Структуры данных и эффективность алгоритмов. 4
 Скачать 2.32 Mb. Скачать 2.32 Mb.
|

Наихудшее и среднее время работы.Характер (и диапазон) изменения времени работы алгоритма обычно зависит от «объема» входных данных. Причем смысл понятия «объем» может зависеть от вида задачи, например, для задачи «Найти n-е простое число» видимо значение n является реалистичным смыслом для понятия «объем», а для задачи «Вычислить сумму n чисел» важны скорее не значения слагаемых, а их количество n. Оценивая время работы алгоритма некоторой функцией T(n) от «объема» входа, мы получаем возможность сравнивать алгоритмы, отвлекаясь от разнообразия входов «объема» n, сравнивать их по скорости роста их функции T(n). При этом возникают вопросы, как и для каких конкретно входных данных производить сравнение. Выбор конкретной функции T(n) сильно зависит от решаемой проблемы, от возможностей анализа исходных данных. Рассмотрим некоторые наиболее часто используемые определения этой функции.
Но имеются впечатляющие примеры, когда программа, очень плохо работающая на некоторых входах, хорошо показывает себя на реальных задачах. Например, о симплекс-методе решения задачи линейного программирования известно: на плохих входах этот алгоритм затрачивает экспоненциальное время, но на реальных задачах устойчиво показывает намного лучшее время. Причиной такого расхождения видимо является то обстоятельство, что плохие входы составляют очень малую долю во множестве всех возможных входов, по крайней мере, с учетом частоты, с которой различные входы встречаются в реальных задачах 11. Другой вариант трактовать функцию T(n) – как время работы в среднем по всем входам «объема» n. При таком определении T(n) оценка дает меньше гарантий - может поступить вход, на котором программа будет работать дольше, чем T(n). Но зато такая оценка будет более реалистичной, если конечно базовое распределение вероятностей входов действительно реалистично соответствует практике применения программы. Специфическим вариантом времени в среднем является амортизированное время. При амортизационном анализе (amortized analysis) время, требуемое для выполнения последовательности операций над структурой данных, усредняется по всем выполняемым операциям. Этот анализ можно использовать, например, чтобы показать, что даже если одна из операций последовательности является дорогостоящей, то при усреднении по всей последовательности средняя стоимость операций будет небольшой. При амортизационном анализе гарантируется средняя производительность операций в наихудшем случае, но с усреднением по последовательностям (допустимых) операций. Чтобы конкретно определить такую функцию надо иметь базовую модель вычислителя. Наиболее простой и наиболее изученной моделью является Машина Тьюринга (МТ). Система команд МТ является очень простой и содержит простейшие команды добавления единицы, присваивания и очистки. С использованием этой модели были изучены сложностные аспекты и получены нижние и верхние оценки временной сложности для широкого класса задач. Однако программирование на языке МТ является достаточно неудобным и сложным, а главное – характер доступа к данным в языке МТ заметно отличается от имеющегося в современных ЭВМ. С этих позиций более близкими к современным ЭВМ являются RAM и RASP машины. RASP-модель (Random Access Stored Program) – машина с произвольным доступом к памяти и хранимой программой. Характерным для RASP–модели является то, что программа находится в памяти и может изменять себя. Эта модель реализует предельный случай, когда сняты ограничения на размер оперативной памяти компьютера и ограничения на размер чисел, помещаемых в этих ячейках. Но в процедурных языках программирования (изначально) не предусматриваются средства динамической (в периоде выполнения) модификации программ. Поэтому для такого программирования наиболее близкой является RAM-модель (Random Access Machine) – машины с произвольным доступом к памяти. RAM машина моделирует вычислительную машину с одним сумматором, при этом программа не может модифицировать саму себя. 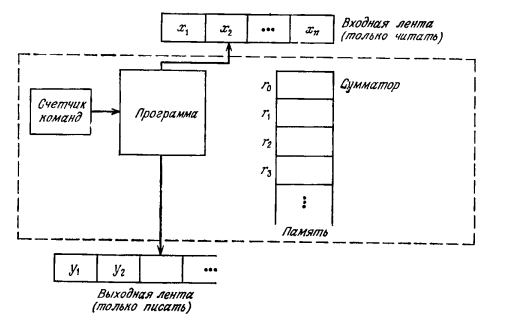 Рис 9. Схема RAM машины Команды этой машины напоминают команды ЭВМ, включают арифметические команды, команды адресации, присваивания, ввода – вывода, команды передачи управления по некоторому условию. Оперативная память неограниченна и состоит из бесконечного числа регистров, в которые записываются произвольные целые числа. Машина считывает данные из входной ленты, результаты работы записываются на выходную ленту. Программа РАМ-машины состоит из последовательности помеченных команд, которые выполняются в заданном порядке, кроме случаев, определяемых командами условного перехода. Такая идеализация допустима в случаях, когда 1) размер задачи достаточно мал, чтобы она поместилась в основную память вычислительной машины, 2) целые числа, участвующие в вычислении, достаточно малы, чтобы их можно было помещать в одну ячейку. Ниже приводится таблица команд РАМ-машины
Операнд может быть одного из следующих типов: 1) =i означает само целое число i и называется литералом, 2) i — содержимое регистра i (i должно быть неотрицательным), 3) *i и означает косвенную адресацию, т. е. значением операнда служит содержимое регистра j, где j — целое число, находящееся в регистре i; если j<0, машина останавливается. При выполнении любой из первых восьми команд счетчик команд увеличивается на единицу. Поэтому команды в данной программе выполняются последовательно, до тех пор пока не встретится команда JUMP или HALT либо JGTZ при содержимом сумматора, большем нуля, либо JZERO при содержимом сумматора, равном нулю. Вообще говоря, РАМ-программа определяет отображение из множества входных лент в множество выходных лент. Так как на некоторых входных лентах программа может не останавливаться, это отображение является частичным (т. е. для некоторых входов оно может быть не определено). Это отображение можно интерпретировать разными способами. Две важные интерпретации — интерпретация в виде функции и интерпретация в виде языка. Предположим, что программа Р всегда считывает с входной ленты n целых чисел и записывает на выходную ленту не более одного целого числа. Пусть Другой способ интерпретировать программу для РАМ — это посмотреть на нее с точки зрения допускаемого ею языка. Алфавит — это конечное множество символов, язык - множество цепочек (слов) алфавита. Символы алфавита можно представить целыми числами 1, 2, . . ., k при некотором k. Данная РАМ допускает (воспринимает) язык в следующем смысле. Пусть на входной ленте находится цепочка Рассмотрим РАМ-программу, которая допускает язык во входном алфавите {1, 2}, состоящий из всех цепочек с одинаковым числом вхождений 1 и 2. Эта программа считывает каждый входной символ в регистр 1, а в регистре 2 оставляет разность d между количеством символов 1 и 2, поступивших до текущего момента. Встретив концевой маркер 0, программа сравнивает d с нулем и в случае совпадения печатает 1 и останавливается. Мы считаем 0, 1 и 2 единственно возможными входными символами. Доказано, что вычислительные способности не сильно изменяются при переходе от одной модели к другой, сложностные оценки связаны между собой подходящими полиномами (небольшой степени). С учетом сказанного, при оценке времени работы программы (на обычном процедурном языке программирования) можно использовать следующее соглашение – время выполнения операторов присваивания, сравнения, ввода и вывода будем считать константой. При этом операторы могут содержать выражения, но с операциями базового типа 12. Точно определить некоторые константы пропорциональности нет возможности, поскольку они зависят от выбранной модели (компилятора, компьютера) и других факторов. Точное определение функции времени T(n) фактически обычно нас тоже не очень интересует, обычно она сложно представима, а нас скорее интересует возможность сравнивать алгоритмы по скорости роста соответствующих оценок времени. Для таких целей более удобны асимптотические представления функции времени. Эти функции разбиваются на классы эквивалентности в зависимости от скорости роста. По построенным классам эквивалентности для фиксированных моделей вычислений строятся сложностные иерархии, позволяющие классифицировать сложности решения соответствующих задач. РАМ и РАСП представляют более сложные модели вычислений, чем это часто бывает необходимо. Можно рассмотреть ряд других более простых моделей, которые наследуют одни черты РАМ и игнорируют другие. 1. Неветвящиеся программы. Для многих задач разумно ограничиться рассмотрением класса РАМ-программ, в которых команды разветвления используются только для того, чтобы повторить последовательность команд, причем число повторений пропорционально размеру входа n. В этом случае можно "развернуть" программу для каждого размера n, копируя повторяющиеся команды надлежащее число раз. В результате получается последовательность неветвящихся программ (т. е. программ без циклов), вообще говоря, возрастающей длины — по одной программе для каждого значения n. Развертывание циклов в программе позволяет обходиться без команд разветвления. Оправданием служит то, что во многих задачах не более чем постоянная доля сложности работы РАМ- программы приходится на команды, управляющие циклом. Подобным же образом часто можно допускать, что входные операторы образуют лишь постоянную долю сложности работы программы, и мы устраняем их, допуская, что перед началом выполнения программы в памяти находится конечное множество входов, требуемых при данном n. |