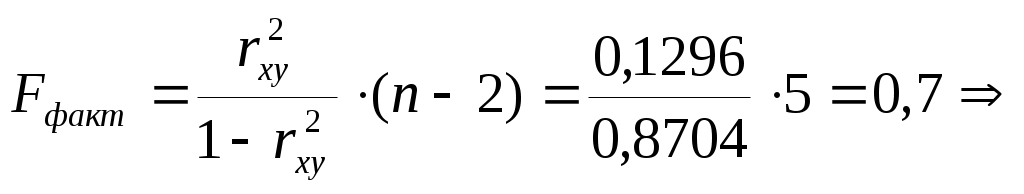 поскольку б) 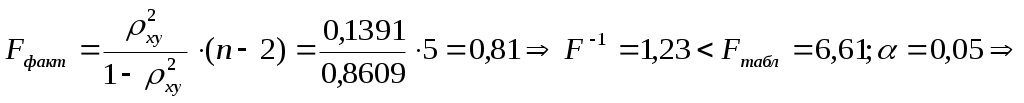 гипотеза в) 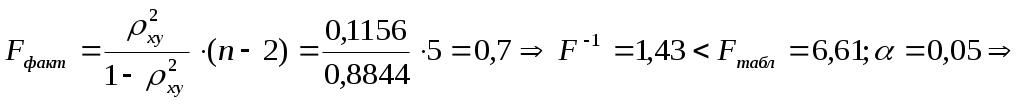 гипотеза г) 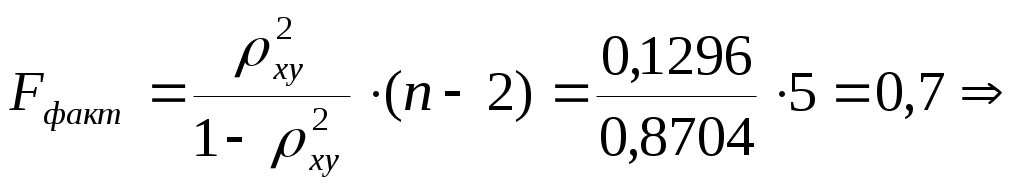 гипотеза гипотеза Пример 2. По 12 территориям региона вводятся данные (таблица 6). Таблица 6
Требования: Постройте линейное уравнение парной регрессии у от х. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации. Оценить статистическую значимость параметров регрессии и корреляции. Выполнить прогноз у при прогнозном значение х, составляющем 107% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал. Решение: Для расчета параметров уравнения линейной регрессии строим расчетную таблицу 7. Таблица 7
Тогда параметры регрессии: 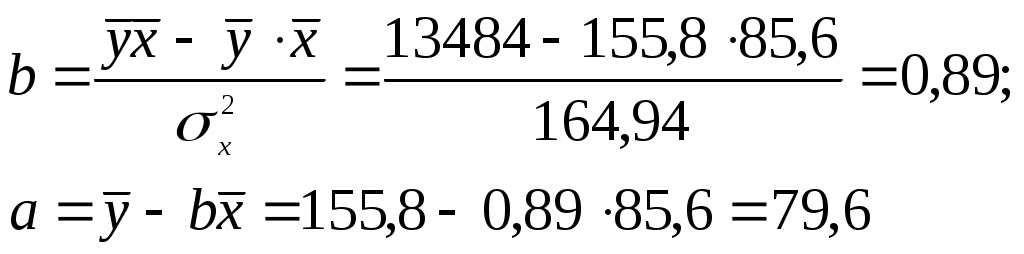 Тесноту линейной связи оценит коэффициент корреляции: 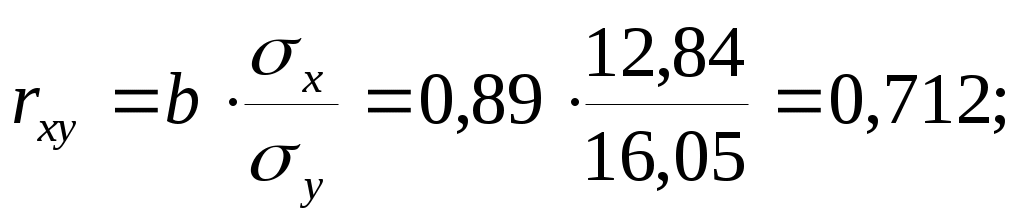 Это означает, что 51% вариации у объясняется вариацией фактора х. Качество модели определяет средняя ошибка аппроксимации: Качество построенной модели оценивается как хорошее, т.к. Оценку статистической значимости параметров регрессии проведем с помощью Определим случайные ошибки 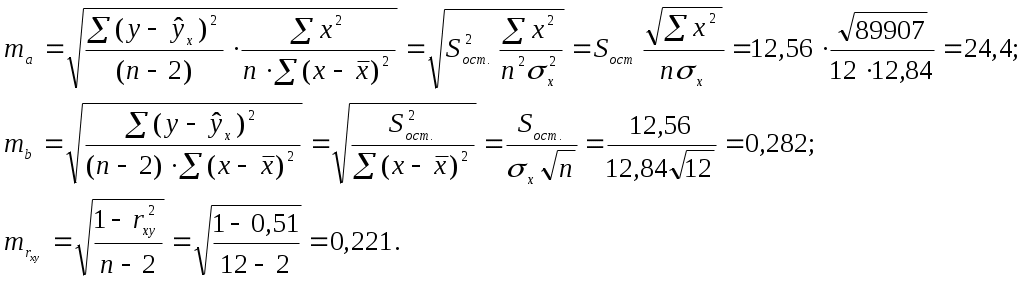 Тогда 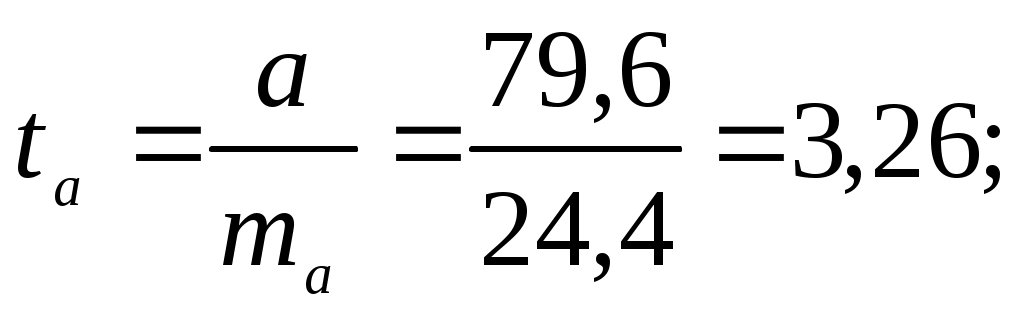 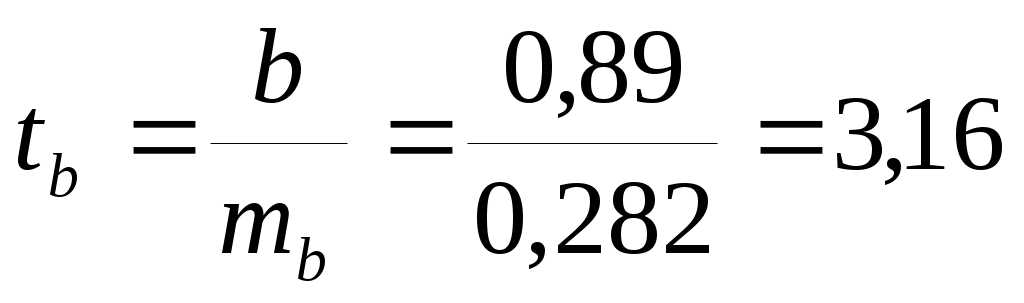 ; ; 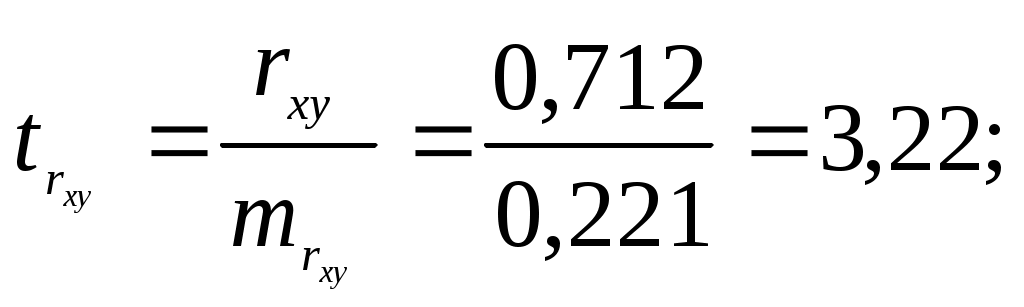 Фактические значения 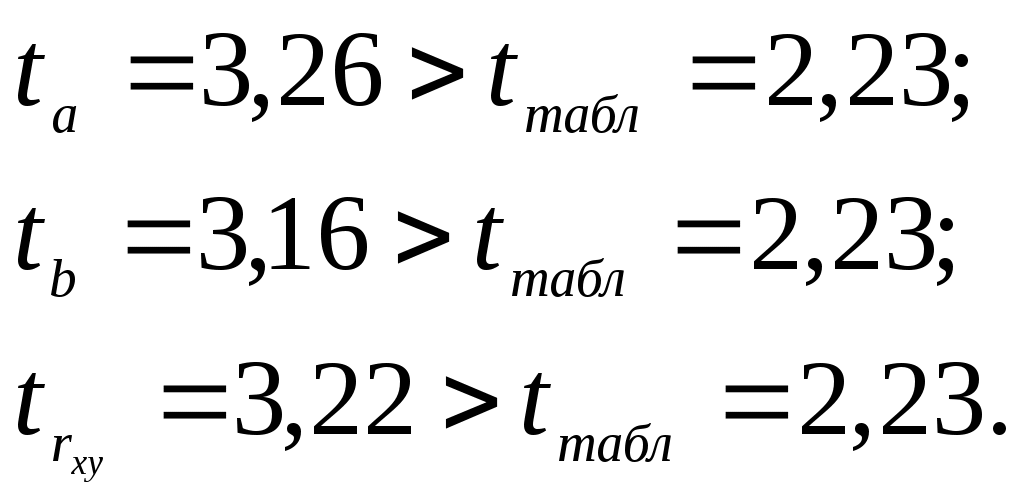 Поэтому гипотеза Рассчитаем доверительный интервал для 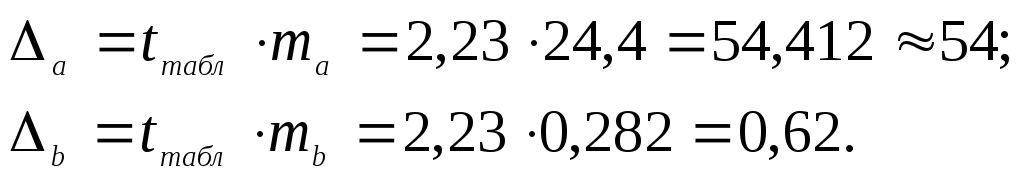 Доверительные интервалы: Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью Полученные оценки уравнения регрессии позволяют использовать для прогноза. Если прогнозное значение х составит: Ошибка прогноза составит: 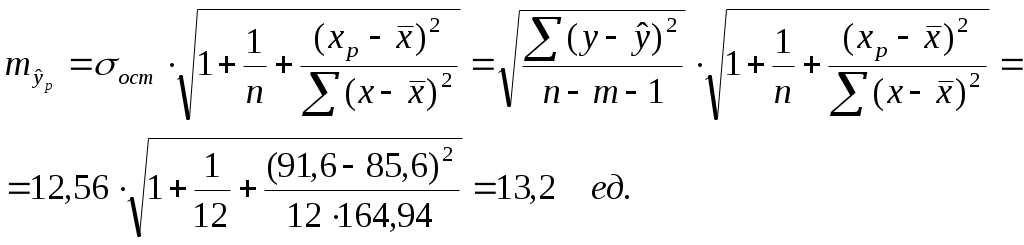 Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит: Доверительный интервал прогноза: Выполненный прогноз у оказался надежным ( 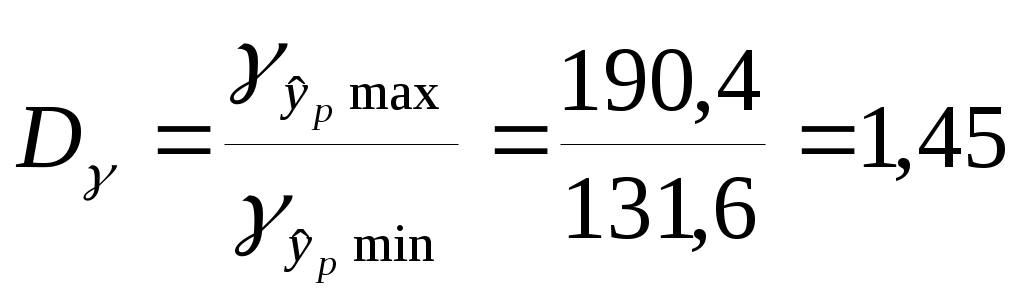 . .Пример 3. По 30 территориям России имеются данные, представленные в таблице 8: Таблица 8
Требуется: Построить уравнение множественной регрессии в стандартной и естественной форме; рассчитать частные коэффициенты эластичности, сравнить их с Рассчитать линейные коэффициенты частной корреляции и коэффициент множественной корреляции, сравнить их с линейными коэффициентами парной корреляции, пояснить различия между ними. Рассчитать общий и частные Решение: Линейное уравнение множественной регрессии у от х1 и х2 имеет вид:. Для расчета его параметров применим метод стандартизации переменных и построим искомое уравнение в стандартизированном масштабе: Расчет 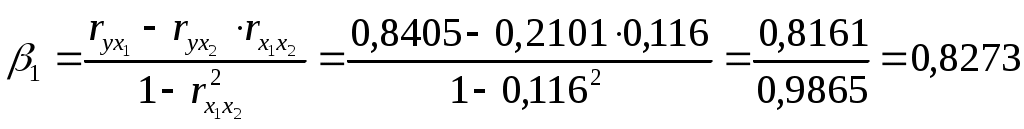 ; ;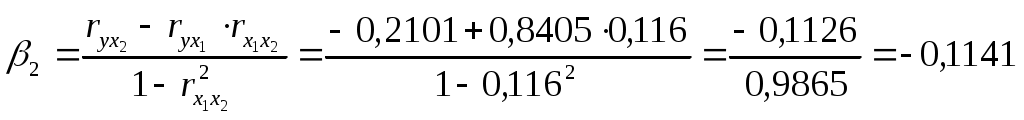 ; ;Для построения уравнения в естественной форме рассчитаем 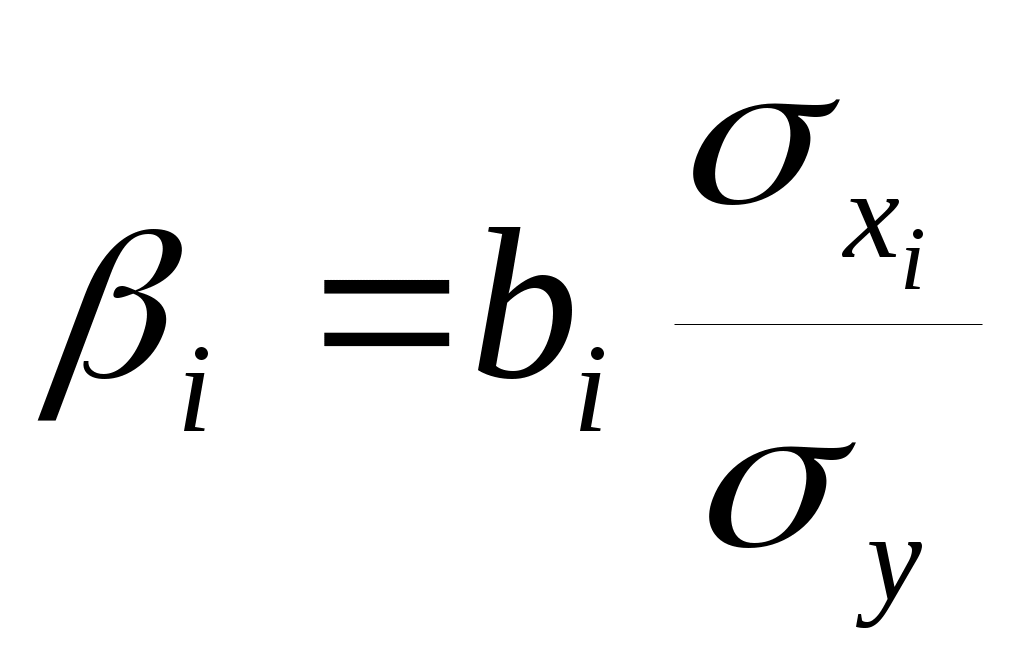 ; ; 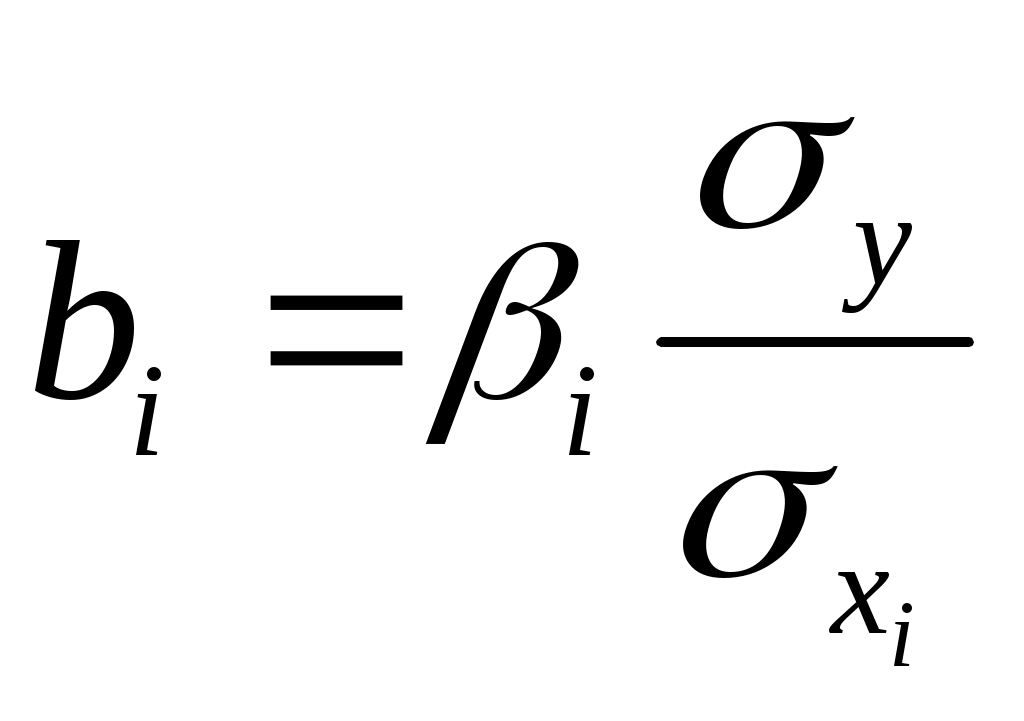 Значение а определим из соотношения: Для характеристики относительной силы влияния х1 и х2 на у рассчитаем средние коэффициенты эластичности: 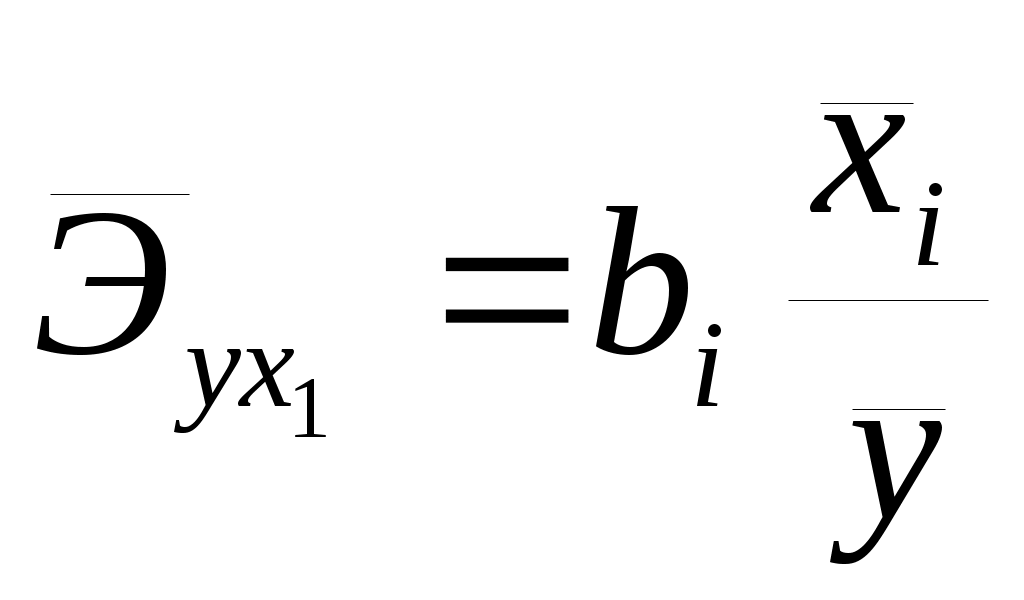 ; ;С увеличением средней заработной платы х1 на 1% от ее среднего уровня средний душевой доход у возрастает на 1,02% от своего среднего уровня; при повышении среднего возраста безработного х2 на 1% среднедушевой доход у снижается на 0,87% от своего среднего уровня. Очевидно, что сила влияния, средней заработной платы х1 на средний душевой доход у оказалась большей, чем сила влияния среднего возраста безработного х2. К аналогичным выводам о силе связи приходим при сравнении модулей значений Различия в силе влияния фактора на результат, полученные при сравнении 2. Линейные коэффициенты частной корреляции здесь рассчитываются по рекуррентной формуле: 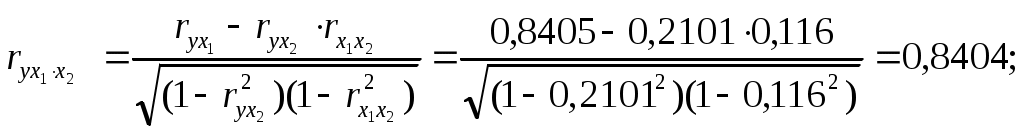 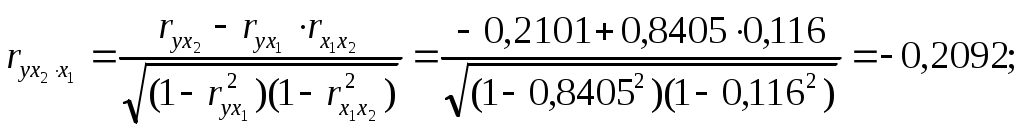 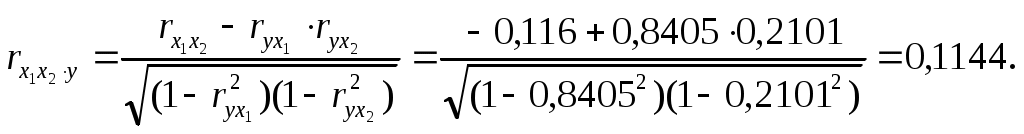 Если сравнить значения парной и частной корреляции, то приходим к выводу, что из-за слабой межфакторной связи ( Расчет линейного коэффициента множественной корреляции выполним с использованием коэффициентов Зависимость у от х1 и х2 характеризуются как тесная, в которой 72% вариации среднего душевного дохода определяется вариацией учтенных в модели факторов: средней заработной платы и среднего возраста безработного. Прочие факторы, не включенные в модель, составляют соответственно 28% от общей вариации у. 3. Общий F-критерий проверяет гипотезу Н0 о статистической значимости уравнения регрессии и показателя тесноты связи (R2=0): 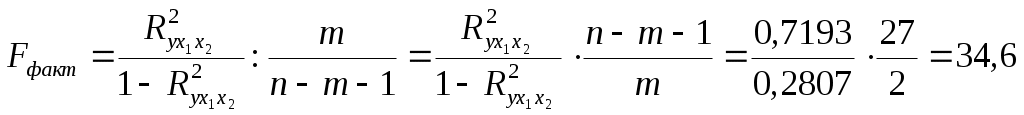 ; ;Fтабл=3,4; при Сравнивая Fтабл и Fфакт, приходим к выводу о необходимости отклонить гипотезу Н0, т.к. Fтабл=3,4<Fфактл=34,6. С вероятностью 1- Частные F-критерии - 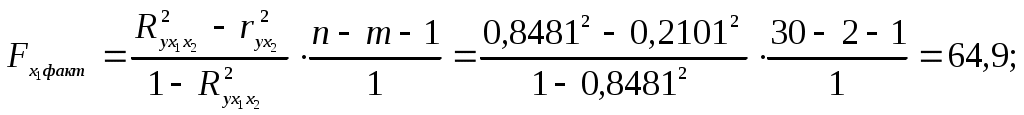 Сравним Fтабл и Fфакт приходим к выводу о целесообразности включения в модель фактора х1 после фактора х2, т.к. Целесообразность включения в модель фактора х2 после фактора х1 проверяет 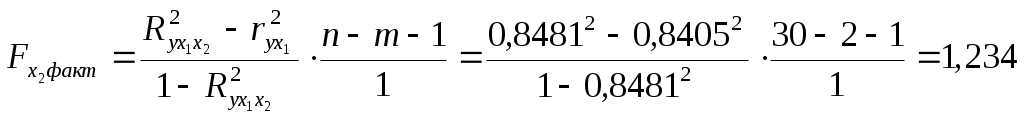 Низкое значение Таким образом подтверждается нулевая гипотеза Н0 о нецелесообразности включения в модель фактора х2 (средний возраст безработного). Это означает, что парная регрессионная модель зависимости среднего дохода от средней заработной платы является достаточно статистически значимой, надежной и что нет необходимости улучшать ее, включая дополнительный фактор х2 (средний возрасте безработного). Пример 4. Имеются данные (таблица 9) за 5лет: Таблица 9
|