Машфак. ТВ иМС для МСФ. Исследование связи между показателями, часть из которых являются случайными
 Скачать 2.07 Mb. Скачать 2.07 Mb.
|

|
А. Дискретные случайные величины. Пусть X–дискретная случайная величина, которая в результате п опытов приняла возможные значения х1, х2,... , хп. Допустим, что вид закона распределения величины Xзадан, но неизвестен параметр θ, которым определяется этот закон. Требуется най- ти его точечную оценку θ* = θ*(х1, х2, ... , хп). Обозначим вероятность того, что в результате испытания величина Xпримет значение хi через р (xi; θ). Функцией правдоподобия дискретной случайной величины Xназывают функцию аргумента θ: L(x1, x2, ..., xn; θ) = р(x1; θ) р(x2; θ) ... р(xn; θ). Оценкой наибольшего правдоподобия параметра θ называют такое его значение θ*, при котором функция правдоподобия достигает максимума. Функции L и 1nLдостигают максимума при одном и том же значении θ, поэтому вместо отыскания максимума функции L ищут, что удобнее, максимум функции 1nL (логарифмическая функция правдоподобия). Точку максимума функции 1nL аргумента θ можно искать, например, так: 1. Найти производную 2. Приравнять производную нулю и найти критическую точку θ* – корень полученного уравнения (уравнения правдоподобия). 3. Найти вторую производную 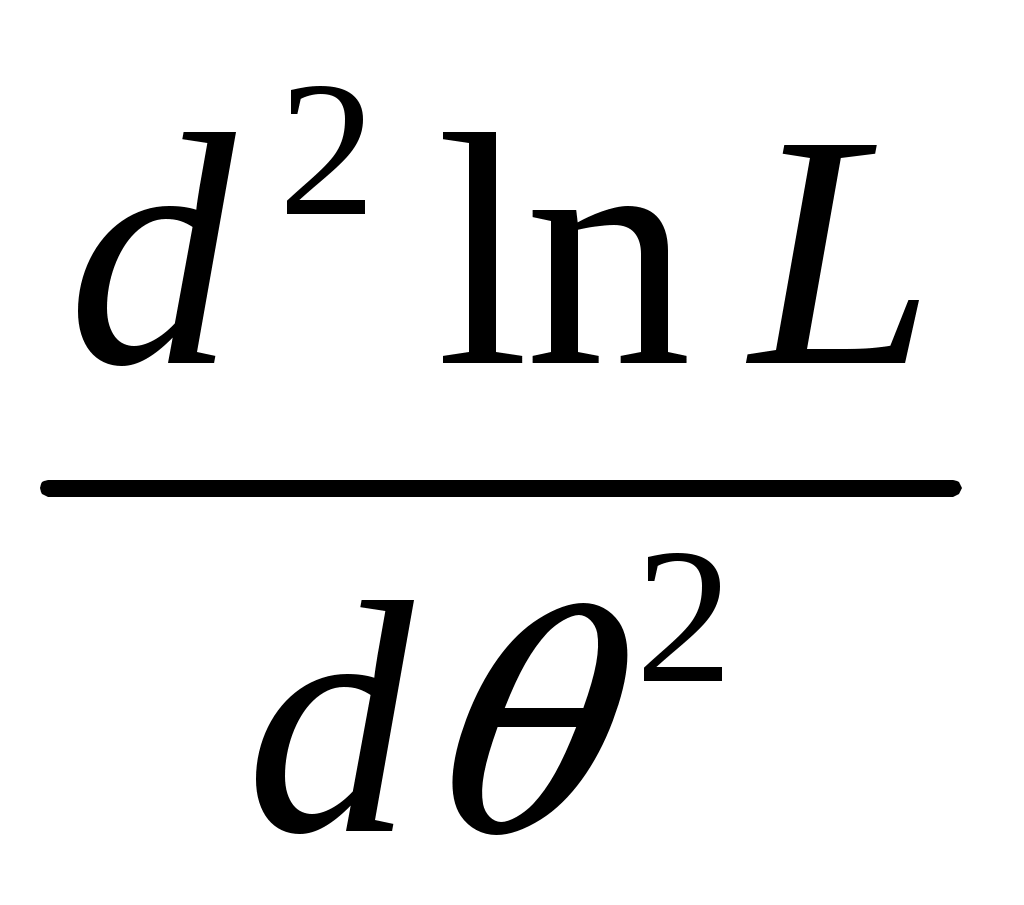 ; если вторая производная при ; если вторая производная приθ = θ* отрицательна, то θ* – точка максимума. Найденную точку максимума θ* принимают в качестве оценки наибольшего правдоподобия параметра θ. Б. Непрерывные случайные величины. Пусть X– непрерывная случайная величина, которая в результате п испытаний приняла значения х1, х2,..., хп. Допустим, что вид плотности распределения – функции f(x) – задан, но неизвестен параметр θ, которым определяется эта функция. Функцией правдоподобия непрерывной случайной величины Xназы-вают функцию аргумента θ: L(x1, x2, ..., xn; θ) = f(x1; θ) ∙ f(x2; θ) ∙ ... ∙ f(xn; θ). Оценку наибольшего правдоподобия неизвестного параметра распре- деления непрерывной случайной величины ищут так же, как в случае дис-кретной случайной величины. Если плотность распределения f(х)непрерывной случайной величины определяется двумя неизвестными параметрами θ1 и θ2, то функция правдоподобия есть функция двух независимых аргументов θ1 и θ 2: L= f(x1; θ1, θ 2) ∙ f(x2; θ 1, θ 2) ∙ ... ∙ f(xn; θ1, θ 2). Далее находят логарифмическую функцию правдоподобия и для отыскания ее максимума составляют и решают систему  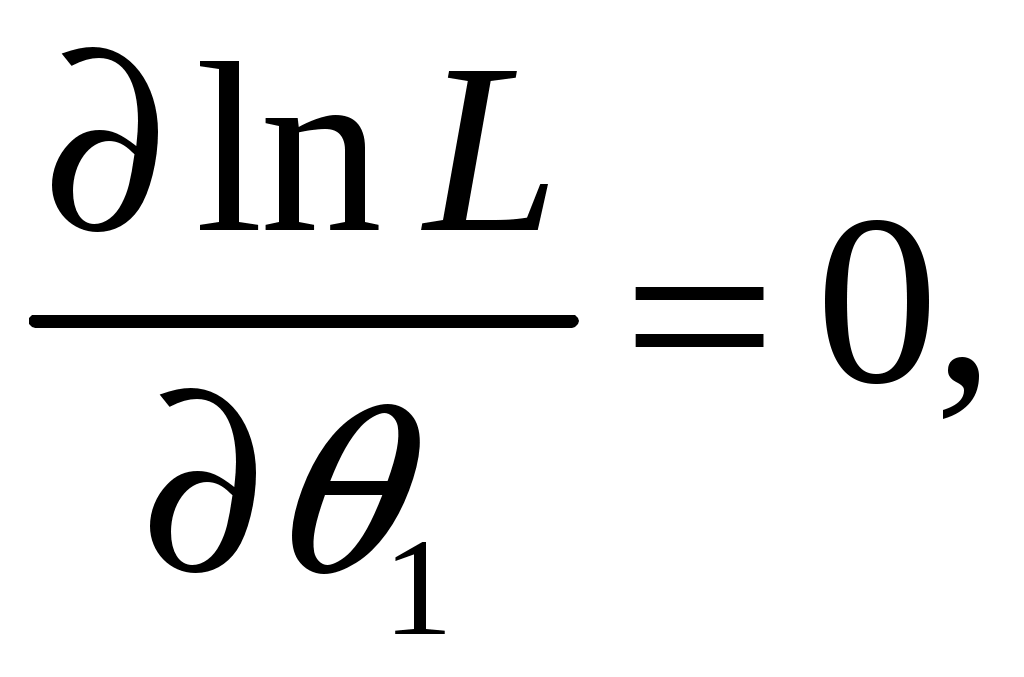 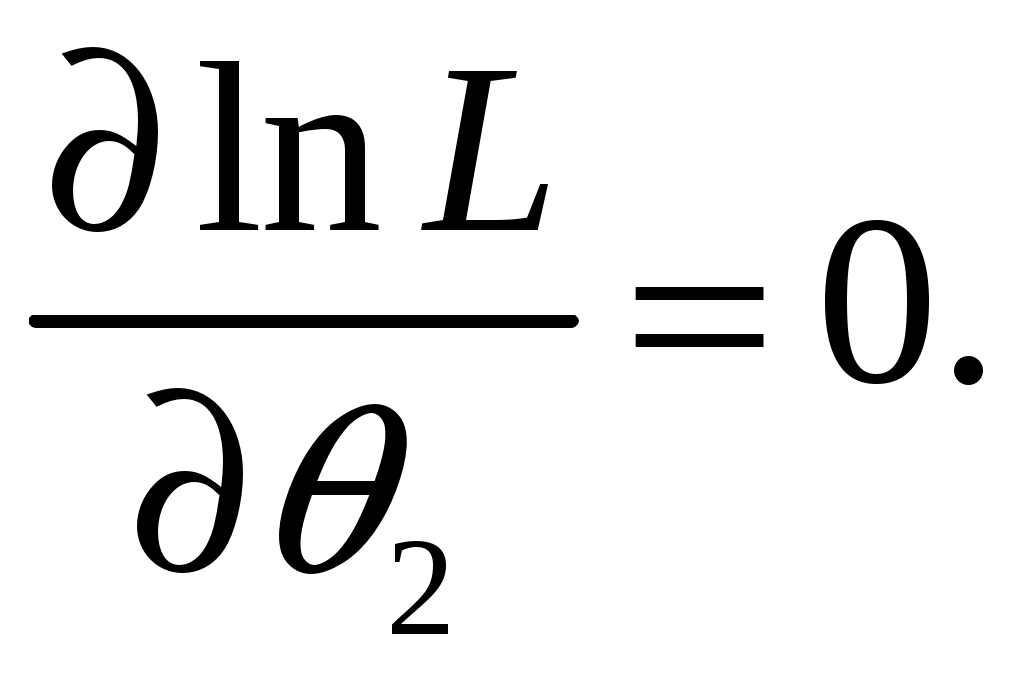 При малом числе наблюдений точечные оценки могут приводить к грубым ошибкам. Чтобы избежать этих ошибок, используют интервальные оценки. Интервальной оценкой называют оценку, которая определяется дву- мя числами Однако статистический метод не позволяет категорически утверждать, что оценка удовлетворяет неравенству (2.10) в смысле математического анализа. Можно только говорить о вероятности (1–), с которой это неравенство выполняется. Доверительной вероятностью оценки называют вероятность (1–) выполнения неравенства Пусть вероятность того, что Формула показывает, что доверительный интервал вает неизвестный параметр с заданной надежностью (1–). Чем меньше длина доверительного интервала Длина доверительного интервала 2 определяется двумя величинами: доверительной вероятностью (1–) и объемом выборки n. Таким образом, , (1–) и n тесно взаимосвязаны и, задавая определенные значения двум из них, можно определить величину третьей. Например, пусть 1. Если известно, то доверительный интервал, накрывающий неизвестное математическое ожидание a с заданной доверительной вероятностью (1–), имеет следующий вид: 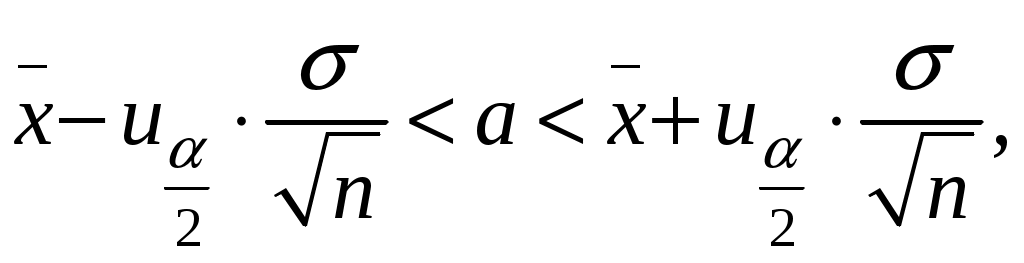 где 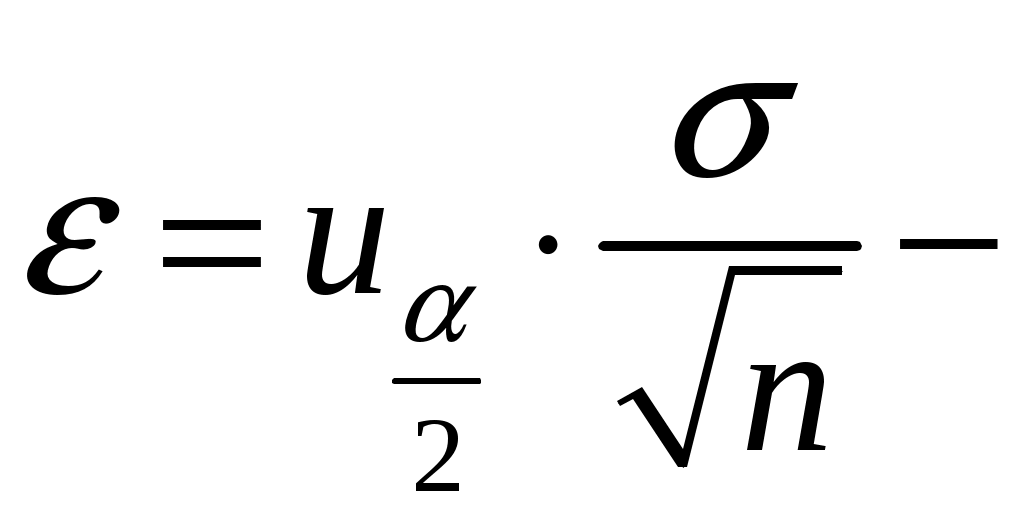 точность (предельная погрешность) точечной оценки математического ожидания. точность (предельная погрешность) точечной оценки математического ожидания. 2. Если же неизвестно, тогда доверительный интервал, накрывающий неизвестное математическое ожидание а СВ ХN (a,), имеет сле-дующий вид: 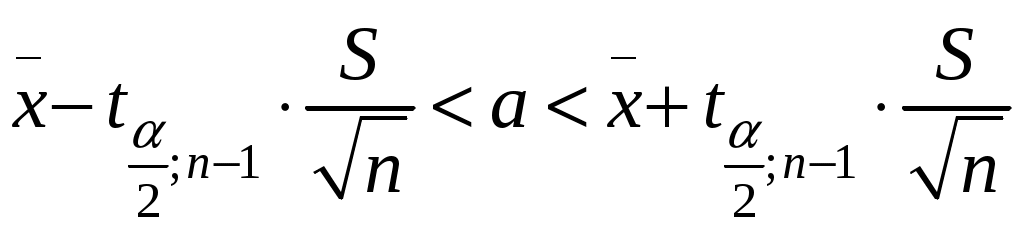 , , где 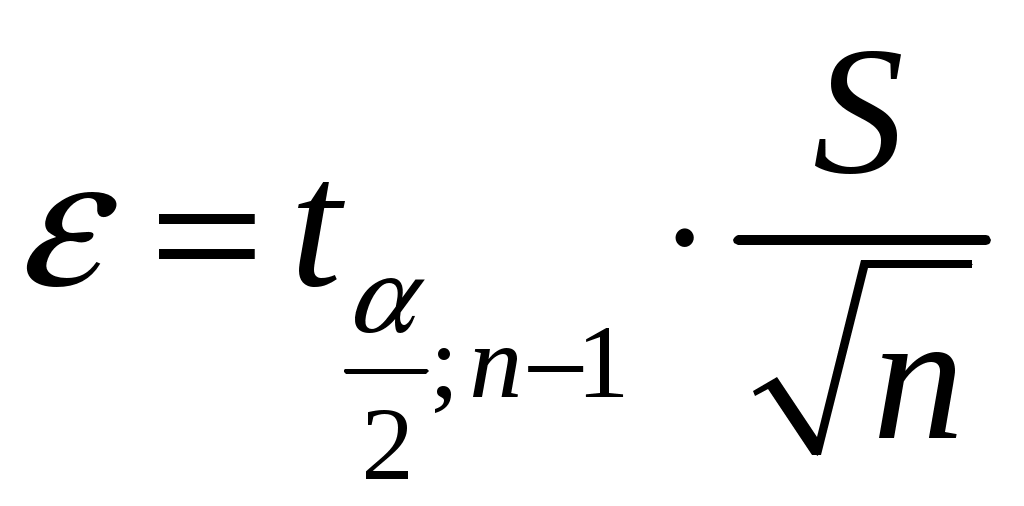 – предельная погрешность точечного оценивания математического ожидания a. – предельная погрешность точечного оценивания математического ожидания a. 3. Доверительный интервал для среднего квадратического отклонения задается системой неравенств 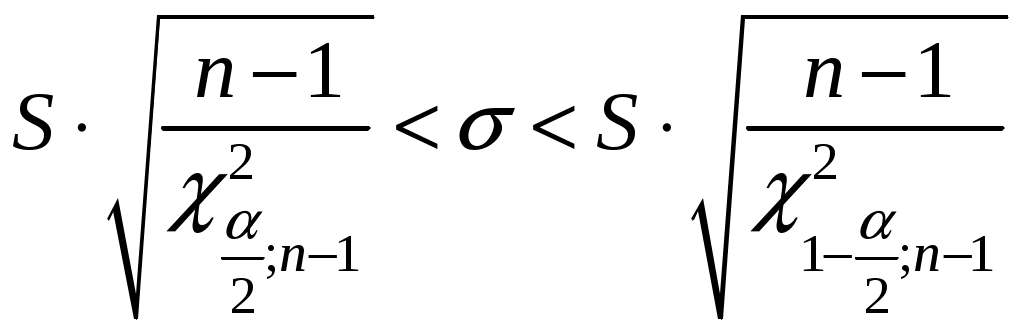 , , где распределения 2 (Приложение 3) по заданной доверительной вероятности (1–) и числу степеней свободы = n–1. Раздел 8. Статистическая проверка гипотез Статистическая гипотеза (или просто гипотезой) – всякое высказывание (предположение) о генеральной совокупности, проверяемое по выборке. Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотезы. Различают два вида критериев: параметрические и непараметричес-кие. Предположение, которое касается неизвестного значения параметра распределения, входящего в некоторое параметрическое семейство распределений, называется параметрической гипотезой. Предположение, при котором вид распределения неизвестен (т.е. не предполагается, что оно входит в некоторое параметрическое семейство распределений), называется непараметрической гипотезой. Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки. Одну из гипотез выделяют в качестве основной (или нулевой) и обозначают тивоположную потезы и обозначают Гипотезу, однозначно фиксирующую распределения наблюдений, на- зывают простой (в ней идет речь об одном значении параметра), в противном случае – сложной. Правило, по которому принимается решение принять или отклонить гипотезу Основной принцип проверки гипотез состоит в следующем. Множество возможных значений статистики критерия • ошибка I-го рода состоит в том, что отвергается нулевая гипотеза • ошибка ІІ-го рода состоит в том, что отвергается альтернативная гипотеза Вероятность ошибки 1-го рода (обозначается через ) называется уровнем значимости критерия. Очевидно, Вероятность ошибки 2-го рода обозначается через Очевидно, Отметим, что одновременное уменьшение ошибок 1-го и 2-го рода возможно лишь при увеличении объема выборок. Поэтому обычно при заданном уровне значимости Методика проверки гипотез сводится к следующему: 1. Располагая выборкой В каждом конкретном случае подбирают статистику критерия По статистике критерия K и уровню значимости Границы областей определяются из соотношений: • • • Для каждого критерия имеются соответствующие таблицы, по кото- рым и находят критическую точку, удовлетворяющую приведенным выше соотношениям. |