|
|
Элементарная биометрия. Книга служит элементарным пособием для практического применения вариационной статистики в биологических исследованиях
В любых биологических экспериментах и наблюдениях особое значение имеют различия, на основании которых судят об эффективности действия тех или иных факторов, например, по разности между опытной и контрольной группами делают заключение о результатах опыта. Точно так же по соответствующим изменениям морфофизиологических показателей определяют возрастные, сезонные и популяционные особенности животных. При этом особенно важно оценить статистическую достоверность разности, т. е. определить, можно ли данное различие считать закономерным, характерным для всей генеральной совокупности и рассматривать его как результат действия особенных факторов, или же оно случайно и является следствием недостаточного количества данных и в следующих опытах может не проявиться.
Обнаружение достоверных отличий статистических параметров – первый шаг к познанию новых биологических закономерностей, причем количественно доказанных. Ответ на вопрос о достоверности или случайности отличий дают статистические критерии, среди которых самые распространенные критерии t Стьюдента и F Фишера. Вычисление их ведется по специальным формулам (различным в зависимости от сравниваемых параметров и типов распределения). Полученные этим способом значения критериев (для чего в формулы подставляются экспериментальные данные) сравнивают с табличными при выбранном уровне значимости (обычно 0.05) и числе степеней свободы (объемы выборок без числа ограничений). Результатом такого сравнения должен стать один из двух вариантов следующего статистического вывода. Если полученное значение (величина) критерия больше табличного, значит, различия между параметрами при заданном уровне значимости и установленном числе степеней свободы достоверны, в разных выборках действительно проявилось действие разных факторов или разных уровней одного фактора. Если же полученная величина критерия меньше табличной, то при данном уровне значимости и числе степеней свободы различия между параметрами недостоверны. Последнее говорит о том, что различия случайны, никакого определенного вывода о побудительных причинах отличий сделать нельзя, нулевая гипотеза остается не опровергнутой.
При сравнении выборок по степени выраженности признака говорят о достоверности (недостоверности) отличий средних арифметических и долей, а при сравнении по уровню изменчивости показателей – о достоверности (недостоверности) отличий стандартных отклонений (дисперсий) и коэффициентов вариации. Особый случай представляет сравнение двух выборок по характеру распределения (достоверность отличия частот), а также общее отличие выборок без указания определенных параметров (для признаков в полуколичественных единицах).
Сравнение средних арифметических
Задача сравнения выборочных средних – это вопрос о том, действовал ли при составлении одной из выборок новый систематический фактор по сравнению с другой выборкой. В терминах статистики отличия между средними могут иметь два противоположных источника:
1. Обе выборки взяты из одной генеральной совокупности, но средние отличаются в силу ошибки репрезентативности.
2. Выборки взяты из разных генеральных совокупностей, отличие средних вызвано, в основном, действием разных доминирующих факторов (а также и случайно).
Статистическая задача состоит в том, чтобы сделать обоснованный выбор. Исходно предполагается (Но): «достоверных отличий между средними нет». Отличить закономерное от случайного можно только на основе знания законов поведения случайной величины. Для исключения чужеродных («выскакивающих») вариант мы применяли закон нормального распределения: в диапазоне четырех стандартных отклонений, M ± 1.96∙S, отклонение вариант от средней происходит по случайным причинам; за границами этого диапазона лежат чужеродные для данной выборки значения. Поскольку выборочные средние имеют нормальное распределение, критерий отличия двух выборочных средних также базируется на свойствах нормального распределения: в границах Mобщ.±1.96∙m (или приблизительно Mобщ.± 2∙m) выборочные средние арифметические отличаются от общей (генеральной) средней по случайным причинам. Тогда рабочая формула для t критерия отличия средних будет:
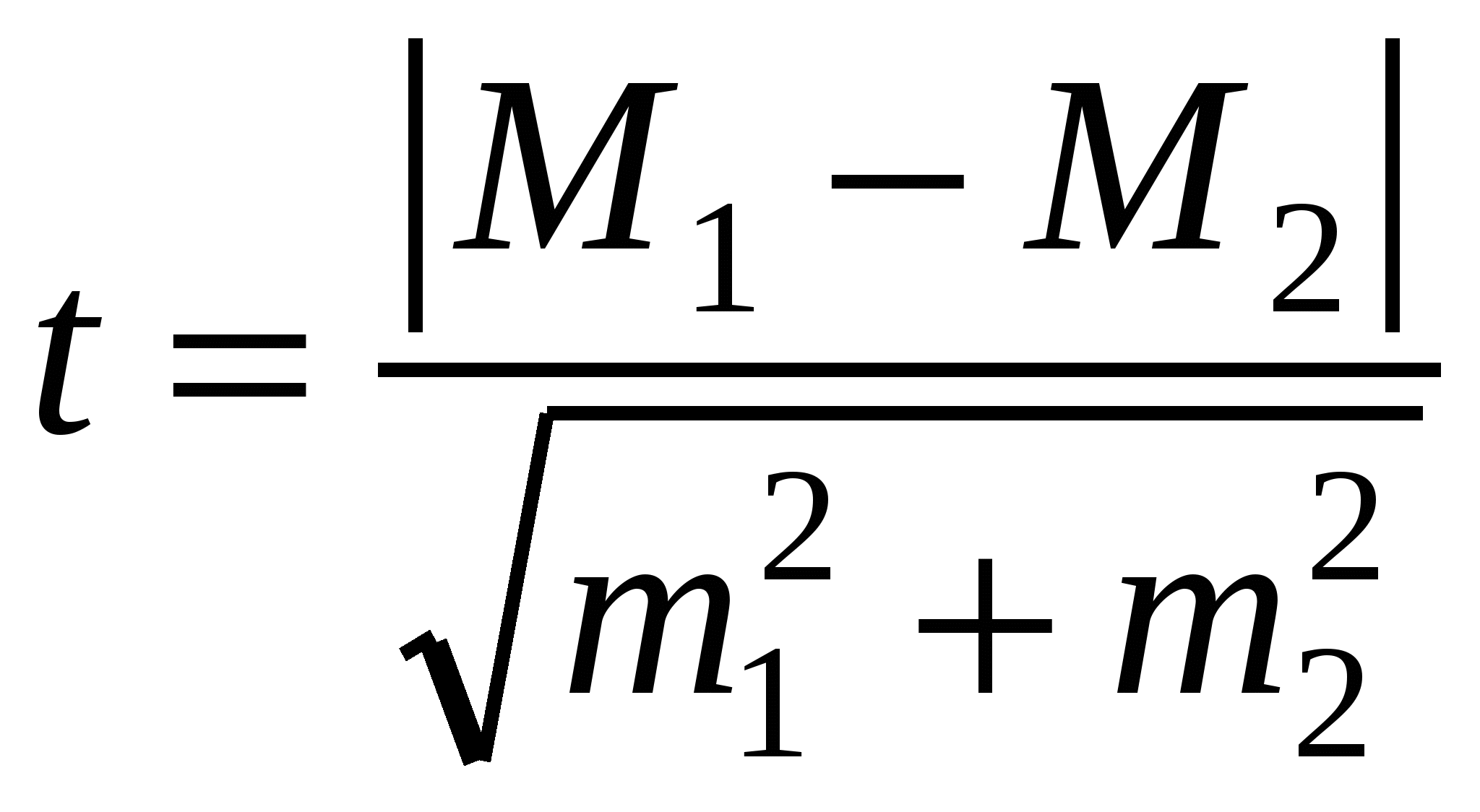 t(α, df).
Следует помнить, что разность средних нужно брать по модулю, т. е. без учета знака. Полученное этим способом значение критерия t Стьюдента сравнивают с табличным при выбранном уровне значимости (обычно для α = 0.05) и числе степеней свободы (объемы выборок без числа ограничений, df = n1 + n2 − 2). Результатом такого сравнения должен стать один из двух вариантов следующего статистического вывода. Если полученное значение (величина) критерия больше табличного, значит, различия между параметрами при заданном уровне значимости и установленном числе степеней свободы достоверны. Если же полученная величина критерия меньше табличной, то при данном уровне значимости и числе степеней свободы различия между параметрами недостоверны. Последнее говорит о том, что различия случайны, никакого определенного вывода сделать нельзя, нулевая гипотеза остается неопровергнутой.
При сравнении выборочных параметров нормального и биномиального распределений используется одна и та же формула. Например, в процессе специальных исследований было установлено, что у стариков до лечения инсулином среднее содержание белков в крови составляло 81.04 ± 1.7, а после лечения 79.33 ± 1.6. Нетрудно видеть, что полученные величины неодинаковы. Но достоверно ли это различие, закономерно ли оно? Можно ли на его основании утверждать, что лечение инсулином понижает содержание белков в крови? Ответ на этот вопрос может дать критерий достоверности различий средних арифметических. Согласно общей нулевой гипотезе средние не отличаются. Проверим ее с помощью критерия Стьюдента:
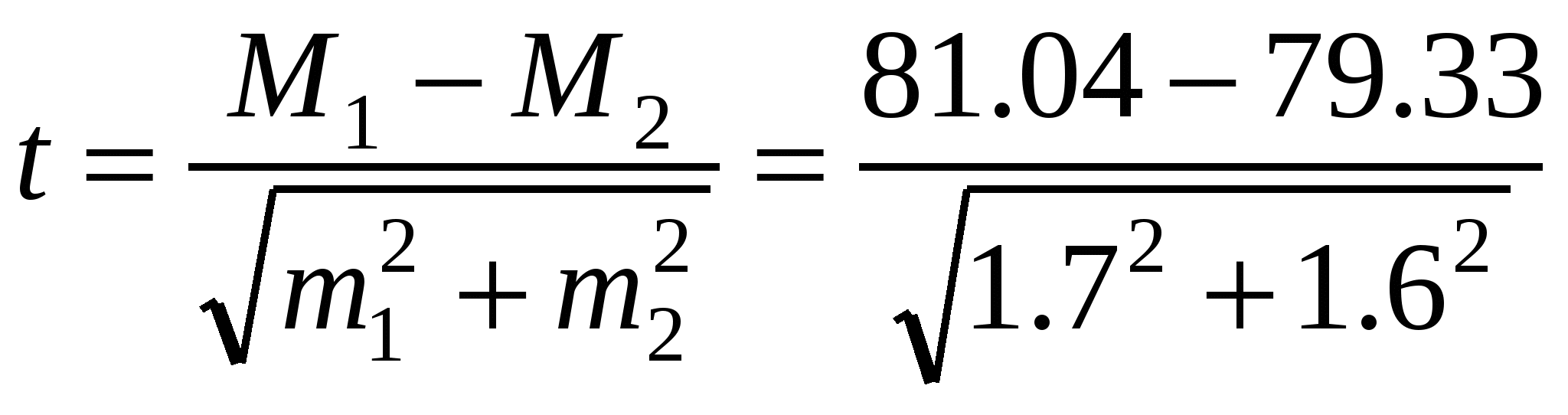 = 0.7. = 0.7.
По таблице граничных значений критерия (табл. 6П) находим, что для уровня значимости α = 0.05 и числа степеней свободы df= 20 + 20 − 2 = 38 величина критерия составляет t(0.05,39) = 2.03. Поскольку полученное значение (0.7) меньше табличного (2.03), нулевая гипотеза сохраняется, различия между средними величинами статистически недостоверны (незначимы). Следовательно, влияние инсулина на содержание белков в крови приведенными выше данными не подтверждается и остается недоказанным, возможно, из-за недостаточного числа определений.
Сравнение долей
При сравнении достоверности различия долей или процентов (p)признаков, характеризующихся альтернативным распределением, применяют критерий Фишера с φ-преобразованием. Вместо процентов берут фи-значения (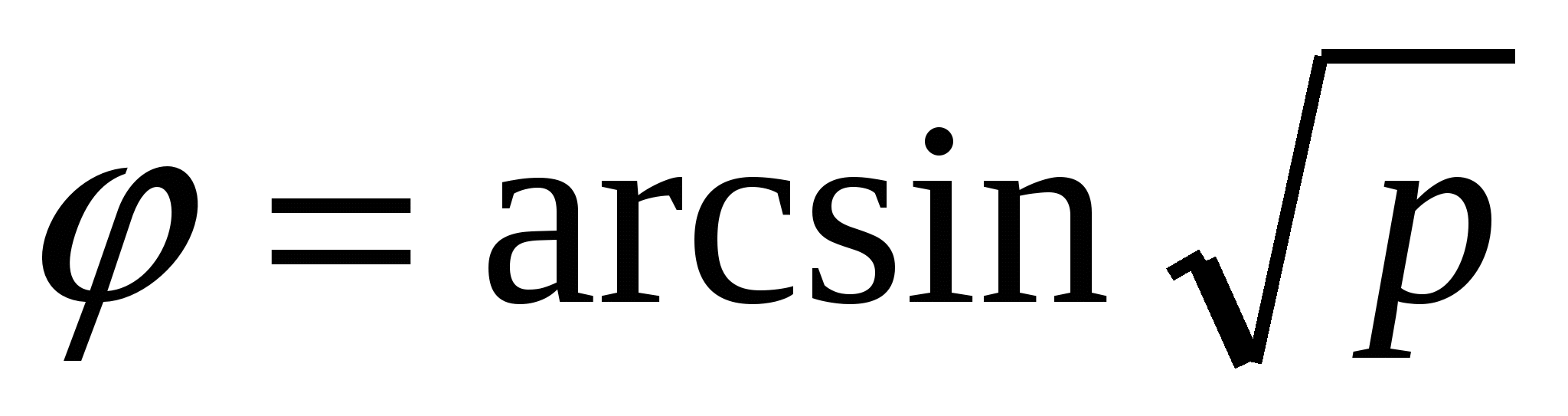 или по таблице 10П) и подставляют их в формулу: или по таблице 10П) и подставляют их в формулу:
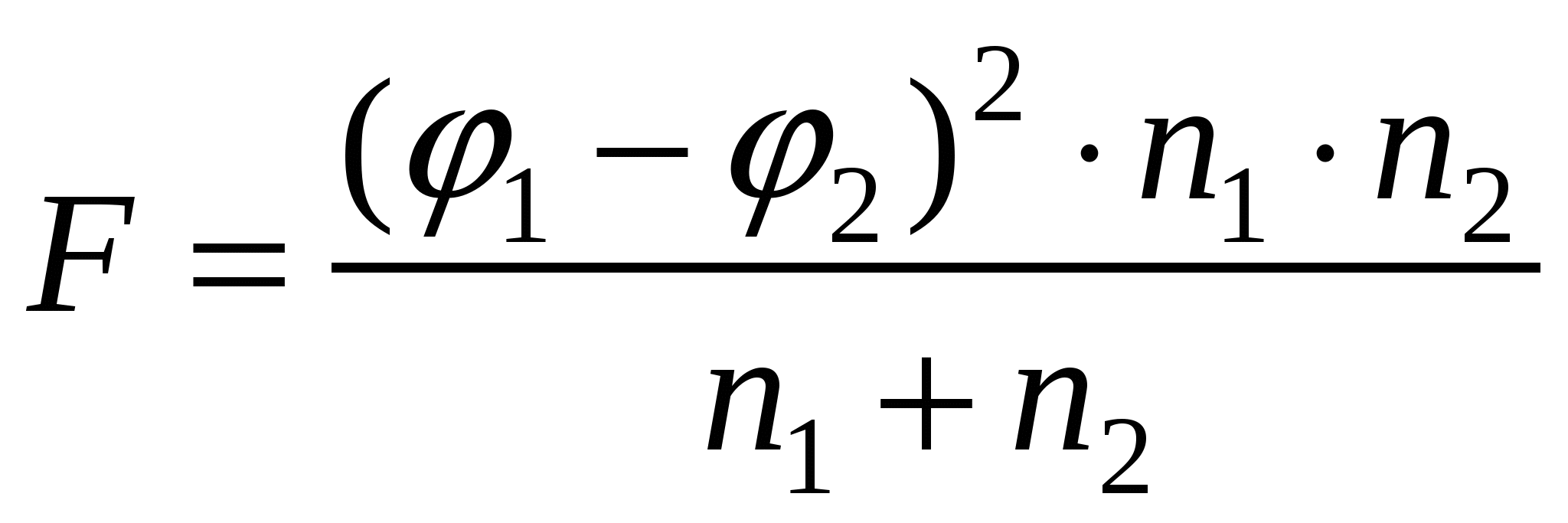
F(α, df1, df2),
где φ1 и φ2 – преобразованные доли,
n1 и n2 – объемы выборок.
Полученное значение сравнивают с табличным в соответствии с заданным уровнем значимости, α = 0.05, и числом степеней свободы: df1 = 1, df2 = n1 + n2 − 2.
Например, в процессе учетов мелких млекопитающих в двух разных биотопах, где стояло по 200 ловушек, попалось соответственно 5 и 15 зверьков. Отличается ли численность животных на этих площадках? Если рассматривать ловушку как варианту, способную принимать два значения – «пустая» и «сработавшая» (со зверьком), то получаем выборку вариант (ловушек) с альтернативным распределением. Число пойманных особей можно пересчитать в процент сработавших ловушек: М1 = 100% ∙ 5 /200 = 2.5%, М1 = 100% ∙ 15 / 200 = 7.5%. По таблице 10П находим значения φ и вычисляем значение критерия: 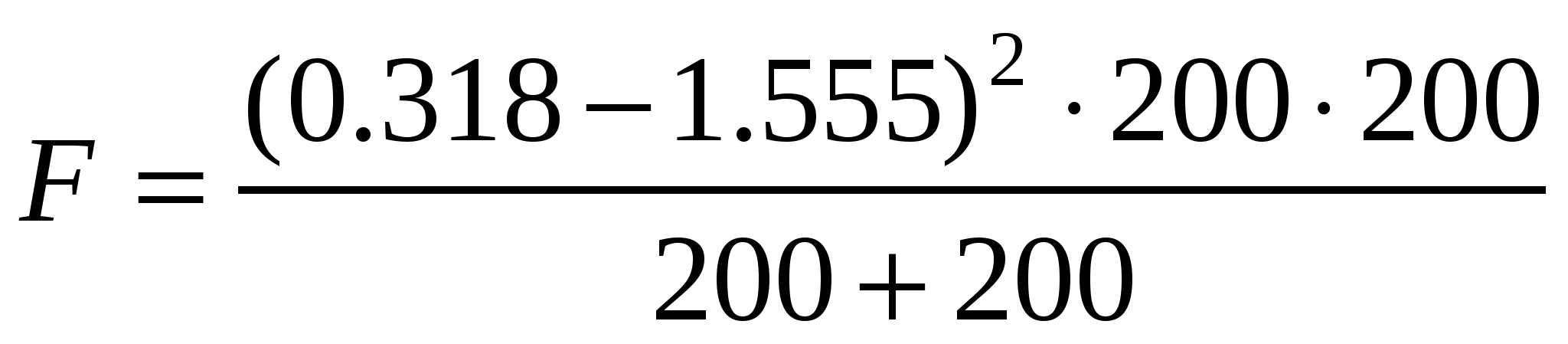 = 5.62. Полученная величина (5.62) больше критической F(0.05, 1, 398) = 3.9, значит, численность мелких млекопитающих во втором биотопе достоверно выше, чем в первом. = 5.62. Полученная величина (5.62) больше критической F(0.05, 1, 398) = 3.9, значит, численность мелких млекопитающих во втором биотопе достоверно выше, чем в первом.
Сравнение показателей изменчивости
Наиболее точным методом определения достоверности различий между выборочными дисперсиями служит критерий F Фишера в форме отношения дисперсий (большее значение должно стоять в числителе):
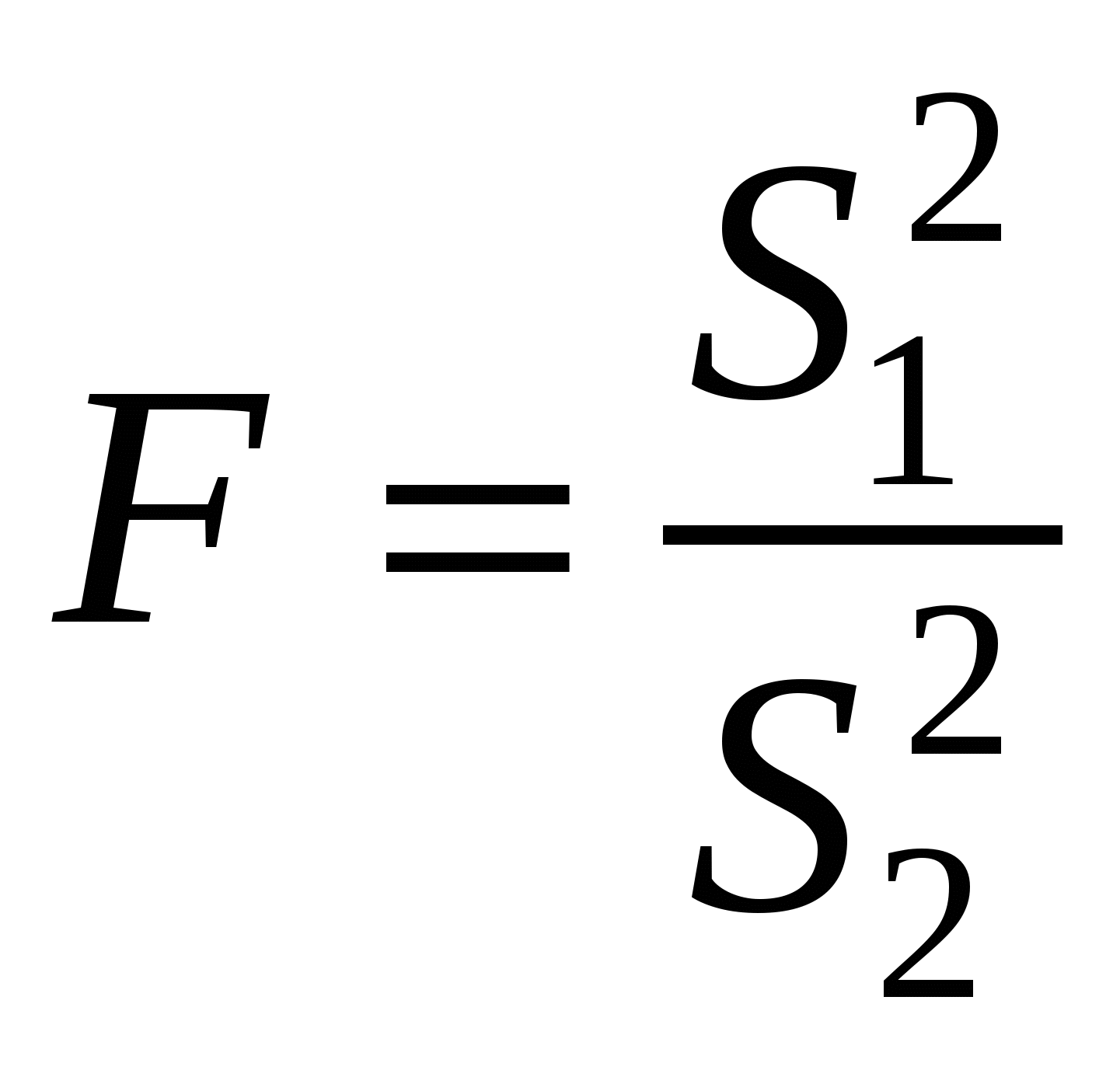
F(α, df1, df2),
где S1 > S2, df1 = n1 − 1, df2 = n2 − 1.
Если полученная величина F больше табличного значения при принятом уровне значимости (табл. 7П для α = 0.05 и табл. 8П для α = 0.01) и числе степеней свободы (df1иdf2), то различие между дисперсиями признается достоверным; если она меньше, то расхождение между ними может считаться несущественным, случайным, т. е. нулевая гипотеза не отвергается.
Рассмотрим такой пример. При сравнении по показателю плодовитости (число эмбрионов на самку) двух популяций красной полевки с разным уровнем численности (у первой, горной, популяции плотность населения в два раза выше, чем у равнинной) оказалось, что при очень близких средних арифметических (соответственно M1 = 5.8 и M2 = 5.4, разница статистически недостоверна) стандартные отклонения значительно различаются: S1 = 1.82, S2 = 0.52 (при n1 = 27, n2 = 12). Отсюда
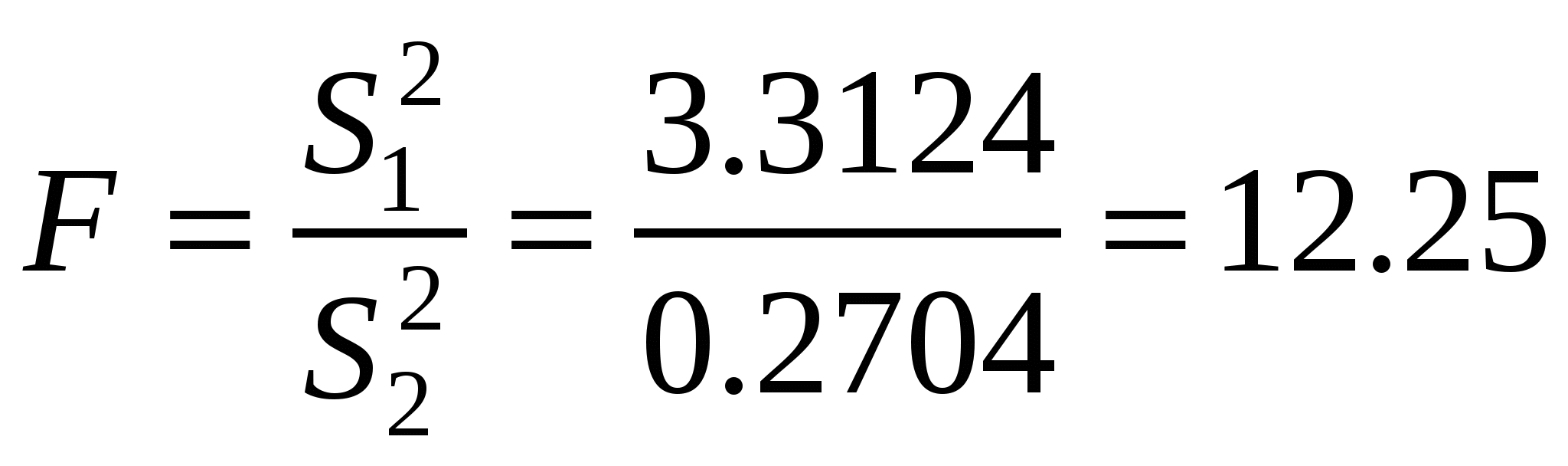 . .
Полученное значение критерия (F= 12.2) больше табличного F(0.05, 26, 11) = 2.6, следовательно, нулевую гипотезу о случайности отличий можно отбросить, сделав вывод о том, что показатели изменчивости плодовитости в разных по численности популяциях достоверно отличаются. С биологических позиций это понятно, поскольку генетические отличия между особями практически по всем признакам, включая плодовитость, в больших популяциях выше, чем в малых. Новым фактором, усиливающим изменчивость особей в выборке, становится возможность появления аберрантных форм в условиях более свободной панмиксии.
Коэффициенты вариации также можно использовать для сравнения изменчивости разных показателей. Достоверность отличий коэффициентов оценивается с помощью критерия Стьюдента по формуле:
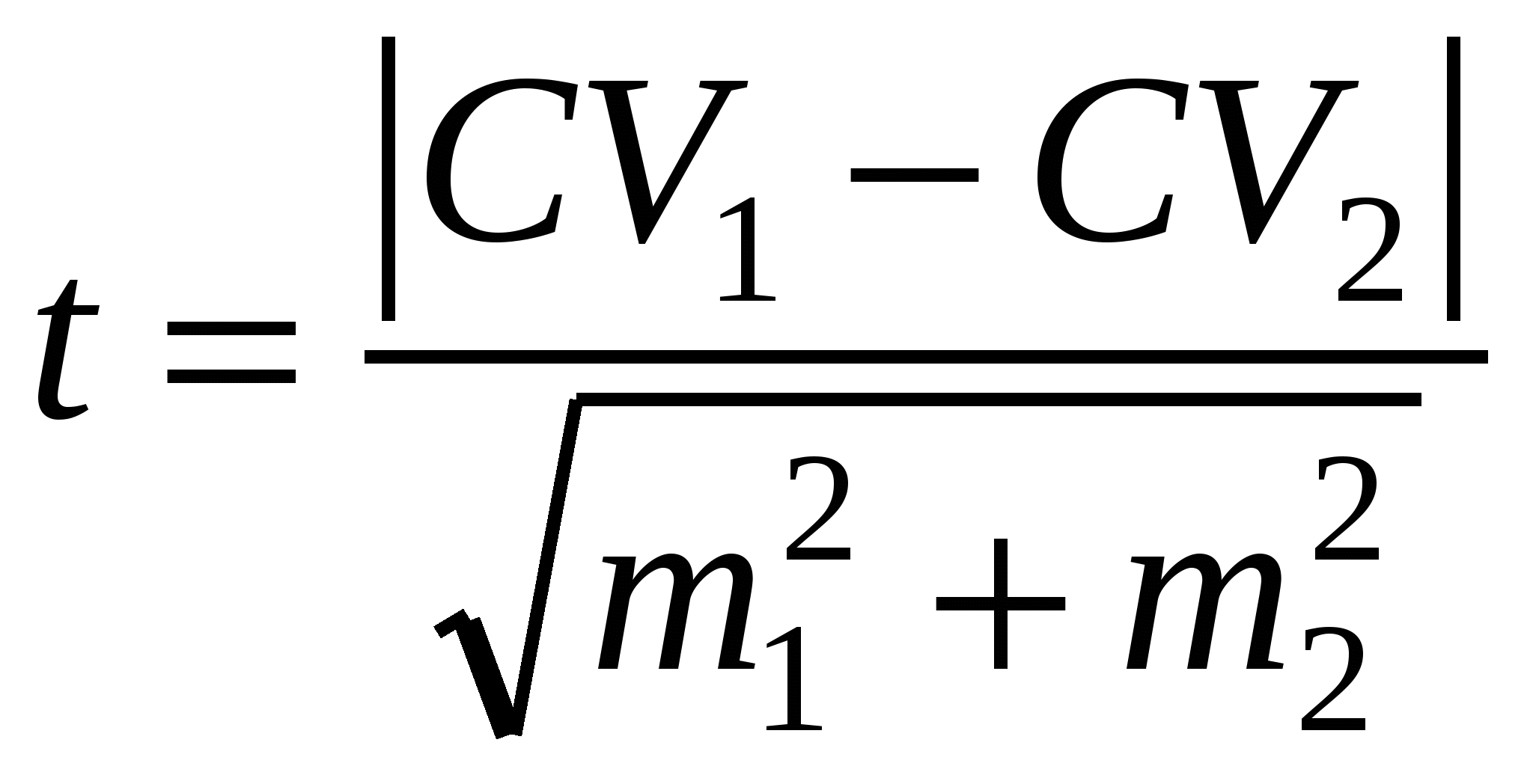
t(0.05, n1+n2−2),
где CV1, CV2 и m1, m2 – значения и ошибки коэффициентов вариации.
Вывод о достоверности отличий делается в том случае, если рассчитанное значение превысит табличное при заданном уровне значимости α = 0.05 и числе степеней свободы df = n1+ n2 − 2. Сравним по критерию Стьюдента изменчивость веса тела землероек и плодовитости лисиц:
CV1 = 8.6 ± 0.77%, n1 = 63; CV2 = 26.7 ± 2.2%, n2 = 76, отсюда
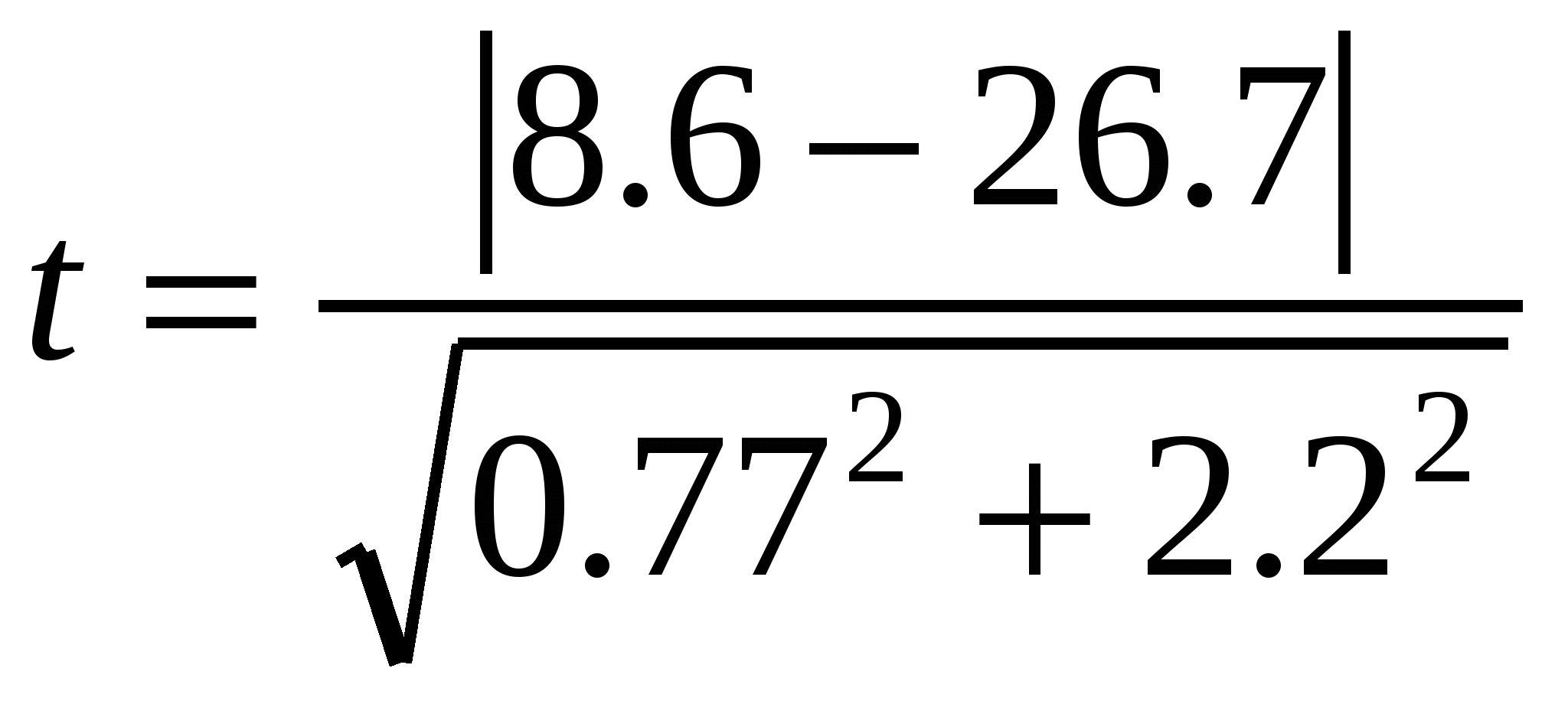 = 7.76. = 7.76.
Поскольку полученное значение (7.8) больше табличного (t(0.05, 137) = 1.96), изменчивость плодовитости лисиц достоверно выше, чем изменчивость веса тела землероек.
Сравнение выборок с помощью непараметрических критериев
Описанные выше статистические критерии (t, F и др.) относятся к параметрическим, т. к. используют стандартные параметры распределений (М, S, n). Они связаны с законом нормального распределения и применяются для оценки расхождения между генеральными параметрами по выборочным показателям сравниваемых совокупностей. Существенным достоинством параметрических критериев служит их большая статистическая мощность, т. е. широкие разрешающие возможности, а недостатком – трудоемкость расчетов, неприменимость к распределениям, сильно отклоняющимся от нормального, а также при исследовании качественных признаков.
Наряду с параметрическими критериями для ориентировочной оценки расхождений между выборками (особенно небольшими) применяются так называемые непараметрические критерии, ориентированные в первую очередь на исследование соотношений рангов исходных значений вариант. Ранг – это число натурального ряда, которым обозначается порядковый номер каждого члена упорядоченной совокупности вариант. Эта замена позволяет сравнивать выборки как по количественным, так и по качественным признакам, значения которых не имеют числового представления, но которые можно ранжировать. Конструкции непараметрических критериев отличаются простотой.
Вся процедура состоит из трех этапов – упорядочивание и ранжирование вариант, подсчет сумм рангов в соответствии с правилами данного критерия, сравнение полученной величины с табличным значением критерия. При этом с параметрическими критериями их роднит общая идеологическая подоплека. Нулевая гипотеза, как правило, состоит в том, что сравниваемые выборки взяты из одной и той же генеральной совокупности, значит, характер распределения вариант в этих выборках должен быть сходным. Поскольку вместо самих значений вариант используются ранги, все непараметрические методы исследуют один вопрос, насколько равномерно варианты разных выборок «перемешаны» между собой. Если варианты разных выборок более или менее регулярно чередуются в общем упорядоченном ряду, значит, они распределены сходным образом и отличий между совокупностями нет. Если же выборки пересекаются не полно (смешиваются только краями распределений, либо одна поглощает другую), то становится ясно, что эти выборки взяты из разных генеральных совокупностей (со смещенными центрами или разными дисперсиями).
Среди множества известных методов мы рассмотримдва метода: Уилкоксона – Манна – Уитни (довольно точный, но не самый простой для вычислений) и критерий Q Розенбаума. (простой для расчетов, но не очень точный).
|
|
|
 Скачать 3.04 Mb.
Скачать 3.04 Mb.