Биометрия. Материалы для практического занятия. Предметом биометрии
 Скачать 1.29 Mb. Скачать 1.29 Mb.
|

|
Коэффициент вариации Пример 13. Сравнивают два варьирующих признака. Один характеризуется средней=2,4 кг и средним квадратическим отклонением=0,58 кг, другой — величинами=8,3 см и = 1,57 см. Следует ли отсюда, что второй признак варьирует сильнее, чем первый? Нет, не следует, так как среднее квадра тическое отклонение определяют по отклонениям от средних, а они различны по величине. Кроме того, не вполне корректно сравнивать величины, выраженные разными единицами меры. Именно поэтому в подобных случаях уместно использовать без размерные значения коэффициентов вариации. Сравнивая их в приводимом примере, находим, что сильнее варьирует не вто рой, а первый признак: Различные признаки характеризуются различными коэффи циентами вариации. Но в отношении одного и того же призна ка значение этого показателяостается более или менее устойчивым и при симметричных распределениях обычно не пре вышает 50%. При сильно асимметричных рядах распределения коэффициент вариации может достигать 100% и даже выше. Варьирование считается слабым, если не превосходит 10%, средним, когдасоставляет 11—25%, и значительным при Применяя коэффициент вариации в качестве характеристики варьирования, следует учитывать единицы размерности изучае мого признака: линейные или весовые (объемные). Акад. И. И. Шмальгаузен (1936) отмечал, что в таких случаях коэф фициент вариации оказывается неодинаковым. Иллюстрацией тому могут служить данные Ю. Г. Артемьева (1939), исследо вавшего варьирование величины внутренних органов у малых сусликов в зависимости от того, какими единицами меры выра жены признаки (табл.10). Данные, приведенные в табл. 10, показывают, что при линей ном выражении величины признака коэффициент вариации ока зывается примерно в три раза меньше, чем При кубическом вы ражении того же признака. Причина такого явления — в мате матических свойствах, которые надо учитывать, чтобы избе жать возможных ошибок. Таблица 10.
Нормированное отклонение t.Отклонение той или иной ва рианты от средней арифметической, отнесенное к величине среднего квадратического отклонения, называют нормирован ным отклонением-. Этот показатель позволяет «измерять» отклонения отдельных вариант от среднего уровня и сравнивать их для разных приз наков. Пример 14. При обследовании группы подростков в возра сте от 15 до 16 лет установлено, что средний рост юношей ха рактеризуется следующими показателями:=164,8 см и= = 5,8 см. В группе оказался юноша, рост которого равен 172,4 см. Спрашивается: как велико отклонение роста этого юноши от средней величины данного признака в этой группе? Нормируя рост юноши (=172,4), находим Получая значения нормированных отклонений для разных признаков, можно сравнить места, занимаемые особью, индиви дом и т. п. по каждому из этих признаков в их распределени ях. Пусть, например, нормированное -отклонение у рассматри ваемого юноши по ширине плеч равно — 0,41. Тогда можно ут верждать что у него длина тела отклоняется от средней в сто рону больших величин этого признака, а ширина плеч — в сто рону малых, т. е. характерен относительно узкоплечий тип те лосложения. Нормированное отклонение используют также при работе с так называемым нормальным распределением. СТРУКТУРНЫЕ СРЕДНИЕ И СПОСОБЫ ИХ ВЫЧИСЛЕНИЯ Медиана (Me). Средняя арифметическая — одна из основных характеристик варьирующих объектов по тому или иному приз наку. Однако она не лишена недостатков, так как очень чув ствительна к увеличению числа наблюдений или к уменьшению за счет вариант, резко отличающихся по своей величине от ос новной массы. Поэтому на величину средней арифметической могут значительно влиять крайние члены ранжированного ва риационного ряда, которые как раз и наименее характерны для данной совокупности. В связи с этим во многих случаях в ка честве обобщающих характеристик совокупности более полез ными могут оказаться так называемые структурные средние. Эти величины обычно представляют собой конкретные вариан ты имеющейся совокупности, которые занимают особое место в ряду распределения. Одной из таких характеристик является медиана — средняя, относительно которой ряд распределения делится на две рав ные части: в обе стороны от медианы располагается одинако вое число вариант. При наличии небольшого числа вариант медиана определяется довольно просто. Для этого собранные данные ранжируют, и при нечетном числе членов ряда цент ральная варианта и будет его медианой. При четном числе членов ряда медиана определяется по полусумме двух сосед них вариант, расположенных в центре ранжированного ряда. Например, для ранжированных значений признака —12 14 16 18 20 22 24 26 28 — медианой будет центральная варианта, т. е. Me—20, так как в обе стороны от нее отстоит по четыре варианты. Для ряда с четным числом членов — 6 8 10 12 14 16 18 20 22 24 — медианой будет полусумма его центральных чле нов, т. е. Me— (14+16)/2= 15. Для данных, сгруппированных в вариационный ряд, медиа на определяется следующим образом. Сначала находят класс, в котором содержится медиана. Для этого частоты ряда куму лируют в направлении от меньших к большим значениям клас сов до величины, превосходящей половину всех членов данной совокупности, т. е. n/2. Первая величина в ряду накопленных частот 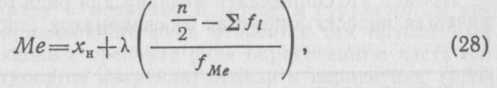 где—нижняя граница классового интервала, содержащего медиану, или полусумма соседних классов безынтервального ряда, в промежутке между которыми находится медиана;— сумманакопленных частот, стоящая перед медианным клас сом;— частота медианного класса;—величина классово го интервала;—общее число наблюдений. Пример 20. Вернемся к ряду распределения кальция (мг%) в сыворотке крови обезьян и вычислим для него медиану (табл. 17). Таблица 17 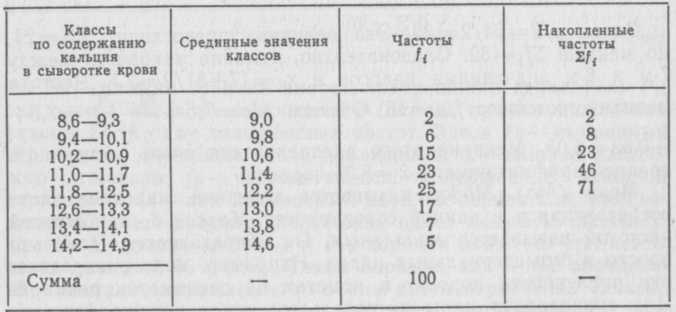 В данном случае Теперь превратим интервальный вариационный ряд в безынтегральный и вычислим медиану по срединным значени ям классовых интервалов. Медиана находится между значения ми классов 11,4 и 12,2. Отсюда Пример 21. Определить медиану для ряда распределения ко личества поросят в пометах 64 свиноматок (табл. 18). Таблица 18  Здесь=64/2=32. Эта величина превосходит медианного класса + средней арифметической=8,25 поросят. Мода (Мо). Модой называется величина, наиболее часто встречающаяся в данной совокупности. Класс с наибольшей частотой называется модальным. Он определяется довольно просто в безынтервальных рядах. Например, мода распределе ния численности поросят в пометах 64 свиноматок равна 8. Для определения моды интервальных рядов служит формула где—нижняя границамодального класса, т. е. класса с наибольшей частотой;—частота класса, предшествующего модальному;—частота класса, следующего за модальным; — ширина классового интервала. Пример 22. Определить моду ряда распределения кальция (мг%) в сыворотке крови обезьян. Необходимые данные содер жатся в табл. 17. Частота модального класса=25, его ниж няя граница=11,8. Частота класса, предшествующего мо дальному,=23, частота класса, следующего за модальным, = 17;=0,8. Подставляя эти данные в формулу (29), нахо дим Квантили. Наряду с медианой и модой к структурным ха рактеристикам вариационного ряда относятся так называемые квантили, отсекающие в пределах ряда определенную часть его членов. К ним относятся квартили, децили и перцентили (про-центили). Квартили — это три значения признака делящие ранжированный вариационный ряд на четыре равные части. Аналогично, девять децилей делят ряд на 10 равных час тей, а 99 перцентилей — на 100 равных частей. В практике используют обычно перцентили третьему квартилям, между которыми находится 50% всех членов ряда, асоответствует второму квартилю и равен медиане, т. е. „ последовательных действий, которые можно выразить в виде следующей формулы: где—нижняя граница класса, содержащего перцентиль; она определяется по величине Пример 23. Найти 50-й перцентиль ряда распределения го дового удоя коров (=80), для которого определены средняя арифметическая и показатели вариации (см. пример 18, табл. 13). Величина Формула (30) применима и для нахождения перцентилей безынтервальных вариационных рядов. Пример 24. Найдите 50-й перцентиль для ряда распределе ния численности поросят в пометах 64 свиноматок; В данном случае К=50*64/100=32. Эта величина больше Тема № 3.Выборочный метод и оценка генеральных параметров. Цель– изучить выборочныйметод и оценку генеральных параметров. Задачи. Генеральная совокупность и выборка. Точечные оценки. Требования, предъявляемые к точечным оценкам. Статистические ошибки. Краткое содержание. Наблюдения над биологическими объектами могут охваты вать все члены изучаемой совокупности без единого исключе ния или ограничиваться обследованием лишь некоторой части членов данной совокупности. В первом случае наблюдения на зывают полными или сплошными, во втором — частичными или выборочными. Полное обследование совокупности позволяет получать исчерпывающую информацию об изучаемом объекте, в чем и заключается преимущество этого способа перед спосо бом выборочного наблюдения. Однако к сплошному наблюде нию прибегают редко, так как эта работа сопряжена с боль шими затратами времени и труда, а также в силу практической невозможности или нецелесообразности проведения такой ра боты. Невозможно, например, учесть всех обитателей зоо- или фитопланктона даже небольшого водоема, потому что их чис ленность практически необозрима. Нецелесообразно высевать всю партию семян для того, чтобы определить их всхожесть. В подавляющем большинстве случаев вместо сплошного наблю дения изучению подвергают некоторую часть обследуемой со вокупности, по которой и судят о ее состоянии в целом. Совокупность, из которой отбирают определенную часть ее членов для совместного изучения, называют генеральной. Отоб ранная тем или иным способом часть генеральной совокупно сти получила название выборочной совокупности или выборки. Общую сумму членов генеральной совокупности называют ее объемом и обозначают буквой N. Теоретически объем генеральной совокупности ничем не ог раничен, т. е. генеральную совокупность представляют как бесконечно большое множество относительно однородных единиц или членов, составляющих ее содержание. Практически же объем генеральной совокупности всегда ограничен и может быть различным в зависимости от объекта наблюдения и той задачи, которую приходится решать. Например, при определе нии продуктивности животных той или иной породы или вида генеральную совокупность составят все особи данной породы или вида. Если же вопрос о продуктивности животных решают в зоне данной области или района, то генеральную совокуп ность составят все животные изучаемой породы, распространен ной в данной области или районе. Объем выборки, обозначаемый буквой п, может быть и большим, и малым, но он не может содержать менее двух единиц. Выборочный метод — основной при изучении статисти ческих совокупностей. Его преимущество перед полным учетом всех членов генеральной совокупности заключается в том, что он сокращает время и затраты труда (за счет уменьшения чис ла наблюдений), а главное — позволяет получать информацию о таких групповых объектах, сплошное обследование которых практически невозможно или нецелесообразно. Основное требование, предъявляемое к любой выборке, сво дится к получению наиболее полной информации о состоянии генеральной совокупности, из которой выборка взята. Опыт показал, что правильно отобранная часть генеральной совокуп ности, т. е. выборка, довольно хорошо отображает структуру генеральной совокупности. Однако полного совпадения выбо рочных показателей с характеристиками генеральной совокуп ности, как правило, не бывает. Чтобы выборка наиболее полно отображала структуру генеральной совокупности, она должна быть достаточно представительной, или репрезентативной (от лат. represento — представляю). Репрезентативность выборки достигается способом рандомизации (от англ. random — слу чай) или случайным отбором вариант из генеральной совокуп ности, что обеспечивает равную возможность для всех членов генеральной совокупности попасть в состав выборки. Существует два основных способа отбора вариант из гене ральной совокупности: повторный и бесповторный. Повторный отбор производят по схеме «возвращения» учтенных единиц в генеральную совокупность, так что одна и та же единица мо жет попасть в выборку повторно. При бесповторном отборе уч тенные единицы не возвращаются в генеральную совокупность, каждая отобранная единица регистрируется только один раз. Повторный отбор не влияет на состав генеральной совокупно сти, и возможность каждой единицы попасть в выборку не ме няется. При бесповторном отборе возможность единиц, состав ляющих генеральную совокупность, попасть в выборку меня ется, так как каждый предшествующий отбор влияет на результаты последующего, а также и на состав генеральной совокуп ности, который тоже претерпевает изменения. В практике обычно применяют бесповторный случайный отбор. Так, если измеряют рост мужчин призывного возраста, то, измерив одно го из них, вторично его уже не измеряют. Случайный повтор ный отбор служит теоретической моделью, с помощью которой изучают процессы, совершающиеся в статистических совокуп ностях, что имеет определенное познавательное значение. Идеальный случайный отбор производится по методу же ребьевки или лотереи, а также с помощью таблицы случайных чисел, позволяющих полностью исключить субъективное влия ние на состав выборки. Сущность этого метода заключается в следующем. На численно ограниченной, но довольно большой искусственной модели генеральной совокупности способом пов торного случайного отбора образуется ряд чисел, которые за носят в таблицу таким образом, чтобы они имели одинаковое количество цифр. Этим облегчается использование такой таб лицы в практических целях. Например, при трехзначности чи сел цифру 8 заносят в таблицу в виде 008, а число 69 — в виде 069 и т. д. Числа записывают в таблицу в случайном порядке, поэтому ее и называют таблицей случайных чисел. Такая че тырехзначная таблица помещена в Приложении (табл. IV). Как пользоваться этой таблицей? Пусть из общего числа 120 животных, содержащихся в виварии, нужно отобрать для опыта 10 особей. Для того чтобы отбор был действительно слу чайным, исключающим субъективные влияния на состав выбор ки, необходимо поступить следующим образом. Всем животным вивария или только животным той группы, из которой намечено отобрать 10 особей, присваивают номера от 1 до п. Затем в таблице случайных чисел находят десять таких, которые не превышают п. Пусть я=120. Пользуясь табл. IV, условимся учитывать первые три цифры в каждом столбце этой таблицы (хотя можно исходить и из другого условия). В первом столб це находят числа 0905 и 0912. Согласно условию, это дает числа 90 и 91. Других нужных чисел в этом столбце нет. Во втором столбце таблицы находят числа 47 и 41. В третьем столбце обнаруживают числа 62, 84, 50 и 31. В четвертом столбце отыскивают остальные два числа: 39 и 87. Всего полу чилось десять чисел: 90, 91, 47, 41, 62, 84, 50, 31, 39 и 87. Осо бей с такими номерами включают в состав экспериментальной группы. Наряду с простым случайным отбором в практике применя ют и другие виды выборки из генеральной совокупности. К ним относится типический, серийный и механический отбор. Типиче ский отбор используют в тех случаях, когда генеральная совокупность расчленяется на отдельные (типические) группы. Например, в хозяйстве среди крупного рогатого скота находят ся первотелки, группы коров по второму, третьему и другим отелам. В таких случаях из каждой группы случайным способом отбирают одинаковое, а чаще пропорциональное число единиц. Затем вычисляют групповые характеристики, объединяемые в общую характеристику генеральной совокупности. При серийном отборе, как и при типическом, генеральную совокупность предварительно делят на группы (серии, гнезда), образуемые обычно по территориальному принципу. Затем по усмотрению исследователя из общего количества серий или гнезд отбирают некоторое их число для совместной обработки. При этом серии могут быть как равночисленными, так и со стоять из разного числа единиц. Например, из 30 групп под ростков в возрасте от 14 до 15 лет намечено обследовать вы борочно шесть групп. Членов этих групп и объединяют для совместного изучения. Таким образом, в отличие от типическо го отбора при серийной выборке из генеральной совокупности извлекают не отдельные единицы, а целые серии или гнезда относительно однородных единиц. При механическом отборе генеральная совокупность разби вается на несколько равных частей или групп. Затем из каждой группы случайным способом отбирают по одной единице. На пример, при обследовании посева ржи на урожайность намече но отобрать 100 растений (или колосьев). В таком случае поле ржи должно быть разбито на сто равных делянок. Следова тельно, при механическом отборе число единиц равно числен ности групп, на которые разбита генеральная совокупность. Механический отбор может производиться и по другой схеме, когда в выборку попадает каждая десятая, сотая и т. п. еди ница генеральной совокупности. Например, при проведении бо танических или зоологических экскурсий можно регистрировать каждый пятый, десятый и т. п. экземпляр встреченных расте ний или животных данного вида. Кроме типического, серийного и механического отбора в практике применяют и другие разновидности случайной вы борки. ТОЧЕЧНЫЕ ОЦЕНКИ Числовые показатели, характеризующие генеральную сово купность, называют параметрами, а числовые показатели, ха рактеризующие выборку,— выборочными характеристиками или статистиками. Выборочные характеристики являются прибли женными оценками генеральных параметров. Это величины случайные, варьирующие вокруг своих параметров. Оценки ге неральных параметров по выборочным характеристикам могут быть точечными и интервальными. Генеральные характеристики, или параметры, принято обоз начать буквами греческого алфавита, а выборочные характе ристики— латинского. Выборочная средняя хср является оценкой генеральной средней µ, выборочная дисперсия sx2—оценкой генеральной дисперсии σх2, а среднее квадратическое отклоне ние sx — оценкой стандартного отклонения σх, характеризую щего генеральную совокупность. Это точечные оценки, пред ставляющие собой не интервалы, а числа («точки»), вычисляе мые по случайной выборке. | ||||||||||||||||||||