Прогнозирование принятия управленческих решений.. Методические указания по изучению курса 7 Варианты контрольной работы 9 Рекомендации по выполнению контрольной работы 12
 Скачать 1.95 Mb. Скачать 1.95 Mb.
|

|
Раздел 2.1. Методы непосредственной экстраполяции Прогнозирование с использованием временных рядов Простейшими методами прогнозирования на основе статистической информации являются экстраполяционные методы, основанные на анализе временных рядов. Многие данные исследований, в частности маркетинговых, представляются для различных интервалов времени, например, на ежегодной, ежемесячной и др. основе. Такие данные называются временными рядами. Под временным рядом (или рядом динамики) понимают совокупность числовых величин, характеризующих изменение некоторого показателя во времени. Временной ряд (ВР) задается в табличной или графической формах и состоит из двух элементов: числовых значений показателя (yi) - уровни ряда и момента времени (t), к которым относятся соответствующие уровни. Оба элемента - члены ВР. Если члены ряда отражают состояние объекта за определенные промежутки времени - ряд называется интервальным, если фиксируют в строго установленные моменты - моментным. В зависимости от способа изменения переменной yt возможно построение ВР, состоящего из абсолютных, относительных и средних величин. Относительные уровни динамических рядов можно получить путем деления абсолютных или средних значений на один и тот же элемент ряда, принятый за базу. Возможно получение относительных величин при сравнении каждого уровня с предыдущим. Особенность динамических рядов в том, что абсолютный уровень каждого члена ряда является одновременно результатом прошлого развития и сходной предпосылкой для экономического роста в будущем. Если говорить более подробно, то элементы ВР формируются под влиянием как объективных, так и случайных факторов. Поэтому каждый член динамического ряда можно представить в виде: Yt = ўt + ytc+ytц+, (2.1) где ўt – значение признака, вытекающее из закономерного изменения показателя во времени, ytц – циклическая компонента, соответствующая колебаниям относительно долгосрочного тренда под воздействием среднесрочных флуктуаций экономической активности; ytc – сезонная компонента, или краткосрочные периодические флуктуации, обусловленные различными причинами (климат, социально-психологические факторы, структура нерабочих дней и т.д.); t - случайная компонента, отражающая совокупное действие плохо изученных процессов, не представимых в количественной форме. Для каждой компоненты рассчитывается параметр, основанный на наблюдавшихся закономерностях: долгосрочном темпе прироста продаж, конъюнктурных флуктуациях, сезонных коэффициентах, специфичных факторах (например для маркетинга – демонстрации товара, мероприятия по стимулированию сбыта и т.п.). Затем эти параметры используют для составления прогноза. Совокупность значений ўt за ряд лет выражает тенденцию развития признака во времени, его эволюцию. Эта компонента называется трендом, тенденцией, эволюторной составляющей. Тренд характеризует общую тенденцию в изменениях показателей ряда. Те или иные качественные свойства развития выражают различные уравнения трендов: линейные, параболические, экспоненциальные, логарифмические, логистические и др. После теоретического исследования особенностей разных форм тренда необходимо обратиться к фактическому временному ряду, тем более что далеко не всегда можно надежно установить, какой должна быть форма тренда из чисто теоретических соображений. По фактическому динамическому ряду тип тренда устанавливают на основе графического изображения, путем осреднения показателей динамики, на основе статистической проверки гипотезы о постоянстве параметра тренда. Разработка прогнозов на базе ВР происходит в несколько этапов. Элементы ВР наносятся на координатное поле; Если графическое построение не дает четкого представления о закономерности изменения признака во времени, то применяются специальные статистические приемы обработки данных (сглаживание по скользящей средней, определение последовательных разностей и пр.); Выбирают и рассчитывают параметры аналитической функции вида ўt =f(t), отражающей динамику изменения прогнозируемого показателя yt во времени. Сглаживание временного ряда Отметим, что пункт 2 представленной схемы прогнозирования может выполнять двоякую роль: он может быть как подготовительным этапом для дальнейшей обработки представленных данных (т.е. для выполнения этапа 3 – расчета параметров прогнозирующей функции ўt), так и служить вполне самостоятельным методом прогнозирования, т.к. он даёт определенное представление о характере тренда. Рассмотрим два способа сглаживания. Метод скользящей средней Суть метода состоит в замене фактических значений показателя их усредненными величинами. Порядок построения. Пусть y1, y2, ..., yn - динамический ряд. Для определения скользящей средней последовательно рассчитывают сумму m (нечетное число) элементов ряда. По отдельным суммам определяют средние арифметические, каждая из которых меняет свою величину (“скользит”) по мере увеличения t. Наиболее часто на практике применяются трех- и пятичленные средние. Формулы расчета: yt’ = (yt-1 +yt+yt+1)/3, t=2,3, ... , (n-1) (2.2) yt’ =(yt-2 + yt-1 +yt+yt+1+ yt+2)/5, t=3,4, ... , (n-2) (2.3) Если скользящая средняя определяется по четному числу элементов, то она не может быть приписана реальному значению t. Ее определяют в 2 этапа: сначала находят средние для промежутков (t-1,t) и (t, t+1), а затем полученные величины суммируют и вновь используют для расчета средней. Чаще используется вычисление по 4 членам ряда: yt’ =1/2[(yt-2+yt-1 +yt+yt+1)/4+(yt-1+yt+yt+1+ yt+2)/4], t=3,4,.. ,(n-2) (2.4) Пример 2.1. В таблице 2.1 представлен объем реализации кондитерских изделий торговым предприятием в течение года. Данные нанесены на график рис. 2.1. Как следует из этого графика этот показатель характеризуется достаточно большим разбросом точек. Поэтому применим к нему метод скользящей средней. Результаты расчетов внесены в таблицу 2.1. и показаны на рис. 2.1. Таблица 2.1.
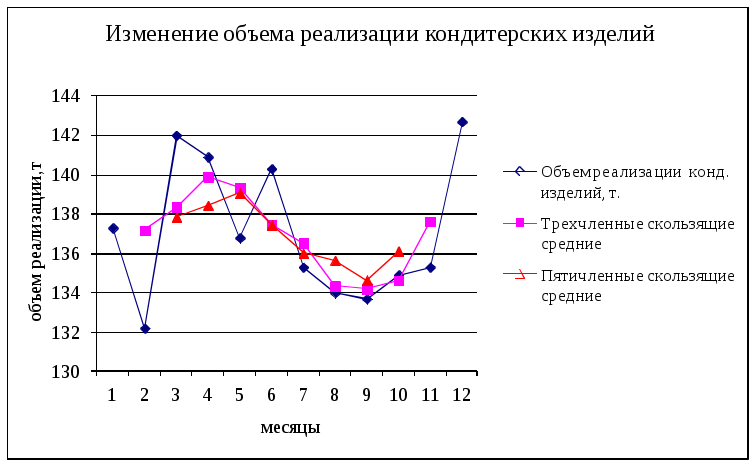 Рис. 2.1. График к примеру 2.1. Метод конечных разностей Сфера применения - случай, когда динамика изменения исследуемой переменной отображается одним из полиномов k-го порядка: ўt =a0 +a1 t+a2t2 + ... + aktk (2.5) Особенность метода - последовательное определение специальных показателей - разностей, среди которых различают разности первого, второго и т.д. порядков: t1 =yt+1 - yt (t=1,2,3, ... , n-1); (2.6) t2=t+11 -t1 = yt+2 - 2yt+1 + yt (t=1,2,3, ... , n-2); (2.7) t3=t+12 -t2 = yt+3 - 3yt+2 +3yt+1 - yt (t=1,2,3, ... , n-3); (2.8) и т.д. В основе метода конечных разностей лежит одно из свойств полинома степени k обращать в нуль разности t+1k+1 и придавать одинаковое значение разностям t+1k . Пример 2.2. По данным объема производства хлеба на предприятиях экономического района за 8 лет необходимо определить закономерность выработки продукции за анализируемый промежуток времени. Рассчитаем первые и вторые разности (см. таблицу 2.2). Таблица 2.2
Как следует из данной таблицы, абсолютные уровни первых разностей для всех значений t являются практически одинаковыми, а величина вторых разностей в большинстве случаев принимает нулевые или близкие к ним значения. Поэтому можно определить зависимость выработки хлеба от времени как полином 1-ой степени, то есть линейную зависимость. Подбор аналитической функции Представив в графическом виде данные, можно с помощью метода наименьших квадратов подобрать линию, в наибольшей степени соответствующую полученным данным и определить прогнозную величину исследуемого признака. Замечание. Строго говоря, подбор аналитической функции нельзя отнести к методу непосредственной экстраполяции. Ведь в данном случае происходит замена временного ряда некой подобранной функцией, т.е. ломаная линия заменяется непрерывной кривой, которую можно рассматривать как некую регрессивную функцию (или математическую статистическую модель). А это значит, что далее мы объединяем метод экстраполяции с методом статистического моделирования. Метод наименьших квадратов Рассмотрим метод наименьших квадратов, который находит применение как в экстраполяционных методах прогнозирования, так и в прогнозах с использованием статистического моделирования. Суть метода наименьших квадратов (МНК) в том, чтобы подобрать параметры уравнения прогноза ўt = f(t) с таким расчетом, чтобы квадраты суммарных отклонений фактических значений ряда (yt) от найденных по статистической модели (ўt) были бы минимально возможными, то есть: (yt - ўt)2 = min (2.9) записав уравнение прямой в виде ўt = a+bt и подставив его в (2.9), получим: (yt - a-bt)2 =min (2.10) В рассматриваемом условии минимизации значения переменных yt и t за предпрогнозный период являются известными, а параметры a и b -неизвестными константами. Для их нахождения надо приравнять нулю частные производные от (2.10) по каждой искомой константе в отдельности. После соответствующих преобразований получают систему уравнений, которую называют нормальной. Для линейного тренда ўt = a+bt нормальные уравнения: yt= na + bt, (2.11) ytt = at + bt2 Подставив в систему (2.11) имеющуюся исходную информацию (yt и t) рассчитываются параметры прогнозирующей функции а и b. Сомножитель n - длина временного ряда. Также можно получить нормальные уравнения для квадратичного тренда ўt = a+bt+сt2, которые выглядят так: yt=na+bt+сt2, ytt =at + bt2 + сt3, (2.12) ytt2 =at2 + bt3 + сt4, Рассчитав все суммы и решив систему относительно а, b и с, получим уравнение параболического тренда. Пример 2.3.. В таблице 2.3 представлены данные, характеризующие динамику выпуска продукции Финляндии ( млн долл.) за 17 лет. Провести расчет параметров линейного и экспоненциального тренда, построить графики ряда динамики и трендов. Таблица 2.3
Для определения числовых значений констант уравнения (2.11) удобно пользоваться таблицей 2.3. Определив все суммы и подставив их в систему нормальных уравнений 367030,0 = 17 a + b 153 3924711,0 = a 153 + b 1785 найдем свободный член уравнения a =7881,74 и коэффициент пропорциональности b = 1523,14. Таким образом, прогнозная модель имеет вид ўt = 7881,74 +1523,14 t Подставляя значения t=1,2…17, получим значения линейного тренда. Нанесем полученные данные на график (рис. 2.2). 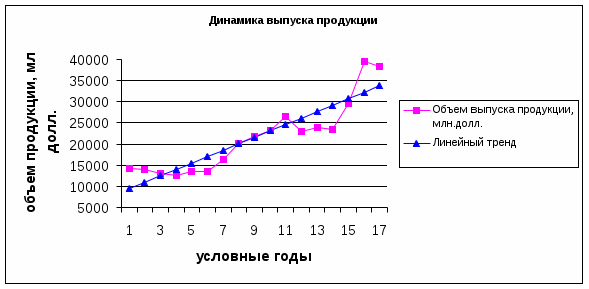 Рис. 2.2 Динамика выпуска продукции Из графика видно, что изменение выпуска продукции можно приблизить линейной зависимостью. В случаях, когда в качестве уравнения регрессии используются гиперболическая, экспоненциальная, степенная, логистическая и некоторые другие функции, процессу построения системы нормальных уравнений должен предшествовать процесс линеаризации кривой, осуществляемый с помощью замены переменных (табл.2.4) Таблица 2.4
Если для описания исходной кривой с равным основанием можно использовать несколько аналитических функций, то для выбора зависимости, наиболее точно отображающей наблюдаемую динамику, рекомендуется применять специальные статистические показатели. Наиболее распространенные из них: 2ост-остаточная дисперсия, ост-среднее квадратичное отклонение, V-коэффициент вариации, r- коэффициент линейной корреляции, Ry/t - индекс корреляции, d -коэффициент детерминации2. Первые три показателя связаны между собой: 2ост= ост = (здесь yср – средняя арифметическая, yср= В качестве уравнения тренда следует использовать ту зависимость, у которой значения 2ост, ост, V - минимальны. Индекс корреляции - дает относительную оценку степени близости тренда к точкам исходной кривой. Общее отклонение фактического значения переменной от среднего уровня можно представить как сумму двух слагаемых: yt – yср=( yt – или сокращенно общ=ост+t, где общ – (yt – yср) — отклонение, измеряющее общую вариацию за счет действия всех факторов; ост=( yt – t=( Если линия тренда подобрана удачно по отношению к точкам исходной кривой, то |yt- Ry/t=t/общ=(общ-ост)/ общ=1-ост/общ (2.13) По этому уравнению можно оценить близости исходной функции и уравнения регрессии. Чем значительнее разброс точек на графике, тем ниже значение Ry/t, и наоборот. Формула (2.13) позволяет оценить расхождение для какого-то одного значения аргумента t. Для итоговой оценки надо просуммировать частные результаты по всем годам оцениваемого периода и для устранения влияния знаков отклонения возвести в квадрат. С учетом вышесказанного: Ry/t= где – 2общ=2 общ/n – общая дисперсия, измеряющая вариацию переменной за счет действия всех факторов; 2ост=2 ост/n – остаточная дисперсия, характеризующая отклонение между ихсодными и расчетными значениями переменной yt. Показатель Ry/t принято называть индексом корреляции. Частный случай индекса корреляции - коэффициент линейной корреляции, который определяется для оценки силы связи при линейном взаимодействии признаков ( Наряду с коэффициентом корреляции применяется коэффициент детерминации: d=r2 (2.15) Он показывает, какая часть общей колеблемости зависимой переменной yt объясняется действием фактор-аргумента t. |