А. П. Господариков, И. А. Лебедев
 Скачать 0.88 Mb. Скачать 0.88 Mb.
|

|
|

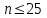 ), то полученные значения можно упорядочить по величине и указать число повторений (частоту) каждого из значений: x1 < x2 < … < xk с частотами m1, m2, …, mk, где m1 + m2 + …+ mk = n (вариационный ряд). При большом числе наблюдений вводятся интервалы группировки
), то полученные значения можно упорядочить по величине и указать число повторений (частоту) каждого из значений: x1 < x2 < … < xk с частотами m1, m2, …, mk, где m1 + m2 + …+ mk = n (вариационный ряд). При большом числе наблюдений вводятся интервалы группировки 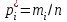 и эмпирические плотности
и эмпирические плотности 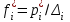 . По этим данным строятся полигон эмпирического распределения (см. рис.1), гистограмма
. По этим данным строятся полигон эмпирического распределения (см. рис.1), гистограмма 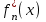 (рис.3) и эмпирическая функция распределения
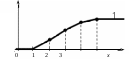
(рис.3) и эмпирическая функция распределения 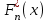 по накопленной эмпирической вероятности (рис.4).
по накопленной эмпирической вероятности (рис.4).

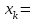 | 0 | 3 | 5 | 9 | 11 | 13 | 17 | 19 | 20 | 24 | 26 | 28 | 31 | 34 | 39 | 40 | 42 |
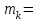 | 4 | 2 | 5 | 3 | 6 | 3 | 3 | 4 | 3 | 2 | 1 | 3 | 3 | 2 | 1 | 3 | 2 |
(k = 1,2,…,17).
Произвести группировку значений и по сгруппированному вариационному ряду построить эмпирическую функцию распределения и гистограмму плотности.
Решение. Вводим интервалы группировки:
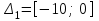 (чтобы первое значение
(чтобы первое значение  включалось с запасом),
включалось с запасом),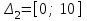 ,
,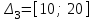 ,
,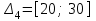 ,
,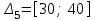 ,
,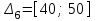 (последнее значение
(последнее значение 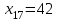 включается с запасом).
включается с запасом).Для сгруппированного вариационного ряда значения равны серединам интервалов:
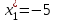 ,
, 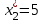 ,
, 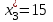 ,
, 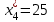 ,
, 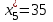 ,
, 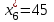 , а частоты
, а частоты 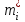 для этих значений (т.е. для интервалов
для этих значений (т.е. для интервалов 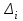 ) получаем, складывая частоты значений
) получаем, складывая частоты значений 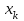 , попавшие в соответствующий интервал группировки, причем для значения , попавшего на границу двух интервалов, частота
, попавшие в соответствующий интервал группировки, причем для значения , попавшего на границу двух интервалов, частота 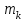 делится между этими интервалами поровну:
делится между этими интервалами поровну: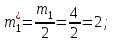
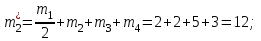
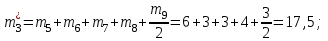
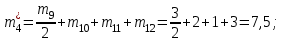
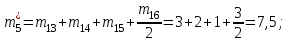
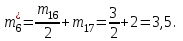
Объем выборки
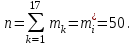
Эмпирические вероятности равны:
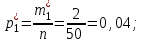
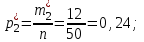
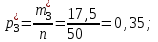
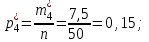
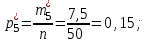
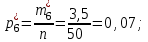
Отметим, что
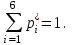 Если же значения
Если же значения  вычисляются приближенно, то при подсчете следует взять запасные знаки за запятой и, округляя (до 0,01; затем до 0,001 и т.д.) найти те значения, при которых равенство
вычисляются приближенно, то при подсчете следует взять запасные знаки за запятой и, округляя (до 0,01; затем до 0,001 и т.д.) найти те значения, при которых равенство 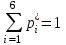 выполнится.
выполнится.Накопленные вероятности:
за
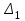 :
: 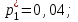 за и
за и 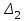 :
: 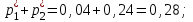
за
, ,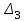 :
: 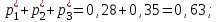
за
, , ,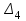 :
: 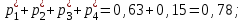
за
, , , ,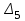 :
: 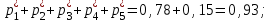
за все интервалы
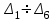 :
: 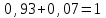 .
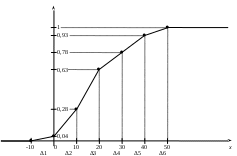
.Для построения графика эмпирической функции распределения, найденные значения накопленной вероятности следует отложить по вертикальной оси в правых концах соответствующих по номерам интервалов
. Полученные точки необходимо соединить отрезками, причем слева от функция 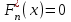 , а справа от
, а справа от 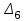 функция
функция 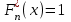 (рис.5).
(рис.5).
Рис.5. Эмпирическая функция
распределения
Определяем эмпирические плотности:
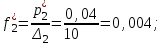
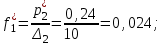
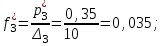
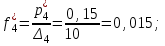
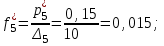
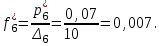
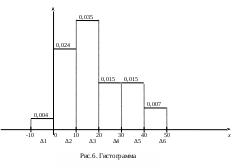
Строим гистограмму (рис.6).
По вариационному ряду (в том числе, сгруппированному) вычисляются основные эмпирические или выборочные характеристики: выборочное среднее
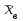 , выборочная дисперсия
, выборочная дисперсия 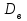 и выборочное отклонение
и выборочное отклонение 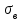 :
: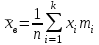 ;
; 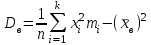 ;
; 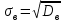 .
.Для каждой выборочной характеристики получается одно определенное значение (точка), которая является приближением соответствующей неизвестной характеристики
 или
или  случайной величины X. Поэтому эти приближения называют точечными оценками характеристик (или параметров) неизвестного распределения. По закону больших чисел эти точечные оценки сходятся к соответствующим неизвестным значениям:
случайной величины X. Поэтому эти приближения называют точечными оценками характеристик (или параметров) неизвестного распределения. По закону больших чисел эти точечные оценки сходятся к соответствующим неизвестным значениям: 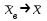 ,
, 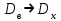 при
при 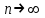 , т.е. эти оценки являются состоятельными. Кроме того, выборочное среднее является несмещенной оценкой, т.е. его математическое ожидание (среднее!) равно неизвестному значению :
, т.е. эти оценки являются состоятельными. Кроме того, выборочное среднее является несмещенной оценкой, т.е. его математическое ожидание (среднее!) равно неизвестному значению : 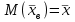 . Выборочная дисперсия является смещенной оценкой:
. Выборочная дисперсия является смещенной оценкой: 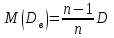 . В результате при небольших объемах (n < 30) часто рассматривают исправленные дисперсию
. В результате при небольших объемах (n < 30) часто рассматривают исправленные дисперсию 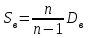 и отклонение
и отклонение 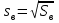 вместо и соответственно.
вместо и соответственно.Другой способ оценки неизвестных характеристик или параметров распределения заключается в указании интервала, куда попадает неизвестное значение с заданной вероятностью (или с заданной надежностью):
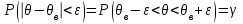 ,
,где
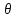 – неизвестное значение;
– неизвестное значение; 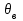 – выборочное значение;
– выборочное значение; 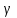 – надежность (или доверительная вероятность);
– надежность (или доверительная вероятность); 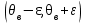 – доверительный интервал.
– доверительный интервал.Такие оценки называются интервальными. Например, если распределение X является нормальным с неизвестным
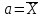 и известным
и известным 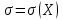 параметрами, то радиус интервала
параметрами, то радиус интервала 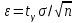 , где
, где 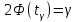 , и доверительный интервал для a с надежностью
, и доверительный интервал для a с надежностью 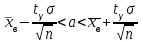 .
.Если вместо значения
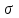 , которое может быть неизвестно, использовать точечную оценку , то получим приближенную интервальную оценку с
, которое может быть неизвестно, использовать точечную оценку , то получим приближенную интервальную оценку с 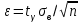 , которая по ЦПТ может применяться и для любого X.
, которая по ЦПТ может применяться и для любого X.Вероятность
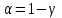 задает вероятность ошибки, т.е. того, что значение a не попадает в доверительный интервал.
задает вероятность ошибки, т.е. того, что значение a не попадает в доверительный интервал.Отметим, что имеются и другие виды интервальных оценок для этих и других параметров распределения [1, 2].
В случае равноотстоящих друг от друга значений xi (например, для сгруппированного вариационного ряда) можно упростить вычисления выборочных характеристик, если, выбрав значение
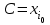 (поближе к середине ряда и с большей частотой
(поближе к середине ряда и с большей частотой 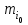 ), называемое «ложным» нулем, и определив величину шага h для значений ряда, ввести условную варианту по формуле:
), называемое «ложным» нулем, и определив величину шага h для значений ряда, ввести условную варианту по формуле: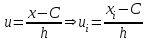 .
.Тогда значения условной варианты будут целыми числами, причем, большой частоте
будет отвечать 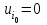 , и поэтому выборочные характеристики для условной варианты вычисляются проще:
, и поэтому выборочные характеристики для условной варианты вычисляются проще: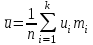 ;
; 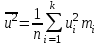 ;
;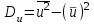 ;
; 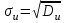 .
.Обратный пересчет производится по формулам
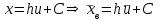 ,
, 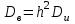 ,
, 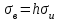 .
.При изучении СВ возникает вопрос о возможном виде ее распределения, т.е. о соответствии (согласии) выборочных данных некоторому гипотетическому теоретическому распределению, что является одной из важных задач проверки статистических гипотез.
Основное предположение называется нулевой гипотезой H0. Возможно рассмотрение и противоположной (альтернативной) гипотезы или каких-нибудь других гипотез. В нашем случае проверка гипотезы H0 состоит в том, что эмпирические данные получены для нормально распределенной генеральной совокупности. Следовательно, при альтернативной гипотезе эмпирические данные не согласуются с ожидаемым нормальным распределением.
Проверка статистических гипотез осуществляется с помощью статистических критериев. Критерий – случайная величина, значение которой вычисляется по эмпирическим данным, т.е. по выборке. Статистический критерий определяет критическую область, при попадании в которую выборочного значения критерия нулевая гипотеза отвергается. Отвергая нулевую гипотезу (если она на самом деле верна), совершают ошибку первого рода; не отвергая нулевую гипотезу (если она на самом деле неверна), допускают ошибку второго рода. Критическая область определяется так, чтобы вероятность ошибки первого рода не превышала уровня значимости
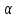 , а вероятность совершить ошибку второго рода была бы наименьшей. Обычно в качестве берут маленькое число (0,05; 0,01; 0,001; …), при этом следует учитывать, что при
, а вероятность совершить ошибку второго рода была бы наименьшей. Обычно в качестве берут маленькое число (0,05; 0,01; 0,001; …), при этом следует учитывать, что при 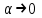 будет уменьшаться критическая область, т.е. практически все гипотезы будут приниматься.
будет уменьшаться критическая область, т.е. практически все гипотезы будут приниматься.Рассмотрим достаточно простой и эффективный критерий согласия – критерий Пирсона хи-квадрат (
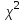 ), для которого мерой расхождения между эмпирическим распределением (выборкой) и теоретическим распределением является разность между эмпирическими и теоретическими частотами для одного и того же значения дискретной случайной величины или, соответственно, для одного и того же интервала в случае непрерывной случайной величины. Для критерия Пирсона находят величину
), для которого мерой расхождения между эмпирическим распределением (выборкой) и теоретическим распределением является разность между эмпирическими и теоретическими частотами для одного и того же значения дискретной случайной величины или, соответственно, для одного и того же интервала в случае непрерывной случайной величины. Для критерия Пирсона находят величину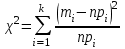 ,
,где mi – эмпирическая частота; pi – соответствующая вероятность для теоретического распределения; npi– теоретическая частота;
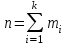 – объем выборки.
– объем выборки. Распределение критерия
зависит от числа степеней свободы r и уровня значимости . Число r определяется числом значений (или интервалов) k и числом наложенных связей 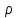 , равным числу соотношений для выборочных данных и теоретических параметров:
, равным числу соотношений для выборочных данных и теоретических параметров: 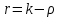 . Например, так как всегда
. Например, так как всегда 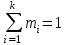 , то
, то 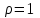 ; если дополнительно положим
; если дополнительно положим 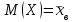 , то
, то 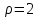 ; если еще положим и
; если еще положим и 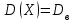 (т.е.
(т.е. 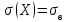 ), то
), то 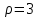 и т.д. По специальной таблице [2, 3], зная значения r и , находят критическое значение
и т.д. По специальной таблице [2, 3], зная значения r и , находят критическое значение 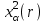 . Вычисленное по выборке значение
. Вычисленное по выборке значение 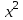 сравнивают с критическим значением: если
сравнивают с критическим значением: если 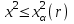 , то различие эмпирических данных с теоретическим распределением можно считать несущественным и гипотеза о согласии эмпирических данных с теоретическим распределением не отвергается; если
, то различие эмпирических данных с теоретическим распределением можно считать несущественным и гипотеза о согласии эмпирических данных с теоретическим распределением не отвергается; если 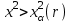 , называемой критической областью, то различия существенны и гипотезу о согласии следует отвергнуть.
, называемой критической областью, то различия существенны и гипотезу о согласии следует отвергнуть.Отметим, что при использовании критерия Пирсона значения, частоты которых малы
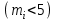 можно объединить (обычно это крайние значения или интервалы).
можно объединить (обычно это крайние значения или интервалы).