Обоснование необходимости и цели использования вычислительной техники для решения задачи. Диплом. Руководство пользователей 47
 Скачать 2.12 Mb. Скачать 2.12 Mb.
|

1.6.3. Обоснование проектных решений по программному обеспечениюРазрабатываемый програмный продукт будет реализован в технологии «клиент-сервер». В качестве сервера баз данных использован сервер Firebird 2.5. Клиентская часть разработана в среде Borland Delphi 7. При этом требования к конфигурации клиентской машине минимальны. Клиентское ПО поддерживает сетевой протокол TCP/IP.[4] Програмное обеспечение: Операционная система Windows XP, Vista, 7; сервер Firebird; MS Excel, IBExpert. Специальное програмное обеспечение составляет: Файл с расширением .exe, для запуска программного продукта, файл базы данных с расширением .fdb, а также файл конфигурации .ini и техническая документация. 1.6.4. Обоснование проектных решений по технологическому обеспечениюВ настоящее время существует большой выбор средств разработки приложений и языков программирования на платформе операционной системы Windows. В настоящее время программирование бурно развивается, как с точки зрения расширения круга решаемых им задач, так и с точки зрения существенного усложнения используемых в программировании технологий. Причем особо необходимо отметить немалые размеры разрабатываемых программных продуктов. Все это требует максимального упрощения и ускорения процесса разработки приложений и использования ранее реализованных программных фрагментов. Такие требования к современному программированию привели к созданию многочисленных RAD – систем, представляющих собой интегрированные среды разработчика, включающие в себя: » средства быстрого и удобного построения программ, в том числе визуального; » встроенные компиляторы и отладчики. Одной из таких RAD-систем является Delphi. Итак, Delphi — это объектно-ориентированная среда для визуального проектирования Windows приложений с развитыми механизмами повторного использования программного кода. Существенной чертой Delphi является компонентная модель разработки программных продуктов. Суть модели заключается в поддержке системой постоянно расширяемого набора объектных компонентов, из которых и строится программа. Компоненты в Delphi просты для использования и развития, как результат сокрытия значительной части той структуры программы, которая близка к взаимодействию с операционной системой. Таким образом, для создания в Delphi несложных программных продуктов совершенно не обязательно понимать внутреннюю структуру Windows-приложения, получаемого после разработки в Delphi. Достаточно просто уметь работать с некоторыми компонентами, поставляемыми вместе со средой разработчика. При этом начать работу со средой можно практически без предварительного ознакомления, а написание первого приложения не потребует углубления в особенности системы. Этому отчасти способствует удобный интерфейс среды разработчика, не перегруженный излишними вопросами к разработчику Глава 2. Проектная часть2.1. Информационное обеспечение задачи (комплекса задач, АРМ)2.1.1. Информационная модель и ее описаниеПостроение инфологической модели БД начнем с реализации диаграммы потоков данных (DFD). Стандарт описания бизнес-процессов DFD — Data Flow Diagram переводится как диаграмма потоков данных и используется для описания процессов верхнего уровня и для описания реально существующих в организации потоков данных. Созданные модели потоков данных компании могут быть использованы при решении таких задач, как: определение существующих хранилищ данных (текстовые документы, файлы, система управления базой данных — СУБД); определение и анализ данных, необходимых для выполнения каждой функции процесса; подготовка к созданию модели структуры данных организации, так называемая ERD-модель (IDEF1X); выделение основных и вспомогательных бизнес-процессов организации. Диаграммы потоков данных показывают, как каждый процесс преобразует свои входные данные в выходные, и выявляют отношения между этими процессами. DFD представляет моделируемую систему как сеть связанных работ. Существуют две нотации диаграмм: графические нотации Йордана Де Марко и Гейна-Сарсона. Различие заключается в графических формах объектов. [2] Основные объекты нотации, : Процессы (Activities). Отображают процессы обработки и изменения информации; Стрелки (Arrows). Отображают информационные потоки; Хранилища данных (Data Store). Отображают данные, к которым осуществляется доступ, эти данные используются, создаются или изменяются работами; Внешние сущности (External References). Отображают объекты, с которыми происходит взаимодействие.  Рисунок 2. Основные объекты DFD в нотации Йордана Де Марко На Рисунок 3 показана диаграмма потоков данных в рамках рассматриваемой предметной области компании. 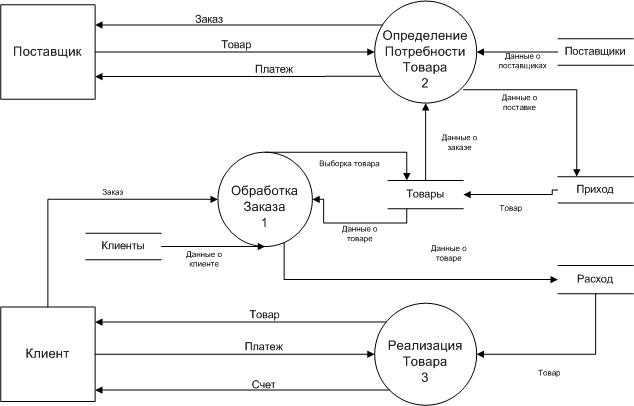 Рисунок 3. Диаграмма потоков данных Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком, но естественный язык не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка. Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).[3] Для того, чтобы определиться с входными и выходными данными и построить инфологическую модель бызы данных, рассмотрим более подробно оперции, которые проходят на складе , приведенные в пункте 1.2.1 дипломной работы: Разгрузка товара. Это первый этап поступления товара на склад. Для того чтобы реализовать поставку на склад, необходимо знать кому нужно сделать заказ на нужный товар, следовательно, можно определить сущность «Поставщики», хранящую в себе в качестве атрибутов информацию о предприятии (наименование предприятия, адрес, телефон, электронная почта, а также различные банковские и юридические реквизиты). Так как поставщики поставляют нам товар, то определяется сущность «Приход», атрибуты сущности хранят информацию о поставке (наименование товара, дата поставки, количество товара и цена товара). Приемка товара. Обычно в ней проводится очистка (если нужно), предварительная регистрация и маркирование товара информационными этикетками. Предварительная регистрация осуществляется с помощью товарной накладной приёмки, учет которых ведет складской работник, также производящий маркирование товара. Размещение на хранение. Из названия можно заметить, что данная операция формирует задачи хранения продукции. Нам известно, что на складе хранится различная продукция именованная товаром. Хранимый товар необходимо в чем-то измерять, поэтому можно определить сущность «Единицы измерения», атрибут которой хранит наименование единицы измерения. Так как на складе товар разнообразен, то для удобства и уменьшения времени на размещение и отборку товара необходимы отделы товаров. Отдел включает в себя определенные группы товаров. Отсюда выделим сущности «Отделы» и «Группы». В качестве атрибутов будет выступать наименование отдела товаров. Отборка товаров из мест хранения. Эта операция происходит по нескольким причинам, одна из которых – необходимость продать размещенный товар. Чтобы продать товар нам необходимо знать, кому продавать, таким образом, нам необходимы клиенты, появляется сущность «Клиенты», атрибуты которой содержат в себе необходимую информацию о клиентах (наименование клиента, тип, адрес, телефон, электронная почта и некоторые банковские реквизиты). У клиента может быть заключен договор с нашей компанией об оптовых продажах, поэтому выделим сущность договора, включающую в себя номер договора, дату и процент скидки. Остальные операции (комплектование и упаковка товаров, погрузка, перемещение грузов внутри склада) используются также работниками склада, грузчиками. Вследствие того, что сам склад необходим для работы с товаром, то смело можно назвать сущность «Товары», атрибуты которой будут хранить в себе информацию о товаре (наименование товара, отдел, группа, единица измерения, цена, количество и комментарий). Также определим вспомогательные сущности, необходимые для упраления пользователями, работающими с програмным продуктом и некоторые другие: сотрудники, должности, организация ( хранит адрес, название компании и реквизиты, используемые в документах). Выходные данные образуются на основе существующих данных, в конкретном случае, составляется отчетность, накладные, товарный чек, счет и прайс-лист (документы должны выводиться на экран и печать), а также справочники. На Рисунок 4 показана инфологическая модель, включающая в себя сущности и атрибуты сущностей. Инфологическая модель базы данных представляет собой описание объектов (сущностей), с набором атрибутов и связей между ними, которые выявляются в процессе исследования как входных, так и выходных данных. Она предназначается для структурного образования предметной области, с ориентированием на информационное внимание пользователей, разрабатываемой системы. Так же инфологическая модель должна быть как стабильной, так и неизменной, и являться представлением аспекта пользователя на описанную предметную область. Однако, при проектировании инфологической модели, должна присутствовать возможность для её увеличения и вставки вспомогательных данных. [1] 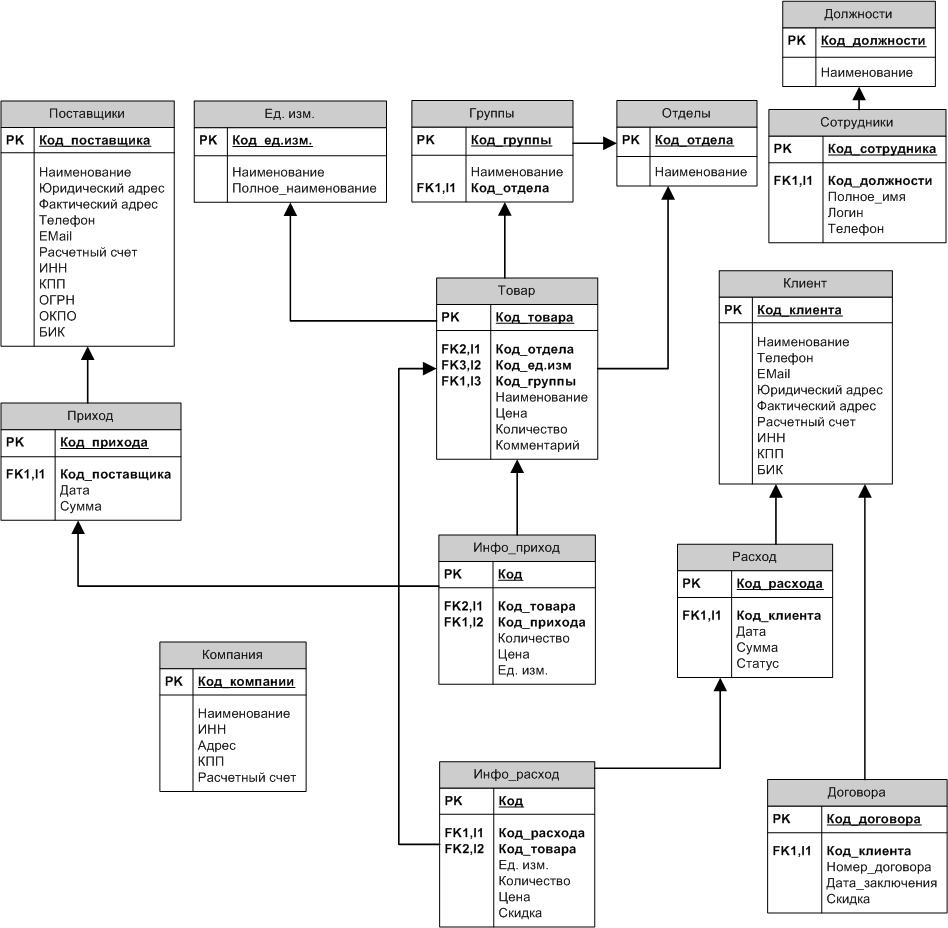 Рисунок 4. Инфологическая модель данных Даталогическая модель строится на основе существующей инфологической модели, для более наглядного вида и анализа - Рисунок 5. Таблица «Товар»
Таблица «Информация о расходе»
Таблица « Расход»
Таблица « Информация о приходе»
Таблица « Приход»
Таблица « Клиенты»
Таблица « Поставщики»
Таблица « Договора»
Таблица « Компания»
Таблица « Сотрудники»
Таблица « Должности»
Таблица « Отделы»
Таблица « Группы»
Таблица « Единицы измерения»
Рисунок 5. Даталогическая модель данных Сегодня наиболее распространены реляционные модели данных . Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или "отношений" в терминологии СУБД). Каждое отношение (таблица) может быть представлено в виде прямоугольного массива со следующими свойствами: Каждая ячейка в таблице представляет точно один элемент данных; Каждая таблица имеет однородные столбцы, все элементы в любом из столбцов одного и того же вида; Каждому столбцу назначено определенное имя; Все строки различны, дублировать строки не разрешается; Строки, и столбцы не зависят от последовательности, просмотр в различной последовательности не может изменить информационное содержание отношения; Каждая строка олицетворяет уникальный элемент данных, который ею и описывается; Столбцы представляют собой отдельные куски информации (атрибуты данных), которые известны о данном элементе. Вообще, лишь немногие реальные базы данных могут быть описаны при помощи единственной таблицы. Большинство приложений используют множество таблиц, которые содержат столбцы (поля) с одинаковым именем. Эти общие данные позволяют, объединяя две (или несколько) таблицы, строить осмысленные ассоциации Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости. Существует несколько правил нормализации баз данных. Каждое правило называется «нормальной формой». Если выполняется первое правило, говорят, что база данных представлена в «первой нормальной форме». Если выполняются три первых правила, считается, что база данных представлена в «третьей нормальной форме». Разрабатываемая БД нормализована до 3НФ и представлена на Рисунок 6.[4]  Рисунок 6. Физическая модель базы данных |